





这篇文章的目的是展示与标准UNIX工具结合使用以分布式方式分析数据时Docker Swarm的功能强大和灵活。 为此,让我们在bash/sh中编写一个简单的MapReduce实现,该实现使用Docker Swarm在整个集群的节点上调度Map作业。
通常在有大量数据集要处理时实施MapReduce。 为了简单起见,并为了使读者可重复,我们使用了一个非常小的数据集,由几兆字节的文本文件组成。
这篇文章不是要向您展示如何编写MapReduce程序。 这也不是在暗示最好以这种方式完成MapReduce。 而是要让您知道,旧的UNIX工具(例如sort , awk , netcat , pv , uniq , xargs , pipe , join , time和cat在基于a的顶部运行时可能对分布式数据处理很有用。 Docker Swarm集群。
因为这只是一个例子,所以要获得容错弹性和冗余还有很多工作要做。 如果您碰巧有一个一次性用例,并且不想在Hadoop等更复杂的项目上花费时间,那么类似此处提出的解决方案可能会很有用。 如果您有一个经常使用的案例,建议您改用Hadoop。
使用Docker Swarm实现MapReduce的要求
要重现本文中的示例,您将需要做一些事情:
- 在本地计算机上安装Docker
- 正在运行的Swarm集群 (如果您没有集群 ,请不要担心。我将解释如何以快速简便的方式为此目的获取集群 )
- 在本地计算机上安装的Docker Machine (如果尚未安装Swarm集群,则设置该集群)
MapReduce是一种编程范例,旨在以分布式方式在集群(在我们的示例中为Swarm集群)上处理大型数据集。 顾名思义,MapReduce由两个基本步骤组成:
- 映射:主节点获取一个大型数据集,并将其分发到计算节点以对其进行分析。 每个节点都返回一个结果。
- 减少:收集每个Map的结果并将其汇总以得出最终答案。
设置Swarm集群
如果您已经拥有Swarm集群,则可以跳过此部分。 只需确保在使用Docker客户端时连接到Swarm集群即可。 为此,您可以检查
DOCKER_HOST环境变量。
我写了一个设置脚本,以便我们可以轻松地在DigitalOcean上创建Swarm集群。 为了使用它,您需要一个DigitalOcean帐户和一个API密钥,以允许Docker Machine为您管理实例。 您可以在此处获取API密钥。
完成API密钥后,将其导出,以便可以在设置脚本中使用它:
export DO_ACCESS_TOKEN=aa9399a2175a93b17b1c86c807e08d3fc4b79876545432a629602f61cf6ccd6b 现在我们准备编写create-cluster.sh脚本:
#!/bin/bash
# configuration
agents="agent1 agent2"
token=$(docker run --rm swarm create)
# Swarm manager machine
echo "Create swarm manager"
docker-machine create \
-d digitalocean \
--digitalocean-access-token=$DO_ACCESS_TOKEN \
--swarm --swarm-master \
--swarm-discovery token://$token \
manager
# Swarm agents
for agent in $agents; do
(
echo "Creating ${agent}"
docker-machine create \
-d digitalocean \
--digitalocean-access-token=$DO_ACCESS_TOKEN \
--swarm \
--swarm-discovery token://$token \
$agent
) &
done
wait
# Information
echo ""
echo "CLUSTER INFORMATION"
echo "discovery token: ${token}"
echo "Environment variables to connect trough docker cli"
docker-machine env --swarm manager您可以注意到,该脚本由三部分组成:
- 配置:这里有两个用于配置整个集群的变量。
agents变量定义在使用swarm create命令填充token变量的同时,将多少个Swarm代理放入群集中,该命令生成由群集用于服务发现的Docker Hub令牌。 如果您不喜欢令牌方法,则可以使用自己的发现服务, 例如Consul,ZooKeeper或Etcd 。 - 创建Swarm主计算机:这是将通过tcp公开Docker远程API的计算机。
- Swarm代理计算机的创建:根据配置,将在DigitalOcean上为每个指定的名称
agent1 agent2创建一台计算机,并将其配置为加入先前创建的Swarm管理器的集群。 - 打印有关生成的集群的信息:当机器运行时,脚本仅打印有关生成的集群以及如何通过Docker客户端连接到集群的信息。
现在,我们终于可以执行create-cluster.sh脚本:
chmod +x create_cluster.sh
./create_cluster.sh几分钟和几行输出后,如果没有任何问题,我们应该看到类似以下内容:
CLUSTER INFORMATION
discovery token: 9effe6d53fdec36e6237459313bf2eaa
Environment variables to connect trough docker cli
export DOCKER_TLS_VERIFY="1"
export DOCKER_HOST="tcp://104.236.46.188:3376"
export DOCKER_CERT_PATH="/home/fntlnz/.docker/machine/machines/manager"
export DOCKER_MACHINE_NAME="manager"
# Run this command to configure your shell:
# eval $(docker-machine env --swarm manager)如建议的那样,您必须运行命令来配置您的shell才能连接到Swarm集群Docker守护程序。
eval $(docker-machine env --swarm manager)要验证集群是否已启动并正在运行,可以使用:
docker-machine ls应该打印:
NAME ACTIVE DRIVER STATE URL SWARM DOCKER ERRORS
agent1 - digitalocean Running tcp://104.236.26.148:2376 manager v1.10.3
agent2 - digitalocean Running tcp://104.236.21.118:2376 manager v1.10.3
manager * (swarm) digitalocean Running tcp://104.236.46.188:2376 manager (master) v1.10.3 请注意,只有一个具有某物体的下面ACTIVE列是主。 这是因为您运行了该eval命令以先前配置您的Shell。
收集数据进行分析
没有要分析的数据,数据分析将一事无成。 我们将使用流行的英国科幻系列片Doctor Who的最新季节的一些笔录。 为此,我创建了一个Gist,其中一些摘录自The Doctor Who Transcripts 。
实际上,我仅将第九医生的最新剧集(始于2005年)添加到Gist中。 您可以通过克隆我的Gist来获得成绩单:
git clone https://gist.github.com/fa9ed1ad11ba09bd87b2d25a14f65636.git who-transcripts 克隆要点后,您应该以一个包含130个笔录的who-transcripts文件夹结束。
由于对本文的要求之一是必须使用UNIX工具进行数据分析,因此我们可以将AWK用于地图程序。
为了对减少步骤有用,我们的地图程序应能够像这样转换记录:
[Albion hospital]
(The patients are almost within touching distance.)
DOCTOR: Go to your room.
(The patients in the ward and the child in the house stand still.)
DOCTOR: Go to your room. I mean it. I'm very, very angry with you. I am very, very cross. Go to your room!
(The child and the patients hang their heads in shame and shuffle away. The child leaves the Lloyd's house and the patients get back into bed.)
DOCTOR: I'm really glad that worked. Those would have been terrible last words.
[The Lloyd's dining room]在键中,像这样的值对:
DOCTOR go
DOCTOR to
DOCTOR your
DOCTOR room
DOCTOR Im
DOCTOR really
DOCTOR glad
... 为此,Map必须跳过不是<speaker>: <phrase>格式的行,然后对于每个单词,它必须打印演讲者姓名和单词本身。
为此,我们可以编写一个简单的AWK程序,例如map.awk :
#!/usr/bin/awk -f
{
if ($0 ~ /^(\w+)(.\[\w+\])?:/) {
split ($0, line, ":");
character=line[1];
phrase=tolower(gensub(/[^a-zA-Z0-9 ]/, "", "g", line[2]));
count=split(phrase, words, " ");
for (i = 0; ++i <= count;) {
print character " " words[i]
}
}
}在您的本地计算机上,您可以轻松地尝试使用以下地图程序:
cat who-transcripts/27-1.txt | ./map.awk计划地图作业
现在我们有了Map程序,我们可以考虑如何开始在集群上调度地图作业了。 我们的调度程序将负责:
- 管理可以同时完成的工作数量
- 将地图程序复制到执行程序中
- 告诉执行者运行地图程序
- 将数据复制到执行者
- 运行地图程序并将每个执行者的结果与其他执行者结合在一起
- 不再需要垃圾收集容器
为此,我们可以编写一个bash脚本,该脚本从who-transcripts文件夹中读取所有脚本。 它还将使用Docker客户端连接到Swarm集群并进行所有操作!
类似于以下脚本的脚本可以完成此重要任务:
#!/bin/bash
function usage {
echo "USAGE: "
echo " ./scheduler.sh <transcripts folder> <max concurrent jobs>"
}
# Argument checking
transcripts_folder=$1
if [ -z "$1" ]; then
echo "Please provide a folder from which take transcripts"
echo ""
usage
exit 1
fi
if [ ! -d "$transcripts_folder" ]; then
echo "Please provide a valid folder from which take transcripts"
echo ""
usage
exit 1
fi
maxprocs=$2
if [ -z "$2" ]; then
maxprocs=5
fi
# Scheduling
proc=0
seed=`uuidgen`
# Cycle trough transcripts and start jobs
for transcript in $transcripts_folder/*; do
(container=`docker run --name "${seed}.$proc" -d alpine sh -c "while true; do sleep 5; done"` > /dev/null
echo "[MAP] transcript: ${transcript} => container: ${container}"
docker cp map.awk $container:/map
cat $transcript | docker exec -i $container ./map >> result.txt
docker rm -f $container > /dev/null) &
(( proc++%maxprocs==0 )) && wait;
done
# Remove containers
docker ps -aq --filter "name=$1" | xargs docker rm -f该脚本由三个重要部分组成:
- 参数检查 :这部分的唯一目的是检索并检查作业执行所需的参数。
- Jobs Execution :这部分由一个
for循环组成,该循环迭代所提供文件夹中的低谷记录文件。 在每次迭代中,都会启动一个容器,并且在执行之前将map.awk脚本复制到其中。 映射的输出重定向到result.txt文件,该文件收集所有映射输出。for循环由maxprocs变量控制,该变量确定并发作业的最大数量。 - 容器的拆除 :在
for循环期间应拆除用过的容器; 如果没有发生,则在循环结束后将其删除。
可以通过使用-rm选项运行容器来简化调度程序脚本,但是这要求map.awk脚本在运行之前已经在映像中。
由于调度程序能够将所需的数据传输给执行者,因此我们不需要任何其他内容,因此可以运行调度程序。 但是在运行调度程序之前,我们必须告诉Docker客户端连接到Swarm集群而不是本地引擎。
eval $(docker-machine env --swarm manager) 这将使用who-transcripts文件夹(最大并行作业数为40)来启动调度程序。
./scheduler.sh who-transcripts 40在执行时,调度程序应输出类似的内容:
[MAP] transcript: who-transcripts/27-10.txt => container: f1b4bdf37b327d6d3c288cc1e6ce1b7f274b3712bc54e4315d24a9524801b230
[MAP] transcript: who-transcripts/27-12.txt => container: 03e18bf08f923c0b52121a61f1871761bf516fe5bc53140da7fa08a9bcb9294c
[MAP] transcript: who-transcripts/27-11.txt => container: dadfb0e2cccf737198e354d2468bdf3eb8419ec131ed8a3852eca53f1e57314b
[MAP] transcript: who-transcripts/27-2.txt => container: 69bb0eb07df7a356d10add9d466f7d6e2c8b7ed246ed9922dc938c0f7b4ee238
[MAP] transcript: who-transcripts/28-1.txt => container: 3f56522aac45fd76f88a190611fb6e3f96f4a65e79e8862f7817be104f648737
[MAP] transcript: who-transcripts/28-6.txt => container: 05048e807996b63231c59942a23f8504eab39ece32e616644ccef2de7cb01d5c
[MAP] transcript: who-transcripts/28-0.txt => container: a0199b5d64ca012e411da09d85081a604f87500f01e193395828e7911f045075 调度程序完成后,我们可以检查result.txt文件。 这是前20行:
DOCTOR go
DOCTOR to
DOCTOR your
DOCTOR room
DOCTOR go
DOCTOR to
DOCTOR your
DOCTOR room
DOCTOR i
DOCTOR mean
MICKEY it
ROSE im
DOCTOR very
DOCTOR very
DOCTOR angry
DOCTOR with
MICKEY you
DOCTOR i
DOCTOR am
ROSE very 大! 这是一个键,值<name> <sentence> 。 因此,让我们看看是否可以使用UNIX命令将此数据简化为有用的数据:
cat result.txt | sort | uniq -c | sort -fr上面的reduce命令对文件进行排序,过滤唯一的行,然后再次以相反的顺序对其进行排序,以便首先显示说话者最常用的单词。 然后,此命令的前20行的输出为:
9271 DOCTOR the
7728 DOCTOR you
5290 DOCTOR a
5219 DOCTOR i
4928 DOCTOR to
3959 DOCTOR it
3501 DOCTOR and
3476 DOCTOR of
2595 DOCTOR that
2457 DOCTOR in
2316 DOCTOR no
2309 DOCTOR its
2235 DOCTOR is
2150 DOCTOR what
2088 DOCTOR this
2009 DOCTOR me
1865 DOCTOR on
1681 DOCTOR not
1580 DOCTOR just
1531 DOCTOR im 这意味着,最常见的词说,由医生是the 。 这是50个最常用词的分布图:
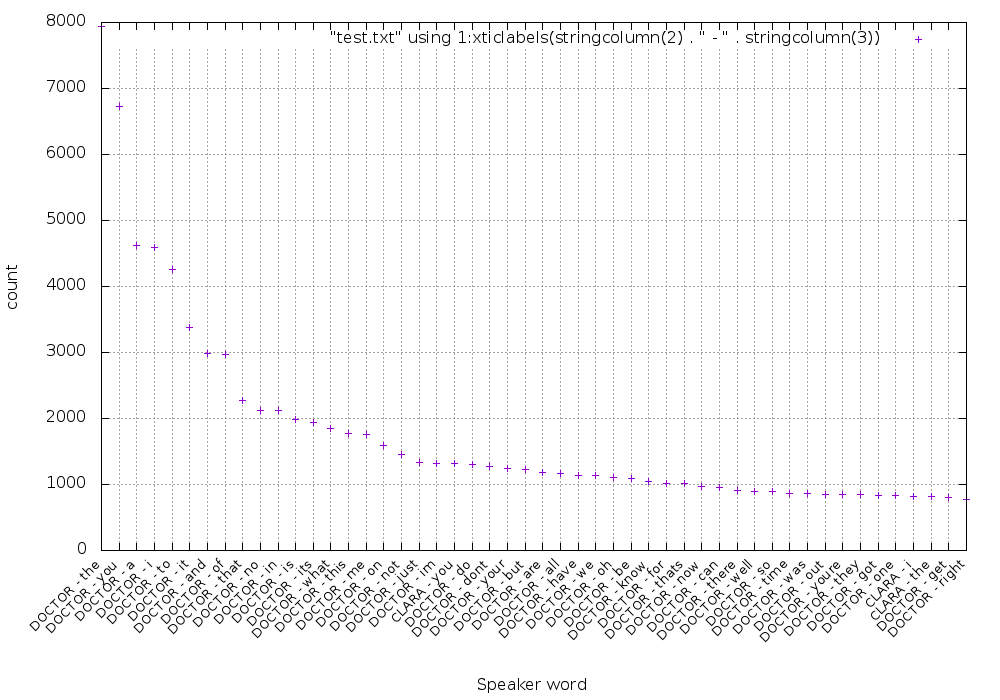
如果您有兴趣,我可以使用以下gnuplot脚本生成此图:
reset
set term png truecolor size 1000,700
set output "dist.png"
set xlabel "Speaker word"
set ylabel "count"
set grid
set boxwidth 0.95 relative
set style fill transparent solid 0.5 noborder
set xtics rotate by 45 right
set xtics font ", 10"
plot "result.txt" using 1:xticlabels(stringcolumn(2) . " - " . stringcolumn(3)) 让我们尝试一些更有意义的事情-让我们看看tardis这个词的使用频率:
cat result.txt | sort | uniq -c | sort -fr | grep 'tardis'不出所料,这表明医生是最谈论“ TARDIS”的人:
335 DOCTOR tardis
43 CLARA tardis
22 ROSE tardis
22 AMY tardis
18 RIVER tardis
16 RORY tardis
10 DOCTOR [OC] tardis
9 MICKEY tardis
8 MARTHA tardis
6 IDRIS tardis
6 DOCTOR tardises
5 JACK tardis
5 DONNA tardis
4 MASTER tardis
4 DALEK tardis
3 TASHA tardis
3 MARTHA [OC] tardis
3 KATE tardis
3 DOCTOR [memory] tardis
2 RIVER [OC] tardis
2 MOMENT tardis
2 MISSY tardis
2 DALEKS [OC] tardis
1 YVONNE tardis
1 WHITE tardis
1 VICTORIA tardis
1 VASTRA tardis
1 UNCLE tardises
1 SUSAN [OC] tardis
1 SEC tardis
1 SARAH tardis
1 ROSITA tardis
1 RORY [OC] tardis
1 ROBIN tardis
1 OSGOOD tardis
1 MOTHER tardis
1 MACE tardis
1 LAKE tardis
1 KATE tardisproofed
1 K9 tardis
1 JENNY tardis
1 JACKIE tardis
1 IDRIS tardises
1 HOWIE tardis
1 HOUSE [OC] tardises
1 HOUSE [OC] tardis
1 HANDLES tardis
1 GREGOR tardis
1 FABIAN tardis
1 EDITOR tardis
1 DOCTOR tardisll
1 DAVROS tardis
1 DANNY tardis
1 DALEK [OC] tardis
1 CRAIG tardis
1 CLARK tardis
1 CLARA [OC] tardis
1 BORS tardis
1 BOB [OC] tardis
1 BLUE tardis
1 AUNTIE tardis
1 ASHILDR tardis结论
Docker Swarm是一种非常灵活的工具,在执行数据分析时,UNIX哲学比以往任何时候都更加重要。 在这里,我们展示了如何通过将Swarm与一些命令混合使用来在群集上分配一个简单的任务-可能的发展是使用一种更易于维护的方法。
一些可能的改进可能是:
- 使用真正的编程语言代替AWK和Bash脚本。
- 构建并推送包含所有必需程序的Docker映像(而不是在Docker运行时将它们复制到Alpine中)。
- 将数据放在最接近处理位置的位置(在示例中,我们使用调度程序在运行时将数据加载到集群中)。
- 最后但并非最不重要的一点:请记住,如果您开始遇到频繁且更复杂的用例,那么Hadoop是您的朋友。
翻译自: https://www.javacodegeeks.com/2016/04/distributed-data-analysis-docker-swarm.html















 1739
1739

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









