






oracle中rowid和rownum的案例
我就直接po截图和代码
图1:

图2:
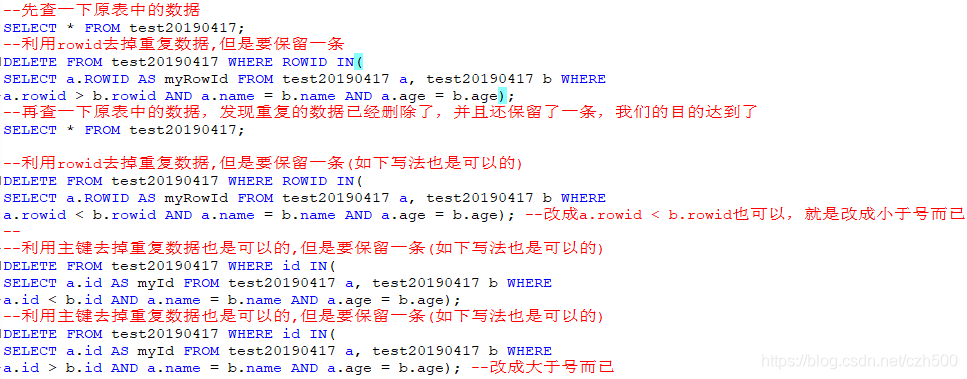
图3:
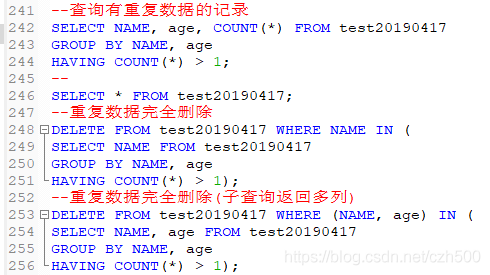
图4:

图5:
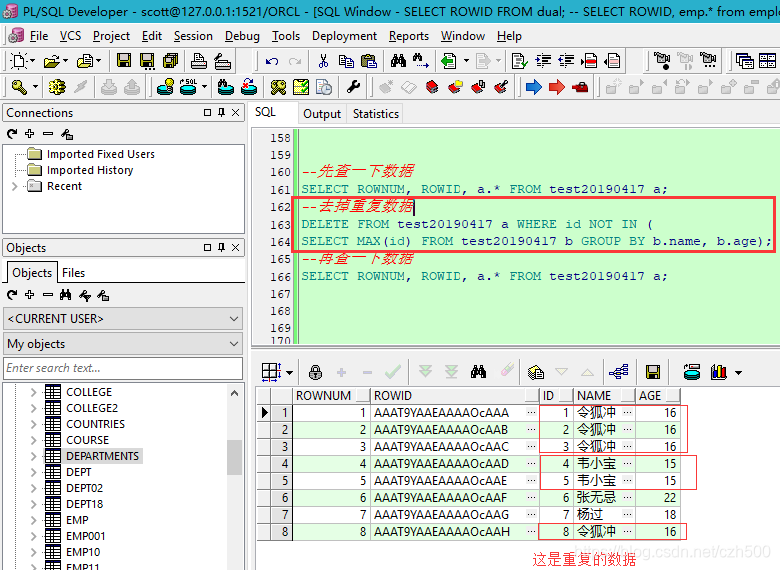
图6:
下面po代码
/*
Oracle学习笔记(rownum和rowid)
rownum和rowid都是伪列(准确来说,ROWID应该不算伪列,因为它实
际上是存在的),但是两者的根本是不同的,
rownum是根据sql查询出的结果给每行分配一个逻辑编号,rownum可以理解为行号
所以你的sql不同也就会导致最终rownum不同,
但是rowid是物理结构上的,在每条记录insert到数据库中时,
都会有一个唯一的物理记录
*/
/*
ROWNUM伪列
可以这么理解ROWNUM,
ROWNUM是伪列,该伪列在表中本身是不存在,只是在查
询的时候,是根据查询结果集而产生的一个"伪数列",
在Oracle中,我们分页的时候可以使用ROWNUM
*/
--使用ROWNUM伪列
--查到1条记录
SELECT ROWNUM, DEPARTMENTS.* FROM SCOTT.DEPARTMENTS WHERE ROWNUM = 1;
--查到0条记录
SELECT ROWNUM, DEPARTMENTS.* FROM SCOTT.DEPARTMENTS WHERE ROWNUM = 2;
--查到2条记录
SELECT ROWNUM, DEPARTMENTS.* FROM SCOTT.DEPARTMENTS WHERE ROWNUM < 3;
--查到0条记录
SELECT ROWNUM, DEPARTMENTS.* FROM SCOTT.DEPARTMENTS WHERE ROWNUM > 1;
--查到表中所有记录(查到28条记录)
SELECT ROWNUM, DEPARTMENTS.* FROM SCOTT.DEPARTMENTS WHERE ROWNUM > 0;
--查到28条记录
SELECT ROWNUM, DEPARTMENTS.* FROM SCOTT.DEPARTMENTS;
--
SELECT ROWNUM, DEPARTMENTS.* FROM SCOTT.DEPARTMENTS;
--查询前5条记录
select ROWNUM, employees.* from employees where
salary > 12000 and ROWNUM <= 5;
select ROWNUM, employees.* from employees where
salary > 12500 and ROWNUM <= 8;
/*
在Oracle数据库中,利用ROWNUM来分页
注意:分页关键字各种数据库不一样
Mysql数据库分页使用limit关键字
sqlServer数据库分页使用top关键字
*/
SELECT ROWNUM, emp.* from employees emp;
--取第5到第10条记录
SELECT myEmp.tempId, myEmp.* from (SELECT ROWNUM tempId, emp.* from employees emp) myEmp
WHERE myEmp.tempId >=5 and myEmp.tempId <10;
--取第5到第10条记录
SELECT emp.tempId, emp.* from (SELECT ROWNUM tempId, emp.* from employees emp) emp
WHERE emp.tempId BETWEEN 5 and 10; --BETWEEN AND 包含边界
--以上两种写法都可以,任选一种即可
/*
Oracle中的rownum不能使用大于>的问题
可以参考网页https://www.cnblogs.com/java0819/archive/2011/08/03/2146205.html
因为rownum总是从1开始的,第一条不满足去掉的话,第
二条的rownum 又成了1。依此类推,所以永远没有满足条件的记录。
可以这样理解:rownum是一个序列,是Oracle数据库从数据文件或缓冲区中读取数据的顺序。
它取得第一条记录则rownum值为1,第二条为2。依次类推。
当使用“>、>=、=、between...and”这些条件时,从缓冲区或数据文件中得到的第一条记
录的rownum为1,不符合sql语句的条件,会被删除,接着取下条。
下条的rownum还会是1,又被删除,依次类推,便没有了数据。
*/
/*
Oracle对rownum的处理:
rownum是在得到结果集的时候产生的,用于标记结果集中结果顺序的一个字段,
这个字段被称为“伪数列”,也就是事实上不存在的一个数列。
它的特点是按顺序标记,而且是逐次递加的,
换句话说就是只有有rownum=1的记录,才可能有rownum=2的记录
*/
/*
注意:
对 ROWNUM 只能使用 < 或 <=, 而用 =, >, >= 都将不能返回任何数据,当
然啦,你如果=1的话,是可以返回数据的
(ROWNUM可以理解成一个伪列,如果把伪列变成一个真实的列就可以使用>、=、>=了)
*/
/*
ROWID知识点
ROWID的作用:由于ROWID用来唯一标识表中数据的唯一性,所以可以利用这个特性去除重复
很显然,如果表中的数据有重复的,但是ROWID肯定是不会重复的,那么就可以利用这个特性去重
*/
--
SELECT ROWID FROM dual;
--
SELECT ROWID, emp.* from employees emp;
/*
可以利用rowid来查询记录,而且通过rowid查询记录是查询速度最快的查询方法。
(这个我没有试过,另外要记住一个长度在18位,而且没有太明显规律的字
符串是一个很困难的事情,所以我个人认为利用rowid查询记录的实用性不是很大)
*/
SELECT ROWID, emp.* from employees emp WHERE ROWID = 'AAASNeAAEAAAAJbAAF';
/*
如下演示ROWID案例
ROWID可以用来去掉重复的数据(去重),当然啦,ROWID还
有其他的功能,可以自己去查阅oracle的相关api文档
*/
--创建一张测试表
CREATE TABLE test20190417(
id number not null,
name VARCHAR2(50) not null,
age NUMBER not null
);
--插入数据(故意插几条重复的数据,方便后面我们做测试)
INSERT INTO test20190417(id, name, age) VALUES(1, '令狐冲', 16);
INSERT INTO test20190417(id, name, age) VALUES(2, '令狐冲', 16);
INSERT INTO test20190417(id, name, age) VALUES(3, '令狐冲', 16);
INSERT INTO test20190417(id, name, age) VALUES(4, '韦小宝', 15);
INSERT INTO test20190417(id, name, age) VALUES(5, '韦小宝', 15);
INSERT INTO test20190417(id, name, age) VALUES(6, '张无忌', 22);
INSERT INTO test20190417(id, name, age) VALUES(7, '杨过', 18);
INSERT INTO test20190417(id, name, age) VALUES(8, '令狐冲', 16);
/*
小知识点(小注意点):
ORACLE中,如果表中的字段名,正好跟sql中关键字重名,写sql语句时要注意:
1.要将该字段名大写
2.字段名两边要加双引号(注:必须是双引号,单引号将无效)
但是在mysql数据库中是使用`着重号(注意是数字键1旁边的反引号`)
如下sql语句
*/
--字段名大写并在两边加上双引号
SELECT "NAME", age , MAX(t.ID) from test20190417 t group by "NAME",age;
--如下,小写加双引号的写法会报错,必须是大写加双引号才可以
--SELECT "name", age , MAX(t.ID) from test20190417 t group by "name",age;
--如下写法也可以
SELECT name, age , MAX(t.ID) from test20190417 t group by name,age;
--如下写法也可以
SELECT NAME, age , MAX(t.ID) from test20190417 t group by NAME,age;
/*
需求:去掉test20190417表中重
复的数据(test20190417表中只要name和age这2个字
段的值一样就认为是重复的数据)即根据name和age这2个字段去重
删除重复数据分两种情况:
情况1:重复数据完全删除
情况2:删除重复数据,但是要保留一条
根据你自己的具体需求,选择两种情况中的一种
去掉重复数据,有两种方法
*/
--方法1
/*
步骤1:创建一张testTemp临时表,把test20190417原
表中的数据插入到testTemp临时表中(注意:原
表中根据name, age这两个字段去重后再插入数据到临时表中)
如下:
*/
--步骤1:
create table testTemp as
SELECT a.* from test20190417 a where a.id in (
select max(b.id) --这里也可以换成min(b.id),效果是一样的
from test20190417 b
where a.name = b.name
and a.age = b.age);
--子查询返回多列
--select * from test20190417 where (name, age) in (SELECT distinct name, age from test20190417);
--查询一下testTemp临时表
select * from testTemp;
--查询一下原表
select * from test20190417;
--步骤2:清空原表记录
truncate table test20190417;
--再查询一下原表,发现原表中的数据已经都清空了
select * from test20190417;
--步骤3:将临时表中的数据插回原表中
insert into test20190417 select * from testTemp;
--此时再查询一下原表,发现去重的目的已经达到了
select * from test20190417;
/*
当然啦,此时我们可以把临时表给drop删除掉,反
正此时testTemp临时表已然没有任何利用价值了
*/
--步骤4:drop删除掉临时表
DROP TABLE testTemp;
/*
ROWID知识点:
ROWID应该不算伪列,因为它是实际存在的
*/
/*
如下摘自网络
oracle还提供了另外一个伪数列:rowid
rowid和rownum不同,一般说来每一行数据对应的rowid是固定而且唯一的
在这一行数据存入数据库的时候就确定了。
可以利用rowid来查询记录,而且通过rowid查询记录是查询速
度最快的查询方法。(这个我没有试 过,另外要记住一个长度在18位,而且没有太明显规
律的字符串是一个很困难的事情,所以我个人认为利用rowid查询记录的实用性不
是很大)
rowid只有在表发生移动(比如表空间变化,数据导入/导出以后),才会发生变化
可以把rowid理解成java中的对象的内存地址
*/
--方法2,我们可以使用ROWID来去重
--
--先看看ROWID长什么样子
SELECT ROWID, ROWNUM, test20190417.* FROM test20190417;
--
SELECT a.ROWID, b.ROWID, a.*, b.* FROM test20190417 a,test20190417 b WHERE a.ROWID > b.rowid
and a.name = b.name and a.age = b.age;
--查询有重复数据的记录
SELECT NAME, age, COUNT(*) FROM test20190417
GROUP BY NAME, age
HAVING COUNT(*) > 1;
--
SELECT * FROM test20190417;
--重复数据完全删除
DELETE FROM test20190417 WHERE NAME IN (
SELECT NAME FROM test20190417
GROUP BY NAME, age
HAVING COUNT(*) > 1);
--重复数据完全删除(子查询返回多列)
DELETE FROM test20190417 WHERE (NAME, age) IN (
SELECT NAME, age FROM test20190417
GROUP BY NAME, age
HAVING COUNT(*) > 1);
--
SELECT ROWID, ROWNUM, test20190417.* FROM test20190417;
--执行下面的sql语句,观察一下查到的结果,就明白了
SELECT a.ROWID AS rowid1, a.*, b.ROWID AS rowid2, b.* FROM test20190417 a, test20190417 b WHERE
a.rowid > b.rowid AND a.name = b.name AND a.age = b.age;
--执行下面的sql语句,观察一下查到的结果,就明白了
SELECT a.ROWID AS rowid1, a.*, b.ROWID AS rowid2, b.* FROM test20190417 a, test20190417 b WHERE
a.rowid < b.rowid AND a.name = b.name AND a.age = b.age;
--其实也可以用主键,执行下面的sql语句,观察一下查到的结果,就明白了
SELECT a.ROWID AS rowid1, a.*, b.ROWID AS rowid2, b.* FROM test20190417 a, test20190417 b WHERE
a.id > b.id AND a.name = b.name AND a.age = b.age;
--执行下面的sql语句,观察一下查到的结果,就明白了
SELECT * FROM test20190417 WHERE ROWID IN(
SELECT a.ROWID AS myRowId FROM test20190417 a, test20190417 b WHERE
a.rowid > b.rowid AND a.name = b.name AND a.age = b.age);
--执行下面的sql语句,观察一下查到的结果,就明白了
SELECT a.ROWID AS myRowId FROM test20190417 a, test20190417 b WHERE
a.rowid > b.rowid AND a.name = b.name AND a.age = b.age
--执行下面的sql语句,观察一下查到的结果,就明白了
SELECT a.ROWID AS myRowId, a.* FROM test20190417 a, test20190417 b WHERE
a.rowid > b.rowid AND a.name = b.name AND a.age = b.age
--执行下面的sql语句,观察一下查到的结果,就明白了
SELECT * FROM test20190417 WHERE ROWID NOT IN(
SELECT a.ROWID AS myRowId FROM test20190417 a, test20190417 b WHERE
a.rowid > b.rowid AND a.name = b.name AND a.age = b.age);
--执行下面的sql语句,观察一下查到的结果,就明白了
SELECT * FROM test20190417 WHERE ROWID IN(
SELECT a.ROWID AS myRowId FROM test20190417 a, test20190417 b WHERE
a.rowid > b.rowid AND a.name = b.name AND a.age = b.age);
--先查一下原表中的数据
SELECT * FROM test20190417;
--利用rowid去掉重复数据,但是要保留一条
DELETE FROM test20190417 WHERE ROWID IN(
SELECT a.ROWID AS myRowId FROM test20190417 a, test20190417 b WHERE
a.rowid > b.rowid AND a.name = b.name AND a.age = b.age);
--再查一下原表中的数据,发现重复的数据已经删除了,并且还保留了一条,我们的目的达到了
SELECT * FROM test20190417;
--利用rowid去掉重复数据,但是要保留一条(如下写法也是可以的)
DELETE FROM test20190417 WHERE ROWID IN(
SELECT a.ROWID AS myRowId FROM test20190417 a, test20190417 b WHERE
a.rowid < b.rowid AND a.name = b.name AND a.age = b.age); --改成a.rowid < b.rowid也可以,就是改成小于号而已
--
--利用主键去掉重复数据也是可以的,但是要保留一条(如下写法也是可以的)
DELETE FROM test20190417 WHERE id IN(
SELECT a.id AS myId FROM test20190417 a, test20190417 b WHERE
a.id < b.id AND a.name = b.name AND a.age = b.age);
--利用主键去掉重复数据也是可以的,但是要保留一条(如下写法也是可以的)
DELETE FROM test20190417 WHERE id IN(
SELECT a.id AS myId FROM test20190417 a, test20190417 b WHERE
a.id > b.id AND a.name = b.name AND a.age = b.age); --改成大于号而已
--
--先查一下原表中的数据
SELECT ROWNUM, ROWID, t.* FROM test20190417 t;
SELECT ROWID, ROWNUM, test20190417.* FROM test20190417;
--执行下面的sql语句,观察一下查到的结果,就明白了
SELECT MAX(a.ROWID), MIN(a.ROWID), MAX(b.ROWID), MIN(b.ROWID) FROM test20190417 a,
test20190417 b WHERE a.name = b.name AND a.age = b.age;
--执行下面的sql语句,观察一下查到的结果,就明白了
SELECT a.ROWID, a.*, b.ROWID, b.* FROM test20190417 a,
test20190417 b WHERE a.name = b.name AND a.age = b.age;
--执行下面的sql语句,观察一下查到的结果,就明白了
SELECT MAX(a.id), MIN(a.id), MAX(b.id), MIN(b.id) FROM test20190417 a,
test20190417 b WHERE a.name = b.name AND a.age = b.age;
--执行下面的sql语句,观察一下查到的结果,就明白了
SELECT ROWID, a.* FROM test20190417 a WHERE ROWID IN
(SELECT MAX(b.ROWID) FROM test20190417 b WHERE a.name = b.name AND a.age = b.age);
--执行下面的sql语句,观察一下查到的结果,就明白了
SELECT * FROM test20190417 a WHERE ROWID IN
(SELECT MAX(b.ROWID) FROM test20190417 b WHERE a.name = b.name AND a.age = b.age);
--执行下面的sql语句,观察一下查到的结果,就明白了
SELECT * FROM test20190417 a WHERE ROWID NOT IN
(SELECT MAX(ROWID) FROM test20190417 b WHERE a.name = b.name AND a.age = b.age);
--执行下面的sql语句,观察一下查到的结果,就明白了
SELECT * FROM test20190417 a WHERE ROWID IN
(SELECT MIN(ROWID) FROM test20190417 b WHERE a.name = b.name AND a.age = b.age);
--执行下面的sql语句,观察一下查到的结果,就明白了
SELECT * FROM test20190417 a WHERE ROWID NOT IN
(SELECT MIN(b.ROWID) FROM test20190417 b WHERE a.name = b.name AND a.age = b.age);
--其实也可以使用主键
SELECT * FROM test20190417 a WHERE id IN
(SELECT MIN(id) FROM test20190417 b WHERE a.name = b.name AND a.age = b.age);
--
SELECT * FROM test20190417 a WHERE id NOT IN
(SELECT MIN(b.id) FROM test20190417 b WHERE a.name = b.name AND a.age = b.age);
--
SELECT * FROM test20190417 a WHERE id IN
(SELECT MAX(b.id) FROM test20190417 b WHERE a.name = b.name AND a.age = b.age);
--
SELECT * FROM test20190417 a WHERE id NOT IN
(SELECT MAX(id) FROM test20190417 b WHERE a.name = b.name AND a.age = b.age);
/*
由于ROWID用来唯一标识表中数据的唯一性,所以可以利用这个特性去除重复
很显然,如果表中的数据有重复的,但是ROWID肯定是不会重复的,那么就可以利用这个特性去重
*/
/*
利用rowid去掉重复数据还有其他的写法
如下:
*/
--先查一下原表中的数据
SELECT ROWNUM, ROWID, t.* FROM test20190417 t;
/*
利用rowid去掉重复数据,但是要保留一条(如下写法也是可以的)
*/
--注意:使用not IN 效率是很低的, not是不带索引的
--使用min()和max()效果是一样的,任选一个都可以
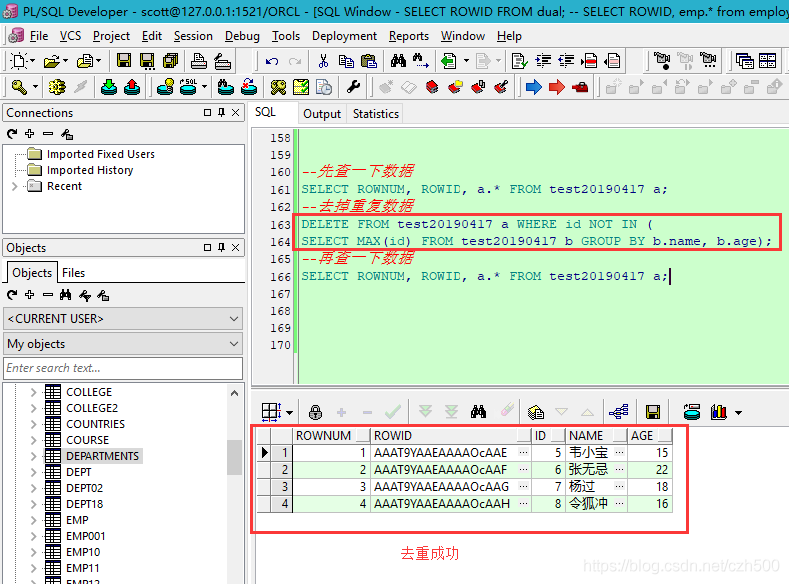
DELETE FROM test20190417 a WHERE ROWID NOT IN (
SELECT MIN(b.ROWID) FROM test20190417 b WHERE a.name = b.name AND a.age = b.age);
--使用max()
DELETE FROM test20190417 a WHERE ROWID NOT IN (
SELECT MAX(ROWID) FROM test20190417 b WHERE a.name = b.name AND a.age = b.age);
--使用主键的写法也是可以的,如下:
DELETE FROM test20190417 a WHERE id NOT IN (
SELECT MIN(id) FROM test20190417 b WHERE a.name = b.name AND a.age = b.age);
--使用max()
DELETE FROM test20190417 a WHERE id NOT IN (
SELECT MAX(id) FROM test20190417 b WHERE a.name = b.name AND a.age = b.age);
--利用rowid去掉重复数据,但是要保留一条,使用分组的写法也是可以的
--先查一下原表中的数据
SELECT ROWNUM, ROWID, t.* FROM test20190417 t;
--使用rowid和分组去重
DELETE FROM test20190417 a WHERE ROWID NOT IN (
SELECT MAX(ROWID) FROM test20190417 b GROUP BY b.name, b.age);
--使用rowid和分组去重
DELETE FROM test20190417 a WHERE ROWID NOT IN (
SELECT MIN(ROWID) FROM test20190417 b GROUP BY b.name, b.age);
--使用主键和分组去重
DELETE FROM test20190417 a WHERE id NOT IN (
SELECT MAX(id) FROM test20190417 b GROUP BY b.name, b.age);
--使用主键和分组去重
DELETE FROM test20190417 a WHERE id NOT IN (
SELECT MIN(id) FROM test20190417 b GROUP BY b.name, b.age);















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









