







这是一篇关于 Kafka 实践的文章,内容来自 DataWorks Summit/Hadoop Summit(Hadoop Summit)上的一篇分享,里面讲述了很多关于 Kafka 配置、监控、优化的内容,绝对是在实践中总结出的精华,有很大的借鉴参考意义,本文主要是根据 PPT 的内容进行翻译及适当补充。
Kafka 的架构这里就不多做介绍了,直接步入正题。
Kafka 基本配置及性能优化
这里主要是 Kafka 集群基本配置的相关内容。
硬件要求
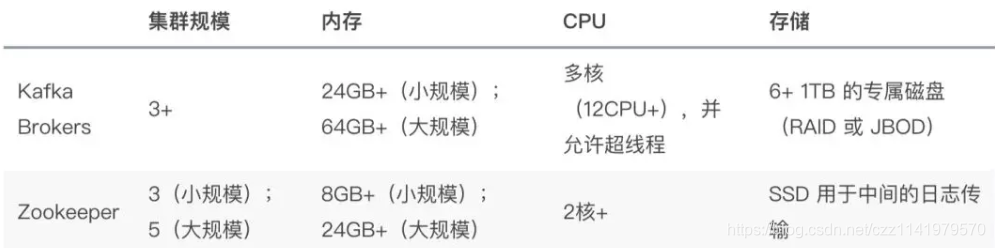
Kafka 集群基本硬件的保证
OS 调优
OS page cache:应当可以缓存所有活跃的 Segment(Kafka 中最基本的数据存储单位);
fd 限制:100k+;
禁用 swapping:简单来说,swap 作用是当内存的使用达到一个临界值时就会将内存中的数据移动到 swap 交换空间,但是此时,内存可能还有很多空余资源,swap 走的是磁盘 IO,对于内存读写很在意的系统,最好禁止使用 swap 分区;
TCP 调优
JVM 配置
JDK 8 并且使用 G1 垃圾收集器
至少要分配 6-8 GB 的堆内存
Kafka 磁盘存储
使用多块磁盘,并配置为 Kafka 专用的磁盘;
JBOD vs RAID10;
JBOD(Just a Bunch of Disks,简单来说它表示一个没有控制软件提供协调控制的磁盘集合,它将多个物理磁盘串联起来,提供一个巨大的逻辑磁盘,数据是按序存储,它的性能与单块磁盘类似)
JBOD 的一些缺陷:
任何磁盘的损坏都会导致异常关闭,并且需要较长的时间恢复;
数据不保证一致性;
多级目录;
社区也正在解决这么问题,可以关注 KIP 112、113:
必要的工具用于管理 JBOD;
自动化的分区管理;
磁盘损坏时,Broker 可以将 replicas 迁移到好的磁盘上;
在同一个 Broker 的磁盘间 reassign replicas;
RAID 10 的特点:
可以允许单磁盘的损坏;
性能和保护;
不同磁盘间的负载均衡;
高命中来减少 space;
单一的 mount point;
文件系统:
使用 EXT 或 XFS;
SSD;
基本的监控
Kafka 集群需要监控的一些指标,这些指标反应了集群的健康度。
CPU 负载;
Network Metrics;
File Handle 使用;
磁盘空间;
磁盘 IO 性能;
GC 信息;
ZooKeeper 监控。
Kafka replica 相关配置及监控
Kafka Replication
-
Partition 有两种副本:Leader,Follower;
- <
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 1755
1755











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









