










爱情公寓大电影已经上映两周了,这种包含十年情怀的超级大IP,上映前就充斥着各种争议,上映后更是议论不断,差评如潮。首日票房超过3亿元,接着豆瓣评分2.6,火爆的票房和低下的评分,形成了强烈的对比,这种充斥着强烈矛盾的神剧,作为十年粉丝的小文,今天也来八一八爱情公寓大电影的是是非非。
一、数据获取
#requests + json
import requests
import json
import time
import jieba
import pandas as pd
import matplotlib.pyplot as plt
from wordcloud import WordCloud,STOPWORDS,ImageColorGenerator
from pyecharts import Line, Geo, Bar,Pie,Overlap,configure
#数据获取
data = pd.DataFrame(columns = ['date','nick','userlevel','city','score','comment','approve'])
for i in range(1,1001):
time.sleep(2)
print('正在爬取第{}页'.format(i))
url = 'http://m.maoyan.com/mmdb/comments/movie/1175253.json?_v_=yes&offset=' + str(i)
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3493.3 Safari/537.36'}
res = requests.get(url = url,headers = headers).content
page = json.loads(res.decode('utf-8'))['cmts']
for n in page:
data = data.append({'date':n['time'].split(' ')[0], 'city':n['cityName'],'score':n['score'],'comment':n['content'],'nick':n['nickName'], 'approve':n['approve'],'userlevel':n['userLevel']},ignore_index=True)
data.to_csv('ipartment.csv')
通过猫眼API爬取了《爱情公寓大电影》的短评,其一天的数据量只有1000页,所以offset取值范围为1:1000。另外,小文只爬取了20号与26号这两天的数据进行分析。(要是各位看官觉得数据量少了点的话,可以每天爬取一次数据,爬几天再分析,因为猫眼只保留一天的数据)
#读取数据
data = pd.read_csv('ipartment.csv')
print('去重前:',data.shape)
data.head()
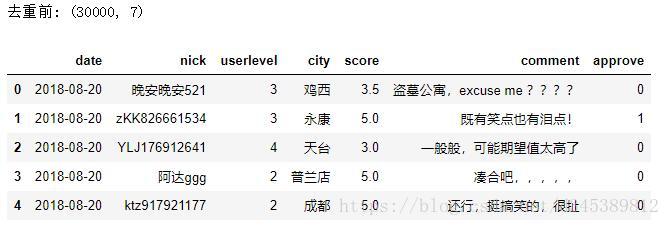
爬取的数据共有30000条,不确定是否有重复,因此先以评论者的昵称进行去重。去重过后发现city有两个缺失值,直接删除,处理后,只剩下1932条数据。。。这感觉也太坑爹了吧,十分之一都没有!!我忍!!!!
#去重
newdata = data.drop_duplicates(['nick'])
newdata.info()
#处理空值
newdata = newdata.dropna(how = 'any')
print('处理后:',newdata.shape)

二、数据分析
本文主要是使用pyecharts进行可视化分析,也算是对pyecharts的实践。
1、评论人群账号等级分布及评分分布
userlevel = newdata.groupby(['userlevel'])['score'].agg(['mean','count'])
userlevel.reset_index(inplace = True)
userlevel['mean'] = round(userlevel['mean'], 1)
bar = Bar('评论人群等级分布及评分分布',background_color = 'white')
bar.add('等级分布',userlevel['userlevel'],userlevel['count'],is_label_show = True,is_splitline_show= False,xaxis_name = '评论人群等级',xaxis_name_size = 16)
line = Line()
line.add('评分分布',userlevel['userlevel'],userlevel['mean'],is_label_show = True, is_splitline_show= False,yaxis_max = 6,line_color='steelblue',line_width = 4)
overlap = Overlap()
overlap.add(bar)
overlap.add(line,yaxis_index=1, is_add_yaxis=True)
overlap.render(path = 'D:\\评论人群等级分布及评分分布.jpeg')
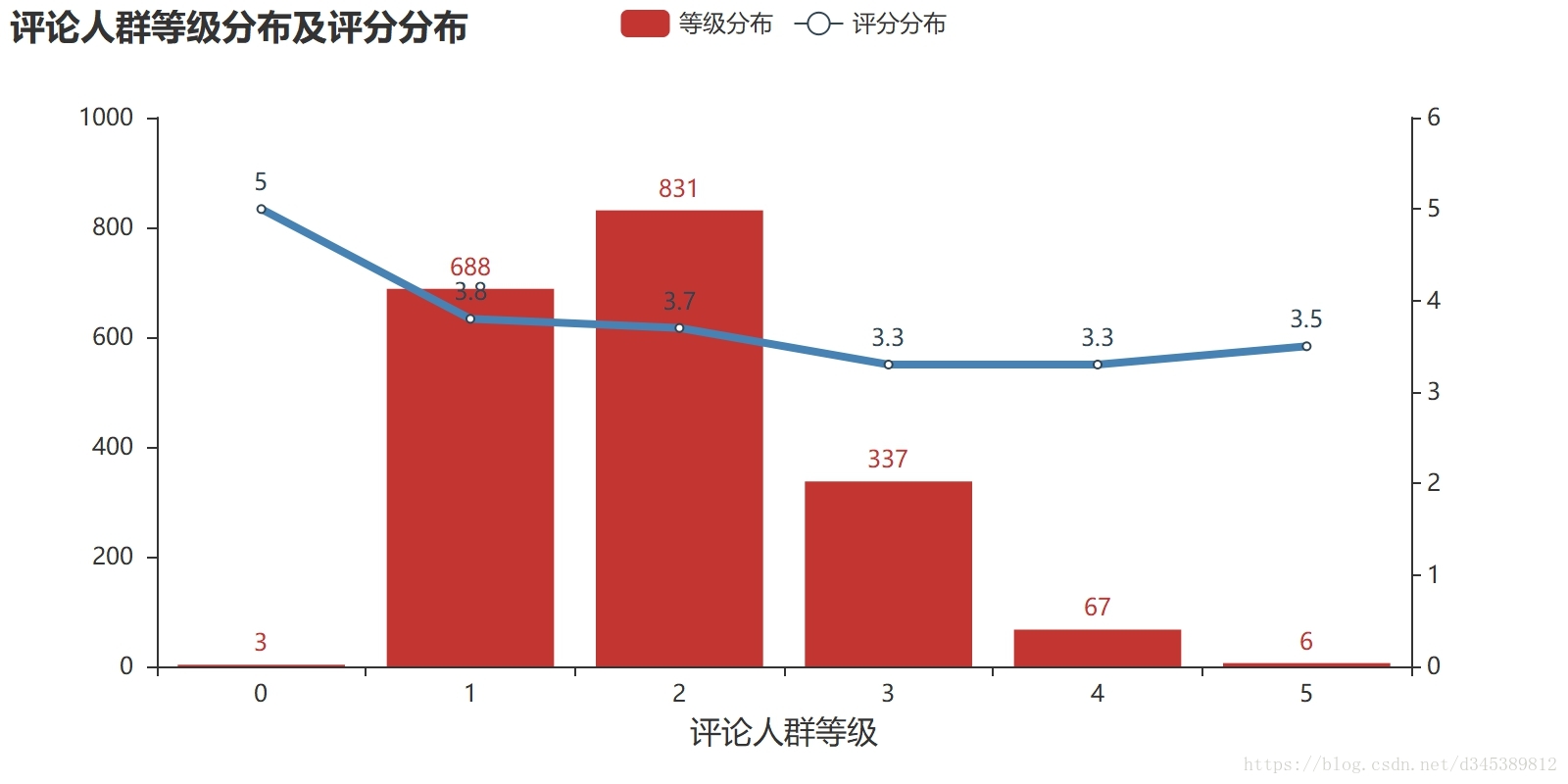
在处理了1932条数据后,我们可以得到爱情公寓大电影的平均得分是3.65,其中评论人群的账号等级主要集中在level1,level2与level3中,占据了总人数的96%,如果将level4与level5的评论人群定义为资深影迷的话,那么level3可以定义为进阶影迷,level1与level2为活跃影迷,level0为新影迷。(此定义是小文所创,如感觉不妥,自行忽略)
那么活跃影迷与进阶影迷给到的平均分分别为3.8,3.7,3.3,看其得分虽说算不上好看,但也不会太差。
2、评论人群账号等级与获赞数量的关系
userlevel1 = newdata.groupby(['userlevel'])['approve'].agg(['sum'])
userlevel1.reset_index(inplace = True)
pie = Pie('评论人群各等级获赞数量',background_color = 'white', title_pos='center')
pie.add( "", userlevel1['userlevel'],userlevel1['sum'], radius=[40, 75],label_text_color=None,is_label_show=True,legend_orient="vertical",legend_pos="left")
pie.render(path = 'D:\\评论人群各等级获赞数量.jpeg')
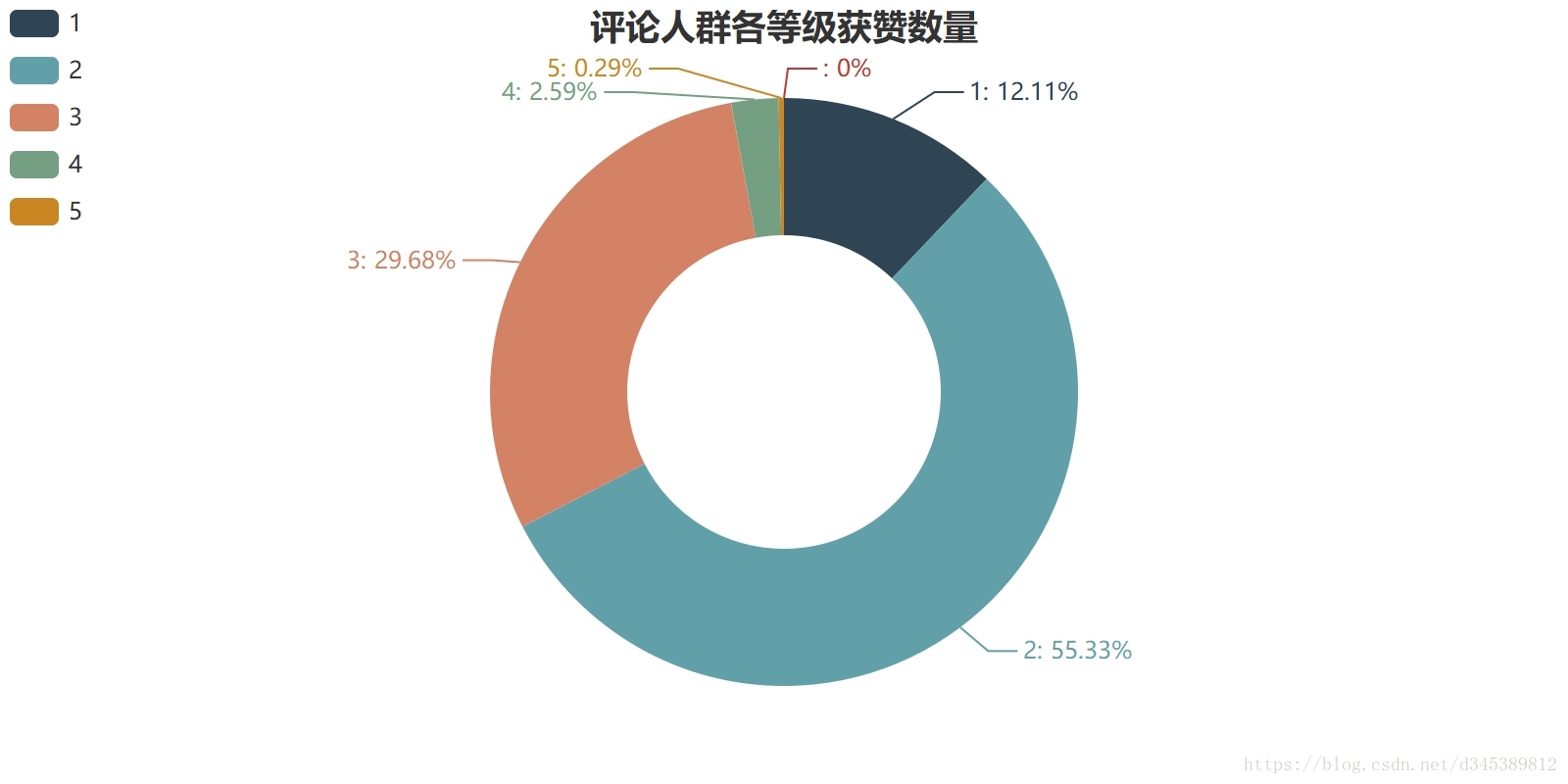
获赞的数量主要分布在活跃影迷以及进阶影迷中,占据了97%的获赞数量,也就意味着有更多的观看者赞同这些影迷的短评。这也很正常,毕竟评论人群中96%是在活跃影迷以及进阶影迷当中。其中活跃影迷获赞数量为67.44%,进阶影迷获赞数量为29.68%。
3、评论人群所在城市分布
city = newdata.groupby(['city'])['score'].agg(['mean','count'])
city.reset_index(inplace= True)
city['mean'] = round(city['mean'], 1)
city_map=[(city['city'][i],city['count'][i]) for i in range(0, city.shape[0])]
geo = Geo('评论人群的地理分布',title_color = 'white',background_color="#404a59")
while True:
try:
attr, value = geo.cast(city_map)
geo.add('',attr,value,visual_range=[0,60], visual_text_color= "#fff",symbol_size= 5, is_visualmap= True,is_piecewise= True,visual_split_number= 5)
except ValueError as ve:
ve = str(ve)
ve = ve.split( 'No coordinate is specified for ')[1]
for i in range(0,len(city)):
if ve in city_map[i]:
city_map.pop(i)
break
else:
break
geo.render(path = 'D:\\评论人群的地理分布.jpeg')
4、评论人群所在城市TOP10与评分分布
#筛选出TOP10城市
city_main = city.sort_values('count',ascending=False)[0:10]
bar = Bar('评论人群TOP10城市分布及评分',background_color = 'white')
bar.add('地理分布',city_main['city'],city_main['count'],is_label_show = True,is_splitline_show= False,xaxis_interval=0,xaxis_rotate=30)
line = Line()
line.add('评分分布',city_main['city'],city_main['mean'],is_label_show = True,is_splitline_show= False,yaxis_max = 5,line_color='steelblue',line_width = 4)
overlap = Overlap()
overlap.add(bar)
overlap.add(line,yaxis_index=1, is_add_yaxis=True)
overlap.render(path = 'D:\\评论人群TOP10城市分布及评分.jpeg')
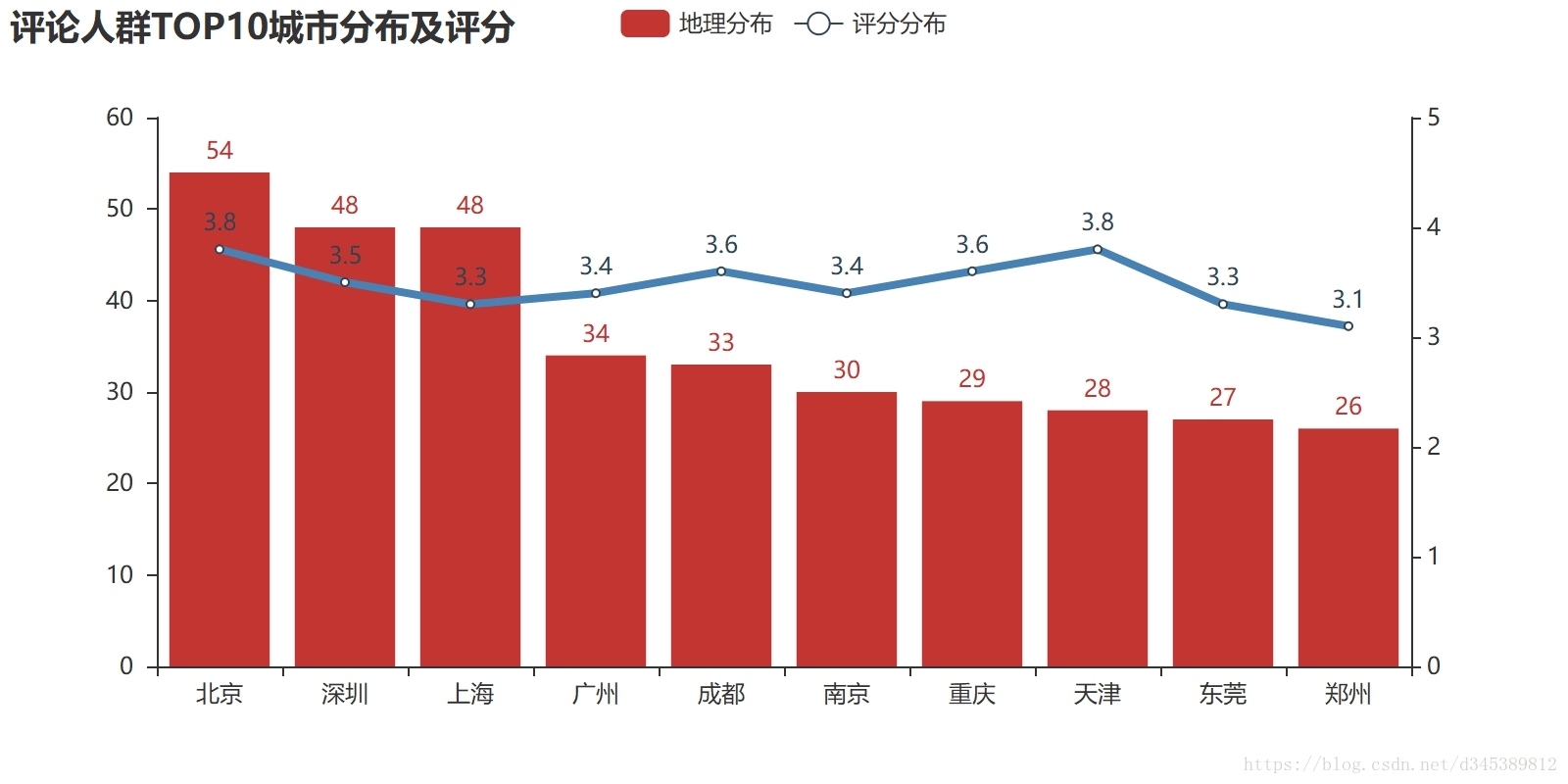
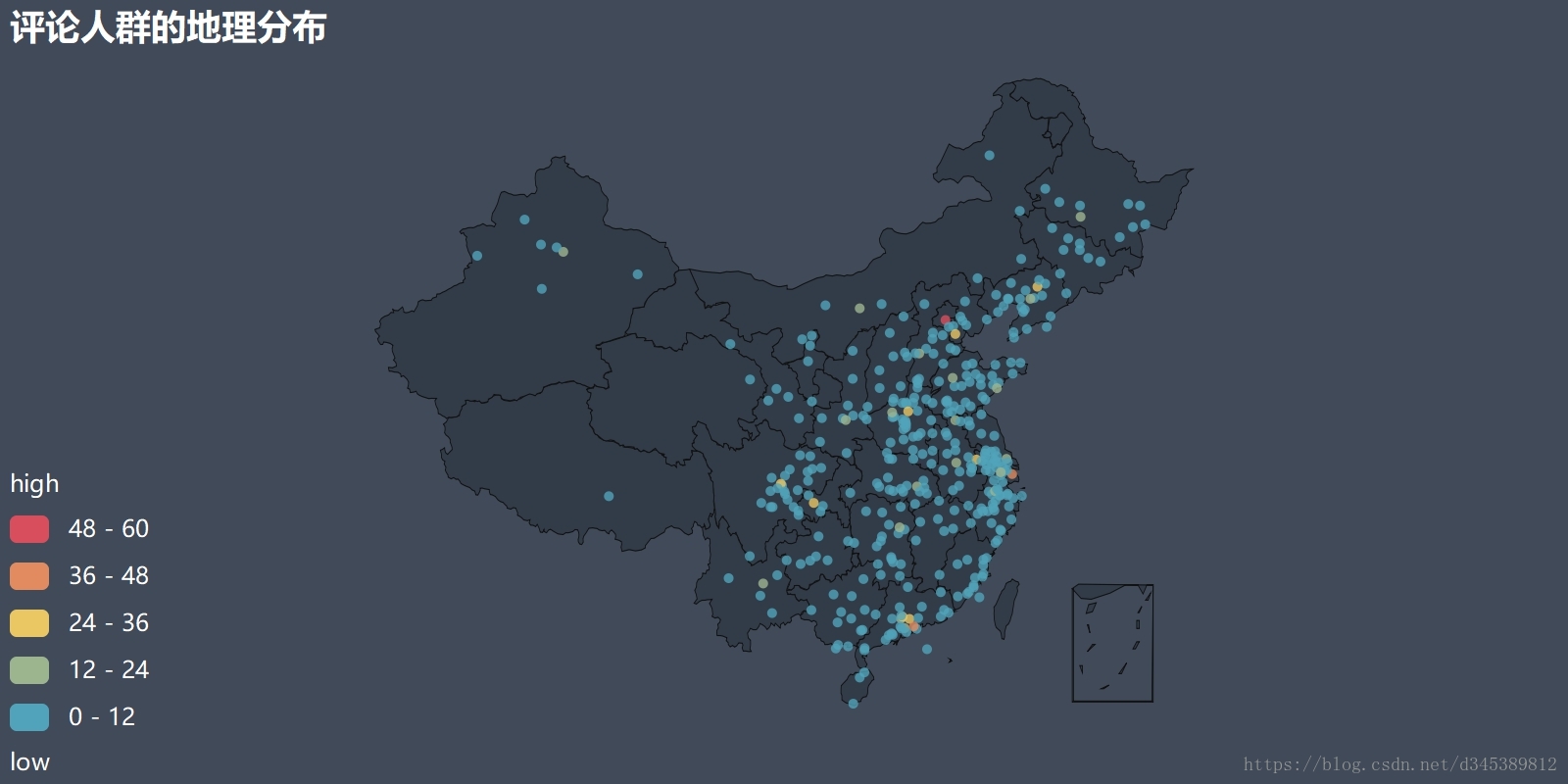
从上图可以看到,评论人群TOP5分别是北上广深成,这在上面的"评论人群的地理分布"图中可见红点与黄点,得分在3.8到3.3之间。
4、短评词云分析
#词云分析
def get_ciyun(data):
comment = jieba.cut(str(data['comment']),cut_all=False)
words = ' '.join(comment)
backgroud_Image = plt.imread('aixin.jpg')
stopwords = STOPWORDS.copy()
wc = WordCloud(width=1800,height=800,margin=2,background_color='white',mask=backgroud_Image,stopwords=stopwords,font_path='C:\Windows\Fonts\STZHONGS.TTF', max_words=100,max_font_size=250,random_state=30)
wc.generate(words)
plt.imshow(wc)
plt.axis('off')
wc.to_file('ciyun.jpg')
plt.show()
从上面的分析我们知道,短评集中在活跃影迷以及进阶影迷当中并且获赞数量也是如此,这意味着大家更认同活跃影迷以及进阶影迷的想法。因此接下来,我们将分开看看活跃影迷、进阶影迷以及整体的短评都说了些什么?
#筛选出活跃影迷与进阶影迷的数据集
newdata1 = newdata[(newdata['userlevel'] ==1) | (newdata['userlevel'] == 2)]
newdata2 = newdata[newdata['userlevel']== 3]
get_ciyun(newdata)
get_ciyun(newdata1)
get_ciyun(newdata2)

整体的短评关键词:好看,期待,还好,可以,不错,搞笑,回忆,盗墓,欺骗等等。

活跃影迷的短评关键词:好看,喜欢,期待,不错,失望,回忆,盗墓,欺骗,烂片等等。

进阶影迷的短评关键词:好看,可以,情怀,盗墓, 超烂, 失望等等。
总体来说,还是积极正面的词语比较多,所以总体评分在3.65分还是比较有代表性的。(前提是根据我们的1932条数据)
另外,活跃影迷对待《爱情公寓大电影》用的词是回忆,而进阶影迷用的是情怀,这样看来可能进阶影迷更加像是爱情公寓的忠实粉丝,例如小文就是其中一个。小文在首映当晚就看了这部电影,个人感觉还是很好看,毕竟是喜剧,喜剧给观众带来欢笑在我看来就是成功的了,虽然一开始小文也是认为《爱情公寓大电影》是爱情公寓的延续,甚至是大结局,但没想到会盗墓去了,真是无厘头,太搞笑了。电影的最后给了一个彩蛋,也是小文的期待 --"第五部爱情公寓coming soon",希望爱5能早点到来。














 628
628











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









