






KVM中Virtio网络的演化之路_virtio kvm-CSDN博客
1.virtio-net驱动与设备最原始的virtio网络
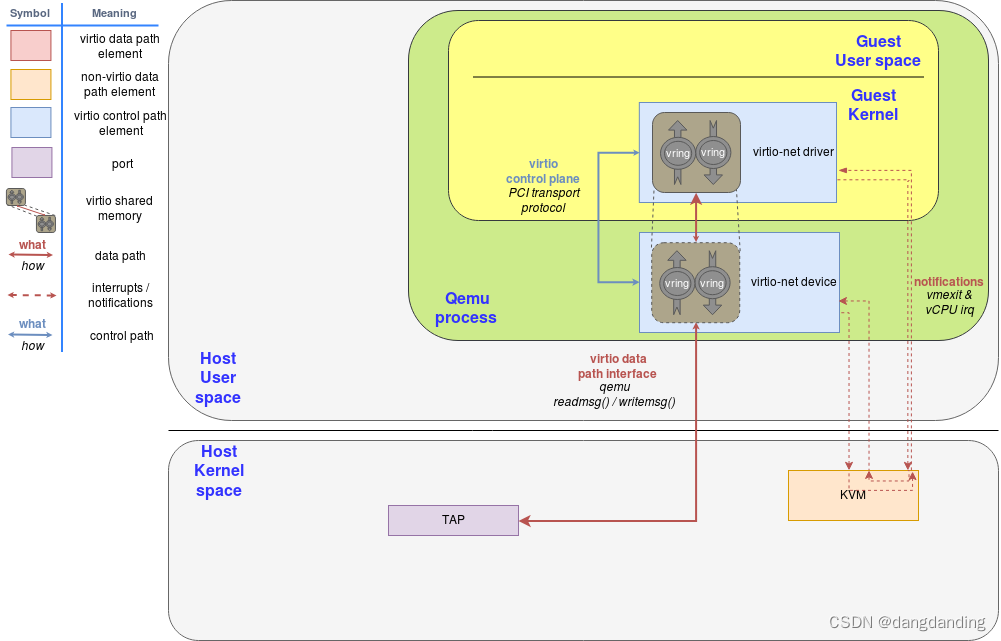
2.vhost-net处于内核态的后端
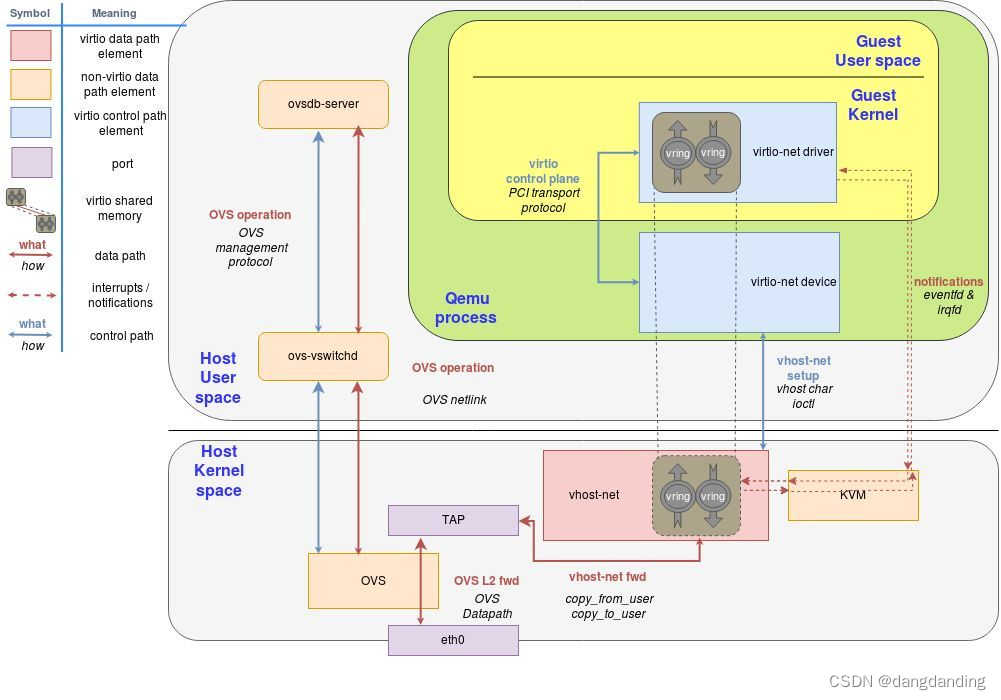
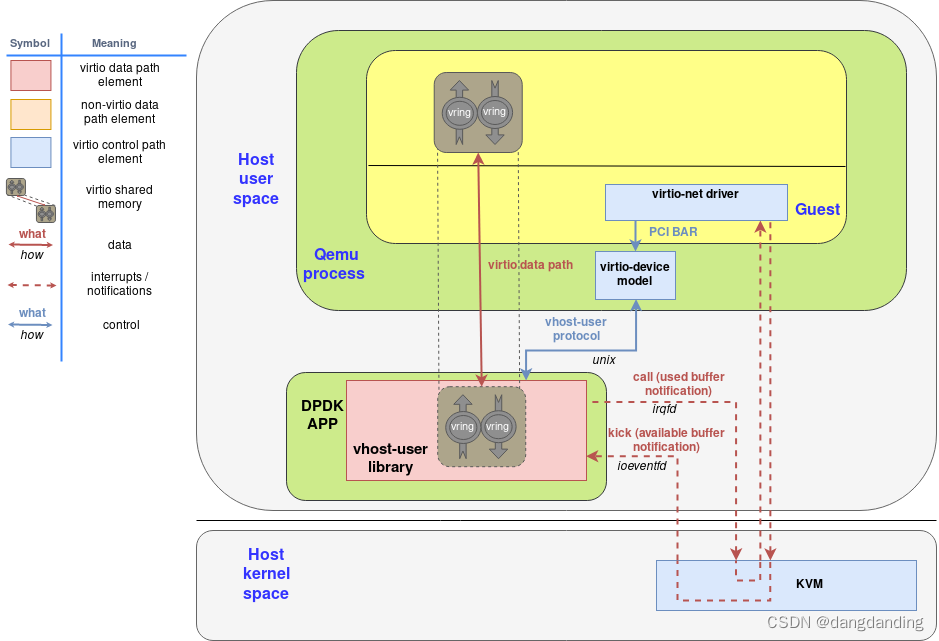
3.vhost-user使用DPDK加速的后端
4.vDPA使用硬件加速数据面
Virtio作为一种半虚拟化的解决方案,其性能一直不如设备的pass-through,即将物理设备(通常是网卡的VF)直接分配给虚拟机,其优点在于数据平面是在虚拟机与硬件之间直通的,几乎不需要主机的干预。而virtio的发展,虽然带来了性能的提升,可终究无法达到pass-through的I/O性能,始终需要主机(主要是软件交换机)的干预。
vDPA(vhost Data Path Acceleration)即是让virtio数据平面不需主机干预的解决方案
DPDK virtio-user介绍及使用 —lvyilong316
DPDK和容器直接的对接方案,我们知道容器(如Docker)网络一般都采用tap+bridge方案,也就是基于内核的网络通信,即使使用ovs一般也是kernel ovs,而不是dpdk-ovs。那么当我们使用的vswitch是基于DPDK时如何和容器对接呢
OVS - 简介 - 知乎 (zhihu.com)
OVS是一个高质量的,多层虚拟交换机(网络分层的层),其目的是让大规模网络自动化可以通过编程扩展,同时仍然支持标准的管理接口和协议:NetFlow. SFlow ... 等,并且它还支持多个物理机的分布式环境。详情请见http://openvswitch.org / http://lamoop.com/post/2013-11
ovs组成:
1. ovsdb-sever: OVS的数据库服务器,用来存储虚拟交换机的配置信息。它于manager和ovs-vswitchd交换信息使用了OVSDB(JSON-RPC)的方式。
2. ovs-vswitchd: OVS的核心部件,它和上层controller通信遵从OPENFLOW协议,它与ovsdb-server通信使用OVSDB协议,它和内核模块通过netlink通信,它支持多个独立的datapath(网桥),它通过更改flow table实现了绑定,和VLAN等功能。
3. ovs kernel module: OVS的内核模块,处理包交换和隧道,缓存flow,如果在内核的缓存中找到转发规则则转发,否则发向用户空间去处理。
ovs原理-内核流表-01 - 知乎 (zhihu.com)
OVS 和 OVS-DPDK 对比
DPDK和kernel通信的常用方式
DPDK和kernel直接的通信路径也叫做exception path,DPDK支持几种方式让用户空间的报文重新进入内核协议栈。
TAP/TUN设备
Kernel NIC Interface(KNI)
virtio-user+vhost-net
网络虚拟化——virtio
原文链接:https://blog.csdn.net/dillanzhou/article/details/120339795
virtio作为一种通用的虚拟IO设备驱动模型,主要定义了两方面的标准模型和接口:控制面的设备配置和初始化,以及数据面的数据传输。
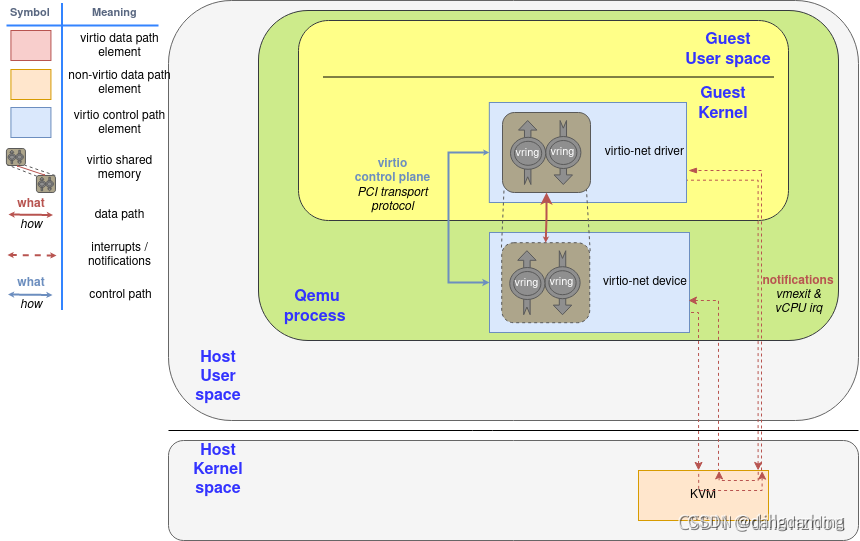
上图是在qemu/kvm虚拟机中实现virtio的架构。可见基本逻辑和其他虚拟网卡是相同的,只是交互方式通过vring队列实现
virtqueue:数据传输模型
virtio中定义了virtqueue作为guest驱动和host后端间的数据传输结构。块设备只需要一个virtqueue用于数据读写,而网络设备则需要两个virtqueue分别用于网络报文的收和发。
1. virtio作为通用的IO虚拟化模型,是如何定义通用的IO控制面和数据面接口的?或者说,基于virtio的网络设备virtio-net和块存储设备virtio-blk,有哪些共通点?
对于控制面,virtio为每个设备封装了virtio_config_ops接口,用于配置和启动设备。
对于数据面,virtio定义了virtqueue抽象传输模型,virtqueue提供了一系列操作接口来完成数据收发和事件通知。virtio_config_ops中的find_vqs接口提供了virtqueue的创建和获取能力。virtqueue具体通过virtio-ring实现,driver向available ring中输入请求,host backend处理请求后向used ring中输入回应。
上述模型和实现是virtio设备通用的,virtio-net和virtio-blk都基于这套模型和接口实现。不同之处只在于使用的virtqueue数量,以及virtqueue/vring中的请求/回应的结构与内容不同,这些都和设备的具体功能和行为密切相关。
2. 在linux内核下,有virtio、virtio-pci、virtio-net、virtio-blk等virtio相关驱动。这些驱动是如何组织的,多个驱动间是什么关系?
linux内核中和virtio相关的驱动主要有:virtio、virtio_ring、virtio_pci、virtio_net、virtio_blk等。其中:
virtio提供了virtio总线和设备控制面的接口。
virtio_ring提供了数据面,也就是virtqueue接口和对应的vring实现。
virtio_pci提供了virtio设备作为PCI设备加载时的通用驱动入口,它依赖virtio和virtio_ring提供的接口。
virtio_net提供了virtio网络设备的标准驱动,它依赖virtio和virtio_ring提供的接口。virtio_net将自己注册为virtio总线的一种设备驱动。
virtio_blk提供了virtio块存储设备的标准驱动,它依赖virtio和virtio_ring提供的接口。virtio_blk将自己注册为virtio总线的一种设备驱动。
3. 一个virtio设备,是如何加入到虚拟机设备模型中,被内核发现和驱动的?
一个virtio PCI设备加载时,内核会尝试所有注册的PCI设备驱动,最后发现可以被virtio_pci驱动。virtio_pci再调用注册到virtio总线上的设备驱动,最后发现可以被virtio_net驱动。virtio_net通过virtio_pci的标准配置接口和host协商设备特性和初始化设备,之后通过virtio_ring提供的接口收发网络数据。
4. virtio-net具体又提供了哪些标准接口?控制面和数据面接口是如何定义的?
virtio设备的控制面和数据面接口都是标准的,只是具体数据格式和含义有区别。virtio-net有自己的feature bit集合,每个virtio-net设备至少使用两个virtqueue用于报文的收和发。virtio-net收发的数据buffer都包括virtio_net_hdr作为头部,用于表示driver和host设置的offload参数。
5. virtio技术为虚拟化而产生,但它能否脱离虚拟化环境使用?例如在普通的容器环境或者物理机环境?
理论上说,virtio设备需要driver和host后端两部分协同完成。在非虚拟化环境下,这个后端可以是内核的vhost模块。vhost模块是在内核中实现的virtio后端功能,是为了进一步提升virtio设备的效率而产生的:
virtio为虚拟IO设备提供了一套标准的接口和实现。同时由于其半虚拟化的特质,virtio驱动在设计和实现时尽可能减少了主要操作路径上会触发host后端操作(vmexit)的指令以提升IO效率。但在执行IO操作时,仍会不可避免的需要触发后端操作。例如virtio-net驱动发包时,在向tx virtqueue写入buffer后必然要kick后端来处理buffer,这个kick就是一个IO写操作。当后端在用户态qemu进程中实现时,这就需要经过guest driver->kvm->qemu->kvm->guest的过程,和普通的虚拟设备驱动是没有区别的,效率仍然低下。为了缩短这个过程,后端实现被放入了内核态,作为一个内核模型/内核线程运行,也就是vhost。有了vhost后,后端操作的流程就变成了guest driver->kvm->vhost->kvm->guest。看似和之前差不多,但是kvm和vhost之间的交互只是一个内核函数调用,性能比之前的kvm和qemu间的用户/内核切换要好的多。同时,使用vhost也提升了后端完成实际IO操作的性能。大部分情况下,后端完成IO操作(例如块设备读写或网络收发)仍然要通过内核接口,例如qemu仍然需要使用文件或socket接口实现,这又需要引入系统调用和状态切换。而使用vhost之后,这些内核能力可以由vhost模块直接调用,又一次减少了状态切换开销。
基于vhost,virtio设备其实不一定需要在虚拟化环境下使用,可以在用户态实现virtio驱动,在初始化时直接与vhost交互完成配置,这样就可以在非虚拟化环境下实现一个用户态的纯虚拟virtio设备。
网络虚拟化——vhost
virtio为虚拟IO设备提供了一套标准的接口和实现。同时由于其半虚拟化的特质,virtio驱动在设计和实现时尽可能减少了主要操作路径上会触发host后端操作(vmexit)的指令以提升IO效率。
但在执行IO操作时,仍会不可避免的需要触发后端操作。例如virtio-net驱动发包时,在向tx virtqueue写入buffer后必然要kick后端来处理buffer,这个kick就是一个IO写操作。当后端在用户态qemu进程中实现时,这就需要经过guest driver->kvm->qemu->kvm->guest的过程,和普通的虚拟设备驱动是没有区别的,效率仍然低下。此外,qemu在向外转发报文时,仍然需要通过系统调用将报文交给内核发送,这又是一次用户态和内核态的切换。
为了缩短这个过程,一种直接的思路就是将virtio后端的实现也放入内核态,作为一个内核模块/内核线程运行。这个思路和KVM类似,将qemu原本在用户态完成的模拟能力转移到内核模块中实现,只是这里要转移的是qemu的设备模拟功能。这项技术称作vhost。
有了vhost后,后端操作的流程就变成了guest driver->kvm->vhost->kvm->guest。看似和之前差不多,但是kvm和vhost之间的交互只是一个内核函数调用,性能比之前的kvm和qemu间的用户/内核切换要好的多。同时,使用vhost也提升了后端完成实际IO操作的性能。大部分情况下,后端完成IO操作(例如块设备读写或网络收发)仍然要通过内核接口,例如qemu仍然需要使用文件或socket接口实现,这又需要引入系统调用和状态切换。而使用vhost之后,这些内核能力可以由vhost模块直接调用,又一次减少了状态切换开销。
redhat的两篇介绍virtio/vhost的文章
Introduction to virtio-networking and vhost-net
Deep dive into Virtio-networking and vhost-net
vhost是一种在内核中提供virtio设备后端功能的技术,其出发点是用于改善虚拟环境下virtio设备的IO性能,避免qemu在用户态实现后端功能所需的大量状态切换和系统调用。
vhost定义了一种基于消息的协议,通过这个协议,virtio后端可以将virtio设备的数据面配置信息转发给另一个组件,从而让这个组件去完成数据面的功能。也就是说,采用vhost技术后,virtio后端的控制面和数据面可以分离成两个组件,控制面组件在完成基本配置后使用vhost协议将数据面配置下发给数据面组件,后续的数据交互由数据面组件实现。
vhost协议只定义了数据面配置的下发规范,数据面能力的具体实现方式由接收vhost消息的组件自己决定。
通过vhost协议,控制面组件主要下发两类数据面配置信息:
virtio后端的内存布局信息,通过这些信息,vhost组件才能够访问virtqueue和virtio driver提供的buffer内存地址一对文件描述符(fd),用于vhost组件与virtio driver间收发通知事件。在kvm场景下这两个fd在vhost和kvm间共享,双方通过这两个fd来互相通知事件,而不需要qemu的参与。
1. vhost支持的是控制面还是数据面的能力?
vhost协议只定义了数据面配置的下发接口,不涉及控制面的能力。vhost-net的实际实现中也是根据接口下发的数据面配置进行数据面交互,不包括控制面的协商和初始化。
2. vhost如何与virtio驱动交互获取控制面信息或数据面数据?
vhost协议并没有规定vhost如何获取配置信息。内核实现的vhost-net是通过对/dev/vhost-net执行ioctl来完成配置的。
3. vhost在获取了virtio设备的操作请求后如何实现后端功能?
vhost根据配置信息获得virtqueue/vring的内存地址,之后就可以通过vring收发数据,vhost-net通过一个tap设备在vring和host间转发报文。vhost配置时还会获得两个fd,用于接收和发送事件通知。
4. 采用vhost后,virtio设备实现是否还依赖于qemu的功能?可否在没有qemu,甚至非虚拟化场景下使用virtio/vhost架构?
在虚拟化场景下,目前的virtio设备仍然依赖qemu实现控制面的协商和vhost-net的配置。但从理论上说qemu并不是必须的,在非虚拟化场景下可以由其他组件来完成virtio虚拟设备的配置。例如DPDK中就支持了virtio-user模式,可以在host用户态进程中直接完成virtio设备配置,并与vhost-net或vhost-user交互,并不需要qemu和kvm来虚拟出一个virtio pci设备。这个模式主要用于在容器网络中使用DPDK,以及让DPDK与内核通信的场景。
5. vhost是否和virtio一样是通用架构,使用vhost支持virtio-net、virtio-blk的后端功能是如何实现的?
vhost协议和具体设备类型无关,linux内核中有vhost模块实现vhost的通用标准接口。除了常用的vhost-net外,也有vhost-blk、vhost-scsi等磁盘块设备的vhost实现。但这些实现并没能进入内核。vhost-blk至少有3次被不同作者提交到内核社区,都没能被合入,主要原因是和qemu中的后端相比性能优势不大,因此没有明显的合入价值。
6. vhost-net是如何实现的,使用vhost-net后virtio-net设备的网络数据收发路径是怎样的?
使用vhost的数据路径大致是virtio-net<-->vhost-net<-->tap<-->kernel stack<-->nic。
原文链接:https://blog.csdn.net/dillanzhou/article/details/120558672
网络虚拟化——vhost-user
在DPDK应用中实现vhost能力,从而在用户态也能达到跳过qemu,让guest virtio driver与外部网络栈高效通讯的效果。DPDK中已经提供了对这个方案的实现支持,称作vhost-user
1. vhost-user如何初始化数据面信息?
vhost-user通过unix socket与qemu进程通信,获取virtqueue的配置信息和内存布局,然后通过mmap实现和qemu/guest的共享内存通信。
2. vhost-user如何和virtio驱动实现共享内存?
如上,vhost-user获取virtqueue内存布局后,通过mmap实现共享内存。
3. vhost-user如何与virtio驱动间实现kick/notify事件通知?
在虚拟机模式下,vhost-user还是和KVM间通过eventfd互相通知事件。KVM再把virtio驱动的kick翻译成ioeventfd写,将vhost-user的irqfd写翻译成guest的irq中断。
4. vhost-user与在qemu中实现的virtio后端有什么区别?
理论上说差别不大,qemu也可以内置vhost-user的实现。只是如果在qemu中实现vhost-user,那么qemu还需要通过另一个队列和DPDK网络应用通信来收发网络数据,因此不如直接将vhost-user集成到DPDK网络应用中效率更高。
5. 除vhost外,virtio驱动能否也运行在用户态?
当然可以,DPDK提供的virtio的用户态驱动virtio-pmd。
6. virtio与vhost如何在非虚拟化场景,没有qemu/kvm介入的情况下运行?
在virtio-pmd的基础上,DPDK提供了virtio-user这个纯用户态的虚拟virtio设备实现。virtio-user可以和vhost-user/vhost-net在非虚拟化环境下交互。在这种模式下,已经不需要qemu/kvm提供virtio-pci设备模拟。virtio-user明确知道自己驱动的是一个纯软件模拟的virtio设备,仍然通过ioctl/unix socket方式将virtqueue配置和内存布局、以及eventfd发送给vhost-net/vhost-user。只是virtio-user现在也直接操作eventfd来实现kick/notify,因为没有了KVM/qemu的模拟实现。
原文链接:https://blog.csdn.net/dillanzhou/article/details/120877753
virtio-pmd
virtio-pmd是DPDK中实现的virtio设备的PMD(poll mode driver)。virtio-pmd通过VFIO接口实现对虚拟/物理virtio网卡的用户态配置和数据处理。与其他网卡设备的PMD相比,virtio-pmd没有什么明显的特别之处。
virtio-user
virtio-user是在virtio-pmd的基础上,完全在用户态实现的virtio虚拟设备。virtio-user与传统的虚拟化技术完全无关,不再需要qemu/kvm等hypervisor介入。virtio-user相当于在用户态进程内同时实现了virtio-pmd和qemu的virtio后端控制面配置能力。
在virtio-user模式下,virtio设备挂载在DPDK内部虚拟的vdev总线上。virtio-user直接与vhost-net/vhost-user交互配置和初始化,通过ioctl/unix socket方式将virtqueue配置和内存布局、以及eventfd发送给vhost-net/vhost-user。之后,virtio-pmd会直接通过操作eventfd的方式来实现和vhost端的事件通知。
原文链接:https://blog.csdn.net/dillanzhou/article/details/120942808
用户态驱动技术有两种:UIO和VFIO。早期版本的DPDK只支持UIO框架,从DPDK1.7开始也支持VFIO。目前VFIO已经是DPDK的主要用户态驱动框架,从DPDK20.02版本开始基于UIO框架的igb_uio模块不再默认编译,文档也不建议再使用UIO。
UIO
UIO是“Userspace I/O”的缩写,是一种相对简单的用户态驱动框架。linux内核中包含了uio.ko内核模块,提供了框架功能。UIO的原理是为每个注册使用UIO的设备生成一个/dev/uioX的字符设备,通过这个字符设备,用户态程序可以实现设备内存空间映射(mmap)、设备中断开关(write)、设备中断获取(read)等操作。
VFIO
VFIO是“Virtual Function I/O”的缩写,但事实上VFIO并不专用于Virtual Function。DPDK的物理网卡pmd也都使用VFIO支持。因此内核VFIO模块的maintainer Alex Williamson建议将其称作“Versatile Framework for userspace I/O”——全能用户态IO框架。从这个解释就能看出,VFIO是对UIO的增强,特别是在前面提到的UIO的几个局限性上,VFIO给出了更完善的解决方案。
原文链接:https://blog.csdn.net/dillanzhou/article/details/120942808















 1033
1033











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









