





scala java 性能
元组是编程语言中非常强大的构造,它允许创建有限元序列。 元组中的元素可以是不同类型,并且很容易声明,例如(“ something”,1,new Date())
关于元组的好处是您只需要决定元素的数据类型而不是名称。
计算机科学有两个难题:缓存失效和命名。
元组有助于解决命名问题。
没有什么是免费的,每件事都有一定的权衡。 在这个博客中,我将分享元组的阴暗面。 我将以Scala元组为例。
有哪些不同的方法来实现元组?
带对象数组的类
这是我想到的第一个选择,它对灵活性有好处,但对诸如
- 类型检查很昂贵
- 并且具有数组索引检查的开销。
- 参数是对象类型,因此对读取和写入都造成内存压力。
- 使变得一成不变的代价很高。 稍后我们将讨论不可变。
- 没有类型,因此序列化将是巨大的开销
具有固定数量的参数的类。
这比第一个要好,但是它也没有什么问题
- 参数是对象类型,因此会增加内存压力
- 除非框架或库生成代码或维护固定的布局对象(例如,Tuple,Tuple2,Tuple3…),否则该变量是可变的
- 由于对象类型而导致的序列化开销。
Scala使用固定数量的参数方法。
在没有Tuple的情况下,穷人的选择是创建具有N个实例变量的类并为其指定适当的类型,scala拥有基于旧派思想的Case类。
让我们比较元组与案例类。 我将使用具有4个参数的元组,其中2个是原始类型(Int和Double)。
元组: (String,String,Int,Double)
案例类别: 案例类别交易(符号:字符串,交换:字符串,数量:整数,价格:双倍)
明智的结构都相同,并且可以相互替换。
记忆测试
基准创建N个元组/案例类实例,并将其放入集合中并测量内存分配。
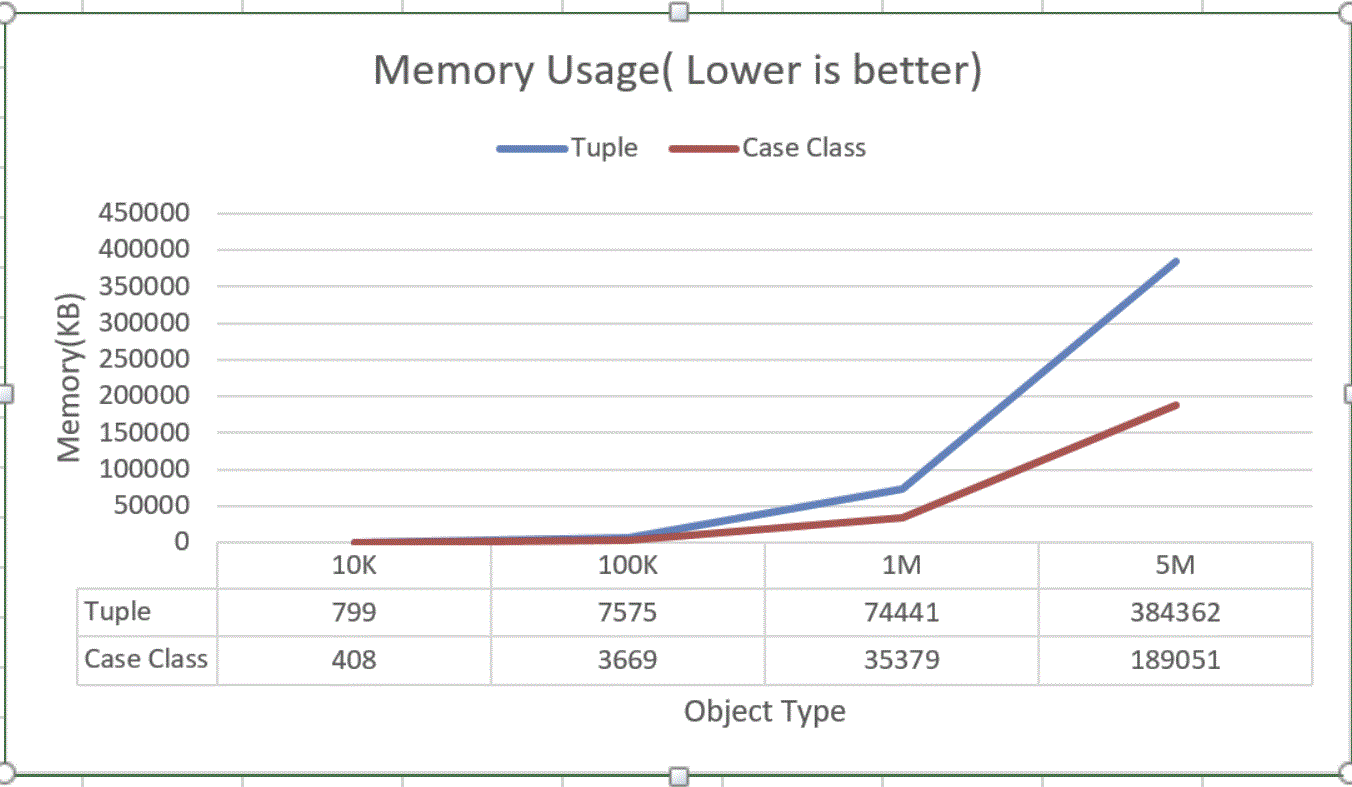
Tuple的内存使用量是原来的两倍,500万个对象的tuple占用384 MB,而case类仅占用189 MB。
读取性能测试
在此测试中,对象被分配一次,并且可以对其进行访问以进行基本聚合。
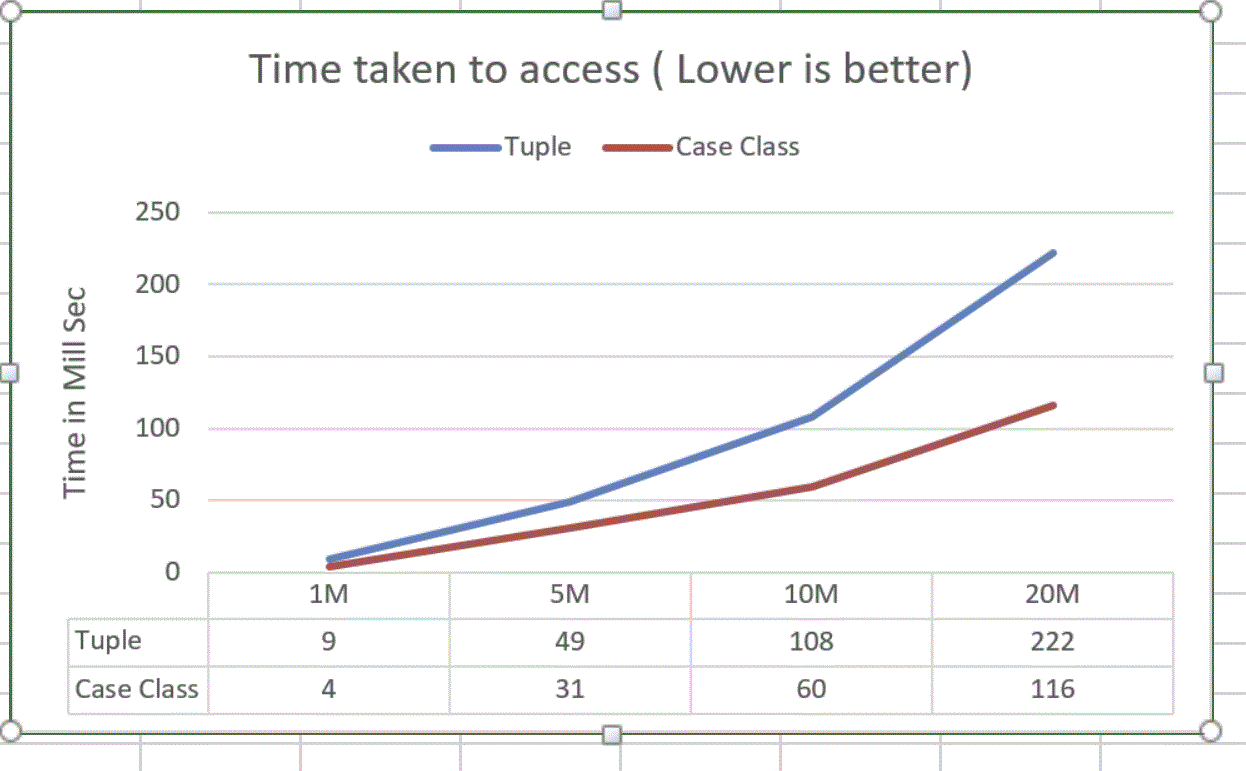
该图表显示了对100万个,500万个等对象的Double值求和所需的时间。
从元组读取很慢,需要花费两倍的时间。
该图表中未显示的一件事是读取期间产生的内存压力。 元组在读取过程中增加了内存压力。
这些数字表明,从内存和CPU使用率来看,Tuple都不是很好。
让我们深入研究为元组和案例类生成的代码,以了解为什么看到这些数字。
我将放置Scala编译器生成的Java代码。
/*
Code for (String,String,Int,Double)
*/
public class Tuple4<T1, T2, T3, T4> implements Product4<T1, T2, T3, T4>, Serializable
{
private final T1 _1;
public T1 _1(){return (T1)this._1;}
public T2 _2(){
return (T2)this._2;
}
public T3 _3(){
return (T3)this._3;
}
public T4 _4(){
return (T4)this._4;
}
}Scala很好地将值标记为最终值,因此它可以从中获得一定的读取效率,但是通过创建对象类型并在每次请求值时进行运行时类型转换都将其全部丢弃。
案例类代码
/*
Code for
case class Trade(symbol: String, exchange: String, qty: Int, price: Double)
*/
public class Trade implements Product, Serializable
{
private final String symbol;
public double price(){
return this.price;
}
public int qty(){
return this.qty;
}
public String exchange(){
return this.exchange;
}
public String symbol(){
return this.symbol;
}
}对于caseclass代码,scala仍在使用原始类型,并且可以提供所有内存和cpu效率。
Spark是非常流行的大规模数据处理框架,许多生产代码是使用Tuple编写的。
基于元组的转换给GC带来了很多负担,并影响了CPU利用率。
由于元组全部基于对象类型,因此它对网络传输也有影响。
类型信息对于优化非常重要,这就是Spark 2基于具有紧凑表示形式的数据集的原因。
因此,下次寻求快速改进时,将Tuple更改为案例类。
用于基准测试的代码@ githib
翻译自: https://www.javacodegeeks.com/2018/07/scala-tuple-performance.html
scala java 性能















 433
433











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









