









Preface
Markov Decision Processes(MDP,马尔科夫决策过程)
Value Function(价值函数)
Value Iteration(值迭代)
Policy Iteration(迭代策略)
Parameter Estimation(参数估计)
Markov Decision Processes
MDP定义
马尔科夫决策过程MDP由一个五元组
(S,A,{Psa},γ,R)
(
S
,
A
,
{
P
s
a
}
,
γ
,
R
)
构成。
S
S
表示状态集(states)。(对于自动直升机系统例子,直升机位置坐标和方向的集合)
表示一组动作(actions)。(对于自动直升机系统例子,使用控制杆操纵的直升机飞行方向,让其向前,向后等)
Psa
P
s
a
是状态转换分布。
∑s′Psa(s′)=1,Psa(s′)≥0
∑
s
′
P
s
a
(
s
′
)
=
1
,
P
s
a
(
s
′
)
≥
0
。
S
S
中的一个状态到另一个状态的转变,需要来参与。
Psa
P
s
a
表示的 是在当前
s∈S
s
∈
S
状态下,经过
a∈A
a
∈
A
作用后,会转移到的其他状态的概率分布情况(当前状态执行 a 后可能跳转到很多状态)。
γ∈[0,1)
γ
∈
[
0
,
1
)
是阻尼系数(discount factor)。
R:S×A⟼R
R
:
S
×
A
⟼
ℝ
,
R
R
是回报函数(reward function),回报函数经常写作的函数(只与
R
R
有关),这样的话,重新写作
R:S⟼R
R
:
S
⟼
ℝ
。
MDP例子
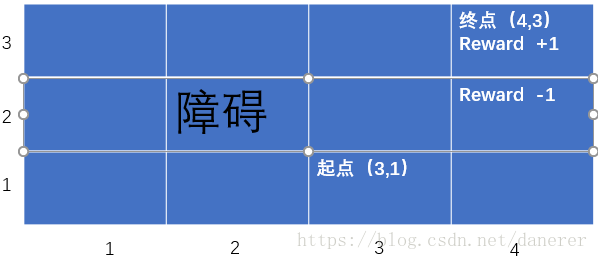
如图,假设有一个机器人生活在上述的网格世界中,从起点(3,1)出发要到达终点(3,2)。
(我们使用reward +1来关联我们希望它到达的网格单元位置;reward -1来关联我们希望它避免的网格单元位置)
对照MDP定义我们可以得到:
S={(1,1),(1,2),(1,3),(1,4),(2,1),(2,3),(2,4),(3,1),(3,2),(3,3),(3,4)}
S
=
{
(
1
,
1
)
,
(
1
,
2
)
,
(
1
,
3
)
,
(
1
,
4
)
,
(
2
,
1
)
,
(
2
,
3
)
,
(
2
,
4
)
,
(
3
,
1
)
,
(
3
,
2
)
,
(
3
,
3
)
,
(
3
,
4
)
}
。
A={N,S,E,W}
A
=
{
N
,
S
,
E
,
W
}
。(北,南,东,西)
由于机器人在移动中存在一定的噪声(误差),所以有当机器人想要向N移动时,有0.1的可能行向W移动,0.1的可能行向E移动,0.8的可能行向N移动。即,例如当机器人在起点想要向N移动时,
P(3,1),N((3,2))=0.8,P(3,1),N((4,1))=0.1,P(3,1),N((2,1))=0.1,P(3,1),N((3,3))=0
P
(
3
,
1
)
,
N
(
(
3
,
2
)
)
=
0.8
,
P
(
3
,
1
)
,
N
(
(
4
,
1
)
)
=
0.1
,
P
(
3
,
1
)
,
N
(
(
2
,
1
)
)
=
0.1
,
P
(
3
,
1
)
,
N
(
(
3
,
3
)
)
=
0
。同时,当机器人撞墙时,机器人保持不动。
回报函数:
R((4,3))=+1
R
(
(
4
,
3
)
)
=
+
1
,
R((4,2))=−1
R
(
(
4
,
2
)
)
=
−
1
,
R(otherS)=−0.02
R
(
o
t
h
e
r
S
)
=
−
0.02
(
R(otherS)
R
(
o
t
h
e
r
S
)
可以理解为每一步的消耗,使机器人尽快到达目的地)。
MDP过程
假设 si s i 表示在时刻 i 的状态, ai a i 表示在时刻 i 的状态将要进行的动作。所以在时刻 0 时的状态为 s0 s 0 ,然后选择一个 a0 a 0 ,根据 s1∼Ps0a0 s 1 ∼ P s 0 a 0 这个分布函数得到在时刻 1 时的状态 s1 s 1 。然后在时刻 1 时的状态为 s1 s 1 ,然后选择一个 a1 a 1 ,根据 s2∼Ps1a1 s 2 ∼ P s 1 a 1 这个分布函数得到在时刻 2 时的状态 s2 s 2 。依次类推,在时刻 i 时的状态为 si s i ,然后选择一个 ai a i ,根据 si+1∼Psiai s i + 1 ∼ P s i a i 这个分布函数得到在时刻 i+1 时的状态 si+1 s i + 1 。
通过上述过程我们得到一系列的时序状态 St={s1,s2,...,si−1,si,si+1,...} S t = { s 1 , s 2 , . . . , s i − 1 , s i , s i + 1 , . . . } 。
为了评估我们的机器人学习的效率(做得好不好),我们计算这个时序状态的回报函数之和:
我们使用阻尼系数(discount factor)
γ∈[0,1)
γ
∈
[
0
,
1
)
来表示当前状态对于时序状态的回报函数之和的影响要大于以后状态对于时序状态的回报函数之和的影响:
所以这个强化学习算法的周期总是基于已有的状态信息来进行动作和下一步状态的转换,我们期望得到的是时序状态的回报函数之和的最大值,即:
为了得到的是时序状态的回报函数之和
E[R(s0)+γR(s1)+γ2R(s2)+...]
E
[
R
(
s
0
)
+
γ
R
(
s
1
)
+
γ
2
R
(
s
2
)
+
.
.
.
]
的最大值,我们需要知道在当前状态下应该采取什么行动。我们将这个动作的选择过程称为策略(policy),每一个 policy 其实就是一个状态到动作的映射函数
π∶S⟼A
π
∶
S
⟼
A
,我们使用
π
π
来表示这个策略的集合。
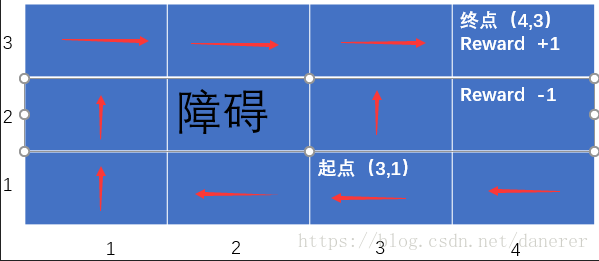
很明显上图所示的策略集合
π
π
并不是一个最佳的策略集合,你可能会想在起点(3,1)时为什么不直接从(3,2),(3,3),(3,4)的最短路径到达终点,而是要走一圈绕路,这是由于在(3,2)有 0.1 的概率进入(4,2)这会造成大的失误,所以MDP过程采用了一种微妙的折中的方法。
Value Function
对于任一策略集合
π
π
,定义值函数(Value Function)
Vπ:S⟼R
V
π
:
S
⟼
R
的映射,
Vπ(S)
V
π
(
S
)
时序状态的回报函数的总和的预期值,即为:
对于下述的的一个策略集合
π
π
与它的时序状态的回报函数的总和的预期值
Vπ(s)
V
π
(
s
)
:
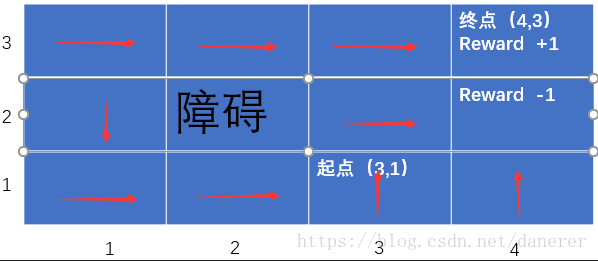

我们可以明显看出这不是一个好的策略集合
π
π
。
对于价值函数我们可以进行下述过程:
所以有:
其中,
Vπ(s1)=E[R(s1)+γR(s2)+..|π,s0=s]
V
π
(
s
1
)
=
E
[
R
(
s
1
)
+
γ
R
(
s
2
)
+
.
.
|
π
,
s
0
=
s
]
。所以:
上式分成了两个部分,第一部分称为当前时刻的即时回报,第二部分称为当前时刻的未来回报。
同时,由于对于当前状态
s
s
采用行动得到的下一个状态
s′
s
′
是随机的,所以有Bellman等式:
举一个具体的例子说明上式。假设
π((3,1))=N
π
(
(
3
,
1
)
)
=
N
且当期状态为
s=(3,1)
s
=
(
3
,
1
)
,所以
Vπ(s)
V
π
(
s
)
为:
如果我们将状态集合 S S 中的所以状态都用Bellman等式表示,我们可以得到由11个方程与11个未知数组成的方程组,进而求得每一个状态的。
所以最优值函数的定义为:
所以有最优值函数
V∗(s)
V
∗
(
s
)
的Bellman等式为:
所以最优策略为:
所以最优策略集合 p∗ p ∗ 为 π∗(s) π ∗ ( s ) 的集合。
Value Iteration
Value Iteration(值迭代)的过程为:
- 将 S S 中每一个 s 的初始化为 0 。
Repeat until convergence{
更新每一个 s 的 V(s) V ( s ) ,
V(s):=R(s)+maxa∈Aγ∑s′∈SPsa(s′)V(s′) V ( s ) := R ( s ) + max a ∈ A γ ∑ s ′ ∈ S P s a ( s ′ ) V ( s ′ )}
上述值迭代过程的第二步循环的实现有两种策略:
- 同步更新:拿初始化后的第一次迭代来说吧,初始状态所有的 V(s) V ( s ) 为 0 。然后对所有的 s 都计算新的 V(s)=R(s)+0=R(s) V ( s ) = R ( s ) + 0 = R ( s ) 。在计算每一个状态时,得到新的 V(s) V ( s ) 后,先存下来不立即更新。待所有的 s 的新值 V(s) V ( s ) 都计算完毕后,再统一更新。 这样,第一次迭代后,V(s)=R(s)。即为,每一次的迭代与上一次的迭代有关,不与当前迭代轮次中最新产生的 V(s) V ( s ) 相关。
- 异步更新:对每一个状态 s,得到新的 V(s) V ( s ) 后,立即更新。这样,第一次迭代后,大部分 V(s)>R(s) V ( s ) > R ( s ) 。即为,每一次的迭代既与于上一次的迭代有关,也与当前迭代轮次中最新产生的 V(s) V ( s ) 相关。
通过值迭代,我们得到:

继而我们可以得到策略集合
π
π
:
在这里我们就可以解释很明显上图所示的策略集合
π
π
在起点(3,1)时为什么不直接从(3,2),(3,3),(3,4)的最短路径到达终点,而是要走一圈绕路。
如果我们在(3,1)选择
W∈A
W
∈
A
,预期总收益为:
如果我们在(3,1)选择
N∈A
N
∈
A
,预期总收益为:
这就是为什么不直接从(3,2),(3,3),(3,4)的最短路径到达终点,而是要走一圈绕路的原因。
Policy Iteration
Policy Iteration(策略迭代)的过程为:
- 将 π π 中每一个 π(s) π ( s ) 的随机初始化为 A={W,N,E,S} A = { W , N , E , S } 中的任意值。
Repeat until convergence{
1. V:=Vπ V := V π 。( Vπ(s)=R(s)+γ∑s‘∈SPsπ(s)(s‘)Vπ(s‘) V π ( s ) = R ( s ) + γ ∑ s ‘ ∈ S P s π ( s ) ( s ‘ ) V π ( s ‘ ) 等式构成的方程组解得每一个 Vπ(s) V π ( s ) )
2.更新每一个 s 的 π(s) π ( s ) ,
π(s)=argmaxa∈A∑s′∈SPsa(s′)V(s′) π ( s ) = arg max a ∈ A ∑ s ′ ∈ S P s a ( s ′ ) V ( s ′ )}
Parameter Estimation
马尔科夫决策过程MDP是一个五元组
(S,A,{Psa},γ,R)
(
S
,
A
,
{
P
s
a
}
,
γ
,
R
)
问题。上面我们得到了处了
Psa
P
s
a
之外的答案。
Psa
P
s
a
的计算公式如下:
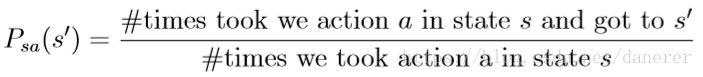
同时当出现0/0的情况时,设定
Psa=1/|s|
P
s
a
=
1
/
|
s
|
。
当转移概率和回报函数(我们一般自己设定)估计出之后,我们可以使用值迭代或者策略迭代来解决 MDP 问题。比如,我们将参数估计和值迭代结合起来(在不知道状态转移概率情况下)的流程如下:
- 将 π π 中每一个 π(s) π ( s ) 的随机初始化为 A={W,N,E,S} A = { W , N , E , S } 中的任意值。
Repeat until convergence{
1.在样本上统计π中每个状态转移次数,用来更新 Psa P s a 和 R
2. V:=Vπ V := V π 。( Vπ(s)=R(s)+γ∑s‘∈SPsπ(s)(s‘)Vπ(s‘) V π ( s ) = R ( s ) + γ ∑ s ‘ ∈ S P s π ( s ) ( s ‘ ) V π ( s ‘ ) 等式构成的方程组解得每一个 Vπ(s) V π ( s ) )
3.更新每一个 s 的 π(s) π ( s ) ,
π(s)=argmaxa∈A∑s′∈SPsa(s′)V(s′) π ( s ) = arg max a ∈ A ∑ s ′ ∈ S P s a ( s ′ ) V ( s ′ )}














 1023
1023











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









