







转自:https://blog.csdn.net/colorant/article/details/73887706
Raft这玩意,网上已经有好多解读文章了,大概比Paxos还要多一些,所以,这篇,不求细节,但求核心思想方面,追一下本源,然后,给自己做个笔记。
Raft是什么,它想解决什么问题?
所以Raft是什么?Raft是一个分布式一致性协议/算法,是Replicated And Fault Tolerant的缩写。
在一个分布式系统中,要提高系统的健壮性,可用性和数据的安全性,最标准的做法是什么?当然是靠多备份了,服务多备份,数据多备份,去除单点,确保即使相关组件挂掉一些,系统还能健康服务。
去除单点,没有固定不变的权威,固然好,但是带来的问题就是,以谁的意见为准?这就是一致性问题。一致性问题的重点,不是探讨科学真理,不是要决定谁对谁错,一致性问题的重点,是解决合作问题,不管对错,大家要统一思想,意见要达成一致。
但即使抛开对错,大家抱着无条件达成一致的目标出发,这件事要做好也并不简单,事实上,在信息可能丢失的环境下,这是一个相当困难的事(可见沟通是多么的重要)。以至于最著名的分布式一致性协议算法Paxos,在1990年提出来之时,几乎没有人能够理解。经过作者多次简化,再解释,包括谷歌等团队的实践再创造,再解释的过程,十几年过去了,才渐渐的成为事实标准并被大家所了解和接受。
但直到今天,无比抽象的Paxos协议,依然是所有学习和构建分布式一致性系统的同学心头难以逾越的一个坎。。。
而再来看Raft,做为一个由学术界发起的研究工作,它的Paper居然不是以理论创新为目标,而是以容易理解为唯一目标,就知道这个坎,是有多么的让人难以释怀。
所以,Raft的目标问题,是构建一个容易理解和构建的分布式一致性协议,在容易的基础上,确保理论正确的。
为了这个目标,Raft做了不少的工作,包括在Paper中甚至花了很大力气做实验研究了大家学习Paxos和学习Raft的难度差别。还专门写了各式各样的PPT和数百页的Book来解释各种细节,最佳实践,构建可视化的程序来展现Raft协议的工作过程等等,恨不得把你可能想到的所有问题的答案都拍你脸上。 要是所有的论文都这么写,世界该有多美好 ;)
Raft的核心思想
Raft之所以会出现,按作者的说法,就是Paxos太难理解了。虽然Raft的目标是容易理解,但这不代表它的实现是简单的,实际上Raft把分布式一致性问题分成了好几个步骤来阐述,包括:
Leader的选举过程
Log的复制方案
数据安全(其实就是一致性)
这里面,个人认为只有Leader选举和Log复制是讨论主体方案流程的,数据安全部分其实是对前两个步骤中可能出现的问题的各种补充。
为了容易理解,Raft对Leader选举采用了最直白的随机时间触发,先到先得得方案来实现,后面的每一步,其实都是对这个步骤打的补丁
你会发现论文的阐述方式,基本就是,诶,这里有一个问题,所以我们引进一个限制或约束来实现。接下来,考虑到什么什么情况,这个逻辑还是有缺陷的,那么我们再规定,必须这样那样。然后如果发生了节点崩溃的情况,还有一些Corner case我们需要解决,那么我们要求前面的这个步骤必须怎样怎样。。。
是的,Raft就是一个在随机时间Leader选举基础上叠加了各种补丁的方案。从理论上来看,和简洁漂亮没有半毛钱关系
如果说Paxos是以不变应万变,告诉你一个究极真理,只要你有办法实现它告诉你的步骤,任何问题都有解,那么Raft就是一个手把手的构建指南,每一步都告诉你怎么具体怎么做,哪一步有漏洞,没关系,后续解法我也帮你想好了,没有究级的“道”,只有完善的“术”。
幸运的是,“道”太抽象了,没有几个人能够真正和实践相结合,“术”要整的完善,固然也不是每个人都有时间和精力能做到,但是一旦有人整理了,照着做就好了 ;)
具体协议思想
Raft的整体原理框架是一个基于Log复制机制的状态机:
首先,从组成Raft服务的服务器中选举出一个唯一的Leader主服务器,然后这个主服务器负责接收客户端的命令请求,并将该指令以Log日志的形式分发复制到其它服务器上保存起来,在主服务器认为数据可靠性有保障的时候(在过半服务器上完成复制),它再通知其它服务器(包括自己)将这条指令在各自的状态机中进行执行。只要保证每台服务器的状态机转换逻辑是一致的,执行的指令也是一致的(包括顺序),那么就可以保证所有Raft服务器之间的状态一致性
为了区分日志的时序关系,Raft对日志的时序赋予了两个概念:Terms(时期)和序号,每当发生Leader选举时,Terms都会递增,而序号也是单向递增的,这两个概念,本身其实并不是分布式一致性的本质需求,而是Raft用来辅助Leader选举,检测冲突,判断Log合法性的手段,作为一个逻辑时钟而存在。Raft协议的主要同步逻辑都和这两个概念密切相关。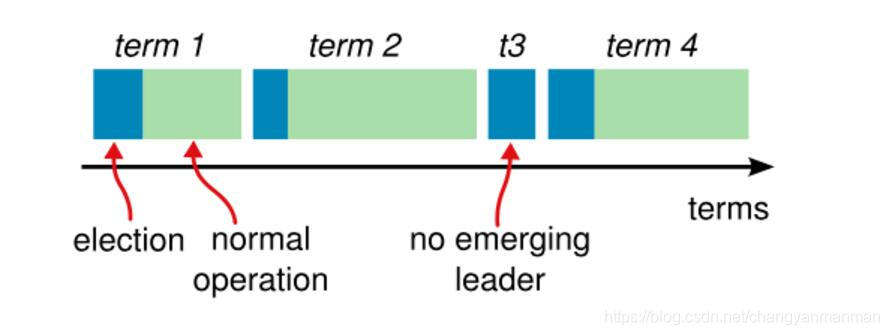
选主逻辑
Paxos的核心逻辑是多个server对一个议案达成一致,选主并不是必备的过程。(当然,可以通过对一个议案达成一致这个方式,来达到选主的目的。通常是优化Paxos性能的一种手段)
而对于Raft来说,选主是核心逻辑,是一切后续流程的源头,个人理解,也是协议中相对Paxos最大程度被简化的地方,一切都是为了后续流程的可理解性和可构造性。
Raft的选主逻辑很简单,要开始一次选举,一台服务器首先把自己已知的当前Terms加一,然后向其它服务器同时发送投票请求,并且给自己投上一票。其它服务器投票的逻辑也很简单,对每个Terms至多投一票,先到先得,如果有人得票过半,那就当选了,就这么简单。当然,实际上要完美的工作并没那么简单,后面还会再打补丁添加一些限制条件。
为了减少大家各投各的,永远达不成一致的概率,每个服务器超时并发起投票请求的时间,都是随机的(特定范围内随机)。如果不是运气背到家了,通常冲突问题一两个回合下来都能很快解决。
LOG日志复制逻辑
选完主,确定了主服务器,接下来的步骤就是日志同步了。在Raft中,所有的客户端请求都由主服务器负责处理的,主服务器将客户端的命令封装成一条日志,发送给其它服务器。日志中包含了命令,对应的Terms时期号和该日志在Log文件中的位置索引。这些额外的附加信息,有助于其它服务器判定日志的合法性和之后的数据同步安全逻辑,事实上还会影响到前面所说的服务器选主的逻辑等等。
日志被复制到其它服务器上不代表这条日志所包含的命令就生效了,复制完的日志还需要经过一个确认提交(commit)的过程,当主服务器确认一条日志已经被多数服务器成功复制后,这条日志所包含的指令就可以正式提交生效了,主服务器会记录当前最新提交状态的日志索引号,并在后续的日志复制请求或心跳中发送给从服务器,最终所有的从服务器也将得到最新的信息并执行指令更新自己的状态机。
日志的复制过程,在实际执行中还会遇到很多问题,比如从服务器的日志和主服务器有冲突:因为主服务器崩溃,未能及时提交日志,然后新的服务器接受了新的指令等各种原因,再比如,从服务器响应日志复制的进度各不相同,还可能重启,崩溃。在Raft中,主服务器采取强制覆盖从服务器的冲突日志的方案来规避日志双向流动,日志只会从主服务器往从服务器发送,不会反向同步,以达到简化日志同步问题的目标。主服务器会为每个从服务器维护一个当前待同步日志索引来跟踪同步进度,实际上判断日志能否正式提交也需要这个信息
数据安全同步的各种问题和补丁
上面的两个步骤,看起来很直白,但实际上是存在很多的Corner Case会打破其逻辑的正确性,比如新选出来的主服务器没有最新已经提交的日志怎么办(所谓最新,就是要不然最后一条日志Terms大,要不然Terms相同,但是序号大),服务不佳,不停有人要求选主,集群几乎不可用怎么办?为此,Raft准备了很多流程和策略补丁来应对类似的这些问题。
先补充两条前面没有提到的日志复制规则:首先,在从服务器接收日志复制指令的过程中,会拒绝Terms时期小于自己已知时期的指令,这个要求很明显,说明有过气的主服务器存在,前老板的要求,当然要婉拒了。。。 其次,主服务器绝对不删除或修改自己已经接受的日志(注意,不是已经提交的)。
但这两条并不解决主服务器上可能没有最新已提交日志的问题,实际上,你还可以构造出很多场景,上述的过程不能保证主服务器上日志是最新的。
所以Raft的整个选举和日志复制过程,还有几条补丁规定:
首先在主服务器的选举过程中,如果发起投票的服务器比从服务器的日志要旧,那么从服务器会拒绝这个选主投票请求。 这条目的是保证候选服务器的日志比过半机器上拥有的已知的日志要新(不代表从服务器的日志是候选服务器的子集,因为从服务器旧的日志可能和候选服务器有冲突)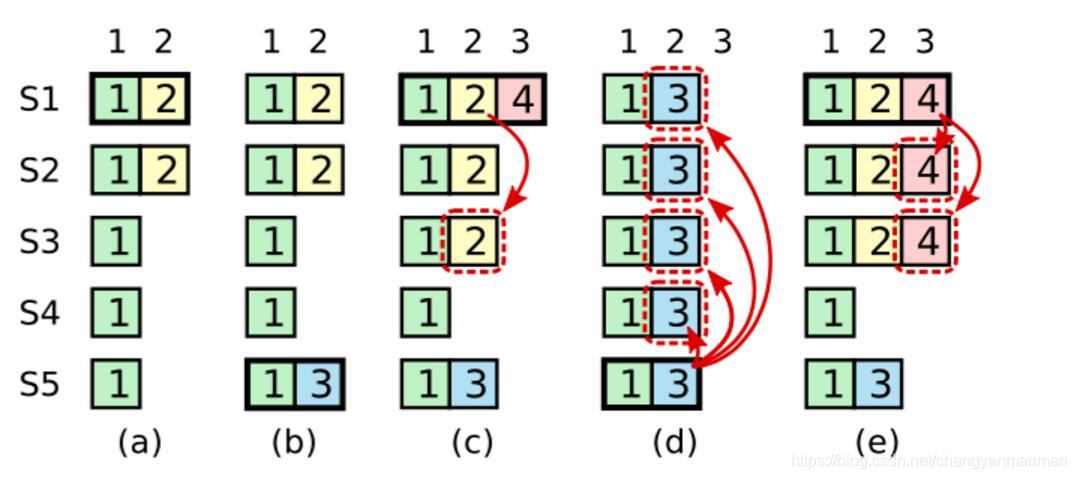
但即使比过半机器的日志新,也不代表就没问题。比如上图的场景:
(a)时间S1是主服务器,Terms2的日志复制了两份,然后主服务器S1崩溃了
(b)时间,S5成功选主(S3/S4/S5投票),自己生成并接受了Terms 3的记录,接着S5崩溃
(c)时间,S1再度选主(S1~S4中三个投票就好),然后复制Terms2的记录到S3服务器
(d)时间S5再度选主(因为它有Terms 3的记录,比S2-S4都新),然后,S5用自己的日志成功替换了S1~S4的所有日志。
这就有问题了,因为Terms2的记录实际上已经满足提交条件(过半机器复制),而且很可能已经被更新到状态机了,这时候被覆盖就造成了状态机和日志的不匹配: 各个服务器的日志一致,但状态机是不一致的。
为了解决这个问题,Raft要求主服务器在确定并通知日志提交时,只在自己当前Terms的日志满足多数原则时才提交,不主动提交历史时期的日志,历史时期的日志在当前时期日志被提交时默认一起提交。(相当于对不同时期日志的提交提出了原子性要求)。
但是如果当前Terms没有日志要提交怎么办?不能无限等下去啊。。。所以,Raft会要求主服务器开始服务时,生成一个当前时期的dummy日志,用来触发提交流程。
所以上图中(e)时间表达的意思是,相比(c)时间,如果提交的是terms 4的记录,那么就不会发生(d)时间所描述的错误。
上面只是一个举例分析的过程,并不能严格证明这样做就真的完全没有问题了,所以Raft论文中还用构造悖论的方式证明了整个流程的正确性
简单说,就是先假设新时期的主服务器没有某个旧时期主服务器已完成提交的日志,那么根据上面的各种流程要求,选举过程等等,可以一步一步推导出该主服务器必须拥有该日志,从而矛盾。篇幅原因,有兴趣深究的同学可以自己查看Paper。
应该说,Raft之所以要打这么多补丁才能较好的搞定同步这件事,根本的原因还是Raft把分布式同步这件工作拆分成了很多独立的步骤来完成,一方面,这样细分问题域,的确降低了协议的抽象性,流程本身更容易和现实可理解的步骤概念对应上。但另一方面,步骤越多,同步这个问题就越容易出纰漏,因为同步本质上就是追求原子性,步骤拆得越多,原子性可能被打破的地方和方式就越多。不过,Raft还是取得了一个较好的平衡。
除此之外,上述流程都是在raft服务器集群的成员集合不变的情况下进行论述的。实际情况是,会有硬件故障,运维,机器变更,扩缩容等各种原因,服务器的成员集合是会发生变化的。这种情况下,在服务器的增减,配置的变更操作过程中,一个不小心,上述流程就可能不能保证正确性了。对于这一点,维护过ZK集群,做过线上不停服迁移的同学八成都踩过坑,确实是一件很难做对的事。
Raft针对服务器成员的变更,专门拓展了相关协议,试图降低这件事的难度。简单来说,就是在Raft服务协议中,明确区分了集群的新老配置,在成员变更的切换过程中,增加了一个联合协同(Joint Consensus)的过程,在这个过程中,选主成功的服务器必须同时在新老服务器成员集合中都获得过半的投票才可以。在后续上下线过程中也有一系列的规范要遵守。(ZK在3.5的版本以后,也增加了专门处理成员变更的流程)
此外,Raft针对日志记录的Compaction压缩,快照的分发,客户端失败重试逻辑等也做了专门的阐述和流程约定,这部分内容相对来说实现方式比较标准,这里就不再赘述。














 829
829











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









