






Customer_List --会员资料表
Customerkey --会员编码 varchar2 不重复
storeid --会员所属门店编码 varchar2
customer_consumption --会员消费表
Customerkey --会员编码 varchar2
storeid --会员消费门店编码 varchar2
Createdate --会员消费日期 Date
需求:
会员归属门店,默认以第一次消费门店为会员归属门店
后续会员在最近三个月内连续就餐次数最高的门店,自动设为会员资料的归属门店
如果最高就餐次数不够4次(含4次) 以上的 ,不予以处理
注意点:
1. 最近三个月内连续就餐次数最高
2. 最高就餐次数不够4次(含4次) 以上的 ,不予以处理
分许:1 把最近三个月的消费记录完全取出来 ( 这边还要确定下 比如 5月2 号的记录 这里是指 3 4 5 ? 还要 2月2号到5月2号 )?
(题外话 如果是消费记录的 前三个月,那难度又添加了,如:现在 系统时间是 9月3日, 单现在要录入 8月3号的数据, 前3月就是 6 月, 7 月, 还有8 月)
2 明显的就是取出最值, 再在最值上面过滤 。。。
分析到这两点 差不多了,
1 制作数据:
with tab1 as(
select 'customer001' Customerkey , 'story002' storeid , to_date('2015-04-21 12:29:19','yyyy-mm-dd hh24:mi:ss') Createdate from dual
union all
select 'customer001' Customerkey , 'story002' storeid , to_date('2015-05-21 17:00:19','yyyy-mm-dd hh24:mi:ss') Createdate from dual
union all
select 'customer001' Customerkey , 'story002' storeid , to_date('2015-06-11 19:00:19','yyyy-mm-dd hh24:mi:ss') Createdate from dual
union all
select 'customer001' Customerkey , 'story001' storeid , to_date('2015-07-21 12:29:19','yyyy-mm-dd hh24:mi:ss') Createdate from dual
union all
select 'customer001' Customerkey , 'story002' storeid , to_date('2015-04-28 17:00:19','yyyy-mm-dd hh24:mi:ss') Createdate from dual
union all
select 'customer001' Customerkey , 'story002' storeid , to_date('2015-07-01 19:00:19','yyyy-mm-dd hh24:mi:ss') Createdate from dual
union all
select 'customer002' Customerkey , 'story001' storeid , to_date('2015-04-21 12:29:19','yyyy-mm-dd hh24:mi:ss') Createdate from dual
union all
select 'customer002' Customerkey , 'story002' storeid , to_date('2015-04-21 17:00:19','yyyy-mm-dd hh24:mi:ss') Createdate from dual
union all
select 'customer002' Customerkey , 'story002' storeid , to_date('2015-04-11 19:00:19','yyyy-mm-dd hh24:mi:ss') Createdate from dual
union all
select 'customer002' Customerkey , 'story001' storeid , to_date('2015-04-06 12:29:19','yyyy-mm-dd hh24:mi:ss') Createdate from dual
union all
select 'customer002' Customerkey , 'story002' storeid , to_date('2015-04-03 17:00:19','yyyy-mm-dd hh24:mi:ss') Createdate from dual
union all
select 'customer002' Customerkey , 'story002' storeid , to_date('2015-08-04 19:00:19','yyyy-mm-dd hh24:mi:ss') Createdate from dual
)
2 统计客户在店中的消费记录
tab2 as (
select customerkey, storeid, count(*) cnt from tab1 group by Customerkey,storeid
)
3 获取最值
tab2 as (
select customerkey, storeid, count(*) cnt , max( count(*) ) over(partition by customerkey) mx from tab1 group by Customerkey,storeid
) select tab2.* from tab2;
注意: max( count(*) ) over(partition by customerkey) mx 的意思是: 客户在哪个店中的消费记录最多。
截图:
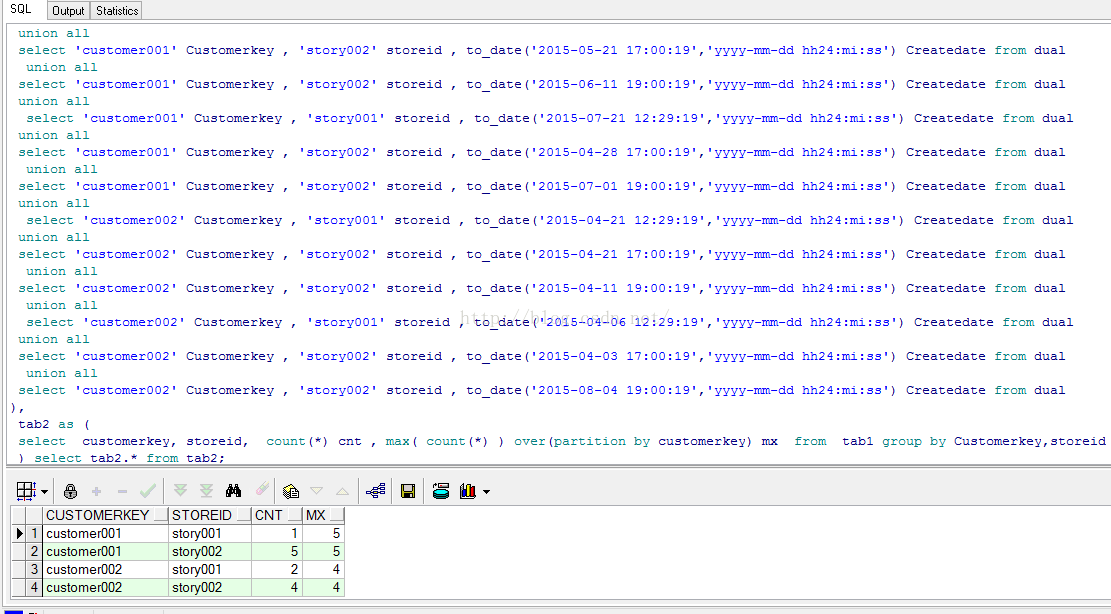
这个表面 001 用户在 002店中 消费到5次... 符合要求。
最后的SQL :
with tab1 as(
select 'customer001' Customerkey , 'story002' storeid , to_date('2015-04-21 12:29:19','yyyy-mm-dd hh24:mi:ss') Createdate from dual
union all
select 'customer001' Customerkey , 'story002' storeid , to_date('2015-05-21 17:00:19','yyyy-mm-dd hh24:mi:ss') Createdate from dual
union all
select 'customer001' Customerkey , 'story002' storeid , to_date('2015-06-11 19:00:19','yyyy-mm-dd hh24:mi:ss') Createdate from dual
union all
select 'customer001' Customerkey , 'story001' storeid , to_date('2015-07-21 12:29:19','yyyy-mm-dd hh24:mi:ss') Createdate from dual
union all
select 'customer001' Customerkey , 'story002' storeid , to_date('2015-04-28 17:00:19','yyyy-mm-dd hh24:mi:ss') Createdate from dual
union all
select 'customer001' Customerkey , 'story002' storeid , to_date('2015-07-01 19:00:19','yyyy-mm-dd hh24:mi:ss') Createdate from dual
union all
select 'customer002' Customerkey , 'story001' storeid , to_date('2015-04-21 12:29:19','yyyy-mm-dd hh24:mi:ss') Createdate from dual
union all
select 'customer002' Customerkey , 'story002' storeid , to_date('2015-04-21 17:00:19','yyyy-mm-dd hh24:mi:ss') Createdate from dual
union all
select 'customer002' Customerkey , 'story002' storeid , to_date('2015-04-11 19:00:19','yyyy-mm-dd hh24:mi:ss') Createdate from dual
union all
select 'customer002' Customerkey , 'story001' storeid , to_date('2015-04-06 12:29:19','yyyy-mm-dd hh24:mi:ss') Createdate from dual
union all
select 'customer002' Customerkey , 'story002' storeid , to_date('2015-04-03 17:00:19','yyyy-mm-dd hh24:mi:ss') Createdate from dual
union all
select 'customer002' Customerkey , 'story002' storeid , to_date('2015-08-04 19:00:19','yyyy-mm-dd hh24:mi:ss') Createdate from dual
),
tab2 as (
select customerkey, storeid, count(*) cnt , max( count(*) ) over(partition by customerkey) mx from tab1 group by Customerkey,storeid
having count(*)>4
) select tab2.* from tab2 where cnt = mx ;
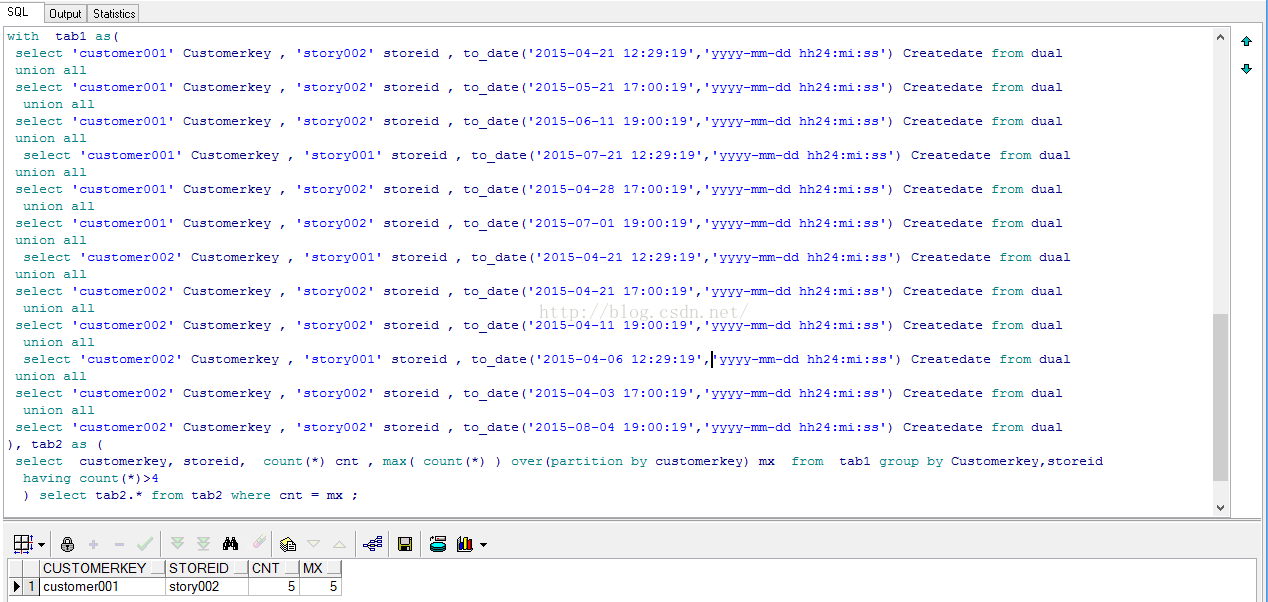
说明: tab1 中全是 满足最近3个月的数据, 加入到项目中 自己在表中刷选即可, 另外这个题目要求是更改 会员的归属店, 这个可以过程在数据库中跑, 根据那个SQL 中店编号, 核对会员的归属店编号, 改动.... 这个这里不写了就, 也可以用merger into 来改, merger into 全表比对, 根据实际的情况取舍。 个人倾向于第一个过程。
最后的结果是:














 654
654











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









