







LSM树(Log-Structured Merge Tree)存储引擎
代表数据库:nessDB、leveldb、Hbase等
LSM Tree 日志结构化合并树,核心思想的核心就是放弃部分读能力,换取写入的最大化能力。它的核心思路其实非常简单,就是假定内存足够大,因此不需要每次有数据更新就必须将数据写入到磁盘中,而可以先将最新的数据驻留在磁盘中,等到积累到最后多之后,再使用归并排序的方式将内存内的数据合并追加到磁盘队尾(因为所有待排序的树都是有序的,可以通过合并排序的方式快速合并到一起)。
日志结构的合并树(LSM-tree)是一种基于硬盘的数据结构,与B-tree相比,能显著地减少硬盘磁盘臂的开销,并能在较长的时间提供对文件的高速插入(删除)。然而LSM-tree在某些情况下,特别是在查询需要快速响应时性能不佳。通常LSM-tree适用于索引插入比检索更频繁的应用系统。Bigtable在提供Tablet服务时,使用GFS来存储日志和SSTable,而GFS的设计初衷就是希望通过添加新数据的方式而不是通过重写旧数据的方式来修改文件。而LSM-tree通过滚动合并和多页块的方法推迟和批量进行索引更新,充分利用内存来存储近期或常用数据以降低查找代价,利用硬盘来存储不常用数据以减少存储代价。
磁盘的技术特性:对磁盘来说,能够最大化的发挥磁盘技术特性的使用方式是:一次性的读取或写入固定大小的一块数据,并尽可能的减少随机寻道这个操作的次数。
LSM Tree存储模型介绍:
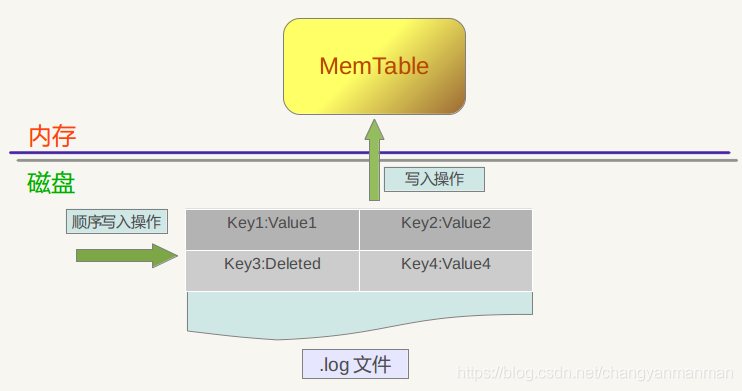
WAL
在设计数据库的时候经常被使用,当插入一条数据时,数据先顺序写入 WAL 文件中,之后插入到内存中的 MemTable 中。这样就保证了数据的持久化,不会丢失数据,并且都是顺序写,速度很快。当程序挂掉重启时,可以从 WAL 文件中重新恢复内存中的 MemTable。
MemTable
MemTable 对应的就是 WAL 文件,是该文件内容在内存中的存储结构,通常用 SkipList 来实现。MemTable 提供了 k-v 数据的写入、删除以及读取的操作接口。其内部将 k-v 对按照 key 值有序存储,这样方便之后快速序列化到 SSTable 文件中,仍然保持数据的有序性。
Immutable Memtable
顾名思义,Immutable Memtable 就是在内存中只读的 MemTable,由于内存是有限的,通常我们会设置一个阀值,当 MemTable 占用的内存达到阀值后就自动转换为 Immutable Memtable,Immutable Memtable 和 MemTable 的区别就是它是只读的,系统此时会生成新的 MemTable 供写操作继续写入。
之所以要使用 Immutable Memtable,就是为了避免将 MemTable 中的内容序列化到磁盘中时会阻塞写操作。
SSTable
SSTable 就是 MemTable 中的数据在磁盘上的有序存储,其内部数据是根据 key 从小到大排列的。通常为了加快查找的速度,需要在 SSTable 中加入数据索引,可以快读定位到指定的 k-v 数据。

SSTable 通常采用的分级的结构,例如 LevelDB 中就是如此。MemTable 中的数据达到指定阀值后会在 Level 0 层创建一个新的 SSTable。当某个 Level 下的文件数超过一定值后,就会将这个 Level 下的一个 SSTable 文件和更高一级的 SSTable 文件合并,由于 SSTable 中的 k-v 数据都是有序的,相当于是一个多路归并排序,所以合并操作相当快速,最终生成一个新的 SSTable 文件,将旧的文件删除,这样就完成了一次合并过程。
常用操作的实现
写入:
在 LSM Tree 中,写入操作是相当快速的,只需要在 WAL 文件中顺序写入当次操作的内容,成功之后将该 k-v 数据写入 MemTable 中即可。尽管做了一次磁盘 IO,但是由于是顺序追加写入操作,效率相对来说很高,并不会导致写入速度的降低。数据写入 MemTable 中其实就是往 SkipList 中插入一条数据,过程也相当简单快速。
更新
更新操作其实并不真正存在,和写入一个 k-v 数据没有什么不同,只是在读取的时候,会从 Level0 层的 SSTable 文件开始查找数据,数据在低层的 SSTable 文件中必然比高层的文件中要新,所以总能读取到最新的那条数据。也就是说此时在整个 LSM Tree 中可能会同时存在多个 key 值相同的数据,只有在之后合并 SSTable 文件的时候,才会将旧的值删除。
删除
删除一条记录的操作比较特殊,并不立即将数据从文件中删除,而是记录下对这个 key 的删除操作标记,同插入操作相同,插入操作插入的是 k-v 值,而删除操作插入的是 k-del 标记,只有当合并 SSTable 文件时才会真正的删除(也就是只有在磁盘上才会删除)。
Compaction
当数据不断从 Immutable Memtable 序列化到磁盘上的 SSTable 文件中时,SSTable 文件的数量就不断增加,而且其中可能有很多更新和删除操作并不立即对文件进行操作,而只是存储一个操作记录,这就造成了整个 LSM Tree 中可能有大量相同 key 值的数据,占据了磁盘空间。
为了节省磁盘空间占用,控制 SSTable 文件数量,需要将多个 SSTable 文件进行合并,生成一个新的 SSTable 文件。比如说有 5 个 10 行的 SSTable 文件要合并成 1 个 50 行的 SSTable 文件,但是其中可能有 key 值重复的数据,我们只需要保留其中最新的一条即可,这个时候新生成的 SSTable 可能只有 40 行记录。
通常在使用过程中我们采用分级合并的方法,其特点如下:
1、每一层都包含大量 SSTable 文件,key 值范围不重复,这样查询操作只需要查询这一层的一个文件即可。(第一层比较特殊,key 值可能落在多个文件中,并不适用于此特性)
2、当一层的文件达到指定数量后,其中的一个文件会被合并进入上一层的文件中。
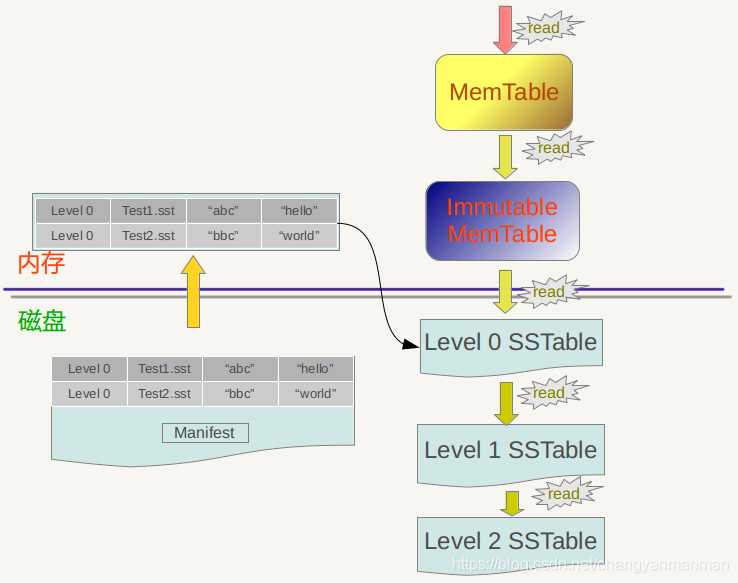
LSM Tree 的读取效率并不高,当需要读取指定 key 的数据时,先在内存中的 MemTable 和 Immutable MemTable 中查找,如果没有找到,则继续从 Level 0 层开始,找不到就从更高层的 SSTable 文件中查找,如果查找失败,说明整个 LSM Tree 中都不存在这个 key 的数据。如果中间在任何一个地方找到这个 key 的数据,那么按照这个路径找到的数据都是最新的。
在每一层的 SSTable 文件的 key 值范围是不重复的,所以只需要查找其中一个 SSTable 文件即可确定指定 key 的数据是否存在于这一层中。Level 0 层比较特殊,因为数据是 Immutable MemTable 直接写入此层的,所以 Level 0 层的 SSTable 文件的 key 值范围可能存在重复,查找数据时有可能需要查找多个文件。
优化读取
因为这样的读取效率非常差,通常会进行一些优化,例如 LevelDB 中的 Mainfest 文件,这个文件记录了 SSTable 文件的一些关键信息,例如 Level 层数,文件名,最小 key 值,最大 key 值等,这个文件通常不会太大,可以放入内存中,可以帮助快速定位到要查询的 SSTable 文件,避免频繁读取。
另外一个经常使用的方法是布隆解析器(Bloom filter),布隆解析器是一个使用内存判断文件是否包含一个关键字的有效方法。
总结
LSM Tree 的思想非常实用,将随机写转换为顺序写来大幅提高写入操作的性能,但是牺牲了部分读的性能。
由于时间序列数据库的特性,运用 LSM Tree 的算法非常合适。持续写入数据量大,数据和时间相关,编码到 key 值中很容易使 key 值有序。读取操作相对来说较少,而且通常不是读取单个 key 的值,而是一段时间范围内的数据,这样就把 LSM Tree 读取性能差的劣势缩小了,反而由于数据在 SSTable 中是按照 key 值顺序排列,读取大块连续的数据时效率也很高。
TSM(Time-Structured Merge Tree)存储引擎
InfluxDB底层的存储引擎经历了从LevelDB到BlotDB,再到选择自研TSM的过程,整个选择转变的思考可以在其官网文档里看到。整个思考过程很值得借鉴,对技术选型和转变的思考总是比平白的描述某个产品特性让人印象深刻的多。
它的整个存储引擎选型转变的过程,第一阶段是LevelDB,选型LevelDB的主要原因是其底层数据结构采用LSM,对写入很友好,能够提供很高的写入吞吐量,比较符合时序数据的特性。在LevelDB内,数据是采用KeyValue的方式存储且按Key排序,InfluxDB使用的Key设计是SeriesKey+Timestamp的组合,所以相同SeriesKey的数据是按timestamp来排序存储的,能够提供很高效的按时间范围的扫描。
不过使用LevelDB的一个最大的问题是,InfluxDB支持历史数据自动删除(Retention Policy),在时序数据场景下数据自动删除通常是大块的连续时间段的历史数据删除。LevelDB不支持Range delete也不支持TTL(time to live),所以要删除只能是一个一个key的删除,会造成大量的删除流量压力,且在LSM这种数据结构下,真正的物理删除不是即时的,在compaction时才会生效。各类TSDB实现数据删除的做法大致分为两类:
1)数据分区:按不同的时间范围划分为不同的分区(Shard),因为时序数据写入都是按时间线性产生的,所以分区的产生也是按时间线性增长的,写入通常是在最新的分区,而不会散列到多个分区。分区的优点是数据回收的物理删除非常简单,直接把整个分区删除即可。缺点是数据回收的精细度比较大,为整个分区,而回收的时间精度取决于分区的时间跨度。分区的实现可以是在应用层提供,也可以是存储引擎层提供,例如可以利用RocksDB的column family来作为数据分区。InfluxDB采用这种模式,默认的Retention Policy下数据会以7天时间跨度组成为一个分区。
2)TTL:底层数据引擎直接提供数据自动过期的功能,可以为每条数据设定存储时间(time to live),当数据存活时间到达后存储引擎会自动对数据进行物理删除。这种方式的优点是数据回收的精细度很高,精细到秒级及行级的数据回收。缺点是LSM的实现上,物理删除发生在compaction的时候,比较不及时。RocksDB、HBase、Cassandra和阿里云表格存储都提供数据TTL的功能。
InfluxDB在经历了几个小版本的BoltDB后,最终决定自研TSM,TSM的设计目标一是解决LevelDB的文件句柄过多问题,二是解决BoltDB的写入性能问题。TSM全称是Time-Structured Merge Tree,思想类似LSM,不过是基于时序数据的特性做了一些特殊的优化。来看下TSM的一些重要组件:
- Write Ahead Log(WAL) : 数据会先写入WAL,后进入memory-index和cache,写入WAL会同步刷盘,保证数据持久化。Cache内数据会异步刷入TSM File,在Cache内数据未持久化到TSM File之前若遇到进程crash,则会通过WAL内的数据来恢复cache内的数据,这个行为与LSM是完全类似的。
- Cache: TSM的Cache与LSM的MemoryTable类似,其内部的数据为WAL中未持久化到TSM File的数据。若进程发生failover,则cache中的数据会根据WAL中的数据进行重建。Cache内数据保存在一个SortedMap中,Map的Key为TimeSeries+Timestamp的组成。所以可以看到,在内存中数据是按TimeSeries组织的,TimeSeries中的数据按时间顺序存放。
- TSM Files: TSM File与LSM的SSTable类似,TSM File由四个部分组成,分别为:header, blocks, index和footer。其中最重要的部分是blocks和index:
- Block:每个block内存储的是某个TimeSeries的一段时间范围内的值,即某个时间段下某个measurement的某组tag set对应的某个field的所有值,Block内部会根据field的不同的值的类型采取不同的压缩策略,以达到最优的压缩效率。
- Index:文件内的索引信息保存了每个TimeSeries下所有的数据Block的位置信息,索引数据按TimeSeries的Key的字典序排序。在内存中不会把完整的index数据加载进去,这样会很大,而是只对部分Key做索引,称之为indirectIndex。indirectIndex中会有一些辅助定位的信息,例如该文件中的最小最大时间以及最小最大Key等,最重要的是保存了部分Key以及其Index数据的文件offset信息。若想要定位某个TimeSeries的Index数据,会先根据内存中的部分Key信息找到与其最相近的Index Offset,之后从该起点开始顺序扫描文件内容再精确定位到该Key的Index数据位置。
- Compaction: compaction是一个将write-optimized的数据存储格式优化为read-optimized的数据存储格式的一个过程,是LSM结构存储引擎做存储和查询优化很重要的一个功能,compaction的策略和算法的优劣决定了存储引擎的质量。在时序数据的场景下,基本很少发生update或者delete,数据都是按时间顺序生成的,所以基本不会有overlap,Compaction起到的作用主要在于压缩和索引优化。
- LevelCompaction: InfluxDB将TSM文件分为4个层级(Level 1-4),compaction只会发生在同层级文件内,同层级的文件compaction后会晋升到下一层级。从这个规则看,根据时序数据的产生特性,level越高数据生成时间越旧,访问热度越低。由Cache数据初次生成的TSM文件称为Snapshot,多个Snapshot文件compaction后产生Level1的TSM文件,Level1的文件compaction后生成level2的文件,依次类推。低Level和高Level的compaction会采用不同的算法,低level文件的compaction采用低CPU消耗的做法,例如不会做解压缩和block合并,而高level文件的compaction则会做block解压缩以及block合并,以进一步提高压缩率。我理解这种设计是一种权衡,compaction通常在后台工作,为了不影响实时的数据写入,对compaction消耗的资源是有严格的控制,资源受限的情况下必然会影响compaction的速度。而level越低的数据越新,热度也越高,需要有一种更快的加速查询的compaction,所以InfluxDB在低level采用低资源消耗的compaction策略,这完全是贴合时序数据的写入和查询特性来设计的。
- IndexOptimizationCompaction: 当Level4的文件积攒到一定个数后,index会变得很大,查询效率会变的比较低。影响查询效率低的因素主要在于同一个TimeSeries数据会被多个TSM文件所包含,所以查询不可避免的需要跨多个文件进行数据整合。所以IndexOptimizationCompaction的主要作用就是将同一TimeSeries下的数据合并到同一个TSM文件中,尽量减少不同TSM文件间的TimeSeries重合度。
- FullCompaction: InfluxDB在判断某个Shard长时间内不会再有数据写入之后,会对数据做一次FullCompaction。FullCompaction是LevelCompaction和IndexOptimization的整合,在做完一次FullCompaction之后,这个Shard不会再做任何的compaction,除非有新的数据写入或者删除发生。这个策略是对冷数据的一个规整,主要目的在于提高压缩率。
组件
TSM 存储引擎主要由几个部分组成: cache、wal、tsm file、compactor。
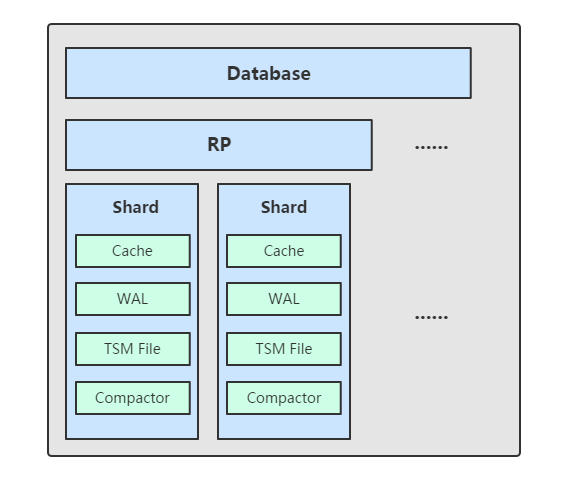
Shard
shard 并不能算是其中的一个组件,因为这是在 tsm 存储引擎之上的一个概念。在 InfluxDB 中按照数据的时间戳所在的范围,会去创建不同的 shard,每一个 shard 都有自己的 cache、wal、tsm file 以及 compactor,这样做的目的就是为了可以通过时间来快速定位到要查询数据的相关资源,加速查询的过程,并且也让之后的批量删除数据的操作变得非常简单且高效。
在 LSM Tree 中删除数据是通过给指定 key 插入一个删除标记的方式,数据并不立即删除,需要等之后对文件进行压缩合并时才会真正地将数据删除,所以删除大量数据在 LSM Tree 中是一个非常低效的操作。
而在 InfluxDB 中,通过 retention policy 设置数据的保留时间,当检测到一个 shard 中的数据过期后,只需要将这个 shard 的资源释放,相关文件删除即可,这样的做法使得删除过期数据变得非常高效。
Cache
cache 相当于是 LSM Tree 中的 memtable,在内存中是一个简单的 map 结构,这里的 key 为 seriesKey + 分隔符 + filedName,目前代码中的分隔符为 #!~#,entry 相当于是一个按照时间排序的存放实际值的数组,具体结构如下:
type Cache struct {
commit sync.Mutex
mu sync.RWMutex
store map[string]*entry
size uint64 // 当前使用内存的大小
maxSize uint64 // 缓存最大值
// snapshots are the cache objects that are currently being written to tsm files
// they're kept in memory while flushing so they can be queried along with the cache.
// they are read only and should never be modified
// memtable 快照,用于写入 tsm 文件,只读
snapshot *Cache
snapshotSize uint64
snapshotting bool
// This number is the number of pending or failed WriteSnaphot attempts since the last successful one.
snapshotAttempts int
stats *CacheStatistics
lastSnapshot time.Time
}
插入数据时,实际上是同时往 cache 与 wal 中写入数据,可以认为 cache 是 wal 文件中的数据在内存中的缓存。当 InfluxDB 启动时,会遍历所有的 wal 文件,重新构造 cache,这样即使系统出现故障,也不会导致数据的丢失。
cache 中的数据并不是无限增长的,有一个 maxSize 参数用于控制当 cache 中的数据占用多少内存后就会将数据写入 tsm 文件。如果不配置的话,默认上限为 25MB,每当 cache 中的数据达到阀值后,会将当前的 cache 进行一次快照,之后清空当前 cache 中的内容,再创建一个新的 wal 文件用于写入,剩下的 wal 文件最后会被删除,快照中的数据会经过排序写入一个新的 tsm 文件中。
目前的 cache 的设计有一个问题,当一个快照正在被写入一个新的 tsm 文件时,当前的 cache 由于大量数据写入,又达到了阀值,此时前一次快照还没有完全写入磁盘,InfluxDB 的做法是让后续的写入操作失败,用户需要自己处理,等待恢复后继续写入数据。
WAL
wal 文件的内容与内存中的 cache 相同,其作用就是为了持久化数据,当系统崩溃后可以通过 wal 文件恢复还没有写入到 tsm 文件中的数据。
由于数据是被顺序插入到 wal 文件中,所以写入效率非常高。但是如果写入的数据没有按照时间顺序排列,而是以杂乱无章的方式写入,数据将会根据时间路由到不同的 shard 中,每一个 shard 都有自己的 wal 文件,这样就不再是完全的顺序写入,对性能会有一定影响。看到官方社区有说后续会进行优化,只使用一个 wal 文件,而不是为每一个 shard 创建 wal 文件。
wal 单个文件达到一定大小后会进行分片,创建一个新的 wal 分片文件用于写入数据。
TSM file
单个 tsm file 大小最大为 2GB,用于存放数据。
TSM file 使用了自己设计的格式,对查询性能以及压缩方面进行了很多优化,在后面的章节会具体说明其文件结构。
Compactor
compactor 组件在后台持续运行,每隔 1 秒会检查一次是否有需要压缩合并的数据。
主要进行两种操作,一种是 cache 中的数据大小达到阀值后,进行快照,之后转存到一个新的 tsm 文件中。
另外一种就是合并当前的 tsm 文件,将多个小的 tsm 文件合并成一个,使每一个文件尽量达到单个文件的最大大小,减少文件的数量,并且一些数据的删除操作也是在这个时候完成。
参考地址:
https://zhuanlan.zhihu.com/p/32710333
http://blog.fatedier.com/2016/08/05/detailed-in-influxdb-tsm-storage-engine-one/














 357
357











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









