







这次再尝试解决过拟合,把残差模块的数量减少到2个,自适应参数化ReLU激活函数里面第一个全连接层的权重数量,减少为之前的1/8,批量大小设置为1000(主要是为了省时间)。
自适应参数化ReLU激活函数的基本原理如下:
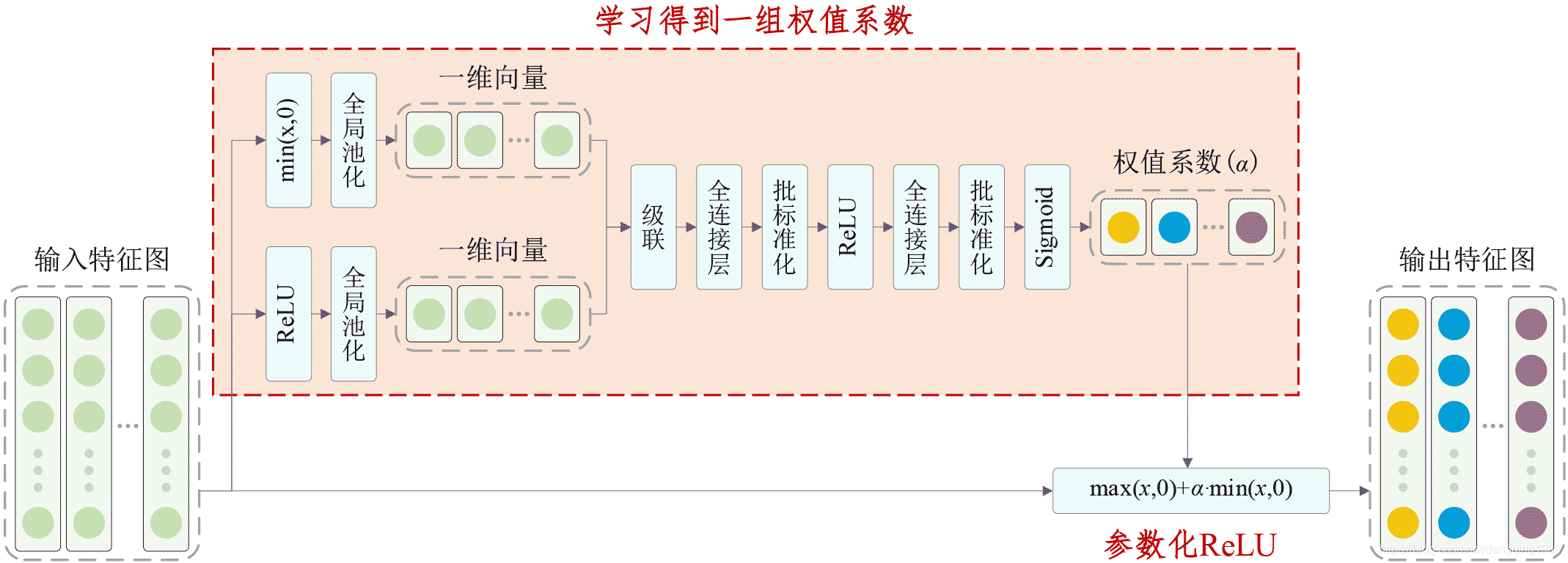
Keras程序如下:
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
"""
Created on Tue Apr 14 04:17:45 2020
Implemented using TensorFlow 1.10.0 and Keras 2.2.1
Minghang Zhao, Shisheng Zhong, Xuyun Fu, Baoping Tang, Shaojiang Dong, Michael Pecht,
Deep Residual Networks with Adaptively Parametric Rectifier Linear Units for Fault Diagnosis,
IEEE Transactions on Industrial Electronics, 2020, DOI: 10.1109/TIE.2020.2972458
@author: Minghang Zhao
"""
from __future__ import print_function
import keras
import numpy as np
from keras.datasets import cifar10
from keras.layers import Dense, Conv2D, BatchNormalization, Activation, Minimum
from keras.layers import AveragePooling2D, Input, GlobalAveragePooling2D, Concatenate, Reshape
from keras.regularizers import l2
from keras import backend as K
from keras.models import Model
from keras import optimizers
from keras.preprocessing.image import ImageDataGenerator
from keras.callbacks import LearningRateScheduler
K.set_learning_phase(1)
# The data, split between train and test sets
(x_train, y_train), (x_test, y_test) = cifar10.load_data()
# Noised data
x_train = x_train.astype('float32') / 255.
x_test = x_test.astype('float32') / 255.
x_test = x_test-np.mean(x_train)
x_train = x_train-np.mean(x_train)
print('x_train shape:', x_train.shape)
print(x_train.shape[0], 'train samples')
print(x_test.shape[0], 'test samples')
# convert class vectors to binary class matrices
y_train = keras.utils.to_categorical(y_train, 10)
y_test = keras.utils.to_categorical(y_test, 10)
# Schedule the learning rate, multiply 0.1 every 1500 epoches
def scheduler(epoch):
if epoch % 1500 == 0 and epoch != 0:
lr = K.get_value(model.optimizer.lr)
K.set_value(model.optimizer.lr, lr * 0.1)
print("lr changed to {}".format(lr * 0.1))
return K.get_value(model.optimizer.lr)
# An adaptively parametric rectifier linear unit (APReLU)
def aprelu(inputs):
# get the number of channels
channels = inputs.get_shape().as_list()[-1]
# get a zero feature map
zeros_input = keras.layers.subtract([inputs, inputs])
# get a feature map with only positive features
pos_input = Activation('relu')(inputs)
# get a feature map with only negative features
neg_input = Minimum()([inputs,zeros_input])
# define a network to obtain the scaling coefficients
scales_p = GlobalAveragePooling2D()(pos_input)
scales_n = GlobalAveragePooling2D()(neg_input)
scales = Concatenate()([scales_n, scales_p])
scales = Dense(channels//8, activation='linear', kernel_initializer='he_normal', kernel_regularizer=l2(1e-4))(scales)
scales = BatchNormalization(momentum=0.9, gamma_regularizer=l2(1e-4))(scales)
scales = Activation('relu')(scales)
scales = Dense(channels, activation='linear', kernel_initializer='he_normal', kernel_regularizer=l2(1e-4))(scales)
scales = BatchNormalization(momentum=0.9, gamma_regularizer=l2(1e-4))(scales)
scales = Activation('sigmoid')(scales)
scales = Reshape((1,1,channels))(scales)
# apply a paramtetric relu
neg_part = keras.layers.multiply([scales, neg_input])
return keras.layers.add([pos_input, neg_part])
# Residual Block
def residual_block(incoming, nb_blocks, out_channels, downsample=False,
downsample_strides=2):
residual = incoming
in_channels = incoming.get_shape().as_list()[-1]
for i in range(nb_blocks):
identity = residual
if not downsample:
downsample_strides = 1
residual = BatchNormalization(momentum=0.9, gamma_regularizer=l2(1e-4))(residual)
residual = aprelu(residual)
residual = Conv2D(out_channels, 3, strides=(downsample_strides, downsample_strides),
padding='same', kernel_initializer='he_normal',
kernel_regularizer=l2(1e-4))(residual)
residual = BatchNormalization(momentum=0.9, gamma_regularizer=l2(1e-4))(residual)
residual = aprelu(residual)
residual = Conv2D(out_channels, 3, padding='same', kernel_initializer='he_normal',
kernel_regularizer=l2(1e-4))(residual)
# Downsampling
if downsample_strides > 1:
identity = AveragePooling2D(pool_size=(1,1), strides=(2,2))(identity)
# Zero_padding to match channels
if in_channels != out_channels:
zeros_identity = keras.layers.subtract([identity, identity])
identity = keras.layers.concatenate([identity, zeros_identity])
in_channels = out_channels
residual = keras.layers.add([residual, identity])
return residual
# define and train a model
inputs = Input(shape=(32, 32, 3))
net = Conv2D(16, 3, padding='same', kernel_initializer='he_normal', kernel_regularizer=l2(1e-4))(inputs)
# net = residual_block(net, 3, 16, downsample=False)
net = residual_block(net, 1, 32, downsample=True)
# net = residual_block(net, 2, 32, downsample=False)
net = residual_block(net, 1, 64, downsample=True)
# net = residual_block(net, 2, 64, downsample=False)
net = BatchNormalization(momentum=0.9, gamma_regularizer=l2(1e-4))(net)
net = Activation('relu')(net)
net = GlobalAveragePooling2D()(net)
outputs = Dense(10, activation='softmax', kernel_initializer='he_normal', kernel_regularizer=l2(1e-4))(net)
model = Model(inputs=inputs, outputs=outputs)
sgd = optimizers.SGD(lr=0.1, decay=0., momentum=0.9, nesterov=True)
model.compile(loss='categorical_crossentropy', optimizer=sgd, metrics=['accuracy'])
# data augmentation
datagen = ImageDataGenerator(
# randomly rotate images in the range (deg 0 to 180)
rotation_range=30,
# Range for random zoom
zoom_range = 0.2,
# shear angle in counter-clockwise direction in degrees
shear_range = 30,
# randomly flip images
horizontal_flip=True,
# randomly shift images horizontally
width_shift_range=0.125,
# randomly shift images vertically
height_shift_range=0.125)
reduce_lr = LearningRateScheduler(scheduler)
# fit the model on the batches generated by datagen.flow().
model.fit_generator(datagen.flow(x_train, y_train, batch_size=1000),
validation_data=(x_test, y_test), epochs=5000,
verbose=1, callbacks=[reduce_lr], workers=4)
# get results
K.set_learning_phase(0)
DRSN_train_score = model.evaluate(x_train, y_train, batch_size=1000, verbose=0)
print('Train loss:', DRSN_train_score[0])
print('Train accuracy:', DRSN_train_score[1])
DRSN_test_score = model.evaluate(x_test, y_test, batch_size=1000, verbose=0)
print('Test loss:', DRSN_test_score[0])
print('Test accuracy:', DRSN_test_score[1])
实验结果如下(为了方便看,删掉了一部分等号):
Epoch 2000/5000
50/50 [=======] - 10s 191ms/step - loss: 0.5083 - acc: 0.8658 - val_loss: 0.5190 - val_acc: 0.8644
Epoch 2001/5000
50/50 [=======] - 10s 194ms/step - loss: 0.5102 - acc: 0.8651 - val_loss: 0.5203 - val_acc: 0.8656
Epoch 2002/5000
50/50 [=======] - 10s 192ms/step - loss: 0.5073 - acc: 0.8659 - val_loss: 0.5245 - val_acc: 0.8612
Epoch 2003/5000
50/50 [=======] - 10s 190ms/step - loss: 0.5105 - acc: 0.8646 - val_loss: 0.5181 - val_acc: 0.8636
Epoch 2004/5000
50/50 [=======] - 9s 186ms/step - loss: 0.5080 - acc: 0.8661 - val_loss: 0.5217 - val_acc: 0.8631
Epoch 2005/5000
50/50 [=======] - 9s 186ms/step - loss: 0.5074 - acc: 0.8641 - val_loss: 0.5237 - val_acc: 0.8614
Epoch 2006/5000
50/50 [=======] - 9s 186ms/step - loss: 0.5060 - acc: 0.8651 - val_loss: 0.5241 - val_acc: 0.8641
Epoch 2007/5000
50/50 [=======] - 10s 190ms/step - loss: 0.5096 - acc: 0.8651 - val_loss: 0.5185 - val_acc: 0.8660
Epoch 2008/5000
50/50 [=======] - 9s 190ms/step - loss: 0.5053 - acc: 0.8686 - val_loss: 0.5186 - val_acc: 0.8624
Epoch 2009/5000
50/50 [=======] - 10s 191ms/step - loss: 0.5057 - acc: 0.8670 - val_loss: 0.5208 - val_acc: 0.8636
Epoch 2010/5000
50/50 [=======] - 10s 190ms/step - loss: 0.5102 - acc: 0.8653 - val_loss: 0.5214 - val_acc: 0.8614
Epoch 2011/5000
50/50 [=======] - 9s 188ms/step - loss: 0.5091 - acc: 0.8651 - val_loss: 0.5211 - val_acc: 0.8629
Epoch 2012/5000
50/50 [=======] - 9s 187ms/step - loss: 0.5069 - acc: 0.8672 - val_loss: 0.5221 - val_acc: 0.8616
Epoch 2013/5000
50/50 [=======] - 9s 184ms/step - loss: 0.5098 - acc: 0.8652 - val_loss: 0.5241 - val_acc: 0.8625
Epoch 2014/5000
50/50 [=======] - 9s 187ms/step - loss: 0.5056 - acc: 0.8666 - val_loss: 0.5188 - val_acc: 0.8623
Epoch 2015/5000
50/50 [=======] - 9s 189ms/step - loss: 0.5050 - acc: 0.8672 - val_loss: 0.5237 - val_acc: 0.8621
Epoch 2016/5000
50/50 [=======] - 10s 193ms/step - loss: 0.5057 - acc: 0.8667 - val_loss: 0.5207 - val_acc: 0.8607
Epoch 2017/5000
50/50 [=======] - 10s 192ms/step - loss: 0.5092 - acc: 0.8642 - val_loss: 0.5172 - val_acc: 0.8637
Epoch 2018/5000
50/50 [=======] - 9s 190ms/step - loss: 0.5062 - acc: 0.8671 - val_loss: 0.5265 - val_acc: 0.8612
Epoch 2019/5000
50/50 [=======] - 9s 188ms/step - loss: 0.5112 - acc: 0.8648 - val_loss: 0.5256 - val_acc: 0.8617
Epoch 2020/5000
50/50 [=======] - 9s 185ms/step - loss: 0.5071 - acc: 0.8663 - val_loss: 0.5241 - val_acc: 0.8622
Epoch 2021/5000
50/50 [=======] - 9s 186ms/step - loss: 0.5079 - acc: 0.8660 - val_loss: 0.5212 - val_acc: 0.8627
Epoch 2022/5000
50/50 [=======] - 9s 185ms/step - loss: 0.5058 - acc: 0.8667 - val_loss: 0.5227 - val_acc: 0.8600
Epoch 2023/5000
50/50 [=======] - 9s 189ms/step - loss: 0.5070 - acc: 0.8661 - val_loss: 0.5259 - val_acc: 0.8608
Epoch 2024/5000
50/50 [=======] - 10s 193ms/step - loss: 0.5053 - acc: 0.8663 - val_loss: 0.5219 - val_acc: 0.8606
Epoch 2025/5000
50/50 [=======] - 10s 191ms/step - loss: 0.5106 - acc: 0.8655 - val_loss: 0.5205 - val_acc: 0.8625
Epoch 2026/5000
50/50 [=======] - 10s 191ms/step - loss: 0.5090 - acc: 0.8649 - val_loss: 0.5221 - val_acc: 0.8610
Epoch 2027/5000
50/50 [=======] - 9s 189ms/step - loss: 0.5103 - acc: 0.8648 - val_loss: 0.5242 - val_acc: 0.8631
Epoch 2028/5000
50/50 [=======] - 9s 189ms/step - loss: 0.5051 - acc: 0.8663 - val_loss: 0.5253 - val_acc: 0.8596
Epoch 2029/5000
50/50 [=======] - 9s 185ms/step - loss: 0.5091 - acc: 0.8654 - val_loss: 0.5237 - val_acc: 0.8612
Epoch 2030/5000
50/50 [=======] - 9s 189ms/step - loss: 0.5076 - acc: 0.8654 - val_loss: 0.5197 - val_acc: 0.8627
Epoch 2031/5000
50/50 [=======] - 9s 189ms/step - loss: 0.5058 - acc: 0.8657 - val_loss: 0.5226 - val_acc: 0.8625
Epoch 2032/5000
50/50 [=======] - 10s 194ms/step - loss: 0.5078 - acc: 0.8669 - val_loss: 0.5225 - val_acc: 0.8639
Epoch 2033/5000
50/50 [=======] - 10s 193ms/step - loss: 0.5101 - acc: 0.8643 - val_loss: 0.5195 - val_acc: 0.8632
Epoch 2034/5000
50/50 [=======] - 10s 191ms/step - loss: 0.5088 - acc: 0.8665 - val_loss: 0.5237 - val_acc: 0.8634
Epoch 2035/5000
50/50 [=======] - 10s 191ms/step - loss: 0.5091 - acc: 0.8644 - val_loss: 0.5182 - val_acc: 0.8652
Epoch 2036/5000
50/50 [=======] - 9s 186ms/step - loss: 0.5090 - acc: 0.8658 - val_loss: 0.5199 - val_acc: 0.8615
Epoch 2037/5000
50/50 [=======] - 9s 187ms/step - loss: 0.5056 - acc: 0.8670 - val_loss: 0.5256 - val_acc: 0.8600
Epoch 2038/5000
50/50 [=======] - 9s 187ms/step - loss: 0.5057 - acc: 0.8665 - val_loss: 0.5261 - val_acc: 0.8600
Epoch 2039/5000
50/50 [=======] - 9s 190ms/step - loss: 0.5088 - acc: 0.8647 - val_loss: 0.5242 - val_acc: 0.8625
Epoch 2040/5000
50/50 [=======] - 10s 192ms/step - loss: 0.5068 - acc: 0.8662 - val_loss: 0.5223 - val_acc: 0.8620
Epoch 2041/5000
50/50 [=======] - 10s 191ms/step - loss: 0.5068 - acc: 0.8655 - val_loss: 0.5189 - val_acc: 0.8594
Epoch 2042/5000
50/50 [=======] - 10s 191ms/step - loss: 0.5070 - acc: 0.8661 - val_loss: 0.5244 - val_acc: 0.8613
Epoch 2043/5000
50/50 [=======] - 9s 187ms/step - loss: 0.5008 - acc: 0.8683 - val_loss: 0.5238 - val_acc: 0.8603
Epoch 2044/5000
50/50 [=======] - 9s 189ms/step - loss: 0.5100 - acc: 0.8652 - val_loss: 0.5233 - val_acc: 0.8609
Epoch 2045/5000
50/50 [=======] - 9s 186ms/step - loss: 0.5007 - acc: 0.8692 - val_loss: 0.5206 - val_acc: 0.8651
Epoch 2046/5000
50/50 [=======] - 9s 188ms/step - loss: 0.5043 - acc: 0.8662 - val_loss: 0.5246 - val_acc: 0.8623
Epoch 2047/5000
50/50 [=======] - 10s 190ms/step - loss: 0.5084 - acc: 0.8644 - val_loss: 0.5211 - val_acc: 0.8620
Epoch 2048/5000
50/50 [=======] - 10s 192ms/step - loss: 0.5068 - acc: 0.8658 - val_loss: 0.5206 - val_acc: 0.8635
Epoch 2049/5000
50/50 [=======] - 10s 194ms/step - loss: 0.5033 - acc: 0.8669 - val_loss: 0.5230 - val_acc: 0.8589
Epoch 2050/5000
50/50 [=======] - 10s 192ms/step - loss: 0.5096 - acc: 0.8653 - val_loss: 0.5217 - val_acc: 0.8610
Epoch 2051/5000
50/50 [=======] - 10s 191ms/step - loss: 0.5081 - acc: 0.8651 - val_loss: 0.5238 - val_acc: 0.8600
Epoch 2052/5000
50/50 [=======] - 9s 186ms/step - loss: 0.5061 - acc: 0.8665 - val_loss: 0.5258 - val_acc: 0.8617
Epoch 2053/5000
50/50 [=======] - 9s 187ms 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 430
430











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









