







翻译 | reason_W
编辑 | 胡永波
【AI科技大本营导读】深度学习优异的性能让其收到了很多人的追捧,但我们对其中的机制真的搞清楚了吗?近日,怼过LeCun的Google大牛Ali Rahimi通过类比光学领域的发展,提出了探索深度学习教学的新思路。文章提出对深度学习进行层次化的抽象,或许可以像高中教光学一样教授深度学习,非常有启发意义。
以下是全文翻译:
深度学习已经成熟到可以在高中进行学习的程度了吗?
对这个问题的思考源于我前段时间收到的一封电子邮件,它来自一家著名公司的产品经理。

“你是如何指导年轻的团队成员来测试预感或者产生直觉的?
我的团队中的工程师经常直接使用一些来自其他研究人员的超参数值,但他们对需要自己调整参数的任务却十分害怕”。
我对着这封电子邮件想了好几天,还是没有给出一个建设性的答案。
如果非要说句什么的话,我想回复说也许她的工程师本来就应该害怕。
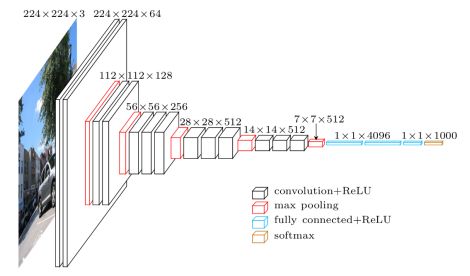
想象一下,你是一名工程师,现在给你这个网络,需要把这个网络在数据集上进行适配。你可能会认为这些层中的每一个存在都是有内在原因的。但就一个研究领域来说,我们还没有一个公认的术语来表述这些原因。我们教深度学习的方式与我们教授其他技术学科的方式截然不同。
几年前,我开始接触光学领域。在光学领域中,你也需要像深度学习一样构建一个处理输入的组件堆栈。下面是一个镜头的组件图。
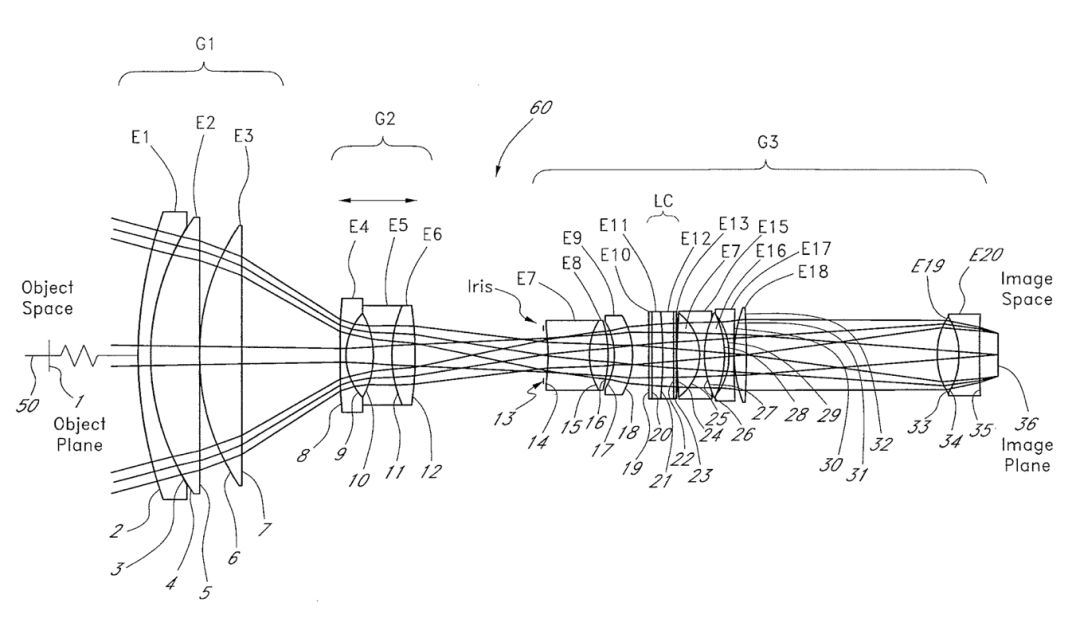
为了设计出一个这样的东西,你需要从基本的堆栈(通常会以发明它的著名人物命名)开始,进行模拟实验以找到那些达不到性能要求的情况,然后添加额外的部分来纠正这个缺点。
然后通过数字优化器运行这个系统来进行调参,如曲面的形状,位置和倾斜度,以最大化某些设计目标。然后,再次模拟,修改,优化,重复这一流程。
就像深度网络一样。
堆栈中的36个部分每一个都是专门添加以纠正某种类型的成像误差的。这就需要一个非常明确的思维模型,来确定每个部分对通过它的光线的作用。这种思维模型通常是根据某种行为,比如折射,反射,衍射,色散或波前进行校正。
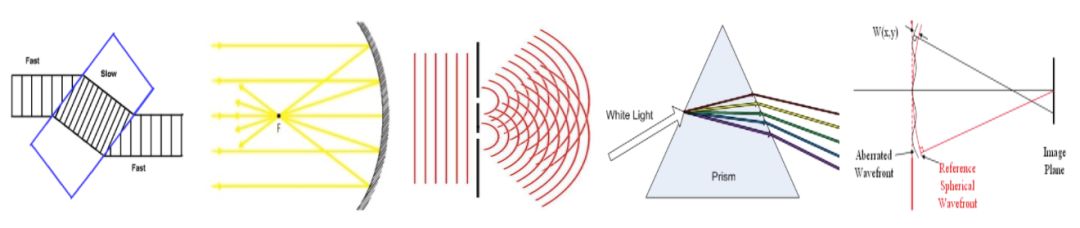
折射、反射、衍射、色散波阵面校正
人们并不害怕这个设计过程。每年,美国有数百名光学工程师毕业并继续从事镜头设计工作。他们并不害怕自己的工作。
这不是因为光学很容易,而是因为光学的思维模型组织得很好。现代光学是按照下面这样的抽象层来进行教导的。

最简单的一层是光线。射线光学是波动光学的简化,射线代表了波动光学中波前的法向矢量。波动光学是麦克斯韦方程的近似解。而麦克斯韦方程则可以从量子物理进行推导,我实际上并不了解这些推导。
这个金字塔的每一层都是通过简化假设从它下面的层中推导出来的。因此,每层都可以解释比上面一层更复杂的现象。

我设计系统的大部分功夫都花在这个金字塔级别最高的前四层上。
这就是今天进行光学教学的方法。但是这些理论并不是一直都像这样以堆栈的方式进行组织。直到一百年以前,这些理论中还有一些是以相互冲突的状态共存。从业者只能依靠一些光学的民间模型进行工作。

这并没有阻止伽利略在牛顿在提出射线光学的一百多年前,就建造一台相当不错的望远镜。伽利略对在光学领域如何构建一个可以放大10倍的望远镜有着非常好的思维模型。但他的理解还不足以指导他纠正色差,或获得广泛的视角。
在这些光学理论被统一进一个抽象金字塔模型之前,每一个理论都必须从光的基本概念开始推导。这涉及到一组新的不切实际的假设。牛顿提出的射线光学将光线模拟为可能被固体物质吸引或排斥的粒子雾。惠更斯将光模拟为纵向压力波,通过一种称为“以太”的神秘媒介进行传播。他把光像声波一样进行建模。麦克斯韦也假设光线通过以太传播。你还可以在麦克斯韦方程的系数名称中看到这个想法的痕迹。
▌原始但可量化具有预测性的模型
尽管这些假设今天可能听起来很愚蠢,但这些模型是具有量化能力以及预测能力的。你可以向其中代入数字,并获得数值化的预测。这对于工程师来说非常有用。
▌目标:一种用于描述深度学习每层行为的模块化语言
如果我们能够像谈论光线穿过光学元件时其元件的作用一样讨论深度学习每一层的作用,那么深度网络的设计工作就会十分容易。
我们通常把卷积层说成对输入进行滤波器匹配的部分,随后的池化层是用来进行非线性操作的。但这是一个相对较底层的描述,类似于用麦克斯韦方程描述镜头的作用。
或许还有更高层的抽象可以依赖,就拿通过网络中间层而被修改的变量而言,这就好像描述透镜在弯曲射线方面的作用。
如果这个抽象是定量的,那会更好,因为你可以在一个公式中代入数字来进行背后的分析,以帮助你设计网络。
▌我们要远离这种语言。就从简单的事情开始吧
我现在的思考正越来越天马行空。
就从简单的事情开始。我们有很多关于深度网络训练工作的思维模型。我也收集了一些值得解释的现象。让我们看看这些思维模型是如何解释这些现象的。
在走得太远之前,这样的设想肯定是要进行的。光学用了300年的时间来做到这一点。而我只花了一个星期六的下午。作为交换,我就只在博客上报告一下我的发现算了。
现象:对SGD一个随机初始化就够。但之后一些小的数值错误,或者错误的步长大小,都会使SGD的效果变差。
一些从业人员已经观察到梯度累计过程中的微小变化是怎样导致模型在测试集性能上出现太大差异的。例如,当你使用GPU而不是CPU进行训练时,就会出现这种情况。
你认为这是一个值得思考的合理观察吗?
或者你认为这是一个假的观察,这可能是不真实的?
也或者你认为这个观察有什么问题,就像是逻辑上的自相矛盾,或者是一个错误的说法?
我敢肯定,你们肯定有很多这些感觉,但现在让我把这个现象先记录下来,我们继续讨论。
现象:浅的局部最小值泛化性比深的值好。
这种说法很流行。有些人坚持说这是真的,而其他人,包括我自己,都认为在这逻辑上是不可能的。还有一些人则以经验为由驳斥了这一说法。还有一些人提供了这个说法的变体。这些混乱的说法仍然没有得到统一。
我注意到这个现象可能会有争议,但是请先记录下来。
现象:插入批量归一化层(Batch Norm layers)会加快SGD。
Batch Norm的作品大多是无可争议的。我只提供一个比较严重的例外,并将其记录为一个不确定的现象。
现象:尽管有许多局部最优点和鞍点,SGD仍然是有效的。
关于这一现象有很多说法。通常认为深度学习的训练损失面上充满了鞍点和局部最小值。此外,还有一种说法是,梯度下降可以解决这些风险,或者它不需要解决这些风险就能产生一个可以很好地泛化的解决方案。同样也有一些说法称,深度模型的损失面是完全良性的。
我勉强记录下这个现象。
现象:Dropout效果比其他随机化策略更好。
我不知道该把Dropout类的操作分到哪一类,所以暂且称之为“随机策略”。
记录下来,不讨论。
现象:深度网络可以记住随机的标签,然而将它们泛化
证据很清楚,并且得到了一些人的正式和支持。
我们把这个现象记录下来,尽管和我们的目的有点冲突。
▌解释
我们收集了一些现象。我也从上面提到的论文中收集了一些我认为有很大可能解释这些现象的理论。
先来看一下这些理论和现象的对应关系:

但是先不要高兴太早,这里还有几点需要我们考虑。
首先,我们对一些一开始我们就试图想要解释的观察结果并不赞同。
其次,我不能把这些解释分解成抽象层次。让光学变的易学的东西没有在这里体现出来。
第三,我怀疑我引用的一些理论是不正确的。
▌我的观点
现在有大量的新手正在涌入深度学习领域,我们也正在为他们配置更多的民间版本和预训练用的深度网络,然后要他们在此基础上进行创新。但如果我们智能像上文那样生硬地去解释那些现象的话,那我们距离为高中生教深度学习的阶段还相差很远。
那该怎么办呢?
如果我们能够在很多抽象层上提供深度网络层次的思维模型,那将是一件非常好的事。什么可能成为深度学习理论中跟折射、散射和衍射一样的概念呢?也许你已经开始从这样的角度进行思考了,但我们还远未能以这样概念为核心来统一深度学习的语言。
接下来我们要收集一系列得到普遍认同的现象。然后去试着解释它们。什么会是深度学习领域相当于牛顿环、克尔效应或者法拉第效应的定理呢?
现在有一些同事已经和我进行了大量的实证研究工作,对本领域中的思维模型进行分类,将其标准化,然后用实验对其进行验证。这方面还有很多工作要做。想要发展出一个可以在高中教授的深度学习的层次化思维模型,我认为这些工作是第一步。
如果你想对这个项目有兴趣,想要一起讨论或帮忙,可以在推特上联系我(https://twitter.com/beenwrekt/status/956621165161779200)。
作者 | Ali Rahimi,Google研究员,因2007年发表的一篇论文获得2017NIPS “Test of Time” 最具时间价值大奖
原文链接 | http://www.argmin.net/2018/01/25/optics/
新一年,AI科技大本营的目标更加明确,有更多的想法需要落地,不过目前对于营长来说是“现实跟不上灵魂的脚步”,因为缺人~~
所以,AI科技大本营要壮大队伍了,现招聘AI记者和资深编译,有意者请将简历投至:gulei@csdn.net,期待你的加入!
如果你暂时不能加入营长的队伍,也欢迎与营长分享你的精彩文章,投稿邮箱:suiling@csdn.net
如果以上两者你都参与不了,那就加入AI科技大本营的读者群,成为营长的真爱粉儿吧!后台回复:读者群,加入营长的大家庭,添加营长请备注自己的姓名,研究方向,营长邀请你入群。



☟☟☟点击 | 阅读原文 | 查看更多精彩内容














 1924
1924











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









