





想象一个简单的Akka actor系统,该系统由两方组成: MonitoringActor和NetworkActor 。 每当有人( 客户 )将CheckHealth发送给前者时,它都会通过发送Ping来询问后者。 NetworkActor有义务尽快与Pong进行答复(方案[A])。 MonitoringActor收到此类答复后,将立即以“ Up状态消息答复客户机。 但是,如果NetworkActor无法在一秒钟内用Pong响应(场景[B]), MonitoringActor有义务发送Down回复。 这两个工作流程如下所示:
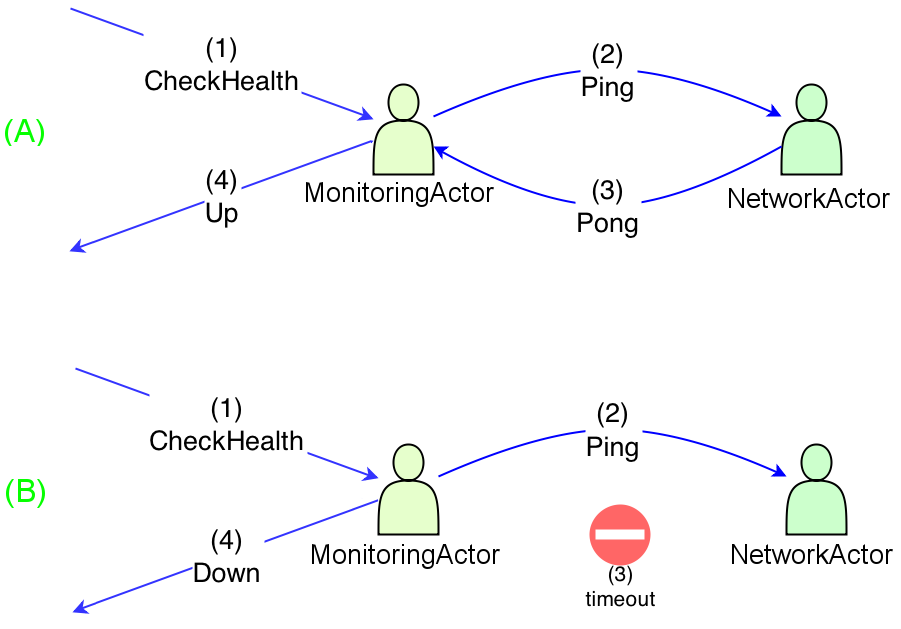
显然,至少有三种方法可以在Akka中实现此简单任务,我们将研究它们的优缺点。
普通演员
在这种情况下, MonitoringActor无需任何中介即可直接侦听Pong :
class MonitoringActor extends Actor with ActorLogging {
private val networkActor = context.actorOf(Props[NetworkActor], "network")
private var origin: Option[ActorRef] = None
def receive = {
case CheckHealth =>
networkActor ! Ping
origin = Some(sender)
case Pong =>
origin.foreach(_ ! Up)
origin = None
}
} NetworkActor的实现是无关紧要的,只要假设它对每个Ping以Pong进行响应即可。 如您所见, MonitoringActor处理两条消息:客户端发送的CheckHealth和大概由NetworkActor发送的Pong 。 遗憾的是,我们不得不将客户引用存储在origin字段下,因为一旦处理CheckHealth ,否则它会丢失。 因此,我们增加了一些状态。 该实现非常简单,但是存在很多问题:
- 随后的
CheckHealth将覆盖以前的origin - 等待
Pong时不应真正允许CheckHealth - 如果
Pong来,我们将处于不一致的状态 - …因为我们还没有1秒的超时条件
但是在实现超时条件之前,让我们重构一下代码以使状态更显式和类型安全:
class MonitoringActor extends Actor with ActorLogging {
private val networkActor = context.actorOf(Props[NetworkActor], "network")
def receive = waitingForCheckHealth
private def waitingForCheckHealth: Receive = {
case CheckHealth =>
networkActor ! Ping
context become waitingForPong(sender)
}
private def waitingForPong(origin: ActorRef): Receive = {
case Pong =>
origin ! Up
context become waitingForCheckHealth
}
} context.become()允许动态更改actor的行为 。 在我们的情况下,我们要么等待CheckHealth要么等待Pong –但绝不会两者都等待。 但是状态( origin参考)去了哪里? 好吧,它被巧妙地隐藏了。 waitingForPong()方法将origin作为参数,并返回PartialFunction 。 此函数关闭该参数,因此不再需要actor全局变量。 好的,现在我们准备在等待Pong时实现1秒超时:
def receive = waitingForCheckHealth
private def waitingForCheckHealth: Receive = {
case CheckHealth =>
networkActor ! Ping
implicit val ec = context.dispatcher
val timeout = context.system.scheduler.
scheduleOnce(1.second, self, Down)
context become waitingForPong(sender, timeout)
}
private def waitingForPong(origin: ActorRef, timeout: Cancellable): Receive = LoggingReceive {
case Pong =>
timeout.cancel()
origin ! Up
context become receive
case Down =>
origin ! Down
context become receive
} 发送Ping我们立即计划在恰好一秒钟后向自己发送Down消息。 然后我们进入waitingForPong 。 如果Pong到达,我们将取消预定的Down并发送Up 。 但是,如果我们第一次收到Down则意味着已经过去了一秒钟。 因此,我们将Down转发给客户。 仅仅是我还是一个如此简单的任务不需要那么多的代码?
此外,请注意,我们的MonitoringActor不能处理多个客户端。 收到CheckHealth ,将不再允许其他客户端,直到将Up或Down发回。 似乎很有局限性。
组成期货
解决同一问题的另一种方法是采用ask模式和期货。 突然,代码变得更短,更易于阅读:
def receive = {
case CheckHealth =>
implicit val timeout: Timeout = 1.second
implicit val ec = context.dispatcher
val origin = sender
networkActor ? Ping andThen {
case Success(_) => origin ! Up
case Failure(_) => origin ! Down
}
} 而已! 我们通过发送Ping 询问 networkActor ,然后当响应到达时我们回复客户端。 如果它是Success(_) ( _占位符代表Pong但我们不在乎),我们发送Up 。 如果是Failure(_) (其中_最有可能在一秒钟后抛出AskTimeout没有回复),我们将Down转发。 这段代码有一个巨大的陷阱。 在成功和失败回调中,我们不能直接使用sender ,因为这些代码段可以在以后由另一个线程执行。 sender的价值是短暂的,当Pong到达时,它可能指向碰巧向我们发送东西的任何其他演员。 因此,我们必须将原始sender保留在origin局部变量中,并捕获该sender 。
如果您觉得这很烦,则可以使用pipeTo模式:
def receive = LoggingReceive {
case CheckHealth =>
implicit val ec = context.dispatcher
networkActor.ask(Ping)(1.second).
map{_ => Up}.
recover{case _ => Down}.
pipeTo(sender)
} 和以前一样,我们ask (同义词?法) networkActor与超时。 如果收到正确答复,我们会将其映射到Up 。 相反,如果将来以异常结束,我们可以通过将其映射到Down消息从中恢复。 无论执行哪个“分支”,结果都将通过管道传递给sender 。
您应该问自己一个问题:为什么尽管使用了sender ,但上面的代码却被破坏了,所以上面的代码还是可以的? 如果仔细查看声明,您会发现pipeTo()按值而不是按名称接受ActorRef 。 这意味着在执行表达式时将立即对sender进行评估,而不是在回复返回时才进行评估。 我们在这里如履薄冰,因此在进行此类假设时请小心。
专门演员
演员是轻量级的,为什么不仅仅为了一次健康检查就创建演员呢? 这个扔掉的参与者将负责与NetworkActor进行通信并将回复推回给客户端。 MonitoringActor的唯一职责是创建该一次性Actor的实例:
class MonitoringActor extends Actor with ActorLogging {
def receive = {
case CheckHealth =>
context.actorOf(Props(classOf[PingActor], networkActor, sender))
}
} PingActor非常简单,类似于第一个解决方案:
class PingActor(networkActor: ActorRef, origin: ActorRef) extends Actor with ActorLogging {
networkActor ! Ping
context.setReceiveTimeout(1.second)
def receive = {
case Pong =>
origin ! Up
self ! PoisonPill
case ReceiveTimeout =>
origin ! Down
self ! PoisonPill
}
} 创建actor时,我们将Ping发送给NetworkActor ,还计划超时消息。 现在我们等待Pong或超时Down 。 在这两种情况下,由于不再需要PingActor我们最终都无法PingActor 。 当然, MonitoringActor可以同时创建多个独立的NetworkActor 。
该解决方案结合了第一个解决方案的简单性和纯度,但与第二个解决方案一样强大。 当然,它也需要大多数代码。 由您决定在实际用例中采用哪种技术。 顺便说一句,写完本文后,我遇到了Ask,Tell和Per-request Actors ,它们涉及到相同的问题并介绍了类似的方法。 绝对也要看!
翻译自: https://www.javacodegeeks.com/2014/01/three-flavours-of-request-response-pattern-in-akka.html















 191
191

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









