









NoSQL
前言
NoSQL,泛指非关系型的数据库,全称Not Only SQL,意即“不仅仅是SQL”。
NoSQL数据库的产生就是为了解决大规模数据集合多重数据种类带来的挑战,尤其是大数据应用难题。在过去几年,关系型数据库一直是数据持久化的唯一选择,数据工作者考虑的也只是在这些传统数据库中做筛选,比如SQL Server、Oracle或者是MySQL。甚至是做一些默认的选择,比如使用.NET的一般会选择SQL Server;使用Java的可能会偏向Oracle,Ruby是MySQL,Python则是PostgreSQL或MySQL等等。
原因很简单:过去很长一段时间内,关系数据库的健壮性已经在多数应用程序中得到证实。我们可以使用这些传统数据库良好的控制并发操作、事务等等。然而如果传统的关系型数据库一直这么可靠,那么还有NoSQL什么事?NoSQL之所以生存并得到发展,是因为它做到了传统关系型数据库做不到的事!
我们使用Python、Ruby、Java、.Net等语言编写应用程序,这些语言有一个共同的特性——面向对象。但是我们使用MySQL、PostgreSQL、Oracle以及SQL Server,这些数据库同样有一个共同的特性——关系型数据库。这里就牵扯到了“Impedance Mismatch”( 阻抗不匹配)这个术语:存储结构是面向对象的,但是数据库却是关系的,所以在每次存储或者查询数据时,我们都需要做转换。Hibernate这样的ORM框架确实可以简化这个过程,但是在对查询有高性能需求时,这些ORM框架就捉襟见肘了。
网络应用程序的规模日渐变大,我们需要储存更多的数据、服务更多的用户以及需求更多的计算能力。为了应对这种情形,我们需要不停的扩展。扩展分为两类:一种是纵向扩展,即购买更好的机器,更多的磁盘、更多的内存等等;另一种是横向扩展,即购买更多的机器组成集群。在巨大的规模下,纵向扩展发挥的作用并不是很大。首先单机器性能提升需要巨额的开销并且有着性能的上限,在Google和Facebook这种规模下,永远不可能使用一台机器支撑所有的负载。鉴于这种情况,我们需要新的数据库,因为关系数据库并不能很好的运行在集群上。不错你也可能会去搭建关系数据库集群,但是他们使用的是共享存储,这并不是我们想要的类型。于是就有了以Google、Facebook、Amazon这些试图处理更多传输所引领的NoSQL纪元。
NoSQL数据库在以下的这几种情况下比较适用:
1、数据模型比较简单;
2、需要灵活性更强的IT系统;
3、对数据库性能要求较高;
4、不需要高度的数据一致性;
5、对于给定key,比较容易映射复杂值的环境。
NoSQL数据库的四大家族
一、键值(Key-Value)数据库
键值数据库就像在传统语言中使用的哈希表。你可以通过key来添加、查询或者删除数据,鉴于使用主键访问,所以会获得不错的性能及扩展性。
键值数据库查找速度快,数据无结构化,通常只被当作字符串或者二进制数据。
适用的场景
储存用户信息,比如会话、配置文件、参数、购物车等等。这些信息一般都和ID(键)挂钩,这种情景下键值数据库是个很好的选择。
不适用场景
1. 取代通过键查询,而是通过值来查询。Key-Value数据库中根本没有通过值查询的途径。
2. 需要储存数据之间的关系。在Key-Value数据库中不能通过两个或以上的键来关联数据。
3. 事务的支持。在Key-Value数据库中故障产生时不可以进行回滚。
产品:Riak、Redis、Memcached、Amazon’s Dynamo、Project Voldemort
- Riak
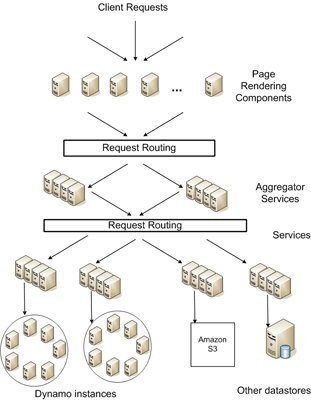
Riak是以 Erlang 编写的一个高度可扩展的分布式数据存储,Riak的实现是基于Amazon的分布式key/value存储引擎Dynamo,如图1所示。
图1
Riak的设计目标之一就是高可用。Riak支持多节点构建的系统,每次读写请求不需要集群内所有节点参与也能胜任。提供一个灵活的 map/reduce 引擎,一个友好的 HTTP/JSON 查询接口。目前有三种方式可以访问 Riak:HTTP API(RESTful 界面)、Protocol Buffers 和一个原生 Erlang 界面。提供多个界面使你能够选择如何集成应用程序。
riak-java-client 是 Riak 的 Java 客户端开发类库,示例代码:
// create a client
IRiakClient riakClient = RiakFactory.pbcClient(); //or RiakFactory.httpClient();
// create a new bucket
Bucket myBucket = riakClient.createBucket("myBucket").execute();
// add data to the bucket
myBucket.store("key1", "value1").execute();
//fetch it back
IRiakObject myData = myBucket.fetch("key1").execute();
// you can specify extra parameters to the store operation using the
// fluent builder style API
myData = myBucket.store("key1", "value2").returnBody(true).execute();
// delete
myBucket.delete("key1").rw(3).execute();有谁在使用
GitHub,一个开源代码库以及版本控制系统,是管理软件开发以及发现已有代码的首选方法,在GitHub,用户可以十分轻易地找到海量的开源代码。
BestBuy ,百思买集团(Best Buy),全球最大家用电器和电子产品零售集团。
- Redis
Redis是一个开源的使用ANSI C语言编写、支持网络、可基于内存亦可持久化的日志型、Key-Value数据库,并提供多种语言的API。Redis支持存储的value类型包括string(字符串)、hash(散列)、list(链表)、set(集合)和zset(有序集合)。这些数据类型都支持push/pop、add/remove及取交集并集和差集及更丰富的操作,而且这些操作都是原子性的。在此基础上,redis支持各种不同方式的排序。Redis数据都是缓存在内存中,会周期性的把更新的数据写入磁盘或者把修改操作写入追加的记录文件,并且在此基础上实现了master-slave(主从)同步。
Jedis 是 Redis 官方首选的 Java 客户端开发包。
有谁在使用
Twitter (Redis和Memcached),一家美国社交网络及微博客服务的网站,是全球互联网上访问量最大的十个网站之一。是一个广受欢迎的社交网络及微博客服务的网站。
StackOverFlow ,是一个与程序相关的IT技术问答网站。用户可以在网站免费提交问题,浏览问题,索引相关内容。是程序员经常光顾的网站之一。
Instagram,是一款支持iOS、Windows Phone、Android平台的移动应用,允许用户在任何环境下抓拍下自己的生活记忆,选择图片的滤镜样式,一键分享至Instagram、Facebook、Twitter、Flickr、Tumblr、foursquare或者新浪微博平台上。不仅仅是拍照,作为一款轻量级但十分有趣的App,Instagram 在移动端融入了很多社会化元素,包括好友关系的建立、回复、分享和收藏等,这是Instagram 作为服务存在而非应用存在最大的价值。
**Flick**r,雅虎旗下图片分享网站。为一家提供免费及付费数位照片储存、分享方案之线上服务,也提供网络社群服务的平台。其重要特点就是基于社会网络的人际关系的拓展与内容的组织。这个网站的功能之强大,已超出了一般的图片服务,比如图片服务、联系人服务、组群服务。
暴雪,大名鼎鼎的游戏公司。
新浪、街旁、知乎等。
Memcached
Memcached 是一个基于一个存储键/值对的高性能的分布式内存对象缓存系统,用于动态Web应用以减轻数据库负载。它通过在内存中缓存数据和对象来减少读取数据库的次数,从而提高动态、数据库驱动网站的速度。
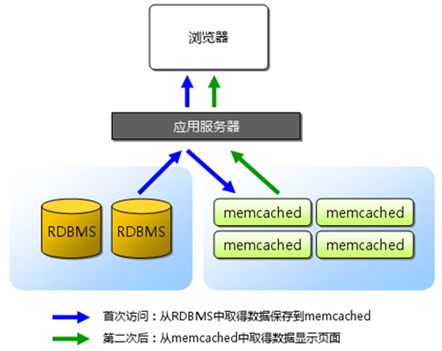
许多Web 应用程序都将数据保存到RDBMS中,应用服务器从中读取数据并在浏览器中显示。但随着数据量的增大,访问的集中,就会出现RDBMS的负担加重,数据库响应恶化,网站显示延迟等重大影响。Memcached是高性能的分布式内存缓存服务器。一般的使用目的是通过缓存数据库查询结果,减少数据库的访问次数,以提高动态Web 应用的速度、提高扩展性。如图2所示。
图2Memcached-Java-Client 是一个memcached Java客户端API,应用广泛,运行比较稳定。XMemcached也使用得比较广泛,而且有较详细的中文API文档,具有如下特点:高性 能、支持完整的协议、支持客户端分布、允许设置节点权重、动态增删节点、支持JMX、与Spring框架和Hibernate-memcached的集 成、客户端连接池、可扩展性好等。
有谁在使用
Twitter (Redis和Memcached)
Youtube ,世界上最大的视频网站。
Wikipedia,维基百科是一个基于维基技术的多语言百科全书协作计划,用多种语言编写的网络百科全书。
WordPress.com,WordPress是一款个人博客系统,并逐步演化成一款内容管理系统软件,用户可以在支持PHP和MySQL数据库的服务器上架设属于自己的网站,也可以把 WordPress当作一个内容管理系统(CMS)来使用。
二、面向文档(Document-Oriented)数据库
面向文档数据库会将数据以文档的形式储存。每个文档都是自包含的数据单元,是一系列数据项的集合。每个数据项都有一个名称与对应的值,值既可以是简单的数据类型,如字符串、数字和日期等;也可以是复杂的类型,如有序列表和关联对象。数据存储的最小单位是文档,同一个表中存储的文档属性可以是不同的,数据可以使用XML、JSON或者JSONB等多种形式存储。
数据结构要求不严格,表结构可变,不需要像关系型数据库一样需要预先定义表结构,但是查询性能不高,而且缺乏统一的查询语法。
适用的场景
1. 日志。企业环境下,每个应用程序都有不同的日志信息。Document-Oriented数据库并没有固定的模式,所以我们可以使用它储存不同的信息。
2. 分析。鉴于它的弱模式结构,不改变模式下就可以储存不同的度量方法及添加新的度量。
不适用场景
在不同的文档上添加事务。Document-Oriented数据库并不支持文档间的事务,如果对这方面有需求则不应该选用这个解决方案。
产品:MongoDB、CouchDB、RavenDB、Terrastore 、OrientDB
- MongoDB
MongoDB是一个基于分布式文件存储的数据库。由C++语言编写。旨在为WEB应用提供可扩展的高性能数据存储解决方案。是一个介于关系数据库和非关系数据库之间的产品,是非关系数据库当中功能最丰富,最像关系数据库的。它支持的数据结构非常松散,是类似json的bson格式,因此可以存储比较复杂的数据类型。Mongo最大的特点是他支持的查询语言非常强大,其语法有点类似于面向对象的查询语言,几乎可以实现类似关系数据库单表查询的绝大部分功能,而且还支持对数据建立索引。
mongoDB对Java支持的驱动包常用的是mongodb-java-driver,另外还有Mopa4j ,全称是 MOngo Persistence API for Java,它将 POJO 映射到 com.mongodb.DBObject,反之也可以。
有谁在使用
Craiglist上使用MongoDB的存档数十亿条记录。
FourSquare,基于位置的社交网站,在Amazon EC2的服务器上使用MongoDB分享数据。
Shutterfly,以互联网为基础的社会和个人出版服务,使用MongoDB的各种持久性数据存储的要求。
bit.ly, 一个基于Web的网址缩短服务,使用MongoDB的存储自己的数据。
spike.com,一个MTV网络的联营公司, spike.com使用MongoDB的。
Intuit公司,一个为小企业和个人的软件和服务提供商,为小型企业使用MongoDB的跟踪用户的数据。
sourceforge.net,资源网站查找,创建和发布开源软件免费,使用MongoDB的后端存储。
etsy.com ,一个购买和出售手工制作物品网站,使用MongoDB。
纽约时报,领先的在线新闻门户网站之一,使用MongoDB。
CERN,著名的粒子物理研究所,欧洲核子研究中心大型强子对撞机的数据使用MongoDB。
CouchDB
CouchDB 是一个开源的面向文档的数据库管理系统,它提供以 JSON 作为数据格式的 REST 接口来对其进行操作,并可以通过视图来操纵文档的组织和呈现。术语 “Couch” 是 “Cluster Of Unreliable Commodity Hardware” 的首字母缩写,它反映了 CouchDB 的目标具有高度可伸缩性,提供了高可用性和高可靠性,即使运行在容易出现故障的硬件上也是如此。
CouchDB是分布式的数据库,它可以把存储系统分布到n台物理的节点上面,并且很好的协调和同步节点之间的数据读写一致性。这当然也得靠Erlang无与伦比的并发特性才能做到。对于基于web的大规模应用文档应用,分布式可以让它不必像传统的关系数据库那样分库拆表,在应用代码层进行大量的改动。
CouchDB是面向文档的数据库,存储半结构化的数据,比较类似lucene的index结构,特别适合存储文档,因此很适合CMS,电话本,地址本等应用,在这些应用场合,文档数据库要比关系数据库更加方便,性能更好。
CouchDB支持REST API,可以让用户使用JavaScript来操作CouchDB数据库,也可以用JavaScript编写查询语句,我们可以想像一下,用AJAX技术结合CouchDB开发出来的CMS系统会是多么的简单和方便。
CouchDB 的 JDBC 驱动程序是jcouchdb ,这是一个经过良好测试并且易于使用的Java库,它会自动地将Java对象序列化、反序列化进CouchDB数据库。选择jcouchdb的另一个原因是它和CouchDB自身的API非常相似。RavenDB
RavenDB是基于Windows/.NET平台的NoSQL数据库,支持Linq的开源文档数据库,旨在Window平台下提供一个高性能,结构简单,灵活,可扩展NoSQL存储。Raven将JSON文档存在数据库中。可以使用C#的Linq语法查询数据。
NBC News,美国国家广播公司使用了RavenDB。Terrastore
Terrastore 是一个基于Terracotta(一 个业界公认的、快速的分布式集群组件)实现的高性能分布式文档数据库。可以动态从运行中的集群添 加/删除节点,而且不需要停机和修改任何配置。支持通过http协议访问Terrastore。Terrastore提供了一个基于集合的键/值接口来管 理JSON文档并且不需要预先定义JSON文档的架构。易于操作,安装一个完整能够运行的集群只需几行命令。OrientDB
OrientDB 是兼具文挡数据库的灵活性和图形数据库管理链接 能力的可深层次扩展的文档-图形数据库管理系统。可选无模式、全模式或混合模式下。支持许 多高级特性,诸如ACID事务、快速索引,原生和SQL查询功能。可以JSON格式导入、导出文档。若不执行昂贵的JOIN操作的话,如同关系数据库可在 几毫秒内可检索数以百记的链接文档图。
三、 列存储(Wide Column Store/Column-Family)数据库
列存储数据库将数据储存在列族(column family)中,一个列族存储经常被一起查询的相关数据。举个例子,如果我们有一个Person类,我们通常会一起查询他们的姓名和年龄而不是薪资。这种情况下,姓名和年龄就会被放入一个列族中,而薪资则在另一个列族中。
列存储查找速度快,可扩展性强,更容易进行分布式扩展,适用于分布式的文件系统。
适用的场景
1. 日志。因为我们可以将数据储存在不同的列中,每个应用程序可以将信息写入自己的列族中。
2. 博客平台。我们储存每个信息到不同的列族中。举个例子,标签可以储存在一个,类别可以在一个,而文章则在另一个。
不适用场景
1. 如果我们需要ACID事务。Vassandra就不支持事务。
2. 原型设计。如果我们分析Cassandra的数据结构,我们就会发现结构是基于我们期望的数据查询方式而定。在模型设计之初,我们根本不可能去预测它的查询方式,而一旦查询方式改变,我们就必须重新设计列族。
产品:Cassandra、HBase
- Cassandra
Cassandra是一套开源分布式NoSQL数据库系统,是一个混合型的非关系的数据库,以Amazon专有的完全分布式的Dynamo为基础,结合了Google BigTable基于列族(Column Family)的数据模型。Cassandra的主要特点就是它不是一个数据库,而是由一堆数据库节点共同构成的一个分布式网络服务,对Cassandra 的一个写操作,会被复制到其他节点上去,对Cassandra的读操作,也会被路由到某个节点上面去读取。对于一个Cassandra群集来说,扩展性能是比较简单的事情,只管在群集里面添加节点就可以了。和其他数据库比较,有三个突出特点:模式灵活、可扩展性、多数据中心。
使用官方java驱动操作cassandra 非常简单。
有谁在使用
Ebay ,(EBAY,中文电子湾、亿贝、易贝)是一个管理可让全球民众上网买卖物品的线上拍卖及购物网站。
Instagram ,是一款支持iOS、Windows Phone、Android平台的移动应用,允许用户在任何环境下抓拍下自己的生活记忆,选择图片的滤镜样式,一键分享至Instagram、Facebook、Twitter、Flickr、Tumblr、foursquare或者新浪微博平台上。
NASA,如雷贯耳,美国国家航空航天局。
Twitter ,(Cassandra and HBase)全世界都非常流行的社交网络及微博客服务的网站。
- HBase
HBase,Hadoop Database,是一个高可靠性、高性能、面向列、可伸缩的分布式存储系统,利用HBase技术可在廉价PC Server上搭建起大规模结构化存储集群。HBase是Apache的Hadoop项目的子项目。HBase不同于一般的关系数据库,它是一个适合于非结构化数据存储的数据库。另一个不同的是HBase基于列的而不是基于行的模式。Apache三剑客:HBase, Cassandra, CouchDB,HBase的前景最为看好,因为它的开发者众多并且都是顶尖高手。
图3描述Hadoop EcoSystem中的各层系统。其中,HBase位于结构化存储层,Hadoop HDFS为HBase提供了高可靠性的底层存储支持,Hadoop MapReduce为HBase提供了高性能的计算能力,Zookeeper为HBase提供了稳定服务和failover机制。Pig和Hive还为HBase提供了高层语言支持,使得在HBase上进行数据统计处理变的非常简单。 Sqoop则为HBase提供了方便的RDBMS数据导入功能,使得传统数据库数据向HBase中迁移变的非常方便。
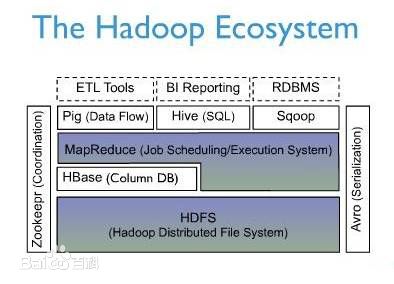
图3
HBase提供的访问接口有:
1. Native Java API,最常规和高效的访问方式,适合Hadoop MapReduce Job并行批处理HBase表数据
2. HBase Shell,HBase的命令行工具,最简单的接口,适合HBase管理使用
3. Thrift Gateway,利用Thrift序列化技术,支持C++,PHP,Python等多种语言,适合其他异构系统在线访问HBase表数据
4. REST Gateway,支持REST 风格的Http API访问HBase, 解除了语言限制
5. Pig,可以使用Pig Latin流式编程语言来操作HBase中的数据,和Hive类似,本质最终也是编译成MapReduce Job来处理HBase表数据,适合做数据统计
6. Hive,支持HBase,可以使用类似SQL语言来访问HBase
有谁在使用
Twitter,全世界都非常流行的社交网络及微博客服务的网站。
Facebook,美国的一个社交网络服务网站。
Yahoo!,美国著名的互联网门户网站,也是20世纪末互联网奇迹的创造者之一。其服务包括搜索引擎、电邮、新闻等,业务遍及24个国家和地区,为全球超过5亿的独立用户提供多元化的网络服务。同时也是一家全球性的因特网通讯、商贸及媒体公司。
四、 图(Graph-Oriented)数据库
图数据库允许我们将数据以图的方式储存。实体会被作为顶点,而实体之间的关系则会被作为边。比如我们有三个实体,Steve Jobs、Apple和Next,则会有两个“Founded by”的边将Apple和Next连接到Steve Jobs。
主要用于社交网络,推荐系统等。专注于构建关系图谱。
适用的场景
1. 在一些关系性强的数据中
2. 推荐引擎。如果我们将数据以图的形式表现,那么将会非常有益于推荐的制定
不适用场景
不适合的数据模型。图数据库的适用范围很小,因为很少有操作涉及到整个图。
产品:Neo4J、Infinite Graph、OrientDB
- Neo4J
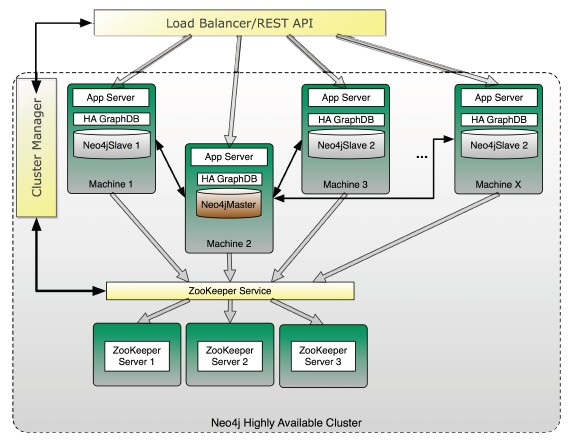
Neo4J是一个高性能的,NOSQL图形数据库,它将结构化数据存储在网络上而不是表中。它是一个嵌入式的、基于磁盘的、具备完全的事务特性的Java持久化引擎,但是它将结构化数据存储在网络(从数学角度叫做图)上而不是表中。Neo4j也可以被看作是一个高性能的图引擎,该引擎具有成熟数据库的所有特性。程序员工作在一个面向对象的、灵活的网络结构下而不是严格、静态的表中——但是他们可以享受到具备完全的事务特性、企业级的数据库的所有好处。它的架构图如图4所示。
图4
neo4j连接java目前主要有嵌入式、jdbc和rest api。
有谁在使用
Adobe,是世界领先数字媒体和在线营销方案的供应商,Adobe 的客户包括世界各地的企业、知识工作者、创意人士和设计者、OEM 合作伙伴,以及开发人员。
Cisco,全球领先的网络解决方案供应商。
T-Mobile,是一家跨国移动电话运营商,是世界上最大的移动电话公司之一。
- Infinite Graph
InfiniteGraph企业分布式图形数据库具有可伸缩性,它还能够在大量多地存储的复杂数据中,为大型企业执行实时搜索。通过使用图算法,它为分析应用程序添加了新的价值,以发现和存储新的连接和关系。
InfiniteGraph需要作为服务项目加以安装,这与以MySQL为代表的传统数据库颇为相似。InfiniteGraph借鉴了Objectivity/DB中的面向对象概念,因此其中的每一个节点及边线都算作一个对象。InfiniteGraph还提供了一套可视化工具用以查看数据。
InfiniteGraph基于Java实现,它的目标是构建“分布式的图形数据库”,已被美国国防部和美国中央情报局所采用。
Redis介绍
目前主流的NoSQL数据库,基于键值的Redis占一席之地,它功能丰富,交互简单,适用场景多。
Redis,全称Remote Dictionary Server,远程字典服务器, Redis是一个开源的、高性能的、基于键值对的缓存与存储系统,通过提供多种键值数据类型来适应不同场景下的缓存与存储需求。它以字典结构存储数据,并允许其他应用通过TCP协议读写字典中的内容。
Redis数据库中的数据是保存在内存中的,因此它的性能比基于硬盘存储的数据库有明显的优势,同时redis提供了对持久化的支持,可以将内存中的数据异步写入到硬盘中。
即使不采取redis作为应用数据库,选择redis作为缓存、队列系统,也是一个不错的选择。
Redis目前支持的键值数据类型如下:
字符串类型(string)
散列类型(hash)
列表类型(list)
集合类型(set)
有序集合类型(zset/sorted_set)
一个Redis实例相当于一格书架,书架里有16本字典(独立数据库),默认从0开始编号,查找最后一本字典的命令是select 15,通过select number可以自由切换数据库,这16个库并非完全隔离,某些命令可以通用,同时redis不支持自定义数据库名和访问密码,所有16个库的访问权限是一致的。区别于oracle的实例,所以不同的应用应该使用不同的redis实例。
安装Redis
首先你需要有一个Linux环境,比如CentOS,打开终端,输入几行安装命令即可。
wget http://download.redis.io/redis-stable.tar.gz
tar xzf redis-stable.tar.gz
cd redis-stable
make
建议编译后执行make install,执行时报错,提示执行make test。
执行make test,提示错误:You need tcl 8.5 or newer in order to run the Redis test
解决办法是安装tcl,2016-07-27 最新版本 tcl8.6.6-src.tar.gz
wget http://downloads.sourceforge.net/tcl/tcl8.6.6-src.tar.gz
sudo tar xzvf tcl8.6.6-src.tar.gz
cd /tcl8.6.6/unix/
sudo ./configure
sudo make
sudo make install
使用Redis
安装完成后,开启redis服务器,直接开启redis-server, 默认端口是6379,也可以使用初始化脚本启动Redis 配置运行方式和持久化文件 日志文件的存储位置等。
测试客户端与redis的连接是否正常,用redis-cli PING,正常回复是PONG。
现在可以对照命令行,亲自体验redis的各种类型的键值对的增删改查操作了。
应用Redis
Jedis 是 Redis 官方首选的 Java 客户端开发包。选择jedis来实现第一个demo。
新建项目,导入jar包:
jedis-2.9.0.jar
commons-pool-1.5.4.jar
新建测试类,新建变量非切片客户端连接jedis,非切片连接池jedisPool,切片客户端连接shardedJedis,切片连接池shardedJedisPool。
JedisPool连一台Redis,ShardedJedisPool连Redis集群,通过一致性哈希算法决定把数据存到哪台上,算是一种客户端负载均衡,所以一般添加缓存的时候用ShardedJedisPool而不是JedisPool,数据操作用JedisPool进行删除,而用ShardedJedisPool进行添加。
public class RedisClient {
private Jedis jedis;//客户端连接
private JedisPool jedisPool;//连接池
private ShardedJedis shardedJedis;//客户端连接
private ShardedJedisPool shardedJedisPool;//连接池
public RedisClient()
{
initialPool();
initialShardedPool();
shardedJedis = shardedJedisPool.getResource();
jedis = jedisPool.getResource();
}
/**
* 初始化非切片池
*/
private void initialPool()
{
// 池基本配置
JedisPoolConfig config = new JedisPoolConfig();
// 可用连接实例的最大数目,默认值为8;
// 如果赋值为-1,则表示不限制;如果pool已经分配了maxTotal个jedis实例,则此时pool的状态为exhausted(耗尽)。
config.setMaxTotal(20);
// 控制一个pool最多有多少个状态为idle(空闲的)的jedis实例,默认值也是8。
config.setMaxIdle(5);
// 等待可用连接的最大时间,单位毫秒,默认值为-1,表示永不超时。如果超过等待时间,则直接抛出JedisConnectionException;
config.setMaxWaitMillis(1000l);
// 在borrow一个jedis实例时,是否提前进行validate操作;如果为true,则得到的jedis实例均是可用的;
config.setTestOnBorrow(false);
jedisPool = new JedisPool(config,"192.168.3.9",6379);
}
/**
* 初始化切片池
*/
private void initialShardedPool()
{
// 池基本配置
JedisPoolConfig config = new JedisPoolConfig();
config.setMaxTotal(20);
config.setMaxIdle(5);
config.setMaxWaitMillis(1000l);
config.setTestOnBorrow(false);
// slave链接
List<JedisShardInfo> shards = new ArrayList<JedisShardInfo>();
shards.add(new JedisShardInfo("192.168.3.9", 6379, "master"));
// 构造池
shardedJedisPool = new ShardedJedisPool(config, shards);
}
/**
* 方法测试
*/
public static void main(String args[]){
//new RedisClient().StringOperate();
//......
}
}redis的易用性在于,它的命令行简单易记,同时提供了几十种不同编程语言的客户端库,这些库都很好的封装了redis的命令,使得在程序中于redis进行交互变得更容易。如下,是jedis一些常用的命令:
1)连接操作命令
quit:关闭连接(connection)
auth:简单密码认证
help cmd: 查看cmd帮助,例如:help quit
2)持久化
save:将数据同步保存到磁盘
bgsave:将数据异步保存到磁盘
lastsave:返回上次成功将数据保存到磁盘的Unix时戳
shundown:将数据同步保存到磁盘,然后关闭服务
3)远程服务控制
info:提供服务器的信息和统计
monitor:实时转储收到的请求
slaveof:改变复制策略设置
config:在运行时配置Redis服务器
4)对value操作的命令
exists(key):确认一个key是否存在
del(key):删除一个key
type(key):返回值的类型
keys(pattern):返回满足给定pattern的所有key
randomkey:随机返回key空间的一个
keyrename(oldname, newname):重命名key
dbsize:返回当前数据库中key的数目
expire:设定一个key的活动时间(s)
ttl:获得一个key的活动时间
select(index):按索引查询
move(key, dbindex):移动当前数据库中的key到dbindex数据库
flushdb:删除当前选择数据库中的所有key
flushall:删除所有数据库中的所有key
5)String
set(key, value):给数据库中名称为key的string赋予值value
get(key):返回数据库中名称为key的string的value
getset(key, value):给名称为key的string赋予上一次的value
mget(key1, key2,…, key N):返回库中多个string的value
setnx(key, value):添加string,名称为key,值为value
setex(key, time, value):向库中添加string,设定过期时间time
mset(key N, value N):批量设置多个string的值
msetnx(key N, value N):如果所有名称为key i的string都不存在
incr(key):名称为key的string增1操作
incrby(key, integer):名称为key的string增加integer
decr(key):名称为key的string减1操作
decrby(key, integer):名称为key的string减少integer
append(key, value):名称为key的string的值附加value
substr(key, start, end):返回名称为key的string的value的子串
6)List
rpush(key, value):在名称为key的list尾添加一个值为value的元素
lpush(key, value):在名称为key的list头添加一个值为value的 元素
llen(key):返回名称为key的list的长度
lrange(key, start, end):返回名称为key的list中start至end之间的元素
ltrim(key, start, end):截取名称为key的list
lindex(key, index):返回名称为key的list中index位置的元素
lset(key, index, value):给名称为key的list中index位置的元素赋值
lrem(key, count, value):删除count个key的list中值为value的元素
lpop(key):返回并删除名称为key的list中的首元素
rpop(key):返回并删除名称为key的list中的尾元素
blpop(key1, key2,… key N, timeout):lpop命令的block版本。
brpop(key1, key2,… key N, timeout):rpop的block版本。
rpoplpush(srckey, dstkey):返回并删除名称为srckey的list的尾元素,并将该元素添加到名称为dstkey的list的头部
7)Set
sadd(key, member):向名称为key的set中添加元素member
srem(key, member) :删除名称为key的set中的元素member
spop(key) :随机返回并删除名称为key的set中一个元素
smove(srckey, dstkey, member) :移到集合元素
scard(key) :返回名称为key的set的基数
sismember(key, member) :member是否是名称为key的set的元素
sinter(key1, key2,…key N) :求交集
sinterstore(dstkey, (keys)) :求交集并将交集保存到dstkey的集合
sunion(key1, (keys)) :求并集
sunionstore(dstkey, (keys)) :求并集并将并集保存到dstkey的集合
sdiff(key1, (keys)) :求差集
sdiffstore(dstkey, (keys)) :求差集并将差集保存到dstkey的集合
smembers(key) :返回名称为key的set的所有元素
srandmember(key) :随机返回名称为key的set的一个元素
8)Sorted-Set
zadd(key, member):向名称为key的set中添加元素member
zrem(key, member) :删除名称为key的set中的元素member
zcard(key) :获取与该Key相关联的Sorted-Sets中包含的成员数量
zcount(key,min,max) :用于获取分数(score)在min和max之间的成员数量
zincrby(key,increment,member) :将为指定Key中的指定成员增加指定的分数
zrange(key,start,stop [WITHSCORES] ):返回顺序在参数start和stop指定范围内的成员
zrangebyscore(key,min,max, [WITHSCORES] [LIMIT offset count] ):返回分数在 min和max之间的所有成员,即满足表达式min <= score <= max的成员,其中返回的成员是按 照其分数从低到高的顺序返回
zrank(key,member):将返回参数中指定成员的位置值,其中0表示第一个成员,它是Sorted-Set中分 数最低的成员
zrevrange(key,start,stop,[WI THSCORES ]):反向排序
zrevrank(key,member):该命令的功能和ZRANK基本相同,唯一的差别 在于该命令获取的索引是从高到低排序后的位置,同样0表示第一个元素,即分数最高的成员
zscore(key,member):获取指定Key的指定成员的分数
zrevrangebyscore(key,max,min,[WITH SCORES] [ LIMIT offset count]):返回分数在 min和max之间的所有成员,即满足表达式min <= score <= max的成员,其中返回的成员是按 照其分数从高到低的顺序返回
zremrangebyrank(key,start,stop):删除索引位置位于 start和stop之间的成员
zremrangebyscore(key,min,max):删除分数在min和 max之间的所有成员,即满足表达式min <= score <= max的所有成员
9)Hash
hset(key, field, value):向名称为key的hash中添加元素field
hget(key, field):返回名称为key的hash中field对应的value
hmget(key, (fields)):返回名称为key的hash中field i对应的value
hmset(key, (fields)):向名称为key的hash中添加元素field
hincrby(key, field, integer):将名称为key的hash中field的value增加integer
hexists(key, field):名称为key的hash中是否存在键为field的域
hdel(key, field):删除名称为key的hash中键为field的域
hlen(key):返回名称为key的hash中元素个数
hkeys(key):返回名称为key的hash中所有键
hvals(key):返回名称为key的hash中所有键对应的value
hgetall(key):返回名称为key的hash中所有的键(field)及其对应的value
10) 事务
multi: 用于标记事务的开始,其后执行的命令都将被存入命令队列,直到执行EXEC时 ,这些命令才会被原子的执行。
exec: 执行在一个事务内命令队列中的所有命令,同时将当前连接的状态恢复为正常状 态,即非事务状态。如果在事务中执行了WATCH命令,那么只有当WATCH所 监控的Keys没有被修改的前提下,EXEC命令才能执行事务队列中的所有命令, 否则EXEC将放弃当前事务中的所有命令。
discard: 回滚事务队列中的所有命令,同时再将当前连接的状态恢复为正常状态,即非事 务状态。如果WATCH命令被使用,该命令将UNWATCH所有的Keys。
watch(key( [key …])): 在MULTI命令执行之前,可以指定待监控的Keys,然而在执行EXEC之前,如果 被监控的Keys发生修改,EXEC将放弃执行该事务队列中的所有命令。
unwatch: 取消当前事务中指定监控的Keys,如果执行了EXEC或DISCARD命令,则无需 再手工执行该命令了,因为在此之后,事务中所有被监控的Keys都将自动取消 。
简单的测试用例
private void KeyOperate() {
System.out.println("======================key==========================");
// 清空数据
System.out.println("清空库中所有数据:"+jedis.flushDB());//输出结果[清空库中所有数据:OK]
// 判断key否存在
System.out.println("判断key999键是否存在:"+shardedJedis.exists("key999")); //输出结果[判断key999键是否存在:false]
System.out.println("新增key001,value001键值对:"+shardedJedis.set("key001", "value001")); //输出结果[新增key001,value001键值对:OK]
System.out.println("判断key001是否存在:"+shardedJedis.exists("key001"));//输出结果[判断key001是否存在:true]
// 输出系统中所有的key
System.out.println("新增key002,value002键值对:"+shardedJedis.set("key002", "value002"));//输出结果[新增key002,value002键值对:OK]
System.out.println("系统中所有键如下:");
Set<String> keys = jedis.keys("*");
Iterator<String> it=keys.iterator() ;
while(it.hasNext()){
String key = it.next();
System.out.println(key);
}//输出结果[系统中所有键如下: key002 key001]
// 删除某个key,若key不存在,则忽略该命令。
System.out.println("系统中删除key002: "+jedis.del("key002"));//输出结果[系统中删除key002: 1]
System.out.println("判断key002是否存在:"+shardedJedis.exists("key002"));//输出结果[判断key002是否存在:false]
// 设置 key001的过期时间
System.out.println("设置 key001的过期时间为5秒:"+jedis.expire("key001", 5)); //输出结果[设置 key001的过期时间为5秒:1]
try{
Thread.sleep(2000);
}
catch (InterruptedException e){
}
// 查看某个key的剩余生存时间,单位【秒】.永久生存或者不存在的都返回-1
System.out.println("查看key001的剩余生存时间:"+jedis.ttl("key001"));//输出结果[查看key001的剩余生存时间:3]
// 移除某个key的生存时间
System.out.println("移除key001的生存时间:"+jedis.persist("key001"));//输出结果[移除key001的生存时间:1]
System.out.println("查看key001的剩余生存时间:"+jedis.ttl("key001"));//输出结果[查看key001的剩余生存时间:-1]
// 查看key所储存的值的类型
System.out.println("查看key所储存的值的类型:"+jedis.type("key001"));//输出结果[查看key所储存的值的类型:string]
/*
* 一些其他方法:1、修改键名:jedis.rename("key6", "key0");
* 2、将当前db的key移动到给定的db当中:jedis.move("foo", 1)
*/
}在main方法中运行该方法,结果如下:
======================key==========================
清空库中所有数据:OK
判断key999键是否存在:false
新增key001,value001键值对:OK
判断key001是否存在:true
新增key002,value002键值对:OK
系统中所有键如下:
key002
key001
系统中删除key002: 1
判断key002是否存在:false
设置 key001的过期时间为5秒:1
查看key001的剩余生存时间:3
移除key001的生存时间:1
查看key001的剩余生存时间:-1
查看key所储存的值的类型:string
private void StringOperate() {
System.out.println("======================String_1==========================");
// 清空数据
System.out.println("清空库中所有数据:"+jedis.flushDB());
System.out.println("=============增=============");
jedis.set("key001","value001");
jedis.set("key002","value002");
jedis.set("key003","value003");
System.out.println("已新增的3个键值对如下:");
System.out.println(jedis.get("key001"));
System.out.println(jedis.get("key002"));
System.out.println(jedis.get("key003"));
System.out.println("=============删=============");
System.out.println("删除key003键值对:"+jedis.del("key003"));
System.out.println("获取key003键对应的值:"+jedis.get("key003"));
System.out.println("=============改=============");
//1、直接覆盖原来的数据
System.out.println("直接覆盖key001原来的数据:"+jedis.set("key001","value001-update"));
System.out.println("获取key001对应的新值:"+jedis.get("key001"));
//2、直接覆盖原来的数据
System.out.println("在key002原来值后面追加:"+jedis.append("key002","+appendString"));
System.out.println("获取key002对应的新值"+jedis.get("key002"));
System.out.println("=============增,删,查(多个)=============");
/**
* mset,mget同时新增,修改,查询多个键值对
* 等价于:
* jedis.set("name","ssss");
* jedis.set("jarorwar","xxxx");
*/
System.out.println("一次性新增key201,key202,key203,key204及其对应值:"+jedis.mset("key201","value201",
"key202","value202","key203","value203","key204","value204"));
System.out.println("一次性获取key201,key202,key203,key204各自对应的值:"+
jedis.mget("key201","key202","key203","key204"));
System.out.println("一次性删除key201,key202:"+jedis.del(new String[]{"key201", "key202"}));
System.out.println("一次性获取key201,key202,key203,key204各自对应的值:"+
jedis.mget("key201","key202","key203","key204"));
System.out.println();
//jedis具备的功能shardedJedis中也可直接使用,下面测试一些前面没用过的方法
System.out.println("======================String_2==========================");
// 清空数据
System.out.println("清空库中所有数据:"+jedis.flushDB());
System.out.println("=============新增键值对时防止覆盖原先值=============");
System.out.println("原先key301不存在时,新增key301:"+shardedJedis.setnx("key301", "value301"));
System.out.println("原先key302不存在时,新增key302:"+shardedJedis.setnx("key302", "value302"));
System.out.println("当key302存在时,尝试新增key302:"+shardedJedis.setnx("key302", "value302_new"));
System.out.println("获取key301对应的值:"+shardedJedis.get("key301"));
System.out.println("获取key302对应的值:"+shardedJedis.get("key302"));
System.out.println("=============超过有效期键值对被删除=============");
// 设置key的有效期,并存储数据
System.out.println("新增key303,并指定过期时间为2秒"+shardedJedis.setex("key303", 2, "key303-2second"));
System.out.println("获取key303对应的值:"+shardedJedis.get("key303"));
try{
Thread.sleep(3000);
}
catch (InterruptedException e){
}
System.out.println("3秒之后,获取key303对应的值:"+shardedJedis.get("key303"));
System.out.println("=============获取原值,更新为新值一步完成=============");
System.out.println("key302原值:"+shardedJedis.getSet("key302", "value302-after-getset"));
System.out.println("key302新值:"+shardedJedis.get("key302"));
System.out.println("=============获取子串=============");
System.out.println("获取key302对应值中的子串:"+shardedJedis.getrange("key302", 5, 7));
}在main方法中运行该方法,结果如下:
======================String_1==========================
清空库中所有数据:OK
=============增=============
已新增的3个键值对如下:
value001
value002
value003
=============删=============
删除key003键值对:1
获取key003键对应的值:null
=============改=============
直接覆盖key001原来的数据:OK
获取key001对应的新值:value001-update
在key002原来值后面追加:21
获取key002对应的新值value002+appendString
=============增,删,查(多个)=============
一次性新增key201,key202,key203,key204及其对应值:OK
一次性获取key201,key202,key203,key204各自对应的值:[value201, value202, value203, value204]
一次性删除key201,key202:2
一次性获取key201,key202,key203,key204各自对应的值:[null, null, value203, value204]
======================String_2==========================
清空库中所有数据:OK
=============新增键值对时防止覆盖原先值=============
原先key301不存在时,新增key301:1
原先key302不存在时,新增key302:1
当key302存在时,尝试新增key302:0
获取key301对应的值:value301
获取key302对应的值:value302
=============超过有效期键值对被删除=============
新增key303,并指定过期时间为2秒OK
获取key303对应的值:key303-2second
3秒之后,获取key303对应的值:null
=============获取原值,更新为新值一步完成=============
key302原值:value302
key302新值:value302-after-getset
=============获取子串=============
获取key302对应值中的子串:302
private void ListOperate() {
System.out.println("======================list==========================");
// 清空数据
System.out.println("清空库中所有数据:"+jedis.flushDB());
System.out.println("=============增=============");
shardedJedis.lpush("stringlists", "vector");
shardedJedis.lpush("stringlists", "ArrayList");
shardedJedis.lpush("stringlists", "vector");
shardedJedis.lpush("stringlists", "vector");
shardedJedis.lpush("stringlists", "LinkedList");
shardedJedis.lpush("stringlists", "MapList");
shardedJedis.lpush("stringlists", "SerialList");
shardedJedis.lpush("stringlists", "HashList");
shardedJedis.lpush("numberlists", "3");
shardedJedis.lpush("numberlists", "1");
shardedJedis.lpush("numberlists", "5");
shardedJedis.lpush("numberlists", "2");
System.out.println("所有元素-stringlists:"+shardedJedis.lrange("stringlists", 0, -1));
System.out.println("所有元素-numberlists:"+shardedJedis.lrange("numberlists", 0, -1));
System.out.println("=============删=============");
// 删除列表指定的值 ,第二个参数为删除的个数(有重复时),后add进去的值先被删,类似于出栈
System.out.println("成功删除指定元素个数-stringlists:"+shardedJedis.lrem("stringlists", 2, "vector"));
System.out.println("删除指定元素之后-stringlists:"+shardedJedis.lrange("stringlists", 0, -1));
// 删除区间以外的数据
System.out.println("删除下标0-3区间之外的元素:"+shardedJedis.ltrim("stringlists", 0, 3));
System.out.println("删除指定区间之外元素后-stringlists:"+shardedJedis.lrange("stringlists", 0, -1));
// 列表元素出栈
System.out.println("出栈元素:"+shardedJedis.lpop("stringlists"));
System.out.println("元素出栈后-stringlists:"+shardedJedis.lrange("stringlists", 0, -1));
System.out.println("=============改=============");
// 修改列表中指定下标的值
shardedJedis.lset("stringlists", 0, "hello list!");
System.out.println("下标为0的值修改后-stringlists:"+shardedJedis.lrange("stringlists", 0, -1));
System.out.println("=============查=============");
// 数组长度
System.out.println("长度-stringlists:"+shardedJedis.llen("stringlists"));
System.out.println("长度-numberlists:"+shardedJedis.llen("numberlists"));
// 排序
/*
* list中存字符串时必须指定参数为alpha,如果不使用SortingParams,而是直接使用sort("list"),
* 会出现"ERR One or more scores can't be converted into double"
*/
SortingParams sortingParameters = new SortingParams();
sortingParameters.alpha();
sortingParameters.limit(0, 3);
System.out.println("返回排序后的结果-stringlists:"+shardedJedis.sort("stringlists",sortingParameters));
System.out.println("返回排序后的结果-numberlists:"+shardedJedis.sort("numberlists"));
// 子串: start为元素下标,end也为元素下标;-1代表倒数一个元素,-2代表倒数第二个元素
System.out.println("子串-第二个开始到结束:"+shardedJedis.lrange("stringlists", 1, -1));
// 获取列表指定下标的值
System.out.println("获取下标为2的元素:"+shardedJedis.lindex("stringlists", 2)+"\n");
}在main方法中运行该方法,结果如下:
======================list==========================
清空库中所有数据:OK
=============增=============
所有元素-stringlists:[HashList, SerialList, MapList, LinkedList, vector, vector, ArrayList, vector]
所有元素-numberlists:[2, 5, 1, 3]
=============删=============
成功删除指定元素个数-stringlists:2
删除指定元素之后-stringlists:[HashList, SerialList, MapList, LinkedList, ArrayList, vector]
删除下标0-3区间之外的元素:OK
删除指定区间之外元素后-stringlists:[HashList, SerialList, MapList, LinkedList]
出栈元素:HashList
元素出栈后-stringlists:[SerialList, MapList, LinkedList]
=============改=============
下标为0的值修改后-stringlists:[hello list!, MapList, LinkedList]
=============查=============
长度-stringlists:3
长度-numberlists:4
返回排序后的结果-stringlists:[LinkedList, MapList, hello list!]
返回排序后的结果-numberlists:[1, 2, 3, 5]
子串-第二个开始到结束:[MapList, LinkedList]
获取下标为2的元素:LinkedList
private void SetOperate() {
System.out.println("======================set==========================");
// 清空数据
System.out.println("清空库中所有数据:"+jedis.flushDB());
System.out.println("=============增=============");
System.out.println("向sets集合中加入元素element001:"+jedis.sadd("sets", "element001"));
System.out.println("向sets集合中加入元素element002:"+jedis.sadd("sets", "element002"));
System.out.println("向sets集合中加入元素element003:"+jedis.sadd("sets", "element003"));
System.out.println("向sets集合中加入元素element004:"+jedis.sadd("sets", "element004"));
System.out.println("查看sets集合中的所有元素:"+jedis.smembers("sets"));
System.out.println();
System.out.println("=============删=============");
System.out.println("集合sets中删除元素element003:"+jedis.srem("sets", "element003"));
System.out.println("查看sets集合中的所有元素:"+jedis.smembers("sets"));
/*System.out.println("sets集合中任意位置的元素出栈:"+jedis.spop("sets"));//注:出栈元素位置居然不定?--无实际意义
System.out.println("查看sets集合中的所有元素:"+jedis.smembers("sets"));*/
System.out.println();
System.out.println("=============改=============");
System.out.println();
System.out.println("=============查=============");
System.out.println("判断element001是否在集合sets中:"+jedis.sismember("sets", "element001"));
System.out.println("循环查询获取sets中的每个元素:");
Set<String> set = jedis.smembers("sets");
Iterator<String> it=set.iterator() ;
while(it.hasNext()){
Object obj=it.next();
System.out.println(obj);
}
System.out.println();
System.out.println("=============集合运算=============");
System.out.println("sets1中添加元素element001:"+jedis.sadd("sets1", "element001"));
System.out.println("sets1中添加元素element002:"+jedis.sadd("sets1", "element002"));
System.out.println("sets1中添加元素element003:"+jedis.sadd("sets1", "element003"));
System.out.println("sets1中添加元素element002:"+jedis.sadd("sets2", "element002"));
System.out.println("sets1中添加元素element003:"+jedis.sadd("sets2", "element003"));
System.out.println("sets1中添加元素element004:"+jedis.sadd("sets2", "element004"));
System.out.println("查看sets1集合中的所有元素:"+jedis.smembers("sets1"));
System.out.println("查看sets2集合中的所有元素:"+jedis.smembers("sets2"));
System.out.println("sets1和sets2交集:"+jedis.sinter("sets1", "sets2"));
System.out.println("sets1和sets2并集:"+jedis.sunion("sets1", "sets2"));
System.out.println("sets1和sets2差集:"+jedis.sdiff("sets1", "sets2"));//差集:set1中有,set2中没有的元素
}在main方法中运行该方法,结果如下:
======================set==========================
清空库中所有数据:OK
=============增=============
向sets集合中加入元素element001:1
向sets集合中加入元素element002:1
向sets集合中加入元素element003:1
向sets集合中加入元素element004:1
查看sets集合中的所有元素:[element004, element001, element003, element002]
=============删=============
集合sets中删除元素element003:1
查看sets集合中的所有元素:[element004, element001, element002]
=============改=============
=============查=============
判断element001是否在集合sets中:true
循环查询获取sets中的每个元素:
element004
element001
element002
=============集合运算=============
sets1中添加元素element001:1
sets1中添加元素element002:1
sets1中添加元素element003:1
sets1中添加元素element002:1
sets1中添加元素element003:1
sets1中添加元素element004:1
查看sets1集合中的所有元素:[element001, element003, element002]
查看sets2集合中的所有元素:[element004, element003, element002]
sets1和sets2交集:[element003, element002]
sets1和sets2并集:[element001, element002, element003, element004]
sets1和sets2差集:[element001]
private void SortedSetOperate() {
System.out.println("======================zset==========================");
// 清空数据
System.out.println(jedis.flushDB());
System.out.println("=============增=============");
System.out.println("zset中添加元素element001:"+shardedJedis.zadd("zset", 7.0, "element001"));
System.out.println("zset中添加元素element002:"+shardedJedis.zadd("zset", 8.0, "element002"));
System.out.println("zset中添加元素element003:"+shardedJedis.zadd("zset", 2.0, "element003"));
System.out.println("zset中添加元素element004:"+shardedJedis.zadd("zset", 3.0, "element004"));
System.out.println("zset集合中的所有元素:"+shardedJedis.zrange("zset", 0, -1));//按照权重值排序
System.out.println();
System.out.println("=============删=============");
System.out.println("zset中删除元素element002:"+shardedJedis.zrem("zset", "element002"));
System.out.println("zset集合中的所有元素:"+shardedJedis.zrange("zset", 0, -1));
System.out.println();
System.out.println("=============改=============");
System.out.println();
System.out.println("=============查=============");
System.out.println("统计zset集合中的元素中个数:"+shardedJedis.zcard("zset"));
System.out.println("统计zset集合中权重某个范围内(1.0——5.0),元素的个数:"+shardedJedis.zcount("zset", 1.0, 5.0));
System.out.println("查看zset集合中element004的权重:"+shardedJedis.zscore("zset", "element004"));
System.out.println("查看下标1到2范围内的元素值:"+shardedJedis.zrange("zset", 1, 2));
}在main方法中运行该方法,结果如下:
======================zset==========================
OK
=============增=============
zset中添加元素element001:1
zset中添加元素element002:1
zset中添加元素element003:1
zset中添加元素element004:1
zset集合中的所有元素:[element003, element004, element001, element002]
=============删=============
zset中删除元素element002:1
zset集合中的所有元素:[element003, element004, element001]
=============改=============
=============查=============
统计zset集合中的元素中个数:3
统计zset集合中权重某个范围内(1.0——5.0),元素的个数:2
查看zset集合中element004的权重:3.0
查看下标1到2范围内的元素值:[element004, element001]
private void HashOperate() {
System.out.println("======================hash==========================");
//清空数据
System.out.println(jedis.flushDB());
System.out.println("=============增=============");
System.out.println("hashs中添加key001和value001键值对:"+shardedJedis.hset("hashs", "key001", "value001"));
System.out.println("hashs中添加key002和value002键值对:"+shardedJedis.hset("hashs", "key002", "value002"));
System.out.println("hashs中添加key003和value003键值对:"+shardedJedis.hset("hashs", "key003", "value003"));
System.out.println("新增key004和4的整型键值对:"+shardedJedis.hincrBy("hashs", "key004", 4l));
System.out.println("hashs中的所有值:"+shardedJedis.hvals("hashs"));
System.out.println();
System.out.println("=============删=============");
System.out.println("hashs中删除key002键值对:"+shardedJedis.hdel("hashs", "key002"));
System.out.println("hashs中的所有值:"+shardedJedis.hvals("hashs"));
System.out.println();
System.out.println("=============改=============");
System.out.println("key004整型键值的值增加100:"+shardedJedis.hincrBy("hashs", "key004", 100l));
System.out.println("hashs中的所有值:"+shardedJedis.hvals("hashs"));
System.out.println();
System.out.println("=============查=============");
System.out.println("判断key003是否存在:"+shardedJedis.hexists("hashs", "key003"));
System.out.println("获取key004对应的值:"+shardedJedis.hget("hashs", "key004"));
System.out.println("批量获取key001和key003对应的值:"+shardedJedis.hmget("hashs", "key001", "key003"));
System.out.println("获取hashs中所有的key:"+shardedJedis.hkeys("hashs"));
System.out.println("获取hashs中所有的value:"+shardedJedis.hvals("hashs"));
System.out.println();
}在main方法中运行该方法,结果如下:
======================hash==========================
OK
=============增=============
hashs中添加key001和value001键值对:1
hashs中添加key002和value002键值对:1
hashs中添加key003和value003键值对:1
新增key004和4的整型键值对:4
hashs中的所有值:[value001, value002, value003, 4]
=============删=============
hashs中删除key002键值对:1
hashs中的所有值:[value001, value003, 4]
=============改=============
key004整型键值的值增加100:104
hashs中的所有值:[value001, value003, 104]
=============查=============
判断key003是否存在:true
获取key004对应的值:104
批量获取key001和key003对应的值:[value001, value003]
获取hashs中所有的key:[key004, key003, key001]
获取hashs中所有的value:[value001, value003, 104]
Spring对Redis的Key-Value数据存储操作提供了更高层次的抽象,因此选择spring-boot-starter-data-redis来实现第二个demo。
- 首先,新建spring boot工程,pom文件内容如下:
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.jianeye</groupId>
<artifactId>redisblog</artifactId>
<version>0.0.1-SNAPSHOT</version>
<packaging>jar</packaging>
<name>RedisBlog</name>
<description>Redis Blog Test</description>
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>1.4.0.RELEASE</version>
<relativePath/>
</parent>
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<project.reporting.outputEncoding>UTF-8</project.reporting.outputEncoding>
<java.version>1.8</java.version>
</properties>
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter</artifactId>
</dependency>
<!-- 无需引用web依赖,spring-boot-starter-thymeleaf已经依赖 -->
<!-- <dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency> -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-redis</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-thymeleaf</artifactId>
</dependency>
<!-- UTILS -->
<dependency>
<groupId>com.fasterxml.jackson.core</groupId>
<artifactId>jackson-databind</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-maven-plugin</artifactId>
</plugin>
</plugins>
</build>
</project>引入了thymeleaf作为视图模板引擎,Thymeleaf 是一个跟 Velocity、FreeMarker 类似的模板引擎,它可以完全替代 JSP 。相较与其他的模板引擎,Thymeleaf 在有网络和无网络的环境下皆可运行,即它可以让美工在浏览器查看页面的静态效果,也可以让程序员在服务器查看带数据的动态页面效果。这是由于它支持 html 原型,然后在 html 标签里增加额外的属性来达到模板+数据的展示方式。浏览器解释 html 时会忽略未定义的标签属性,所以 thymeleaf 的模板可以静态地运行;当有数据返回到页面时,Thymeleaf 标签会动态地替换掉静态内容,使页面动态显示。
- 使用配置文件 application.yml 配置服务器参数、Redis参数等。
server:
port: 8091
context-path: #不写应用根目录
sessionTimeout: 30
logging:
level:
com.jianeye.redis.blog: DEBUG
spring:
redis:
host: 192.168.3.30
port: 6379
password:
database: 0
timeout: 0
pool:
max-active: 8
max-idle: 8
max-wait: -1
min-idle: 0
testOnBorrow: true # 当调用borrow Object方法时,是否进行有效性检查
sentinel:
master: # Name of Redis server.
nodes: # Comma-separated list of host:port pairs.
mvc:
view:
prefix: /templates/
suffix: .html
thymeleaf: # Allow Thymeleaf templates to be reloaded at dev time
cache: false- 编写Redis配置类RedisConfig.java。
package com.jianeye.redis.blog.config;
Configuration
EnableCaching
public class RedisConfig extends CachingConfigurerSupport {
@Value("${spring.redis.host}")
private String host;
@Value("${spring.redis.port}")
private int port;
@Value("${spring.redis.timeout}")
private int timeout;
@Bean
public JedisConnectionFactory redisConnectionFactory() {
JedisConnectionFactory factory = new JedisConnectionFactory();
factory.setHostName(host);
factory.setPort(port);
factory.setTimeout(timeout);
factory.setUsePool(true);
return factory;
}
@Bean
public CacheManager cacheManager(@SuppressWarnings("rawtypes")RedisTemplate redisTemplate) {
return new RedisCacheManager(redisTemplate);
}
@Bean
public RedisTemplate<String, String> redisTemplate(RedisConnectionFactory factory) {
StringRedisTemplate template = new StringRedisTemplate(factory);
//设置序列化工具,这样Bean不需要实现Serializable接口
setSerializer(template);
template.afterPropertiesSet();
return template;
}
private void setSerializer(StringRedisTemplate template) {
@SuppressWarnings({ "rawtypes", "unchecked" })
Jackson2JsonRedisSerializer jackson2JsonRedisSerializer = new Jackson2JsonRedisSerializer(Object.class);
ObjectMapper om = new ObjectMapper();
om.setVisibility(PropertyAccessor.ALL, JsonAutoDetect.Visibility.ANY);
om.enableDefaultTyping(ObjectMapper.DefaultTyping.NON_FINAL);
jackson2JsonRedisSerializer.setObjectMapper(om);
template.setValueSerializer(jackson2JsonRedisSerializer);
}
@Bean
public KeyGenerator keyGenerator(){
return new KeyGenerator() {
@Override
public Object generate(Object target, Method method, Object... params) {
StringBuilder sb = new StringBuilder();
sb.append(target.getClass().getName());
sb.append(method.getName());
for (Object obj : params) {
sb.append(obj.toString());
}
return sb.toString();
}
};
}
}- 贴出Spring Boot 启动类RedisDatabaseApp.java代码
package com.jianeye.redis.blog;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
@SpringBootApplication
public class RedisBlogApplication {
public static void main(String[] args) {
SpringApplication.run(RedisBlogApplication.class, args);
}
}- 实体类Blog
package com.jianeye.redis.blog.vo;
/**
* @author xudan
* 博客
*/
public class Blog {
private String id;
private String title;
private String summary;
private String content;
private String author;
private Date createtime;
private Date modifytime;
private String tags;//标签
}- 操作类BlogDao
package com.jianeye.redis.blog.dao;
/**
* @author xudan
* 用户操作类
*/
@SuppressWarnings("unchecked")
@Component
public class BlogDao {
@SuppressWarnings("rawtypes")
@Autowired
private RedisTemplate redisTemplate;
/**
* 获取博客列表
* 列表blog:ids中保存所有博客id,获取列表片段,根据博客id获取对应的博客信息
* @param curPage
* @return
*/
public List<Blog> getList(int curPage) {
Long start = (long)(curPage-1)*Constants.pageNum;
Long end = (long) (curPage*Constants.pageNum-1);
List<Integer> ids = redisTemplate.opsForList().range("blog:ids", start, end);
List<Blog> list = new ArrayList<Blog>();
for(int id : ids ){
Blog b = this.read("blog:"+id);
if(b != null){
list.add(b);
}
}
return list;
}
/**
* 保存博客
* 新增-blog:count键自增,博客id为blog:[blog:count值];将博客id的数字部分保存在列表blog:ids中
* 修改
* 保存博客标签信息,博客所属标签保存在集合[博客ID]:tags中
* 标签下的博客保存在集合tags:[标签名]:blog中
* @param blog
*/
@Transactional
public void save(final Blog blog) {
if(StringUtils.isEmpty(blog.getId())){//新增
blog.setCreatetime(new Date());
Long id = redisTemplate.opsForValue().increment("blog:count", 1);//id自增
blog.setId("blog:"+id);//设置ID
redisTemplate.opsForValue().set(blog.getId(), blog);//保存
redisTemplate.opsForList().leftPush("blog:ids", id);//列表,储存博客ID
//保存字符串类似blog:12345会报错
//com.fasterxml.jackson.core.JsonParseException: Unrecognized token 'blog': was expecting ('true', 'false' or 'null')
String[] tags = blog.getTags().split(" ");
if(tags != null && tags.length>0){
for(String tag :tags){
redisTemplate.opsForSet().add(blog.getId()+":tags", tag);//博客所属标签集合
redisTemplate.opsForSet().add("tags:"+tag+":blog", id);//标签所有博客集合
}
}
}else{//修改
blog.setModifytime(new Date());
redisTemplate.opsForValue().set(blog.getId(), blog);//保存
String idnum = blog.getId().split(":")[1];
String[] tags = blog.getTags().split(" ");
if(tags != null && tags.length>0){
for(String tag :tags){
redisTemplate.opsForSet().add(blog.getId()+":tags", tag);//博客所属标签集合
redisTemplate.opsForSet().add("tags:"+tag+":blog", idnum);//标签所有博客集合
}
}
}
}
/**
* 添加标签,初始化没有博客ID数据,故加0
*/
public void saveTag(String tag){
redisTemplate.opsForSet().add("tags:"+tag+":blog", 0);//添加标签
}
/**
* 根据博客ID获取博客
* @param id
* @return
*/
public Blog read(final String id) {
return (Blog) redisTemplate.opsForValue().get(id);
}
/**
* 删除博客
* @param ids
*/
public void delete(String... ids) {
for (String id : ids) {
delete(id);
}
}
/**
* 删除博客
* @param id
*/
public void delete(final String id) {
if (redisTemplate.hasKey(id)) {
redisTemplate.delete(id);
String idnum = id.split(":")[1];
redisTemplate.opsForList().leftPush("blog:ids", Integer.parseInt(idnum));//列表,储存博客ID
}
}
/**
* 根据博客ID获取其所有标签
* @param blogId
* @return
*/
public Set<String> getTagsByBlog(String blogId) {
Set<String> tags = new HashSet<String>();//
String idnum = blogId.split(":")[1];
tags = redisTemplate.opsForSet().members("blog:"+idnum+":tags");//集合,储存博客所属标签;命名规则:blog:[博客ID]:tags
return tags;
}
/**
* 根据标签获取其所有博客
* @param blogId
* @return
*/
public List<Blog> getBlogsByTag(String tag) {
Set<Integer> tags = new HashSet<Integer>();//
List<Blog> list = new ArrayList<Blog>();
tags = redisTemplate.opsForSet().members("tags:"+tag+":blog");//集合,储存标签所有博客;标签key命名规则:tags:[标签名]:blog
for(Integer tg : tags ){
Blog b = this.read("blog:"+tg);
if(b != null){
list.add(b);
}
}
return list;
}
/**
* 获取所有标签
* @return
*/
public Set<String> getTags() {
Set<String> result = new HashSet<String>();
Set<String> tags = new HashSet<String>();//获取标签集合键
tags = redisTemplate.keys("tags:*:blog");//获取所有标签;标签key命名规则:tags:[标签名]:blog
for(String tag : tags){
String[] temp = tag.split(":");
result.add(temp[1]);
}
return result;
}
/**
* 增加访问量
* @return
*/
public void readBlog(String blogId) {
String idnum = blogId.split(":")[1];
redisTemplate.opsForZSet().incrementScore("blog:view", Integer.parseInt(idnum), 1);//访问量有序集合
}
/**
* 查看热门排行
* @param curPage
* @return
*/
public List<Blog> rank(int curPage) {
Long start = (long)(curPage-1)*Constants.pageNum;
Long end = (long) (curPage*Constants.pageNum-1);
Set<Integer> ids = redisTemplate.opsForZSet().reverseRange("blog:view", start, end);//查看前10
List<Blog> list = new ArrayList<Blog>();
for(int id : ids ){
Blog b = this.read("blog:"+id);
if(b != null){
list.add(b);
}
}
return list;
}
}- 服务类BlogService
package com.jianeye.redis.blog.service;
/**
*博客类操作Service
* @author xudan
*/
@Service
public class BlogService {
@Autowired
private BlogDao blogDao ;
public List<Blog> getList(int curPage) {
return blogDao.getList(curPage);
}
public Blog findBlog(String id){
return blogDao.read(id);
}
public void saveBlog(Blog blog){
blogDao.save(blog);
}
public void deleteBlog(String id){
blogDao.delete(id);
}
public Set<String> getTags() {
return blogDao.getTags();
}
public Set<String> getTagsByBlog(String blogId){
return blogDao.getTagsByBlog(blogId);
}
public List<Blog> getBlogsByTag(String tag) {
return blogDao.getBlogsByTag(tag);
}
public void saveTag(String tag){
blogDao.saveTag(tag);
}
public void readBlog(String blogId) {
blogDao.readBlog(blogId);
}
public List<Blog> rank(int curPage) {
return blogDao.rank(curPage);
}
}- 控制类BlogController
package com.jianeye.redis.blog.controller;
/**
* 博客类Controller
* @author xudan
*/
@Controller
@RequestMapping("/blog")
public class BlogController {
@Autowired
private BlogService blogService ;
@RequestMapping("/main")
public ModelAndView main(@RequestParam(value="curPage",required = false) Integer curPage){
ModelAndView mv = new ModelAndView("blog/main");
List<Blog> bloglist = blogService.getList((curPage == null || curPage == 0)? 1 : curPage);
mv.addObject("bloglist", bloglist);
mv.addObject("msg", "");
return mv;
}
@RequestMapping("/add")
public ModelAndView add(){
ModelAndView mv = new ModelAndView("blog/edit");
Blog blog = new Blog();
Set<String> tags = blogService.getTags();
mv.addObject("blog", blog);
mv.addObject("tags",tags);
return mv;
}
@RequestMapping("/edit")
public ModelAndView edit(@RequestParam String id){
ModelAndView mv = new ModelAndView("blog/edit");
Blog blog = blogService.findBlog(id);
Set<String> tags = blogService.getTags();
mv.addObject("blog", blog);
mv.addObject("tags",tags);
return mv;
}
@RequestMapping("/save")
public ModelAndView save(Blog blog){
ModelAndView mv = new ModelAndView("blog/main");
String msg = "";
try{
blogService.saveBlog(blog);
msg = "保存成功!";
}catch(Exception e){
msg = "保存失败!";
}
List<Blog> bloglist = blogService.getList(1);
mv.addObject("bloglist", bloglist);
mv.addObject("msg", msg);
return mv;
}
@RequestMapping("/del")
public ModelAndView del(@RequestParam String id){
ModelAndView mv = new ModelAndView("blog/main");
String msg = "";
try{
blogService.deleteBlog(id);
msg = "删除成功!";
}catch(Exception e){
msg = "删除失败!";
}
List<Blog> bloglist = blogService.getList(1);
mv.addObject("bloglist", bloglist);
mv.addObject("msg", msg);
return mv;
}
@RequestMapping("/tags")
@ResponseBody
public Object getTags(){
Map<String,Object> result = new HashMap<String,Object>();
try{
Set<String> tags = blogService.getTags();
result.put("code", Constants.SUCCESS);
result.put("data", tags);
}catch(Exception e){
result.put("code", Constants.FAILURE);
}
return result;
}
@RequestMapping("/tagsOfBlog")
@ResponseBody
public Object getTagsOfBlog(@RequestParam String id){
Map<String,Object> result = new HashMap<String,Object>();
try{
if(StringUtils.isEmptyOrWhitespace(id)){
result.put("code", Constants.FAILURE);
}else{
Set<String> tags = blogService.getTagsByBlog(id);
result.put("code", Constants.SUCCESS);
result.put("data", tags);
}
}catch(Exception e){
result.put("code", Constants.FAILURE);
}
return result;
}
@RequestMapping("/addtags")
public ModelAndView addtags(String tag){
ModelAndView mv = new ModelAndView("blog/main");
String msg = "";
try{
if(StringUtils.isEmptyOrWhitespace(tag)){
msg = "标签为空!";
}else{
blogService.saveTag(tag);
msg = "保存成功!";
}
}catch(Exception e){
msg = "保存失败!";
}
List<Blog> bloglist = blogService.getList(1);
mv.addObject("bloglist", bloglist);
mv.addObject("msg", msg);
return mv;
}
@RequestMapping("/getBlogsByTag")
public ModelAndView getBlogsByTag(String tag){
ModelAndView mv = new ModelAndView("blog/main");
String msg = "";
if(StringUtils.isEmptyOrWhitespace(tag)){
msg = "标签为空!";
}else{
List<Blog> bloglist = blogService.getBlogsByTag(tag);
mv.addObject("bloglist", bloglist);
}
mv.addObject("msg", msg);
return mv;
}
@RequestMapping("/readBlog")
@ResponseBody
public Object readBlog(String id){
Map<String,Object> result = new HashMap<String,Object>();
if(StringUtils.isEmptyOrWhitespace(id)){
result.put("code", Constants.FAILURE);
}else{
blogService.readBlog(id);
result.put("code", Constants.SUCCESS);
}
return result;
}
@RequestMapping("/rank")
public ModelAndView rank(@RequestParam(value="curPage",required = false) Integer curPage){
ModelAndView mv = new ModelAndView("blog/main");
List<Blog> bloglist = blogService.rank((curPage == null || curPage == 0)? 1 : curPage);
mv.addObject("bloglist", bloglist);
mv.addObject("msg", "");
return mv;
}
}- 静态资源文件访问配置WebMvcConfig
package com.jianeye.redis.blog.config;
/**
* 静态资源文件
* @author xudan
*/
@Configuration
public class WebMvcConfig extends WebMvcConfigurerAdapter{
/**
* 增加文件访问路径
* 相当于虚拟路径
*/
@Override
public void addResourceHandlers(ResourceHandlerRegistry registry) {
registry.addResourceHandler("/**").addResourceLocations("classpath:/static/");
registry.addResourceHandler("/static/**").addResourceLocations("classpath:/static/");
}
}- 测试页面
页面引用了bootstrap和jQuery
src\main\resources\templates\blog\main.html
<!DOCTYPE html>
<html xmlns="http://www.w3.org/1999/xhtml"
xmlns:th="http://www.thymeleaf.org">
<head>
<meta charset="UTF-8"></meta>
<title th:text="首页">首页</title>
<link rel="stylesheet" type="text/css" th:href="@{/static/lib/bootstrap/css/bootstrap.css}"></link>
<style>
.tgsplit{
width:100px;
height:30px;
border:1px solid blue;
margin-right:20px;
background:;
cursor:pointer;
}
</style>
<script type="text/javascript" th:src="@{/static/lib/jquery-3.1.0.min.js}"></script>
<script type="text/javascript" th:src="@{/static/lib/bootstrap/js/bootstrap.js}"></script>
<script type="text/javascript" th:src="@{/static/js/blog/main.js}"></script>
</head>
<body>
<div class="container-fluid">
<div class="row">
<div class="col-md-2" style="background: linear-gradient(to right, red , blue);">
</div>
<div class="col-md-10">
<div>
<hr></hr>
<form role="form" class="form-inline" action="#" th:action="@{/blog/addtags}" method="post" th:method="post">
<input type="text" class="form-control" id="tag" name="tag"></input>
<button type="submit" class="btn btn-warning">添加标签</button>
<a class="btn btn-info" th:href="@{/blog/add}">新增博客</a>
<a class="btn btn-success" th:href="@{/blog/rank}">查看热门</a>
</form>
<hr></hr>
<span id="tagsspan"></span>
<hr></hr>
</div>
<ul th:each="blog:${bloglist}" class="list-unstyled">
<li th:text="${blogStat.count}">1</li>
<li><a href="javascript:void(0);" th:onclick="'javascript:readBlog(\''+${blog.id}+'\')'" th:text="${blog.title}">学习使用redis为数据库</a></li>
<li><footer th:text="${blog.summary}">redis大都作为缓存使用,很少真的用作数据库啊</footer></li>
<li th:text="${#dates.format(blog.createtime, 'yyyy-MM-dd')}">2016-09-06></li>
<li>
<a th:href="@{/blog/edit/(id=${blog.id})}">修改</a>
<a th:href="@{/blog/del/(id=${blog.id})}">删除</a>
</li>
</ul>
<div th:text="${msg}">
欢迎!
</div>
</div>
</div>
</div>
</body>
</html>src\main\resources\static\js\blog\main.js
$(function(){
var allTags = getTags();
if(allTags){
var tp = "";
for(var t in allTags){
tp += "<span class='tgsplit'>"+allTags[t]+"</span>";
}
$("#tagsspan").html(tp);
}
$(".tgsplit").click(function(){
var val = $(this).text();
if(val){
location.href = "/blog/getBlogsByTag?tag="+val;
}
})
})
/**获取标签*/
function getTags(){
var res = [];
$.ajax({
url: "/blog/tags",
type: 'GET' ,
async : false,
dataType: 'json' ,
success : function (data) {
if(data.code == "success"){
console.log(data.data);
res = data.data;
}
},
error: function (response) {
//console.log(response);
}
});
return res;
}
function readBlog(id){
if(id){
$.ajax({
url: "/blog/readBlog",
type: 'GET' ,
async : false,
data : "id="+id,
dataType: 'json' ,
success : function (data) {
if(data.code == "success"){
alert("OK")
}
},
error: function (response) {
//console.log(response);
}
});
}
}src\main\resources\templates\blog\edit.html
<!DOCTYPE html>
<html xmlns="http://www.w3.org/1999/xhtml"
xmlns:th="http://www.thymeleaf.org">
<head>
<meta charset="UTF-8"></meta>
<title th:text="博客">博客</title>
<link rel="stylesheet" type="text/css" th:href="@{/static/lib/bootstrap/css/bootstrap.css}"></link>
<style>
.tgsplit{
width:100px;
height:30px;
border:1px solid green;
margin-right:20px;
cursor:pointer;
}
</style>
<script type="text/javascript" th:src="@{/static/lib/jquery-3.1.0.min.js}"></script>
<script type="text/javascript" th:src="@{/static/lib/bootstrap/js/bootstrap.js}"></script>
<script type="text/javascript" th:src="@{/static/js/blog/edit.js}"></script>
</head>
<body>
<div class="container-fluid">
<div class="row">
<div class="col-md-2">
<div style="width:100%;height:100%;background: linear-gradient(to right, red , blue);"></div>
</div>
<div class="col-md-10">
<form role="form" action="#" th:action="@{/blog/save}" method="post" th:method="post" th:object="${blog}">
<div class="form-group">
<input type="hidden" class="form-control" id="id" name="id" th:field="*{id}"></input>
<label for="title">标题</label>
<input type="text" class="form-control" id="title" name="title" th:field="*{title}" placeholder="请输入标题"/>
</div>
<div class="form-group">
<label for="content">内容</label>
<textarea class="form-control" id="content" name="content" th:field="*{content}" placeholder="请输入内容">内容</textarea>
</div>
<div class="form-group">
<label for="summary">摘要</label>
<textarea class="form-control" id="summary" name="summary" th:field="*{summary}" placeholder="请输入摘要">摘要</textarea>
</div>
<div class="form-group">
<label for="tags">标签</label>
<input type="text" class="form-control" id="tags" name="tags" th:field="*{tags}" />
<span id="tagsspan"></span>
</div>
<button type="submit" class="btn btn-success">保存</button>
<a th:href="@{/blog/main}" href="#" class="btn btn-info">返回</a>
</form>
</div>
</div>
</div>
</body>
</html>src\main\resources\static\js\blog\edit.js
$(function(){
var id = $("#id").val();
var allTags = getTags();
var tags = getTagsOfBlog(id);
if(allTags){
var tp = "";
for(var t in allTags){
tp += "<span class='tgsplit'>"+allTags[t]+"</span>";
}
$("#tagsspan").html(tp);
}
$(".tgsplit").click(function(){
var val = $(this).text();
var tags = $("#tags").val();
if(tags.indexOf(val) == -1){
$("#tags").val(tags+" "+val);
}
})
})
function getTags(){
var res = [];
$.ajax({
url: "/blog/tags",
type: 'GET' ,
async : false,
dataType: 'json' ,
success : function (data) {
if(data.code == "success"){
console.log(data.data);
res = data.data;
}
},
error: function (response) {
//console.log(response);
}
});
return res;
}
function getTagsOfBlog(id){
var res = [];
if(id){
$.ajax({
url: "/blog/tagsOfBlog",
type: 'GET' ,
async : false,
data: "id="+id,
dataType: 'json' ,
success : function (data) {
if(data.code == "success"){
console.log(data.data);
res = data.data;
}
},
error: function (response) {
//console.log(response);
}
});
}
return res;
}- 启动项目,开始运行
进入列表页,如图5所示:
图5
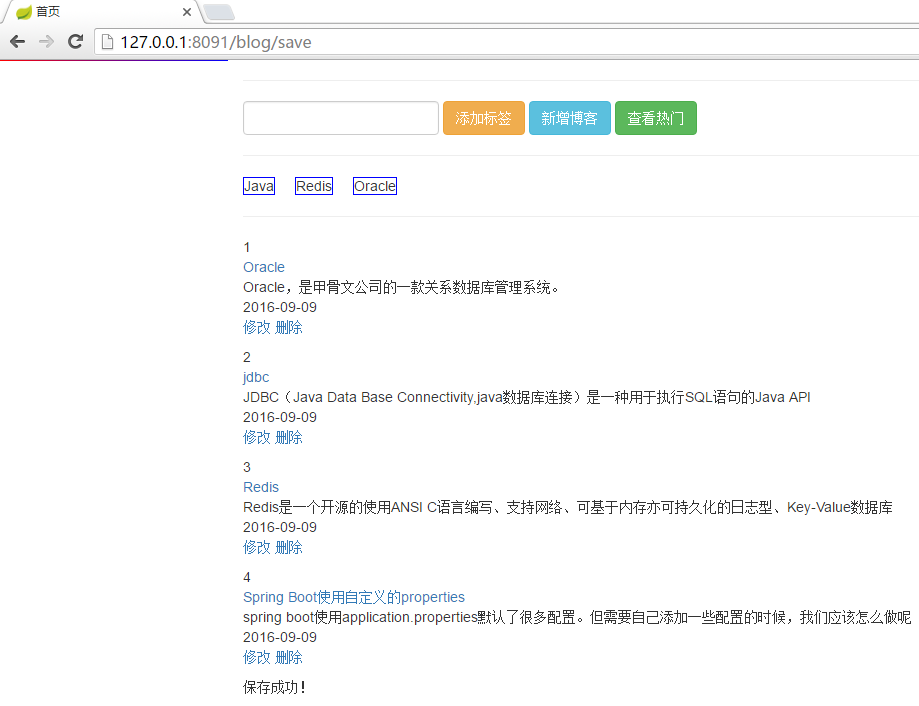
添加标签:页面会列出所有已经添加的标签,由于标签是键,所以不会出现重复的标签;
新增博客:如图6所示:
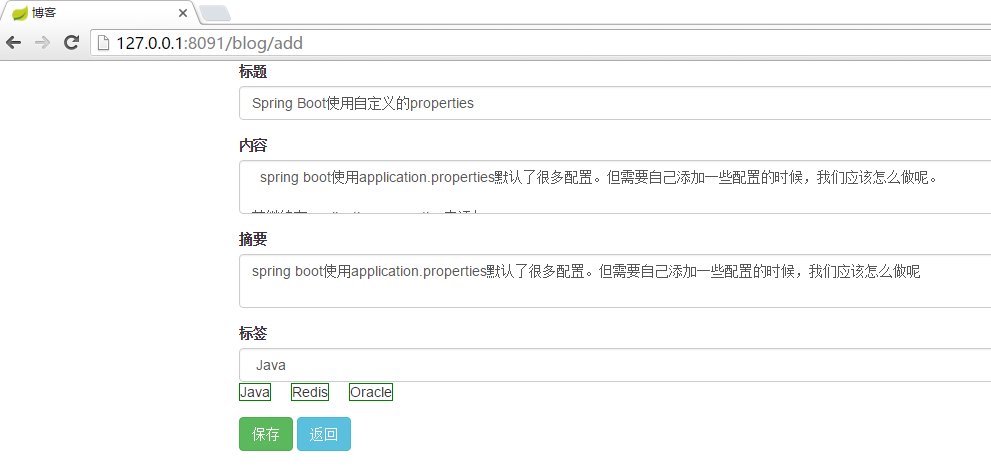
图6
填写博客内容,选择博客标签,博客标签为集合内元素,因此也不会出现重复;
查看热门:点击博客列表的标题,会为该博客的访问量进行累加,查看热门是根据访问量进行排序,获取博客列表的;博客的访问量与博客ID保存在有序集合里,进行排序十分快速。
在redistemplate中配置Serializer
redisTemplate.opsForValue().set(blog.getId(), blog);//保存不在redistemplate中配置Serializer,而是在Service的实现类中单独指定Serializer
boolean result = redisTemplate.execute(new RedisCallback<Boolean>() {
public Boolean doInRedis(RedisConnection redisConnection) throws DataAccessException {
RedisSerializer<String> redisSerializer = redisTemplate .getStringSerializer();
byte[] key = redisSerializer.serialize(user.getId());
byte[] value = redisSerializer.serialize(user.getName());
return redisConnection.setNX(key, value);
}
}); 小结:这个demo中用到了Redis的字符串类型、列表类型、集合类型和有序集合类型,缺少散列类型。同时这个demo简陋无比,漏洞不少,所以接下来就是优化代码,改善设计,首先需要将博客保存为散列类型,这样获取列表时,只需要获取用到的字段,节省资源。
应对不同的应用场景,需要根据实际业务来选择合适的数据类型。选择对了合适的数据类型,可以达到远远优于关系型数据库的效率。目前发布的最新稳定版本是Redis3.2.3,Redis嵌入Lua脚本执行和Redis集群已经都得到了很好地实现,可以实现更多功能,应用范围也更广。未来Redis将进一步发展其in-memory内存和NOSQL数据库服务。
–注:学习所用,大部分内容摘自网络,向原创者致敬















 1041
1041

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









