





一旦启动了游戏原型应用程序,优先级之一就是初始化数据库并管理数据库架构更改。
游戏为我们提供了发展 。 通过利用演化,我们能够创建数据库并管理架构的任何将来更改。
首先,我们需要添加jdbc依赖关系和Evolutions依赖关系。
libraryDependencies += evolutions
libraryDependencies += jdbc 然后,我们将使用保留在磁盘上的简单h2数据库作为播放应用程序的默认数据库。
我们编辑conf / application.conf文件并添加以下行。
db.default.driver=org.h2.Driver
db.default.url="jdbc:h2:/tmp/defaultdatabase"要特别注意,我们的数据库位置在tmp目录中,因此一旦重新启动工作站,所有更改都将被删除。
一旦配置好数据库,就可以创建第一个sql语句了。
我们的脚本应位于conf / evolutions / {您的数据库名称}目录中,因此在我们的情况下
/ conf / evolutions / default。
我们的第一个脚本“ 1.sql”将创建用户表。
# Users schema
# --- !Ups
CREATE TABLE users (
id bigint(20) NOT NULL AUTO_INCREMENT,
email varchar(255) NOT NULL,
first_name varchar(255) NOT NULL,
last_name varchar(255) NOT NULL,
PRIMARY KEY (id),
UNIQUE KEY (email)
);
# --- !Downs
DROP TABLE users; 如我们所见,我们跌宕起伏。 他们代表什么? 正如您已经猜到的,向上描述了转换,而向下描述了如何还原它们。
因此,下一个问题将是如何使用此功能?
假设您有两个开发人员在2.sql上工作。 完成后,他们在本地成功迁移了数据库,但是合并结果与他们在数据库上执行的文件大不相同。 演进所做的是检测文件是否不同,然后通过应用向下版本然后应用最新版本来还原旧版本。
现在我们都准备运行我们的应用程序。
sbt run在localhost:9000导航后,将显示一个屏幕,迫使我们运行检测到的演变。
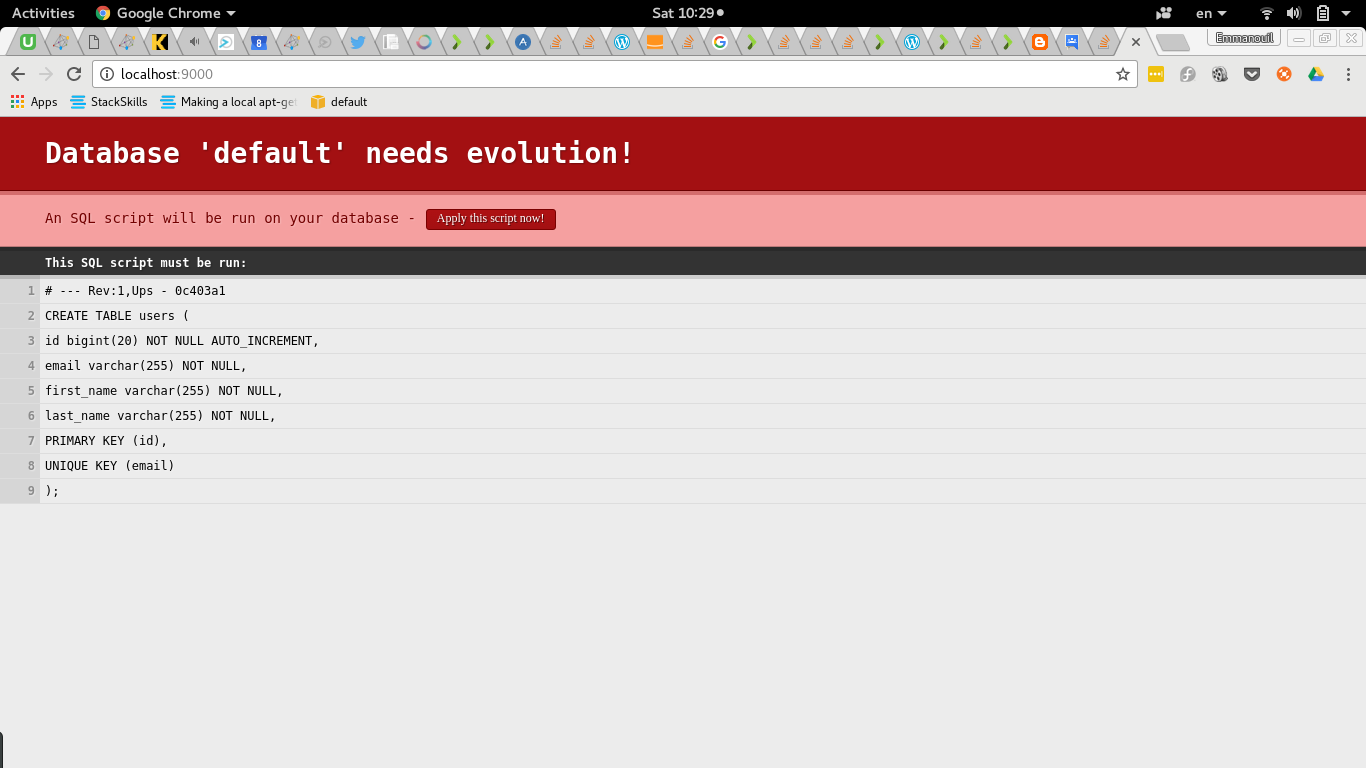
让我们更进一步,看看对我们的数据库模式做了什么。 我们可以使用dbeaver或您的ide轻松浏览h2数据库。
通过发布显示表,结果包含一个额外的表。
>SHOW TABLES;
TABLE_NAME,TABLE_SCHEMA
PLAY_EVOLUTIONS,PUBLIC
USERS,PUBLICPLAY_EVOLUTIONS表跟踪我们的更改
Id是我们创建的演进脚本的编号。 字段apply和restore是我们之前创建的ups和downs sql语句。
字段哈希用于检测我们文件的更改。 如果演化的哈希与所应用的哈希不同,则将还原先前的演化并应用新脚本。
例如,让我们增强之前的脚本并添加一个字段。 字段用户名。
# Users schema
# --- !Ups
CREATE TABLE users (
id bigint(20) NOT NULL AUTO_INCREMENT,
email varchar(255) NOT NULL,
username varchar(255) NOT NULL,
first_name varchar(255) NOT NULL,
last_name varchar(255) NOT NULL,
PRIMARY KEY (id),
UNIQUE KEY (email)
);
# --- !Downs
DROP TABLE users;一旦开始我们的应用程序,我们将看到一个屏幕,该屏幕迫使我们发布不同修订版本的演变。 如果我们点击应用,则用户表应包含用户名字段。
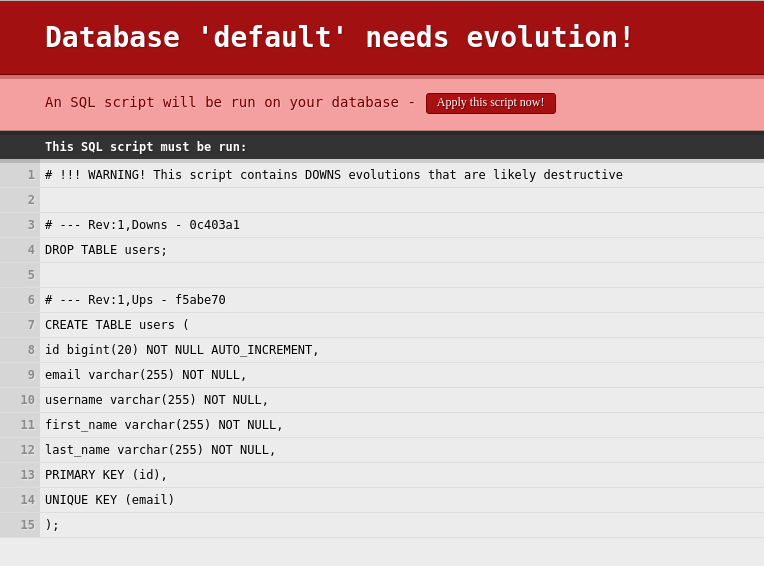
因此,新修订的过程非常简单。
从新的1.sql文件中提取哈希值。 然后查询检查是否已应用1.sql文件。 如果已应用,则检查散列是否相同。 如果不是,则执行当前数据库条目中的downs脚本。 完成后,将应用新脚本。
翻译自: https://www.javacodegeeks.com/2017/04/database-initialization-play-scala.html















 93
93

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









