







lucene中的同步机制(lucene locking mechanism)及规则(Concurrency rules)
1、多个只读操作都可以并发,可以是多线程的或者是平行的搜索同一个索引。
2、当索引文件被改变的时候,只读操作同样支持并发。也就是说当你优化索引或者是往索引中添加或者是更新删除索引中的documents,只读操作仍然是允许的(可以继续search)。
3、同一时间只允许一个读写操作。索引在同一时间只能被一个IndexWriter或者IndexReader所打开。
下图是可以当有IndexWriter或者IndexReader在使用的时候可以执行的操作的表格,X号的表示不能执行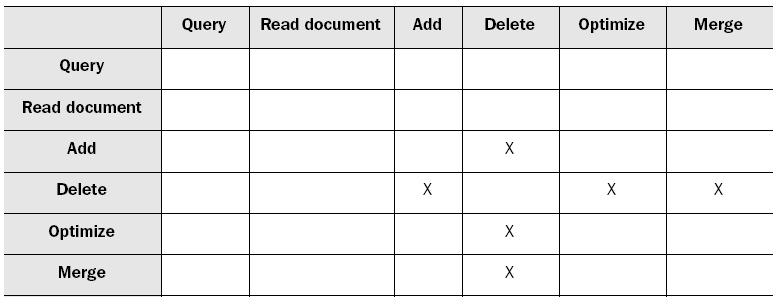
从上面的表格可以看出对索引进行操作是不会终止查询和读取索引的,但在实际使用中会影响到查询的效率。如何有线程在不段的做增量索引的话可以将IndexWriter的mergeFactor和maxBufferedDocs的值设置的大些,这样会降低io操作并且不会频繁的merge,另外可以自定义optimize的时间,保证search的效率。
指定lock文件存放位置
lucene中lock files的默认是由java.io.tempdir的系统属性来制定的。通常linux下是在/tem/,window下是在C:/Documents and Settings//Local Settings/Temp下。
我们可以通过java -Dorg.apache.lucene.lockDir=<% path %> 来制定lock files的存放位置。
lucene目前有write.lock和commit.lock两种。
write.lock是在对索引文件进行修改的时候生成的,这个时候IndexWriter的操作或者IndexReader 删除Documents, 取消删除都会抛出异常。
commit.lock是在segments文件被读取或者合并的时候生成的。当IndexReader 读取索引文件之前会获得commit.lock,当segments被读取完毕的时候会释放。IndexWriter在添加文档或者合并索引的时候同样会获得commit.lock
可以用IndexReader的 isLocked来判读索引文件是否被锁,或者unlock方法来解锁
|
| isLocked(String directory) |
|
|
|















 2500
2500

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









