





 本文提供了一个使用Scala和Spark Streaming从Slack接收实时数据的示例。首先介绍了如何设置开发环境,包括配置Scala和SBT,然后讲解了编写代码、配置Slack API访问权限、启动独立模式的Apache Spark以及运行Spark Streaming应用程序的步骤。文章详细描述了代码实现,包括创建WebSocket连接、解析JSON数据和使用外部库。最后,探讨了Spark Streaming的关键概念,如微批处理和Receiver的实现。
本文提供了一个使用Scala和Spark Streaming从Slack接收实时数据的示例。首先介绍了如何设置开发环境,包括配置Scala和SBT,然后讲解了编写代码、配置Slack API访问权限、启动独立模式的Apache Spark以及运行Spark Streaming应用程序的步骤。文章详细描述了代码实现,包括创建WebSocket连接、解析JSON数据和使用外部库。最后,探讨了Spark Streaming的关键概念,如微批处理和Receiver的实现。
让我们在Scala中编写一个Spark Streaming示例,该示例从Slack流传输。 这篇文章将首先展示如何编写,配置和执行代码。 然后,将详细检查源代码。 如果您没有Slack团队,则可以免费设置一个。 我们也会介绍。
让我们从大体上概述将要采取的步骤。
Spark Streaming示例概述
- 设置Scala和SBT的开发环境
- 写代码
- 配置Slack进行流访问
- 以独立模式启动Apache Spark
- 运行Spark Streaming应用
- 重新访问代码以描述基本概念。
因此,我们的最初目标是运行代码。 然后,我们将详细检查源代码。
1.为Scala和SBT设置Spark流开发环境
让我们遵循SBT目录约定。 创建一个新目录开始。 我将以我的spark-streaming-example为例。 以下是创建目录的命令,但是如果您愿意,也可以使用窗口管理器。 如果这个目录结构对您没有意义,或者您以前没有使用SBT编译Scala代码,那么这篇文章可能不是您的最佳选择。 抱歉,我不得不写那个。 我并不是说这是对您的个人攻击。 我相信你是个很棒而有趣的人。 这篇文章不是很高级,但是我只想对您坦率和诚实。 从长远来看,对我们俩都更好。
无论如何,我们在哪里? 您是Scala-compiling-maestro ...哦,是的,目录结构。
Spark Streaming示例环境设置
mkdir spark-streaming-example
cd spark-streaming-example
mkdir src
mkdir src/main
mkdir src/main/scala
mkdir src/main/scala/com
mkdir src/main/scala/com/supergloo接下来,在dev目录的根目录中创建一个build.sbt文件。 准备惊喜吗? 惊喜! 我的build.sbt将在spark-streaming-example /目录中。
我正在使用的build.sbt是:
Spark Streaming示例build.sbt
name := "spark-streaming-example"
version := "1.0"
scalaVersion := "2.11.8"
resolvers += "jitpack" at "https://jitpack.io"
libraryDependencies ++= Seq("org.apache.spark" % "spark-streaming_2.11" % "1.6.1",
"org.scalaj" %% "scalaj-http" % "2.2.1",
"org.jfarcand" % "wcs" % "1.5")您知道发生了什么,对不对? 我说,对! 希望您不要从那里跳出椅子。 我没有大喊大叫,但只是想确保您仍然与我在一起。
简而言之:我将使用Scala 2.11.8并获取一些依赖项,例如Spark Streaming 2.11,Scalaj-http和WCS。 有链接到这些,这是稍后在帖子中的更多描述。 简而言之,我们需要wcs来建立与松弛的websocket连接,而scalaj-http用于http客户端。 记住,我们的首要目标是工作代码,然后我们将返回更详细的描述。 跟我在一起。
2.编写Scala代码
我称此步骤为“编写Scala代码”,但是我考虑得越多,这并不完全正确。 实际上,我将编写代码,然后您就可以复制粘贴了。 幸运的你。 看看我有多在乎你。
您需要两个文件:
在src / main / scala / com / supergloo目录中,名为SlackReceiver.scala的文件包含以下内容:
Spark Streaming示例Slack接收器
package com.supergloo
import org.apache.spark.Logging
import org.apache.spark.storage.StorageLevel
import org.apache.spark.streaming.receiver.Receiver
import org.jfarcand.wcs.{TextListener, WebSocket}
import scala.util.parsing.json.JSON
import scalaj.http.Http
/**
* Spark Streaming Example Slack Receiver from Slack
*/
class SlackReceiver(token: String) extends Receiver[String](StorageLevel.MEMORY_ONLY) with Runnable with Logging {
private val slackUrl = "https://slack.com/api/rtm.start"
@transient
private var thread: Thread = _
override def onStart(): Unit = {
thread = new Thread(this)
thread.start()
}
override def onStop(): Unit = {
thread.interrupt()
}
override def run(): Unit = {
receive()
}
private def receive(): Unit = {
val webSocket = WebSocket().open(webSocketUrl())
webSocket.listener(new TextListener {
override def onMessage(message: String) {
store(message)
}
})
}
private def webSocketUrl(): String = {
val response = Http(slackUrl).param("token", token).asString.body
JSON.parseFull(response).get.asInstanceOf[Map[String, Any]].get("url").get.toString
}
}并且您将需要在同一目录中的另一个文件SlackReceiver.scala,其内容如下:
Spark Streaming示例应用程序
package com.supergloo
import org.apache.spark.SparkConf
import org.apache.spark.streaming.{Seconds, StreamingContext}
/**
* Spark Streaming Example App
*/
object SlackStreamingApp {
def main(args: Array[String]) {
val conf = new SparkConf().setMaster(args(0)).setAppName("SlackStreaming")
val ssc = new StreamingContext(conf, Seconds(5))
val stream = ssc.receiverStream(new SlackReceiver(args(1)))
stream.print()
if (args.length > 2) {
stream.saveAsTextFiles(args(2))
}
ssc.start()
ssc.awaitTermination()
}
}好的,在这一点上,“我们”已经完成了代码。 “我们”是指您。
我认为确保SBT满意是个好主意。
因此,尝试sbt compile 。 对于我的环境,我将从命令行在spark-streaming-example文件夹中运行此文件。 在这篇文章的参考资料部分中,有一个指向我运行此视频的YouTube屏幕截图的链接。 也许对您也有帮助。 我不知道。 你告诉我。 实际上,不要告诉我它是否有效。 在页面评论中让我知道哪些无效。 它可以在我的机器上工作。 以前听过吗?
3.配置Slack进行API访问
您需要OAuth令牌才能通过API访问Slack并运行此Spark Streaming示例。 对我们来说幸运的是,Slack提供了不需要通过所有OAuth重定向的测试令牌。 该令牌对于此示例将是完美的。
要获得令牌,请访问https://api.slack.com/docs/oauth-test-tokens列出您已加入的Slack团队。 这是我的样子(没有蓝色箭头):
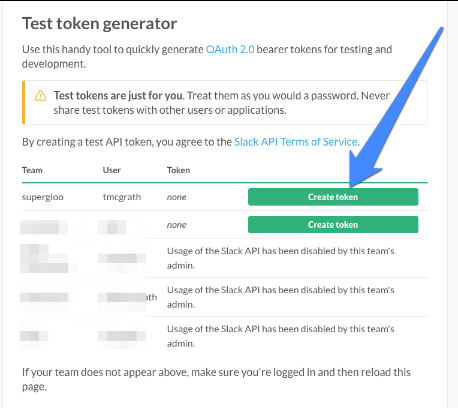
我变灰了一些以保护无辜者。 关键是,您应该看到“创建令牌”的绿色框。 再次查看上方的屏幕截图以及蓝色箭头所指的位置。 您应该有此选项。 如果您不这样做,那么还有另一种选择。
建立您自己的免费Slack团队网站很容易。 并且,当您这样做时,默认情况下,新的团队设置将启用API访问权限。 因此,如果您没有任何现有团队的“创建令牌”按钮,请创建一个新团队。 从这里https://slack.com/create开始。
一旦建立了新团队,或者在前面提到的OAuth测试令牌页面上有可用的“创建令牌”按钮,请单击该按钮以生成令牌。 保留该令牌,因为我们以及“我们”一词意味着您很快将需要它。 但是首先,“我们”需要启动Spark,以便我们可以运行此示例。 我们在一起,您和我。 开始了。
4.以独立模式启动Apache Spark
我假设您有一个Apache Spark环境可以使用。 如果不这样做,那么像这样的Spark Streaming教程可能会有点领先。 如果您超越自己,我会喜欢您的风格。 没有什么比首先跳入深渊。 但是,该池可能是空的,可能会受伤。 我的意思不是从字面上伤害。 比身体更重要。
该站点上有大量资源,可帮助您运行Spark Cluster Standalone进行设置。 正如我所说,您需要。 但是,如果需要,让我们继续。
对于本Spark Streaming教程,我将尽可能采用最简单的Spark设置。 这意味着我们将在独立模式下运行Spark。 您知道,我可以在这里做出决定。 我是博主。 好吧,好吧,我知道,这不是一个大问题。 但是,一个人可以做梦。 而且我实际上并不梦想成为博主。 我梦想带我的孩子们在世界各地的冒险。 我梦想看电影。 有时我梦想着在我的孩子们在世界另一端的某个地方看电影。
无论如何,如果您在运行自己的Spark Cluster方面表现出色,那么也可以在此示例代码上运行。 您的来电。 显然,您是这附近的老板。
好的,老板,从命令行启动Spark Standalone Master:
从命令行启动Spark Master
~/Development/spark-1.5.1-bin-hadoop2.4 $ sbin/start-master.sh您应该从适合您环境的位置调用start-master.sh或Windows等效文件。 对我来说,那是spark-1.5.1-bin-hadoop2.4目录。 通过查看示例,您知道不是吗?
接下来开始工作:
启动Spark Worker
~/Development/spark-1.5.1-bin-hadoop2.4 $ sbin/start-slave.sh spark://todd-mcgraths-macbook-pro.local:7077 启动Spark worker时,您不想添加spark://todd-mcgraths-macbook-pro.local:7077 。 那是我的。 将其保留为空白或将其设置为适合您的计算机的内容。 todd-mcgraths-macbook-pro.local是我的笔记本电脑,而不是您的笔记本电脑。
好的,您应该能够判断Spark启动是否一切正常。 如果没有,您肯定会在本教程中遇到麻烦。 您可能需要在那里快速减速。 但是,你是老板。
您可能需要打开另一个命令窗口才能运行下一步。
5.运行Spark Streaming应用
Scala和Spark风扇,我们开始。 听着,我知道sbt有时可能是熊。 成为simple build tool需要花费一些时间。 但是,我不会在这里进行讨论。 好?
- 在build.sbt所在的目录中启动SBT。
启动SBT以运行Spark Streaming示例~/Development/spark-streaming-example $ sbt - 在您的sbt控制台中:
在SBT中运行Spark Streaming示例run local[5] <your-oauth-token> output
您应该看到的内容:
在SlackStreamingApp启动之后,您将看到从Slack检索到的JSON。 莫莉,让我重复一遍:来自Slack的JSON。 我们做到了! 多拉可能会大喊罗西西莫斯! 在此刻。 也许Boots会这么说。 我记不清了,不在乎。 你也不是。
根据您的日志设置,内容可能会很快在控制台中滚动。
您可以通过从OAuth令牌访问向Slack小组添加消息来进行验证。 您还将流式传输有关Slack事件的消息,例如加入和离开频道,漫游器等。
哇,我们实际上做到了。 你和我,孩子 我一直对你充满信心。 我没有其他人相信你。 好吧,说实话,不是真的。 毕竟这是互联网。 但是,每隔一段时间,我都会感到惊喜。 我仍然认为你很整洁。
6.重温Spark Streaming代码–描述关键概念
好的,让我们重新访问代码,并从外部依赖关系开始。 正如build.sbt部分中简要指出的那样,我们通过WebSocket连接到Slack。 为了建立WebSocket连接并解析传入的JSON数据,我们使用了三件事:外部WebSocket Scala库(wcs),外部HttpClient库(scalaj-http)和Scala中的本机JSON解析器。 同样,指向正在使用的外部库的链接位于下面的参考资料部分。 我们在两个SlackReceiver函数中看到了所有这三个函数。
Spark Streaming Receiver示例WebSocket,HttpClient,JSON
private def receive(): Unit = {
val webSocket = WebSocket().open(webSocketUrl())
webSocket.listener(new TextListener {
override def onMessage(message: String) {
store(message)
}
})
}
private def webSocketUrl(): String = {
val response = Http(slackUrl).param("token", token).asString.body
JSON.parseFull(response).get.asInstanceOf[Map[String, Any]]
.get("url").get.toString
} webSocketUrl函数使用我们在第一个参数中发送的OAuth令牌run 。 很快会有更多。 请注意,在JSON.parseFull中将传入的响应数据解析为JSON。 初始化SlackReceiver时,我们从SlackStreamingApp发送了OAuth令牌:
将OAuth令牌发送到我们的Spark Streaming Receiver
val stream = ssc.receiverStream(new SlackReceiver(args(1))) 另外,我们在webSocketUrl函数中看到期望JSON和Map [String,Any]的架构键/值对。
好的,这涵盖了正在使用的外部库。 我们继续吧。
回想一下该站点上先前的Spark Streaming教程(下面的参考资料中的链接),可以将Spark Streaming视为一个微批处理系统。 Spark Streaming无需一次等待和处理一个记录的流数据,而是将流数据离散化为微批。 换句话说,Spark Streaming的接收器并行接收数据并将其缓冲在Spark的worker节点的内存中。
微批在指定时间范围内轮询流源。 此示例应用程序的轮询频率是多少? 这是SlackStreaming应用代码中声明的每5秒:
Spark Streaming Context设置为每5秒轮询一次
val ssc = new StreamingContext(conf, Seconds(5))那StreamingContext呢? StreamingContext是特定于Spark Streaming的上下文类型。 惊讶吗 当然不是。 您可以用名字StreamingContext来分辨,对吗? 我说的对!! 那个时候你跳出椅子了吗? 希望如此。 在构建流应用程序时,需要一个StreamingContext。
现在回到SlackReceiver类。 扩展Receiver是我们为Spark Streaming构建自定义接收器时所要做的。 如果您现在还没有猜到,让我告诉您,我们为Slack构建了一个自定义接收器。 好吧,你能看看我们吗? 我们构建了一个自定义接收器。 有人给我们奖杯。 或丝带。 或丝带奖杯。
类声明:
火花流接收器
class SlackReceiver(token: String) extends Receiver[String](StorageLevel.MEMORY_ONLY) with Runnable { 关于此声明,没有什么要注意的事情。 首先,使用Runnable特性是为了方便运行此示例。 我认为从SBT运行此程序将使事情变得更容易。
我们将StorageLevel设置为仅内存
火花流接收器
StorageLevel.MEMORY_ONLY这是默认值。 这里没什么好看的。 这会将RDD存储为JVM中的反序列化对象。 如果存储需求超出可用容量,它将不会溢出到磁盘上,并且每次需要且不在内存中时都需要重新计算。 同样,在此示例中,我们不需要任何其他信息。 如果需要有关存储级别的更多信息,请检查其他示例,例如MEMORY_AND_DISK,MEMORY_ONLY_SER,DISK_ONLY和其他示例。 这是一个Spark Streaming帖子,ang。
最后,在扩展Receiver时,我们将覆盖三个功能。 (或者,您可能会在onStart内调用run一些示例,但是我们在这里不打算这样做。为什么?因为我是个大人物,而且是一个“远见者”。再三考虑,我是个大人物。像他们在biznas中所说的那样,射击有远见的人或BSV。<–那是我的国际偷窥不正当的事。<-那是我的非s语听众却被错了的人…。当它,现在我被跟踪了。)
我们刚刚说到哪了?! 伙伴,别让我迷路。 我们需要重写两个函数,因为Receiver是一个抽象类:
Spark Streaming Receiver的特定功能
...
override def onStart(): Unit = {
thread = new Thread(this)
thread.start()
}
override def onStop(): Unit = {
thread.interrupt()
}
... onStart正在生成并启动一个新线程来接收流源。 这触发了对我们覆盖的Thread run函数的调用,该函数调用了先前描述的receive函数。
onStop可以确保在接收器停止时停止任何生成的线程。
(未显示,但是接收时的异常可以通过使用restart重新启动接收器或通过stop完全stop来处理。有关更多信息,请参见Receiver文档。)
所以,这就是代码。 但是,我们还要考虑如何调用此示例。 一个重要的细节是使用“ 5”:
调用Spark Streaming示例
run local[5] <your-oauth-token> output为什么是5? 如果我们使用“ local”或“ local [1]”作为主URL,则仅一个线程将用于运行任务。 当使用基于流接收器的输入DStream时,将使用单个线程来运行接收器,而不会留下任何线程来处理接收到的数据。 因此,始终使用“ local [ n ]”作为主URL,其中n >要运行的接收者数。
在独立模式之外的Spark集群上运行时,分配给Spark Streaming应用程序的核心数必须大于接收器数。
最后,我们将以一个无关紧要的细节结束。 最后一个参数是“输出”,您可以在此处使用SlackStreamingApp看到的:
可选:将Spark Stream文件保存为文本
if (args.length > 2) {
stream.saveAsTextFiles(args(2))
}第二个参数是可选的,它指定是否将流数据保存到磁盘以及保存到哪个目录。
结论
因此,除了开玩笑之外,我希望这个Spark Streaming示例可以为您提供帮助。 我喜欢帮助尝试的好人。 我希望你是那种人之一。
在Twitter和YouTube上订阅之后,您可能会喜欢注册邮件列表。 您有选择。 我认为这些网站的链接都在每个页面的底部。 老实说,我不能完全确定我是否希望您关注或订阅,但是我认为我实际上不能阻止您这样做。 所以,你是老板。 看到? 我再次做到了。 只是很开心。
请注意,如果在下面的评论中对此帖子有任何疑问或建议,请告诉我。
这是我执行上述大多数步骤的屏幕截图。
妈,我在YouTube上! 您可以根据需要订阅supergloo YouTube频道。 我妈做过 我认为。 至少,她告诉我她做到了。 (我叫她妈妈,而不是妈妈,过来。我来自明尼苏达州。)
此Spark Streaming示例教程的资源
- WSC –异步WebSocket连接器– https://github.com/jfarcand/WCS
- HttpClient – https://github.com/scalaj/scalaj-http
- 在此站点上查看“ Spark Streaming Example Part 1”。 该帖子是第2部分的松散耦合。
翻译自: https://www.javacodegeeks.com/2016/03/spark-streaming-example-stream-slack.html















 743
743

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









