










本系列前五篇都是讲述的比较排序算法,从本文开始,将进入线性时间排序。什么是比较排序,简单的说,就是排序的过程依赖于数组中数据大小的比较,从而来确定数据在排好序输出时的位置。
比较排序法比较直观,但是也有它的不足,我们容易证明任何比较排序法,在最坏的情况下的时间复杂度的下限都是 nlgn。要证明这个问题,我们首先要搞清楚一个模型:决策树模型。
一、决策树模型
什么是决策树?决策树从形态上来讲,是一颗完全二叉树,它除叶子节点之外,其他层的节点都是满的。它的每一个叶子节点表示对输入数据组合的一种排序可能,而它的非叶子节点表示一次判断操作。还是以一个例子来说明比较形象:
比如对于一个有三个元素的数组,它排序一共有多少种可能呢?不难算出应该是3*2*1=3!种组合,所以它的决策树的叶子节点有3!也即6个,因为每一个叶子节点代表一种排序可能。那么这些叶子节点是如何得到的呢?是根据非叶子节点的判断条件而得到的,我们让1 2 3 分别代表3元素数组的三个元素,判断过程如图:
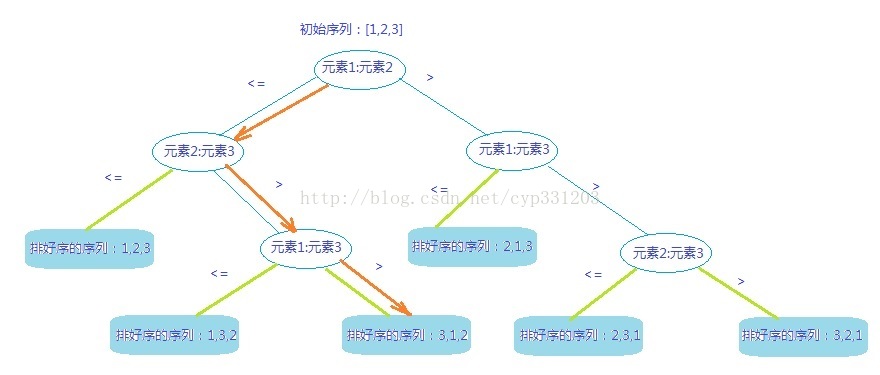
如上图,我们先比较元素1和2,然后根据结果,来判断是进入左子树还是右子树,然后一层层的判断,最后得到排序结果中的一种,当然对于某一个确定的数组来说,路径只可能是一种;比如我们以数组[6,8,5]为例,则走的是橙色箭头的路径,最后排序完之后是:元素3,1,2,;也即[5,6,8]。
根据完全二叉树的性质,我们可以知道,对于高度为h的完全二叉树,叶子节点最多有2^h个,而我们这里(对于n个节点的排序)策略树最下一层的叶子节点个数为n!个,所以我们不难得到2^h>=n!,所以有:h>=lg(n!),又由算法导论(第三版)上的公式3.19可知lg(n!)>=nlgn,所以h>=nlgn。
至此,我们可以知道,对于任何的比较排序算法,它的策略树高度最少也为nlgn高,即它要得到一个排序的结果,至少也要经过nlgn步,最坏的情况下时间复杂度下限为nlgn。
二、计数排序算法
对于计数排序来说,它的时间复杂度为O(n),但是它的使用有一些附加的限制条件:①输入的n个元素都是在0~k区间内的一个整数,其中k为某个整数;②k=O(n)
对于满足上述两个条件的数组,就可以使用计数排序,且排序的时间复杂度为O(n)。
计数排序并不像之前的快速排序,堆排序一样,需要进行元素之间的比较。计数排序是一种完全不需要进行元素的比较的排序方法。我们来看看计数排序的基本思想:
由于计数排序针对的数组是满足上述①和②条件的,所以我们可以知道,数组中的元素的取值只有k+1种可能,也即从0~k的值中选取。并且,对于排序来说,以从小到大排序为例,对于某个确定的元素而言,如果数组中的元素都是互异的情况下,如果我们知道数据中小于该元素的个数有多少个,那么我们就可以确定该元素的位置;如果对于元素的值有相等的情况,我们只需要对相等的元素进行处理即可。
例如,x是数组中的一个元素,在数组中有17个元素小于x,且没有元素与x的值相等,那么x在排序好的数组中就应该位于第18个元素(从小到大排序)。当有元素跟x的值相等的时候,则需要调整方案,处理相等的时候的顺序。
基于上面的思想,对于从小到大的计数排序,我们只要求出对于每个元素不大于他们的所有元素的个数,则可以想办法来确定他们在排序之后的位置,即可以完成排序了。可以预想到,除了要排序的数组a[n]之外,我们还需要一个数组b[n]来存储排序好的数组的元素,和一个数组c[k+1]来存储从0~k这k+1个值分别在数组中出现的次数,进而求出比他们小的值出现的次数之和。
这里给出一个c++的实现代码:
#include <iostream>
#define max_value 7
#define min_value 0
using namespace std;
void countingSort(int a[], int c[], int b[], int max);
void printArray(int a[], int len);
int main() {
int a[10] = { 5, 4, 0, 1, 6, 4, 0, 1, 7, 3 };
int b[10];
int c[max_value + 1];
printArray(a, 10);
countingSort(a, c, b, 7);
printArray(b, 10);
return 0;
}
/*
* 计数排序,假设n个数,最大值为7,最小值为0
*/
void countingSort(int a[], int c[], int b[], int max) {
int tmp;
/* 初始化c数组,为了方便后面统计小于某元素的元素个数,因为某些元素可能不出现,那么它们的个数应该初始化为0 */
for (int i = 0; i <= max; i++) {
c[i] = 0;
}
//printArray(c, 8);
//统计a数组中每个元素出现的次数
for (int i = 0; i < 10; i++) {
c[a[i]]++;
}
//printArray(c, 8);
//统计在小于等于每个元素的元素有多少个
for (int i = 0; i <= max; i++) {
tmp = i - 1;
if (tmp < 0) {
//什么都不做
} else {
c[i] += c[tmp];
}
}
//printArray(c, 8);
//将输出的排序数组填入到b中
for (int i = 9; i >= 0; i--) {
//减一是为了让数组序数从0开始算起
b[c[a[i]] - 1] = a[i];
c[a[i]]--;//处理有元素的值相同的情况
}
}
//打印数组
void printArray(int a[], int len) {
for (int i = 0; i < len; i++) {
cout << a[i] << ' ';
}
cout << endl;
}
三、计数排序算法的分析
我们根据上面的代码,不难算出计数排序的算法复杂度:这里取值k=8,因为是[0,7],输入元素个数为n=10,所以,O(k)+O(n)+O(k)+O(n)=O(k+n),而当k=O(n)时,整个时间复杂度为O(n)。
可以发现,计数排序的时间复杂度比比较排序最坏情况下的复杂度nlgn要好,但是计数排序的应用范围要窄。
计数排序的另外一个重要性质就是它是稳定的,也就是说对于数组中相同的值的元素而言,先输入的元素在排序之后也在前,而后输入的元素在后;这一性质是由输入排序数组到b[n]中,采用从大到小循环,且循环一次进行一次c[a[i]--]来保证的,让后输入的元素排在序号比较大的位置。计数排序经常会被用作基数排序算法的一个子过程,而在这其中,要求计数排序必须是稳定的。














 7124
7124











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









