





我在我的书《面向Java开发人员的微服务》(O'Reilly,2016年6月,即将推出!)中介绍了其中的一些内容,但是我想在此给出更具体的说明。 我从人们那里收到有关NetflixOSS(它很棒)以及它如何在Kubernetes中运行(它也很棒!)的问题,以及某些组件的重叠之处。 让我试图解释一些 。
Netflix OSS是Netflix编写的一组框架和库,用于大规模解决一些有趣的分布式系统问题。 如今,对于Java开发人员而言,它已成为在云环境中开发微服务的同义词 。 服务发现 , 负载平衡 , 容错等模式对于可扩展的分布式系统而言是非常重要的概念,而Netflix为这些带来了不错的解决方案。 Netflix决定Swift通过“谢谢”的方式,通过这些库和框架为更广泛的开源社区做出贡献。 其他互联网公司也这样做,所以谢谢。 其他一些大型的互联网公司则对他们的发现申请专利,并保持封闭的状态。 那太糟糕了。

无论如何,很多Netflix OSS是在事情在AWS云上运行且没有其他选择的时候编写的。 关于这种遗产的许多假设都被纳入了Netflix库中,这些库可能根据您今天的运行位置(即linux容器等)而不再适用。 随着linux容器 , Docker , 容器管理系统等的出现,我们开始看到在linux容器(在云中,在私有云中,两者都在)中运行微服务的巨大价值。 此外,由于容器基本上是不透明的服务包装,因此我们倾向于不太关心容器内部真正运行的技术(是Java还是Node.js或Go?)。 Netflix OSS主要用于Java开发人员。 它们是需要在Java应用程序/服务代码中包含的库/框架/配置的集合。
因此,这使我们指向了第一点。
微服务可以在多种框架/语言中实现,但是诸如服务发现,负载平衡,容错等功能仍然非常重要。 如果我们在容器中运行这些服务,则可以利用与语言无关的强大基础结构来执行构建 , 打包 , 部署 , 运行状况检查 , 滚动升级 , 蓝绿色部署 , 安全性等工作。 例如, OpenShift是一种考虑到企业需求而构建的Kubernetes风格,它可以为您完成所有这些事情:您无需强迫进入知道或关心这些事情的应用程序层。 使您的应用程序和服务保持简单,并专注于应做的事情。

那么基础架构还能帮助服务发现,负载平衡和容错吗? 为什么这应该是应用程序级的东西?
如果使用Kubernetes(或某些变体),答案是:是的。
服务发现Kubernetes方式
使用Netflix OSS,通常需要设置一个服务发现服务器 ,该服务器充当可以在各种客户端中发现的端点的注册表。 例如,也许您使用Netflix Ribbon与其他服务进行通信,并且需要发现它们在哪里运行。 可以删除服务,它们可以因自己的意愿而死,或者我们可以向集群添加更多服务以帮助扩展。 该中央服务发现注册表基本上跟踪集群中可用的服务。
问题之一:作为开发人员,您需要执行以下操作:
此外,您需要找到所使用的编程语言的客户端,该客户端可以理解如何与服务发现机制对话。 就像我们已经说过的那样,微服务可以用多种不同类型的语言实现,因此可以使用非常好的Java客户端,但是如果不存在Go或NodeJS客户端,则必须自己编写。 语言和开发人员的每一种排列都可能以他们自己的方式来实现这种客户端而告终,现在您不得不维护多个尝试以相同方式但可能在语义上不同的方式执行操作的客户端。 也许每种语言都使用自己的服务发现服务器,并且拥有自己的即用型客户端? 因此,现在您可以管理和维护每种语言类型的服务发现服务器的基础结构吗? 无论哪种方式...太好了。
如果我们仅使用DNS怎么办?
好吧,那解决了我们的客户图书馆问题吧? DNS可以移植到任何使用TCP / UDP的系统中,并且无论您在本地,云,容器,Windows,Solaris等任何地方部署, DNS都可以轻松使用。 您的客户仅指向域名(即http:// awesomefooservice /),基础结构便知道如何路由到DNS指向的服务(可以是具有负载平衡器的VIP或轮询DNS,等等)。 好极了! 现在,我们不必弄清楚我需要使用哪个客户端来发现服务,我只需使用所需的任何TCP客户端即可。 我也不必弄清楚如何管理DNS群集,它已植入网络路由器,并且非常容易理解。
也许DNS糟透了弹性发现
缺点:DNS有点吸引弹性,动态的服务群集。 将服务添加到群集时会发生什么? 还是带走了? 服务的IP地址可能会缓存在DNS服务器/路由器(甚至有些您不拥有)中,甚至是您自己的IP堆栈中。 如果您的服务/应用程序正在非80端口侦听怎么办? DNS是考虑到标准端口(例如端口80)而建立的。 要对DNS使用非标准端口,可以使用DNS SRV记录,但随后又需要在应用程序层使用特殊客户端来发现这些条目。
Kubernetes服务
让我们只使用Kubernetes 。 无论如何,我们将在Docker / linux容器容器中运行东西,而Kubernetes是运行Docker容器的最佳场所。 或火箭容器 。 或Hyper.sh“容器” 。
(请注意,我是技术的傻瓜,更是如此,看起来是“简单”的技术……因为您无法构建具有复杂零件的复杂系统。您需要简单零件。但是制造简单零件本身就是复杂的。Google和红帽已经使用Kubernetes简化了分布式系统的部署/管理/工作,这对我来说简直是棒极了:))
使用Kubernetes,我们只需创建并使用Kubernetes Services ,我们就完成了! 我们不必浪费时间来设置发现服务器,编写自定义客户端,使用DNS进行固定等等。它可以正常工作,我们将继续进行微服务中提供业务价值的下一部分。
那么它是怎样工作的?
这是Kubernetes引入表格以实现此目的的简单抽象:
豆荚很简单。 它们基本上是您的linux容器。 标签很简单。 它们基本上是键值字符串,可用于标记Pod(例如Pod A具有标签app=cassandra , tier=backend , version=1.0 , language=java )。 这些标签可以是您内心渴望的任何东西。
最后一个概念是服务 。 也很简单。 服务是固定的群集IP地址 。 此IP地址是一个虚拟IP地址 ,可用于发现/调用Pod /容器中的实际端点。 该IP地址如何知道哪些Pod /容器可以被发现? 它使用_Label Selector__来选择具有您定义的标签的容器。 例如,假设我们想要一个带有“ app = cassandra AND tier = backend”选择器的Kubernetes服务。 这将为我提供带有虚拟IP的服务,该服务会发现与该标签匹配的任何Pod(同时具有app = cassandra和tier = backend)。 会主动评估此选择器,以便所有离开群集的Pod或加入群集的任何Pod(基于它们具有的标签)将自动开始参与服务发现。
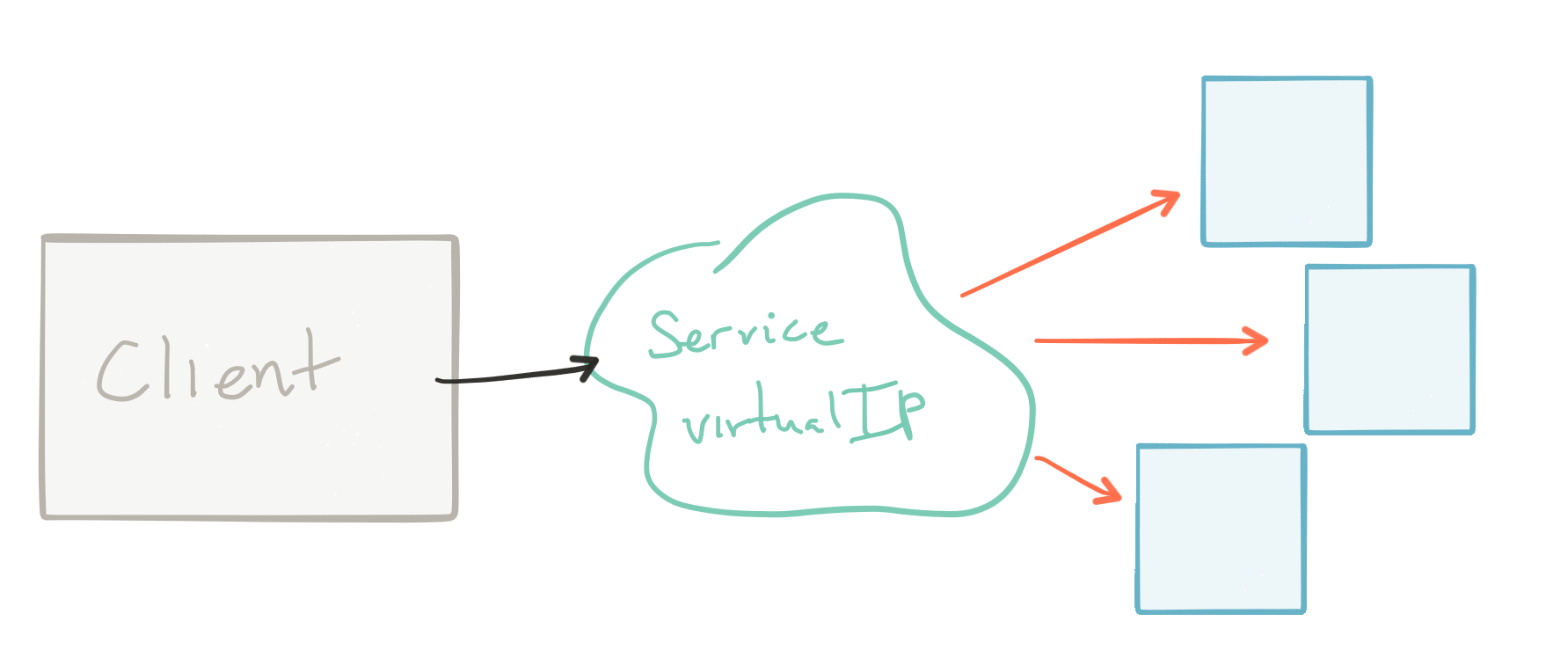
使用Kubernetes Services来选择要添加到服务中的容器的另一个附加好处是,Kubernetes在其活动性和健康性方面很了解哪个容器属于服务。 Kubernetes可以使用内置的活动性和运行状况检查功能 ,根据特定服务的生命周期和/或功能是否正常,确定是否应将一个Pod包含在特定服务的Pod集群中。 它可以驱逐那些不是的。
请注意 ,Kubernetes服务的实例不是“事物”,设备,泊坞容器或其他任何东西。它是虚拟的“事物”……因此,没有单点故障。 这是Kubernetes路由的IP地址。
对于开发人员来说,这是非常强大和简单的。 现在,希望使用Cassandra后端的应用程序仅使用此固定IP地址与Cassandra数据库进行对话。 但是,对固定IP进行硬编码通常不是一个好主意,因为如果要将应用程序/服务移至其他环境(即QA,PROD等),该怎么办。 现在您必须更改该IP(或注入一些配置),并且现在已经增加了配置负担。 因此,我们只使用DNS :)
在Kubernetes中使用群集DNS是正确的答案。 由于IP是针对给定环境(Dev,QA等)固定的,因此我们不关心对其进行缓存:它永远不会更改。 现在,如果我们使用DNS,则可以将我们的应用程序配置为与http:// awesomefooservice /上的服务进行通信,甚至当我们从Dev迁移到QA到Prod时,只要在每个环境中都有这些Kubernetes服务,我们的应用程序就不需要改变。
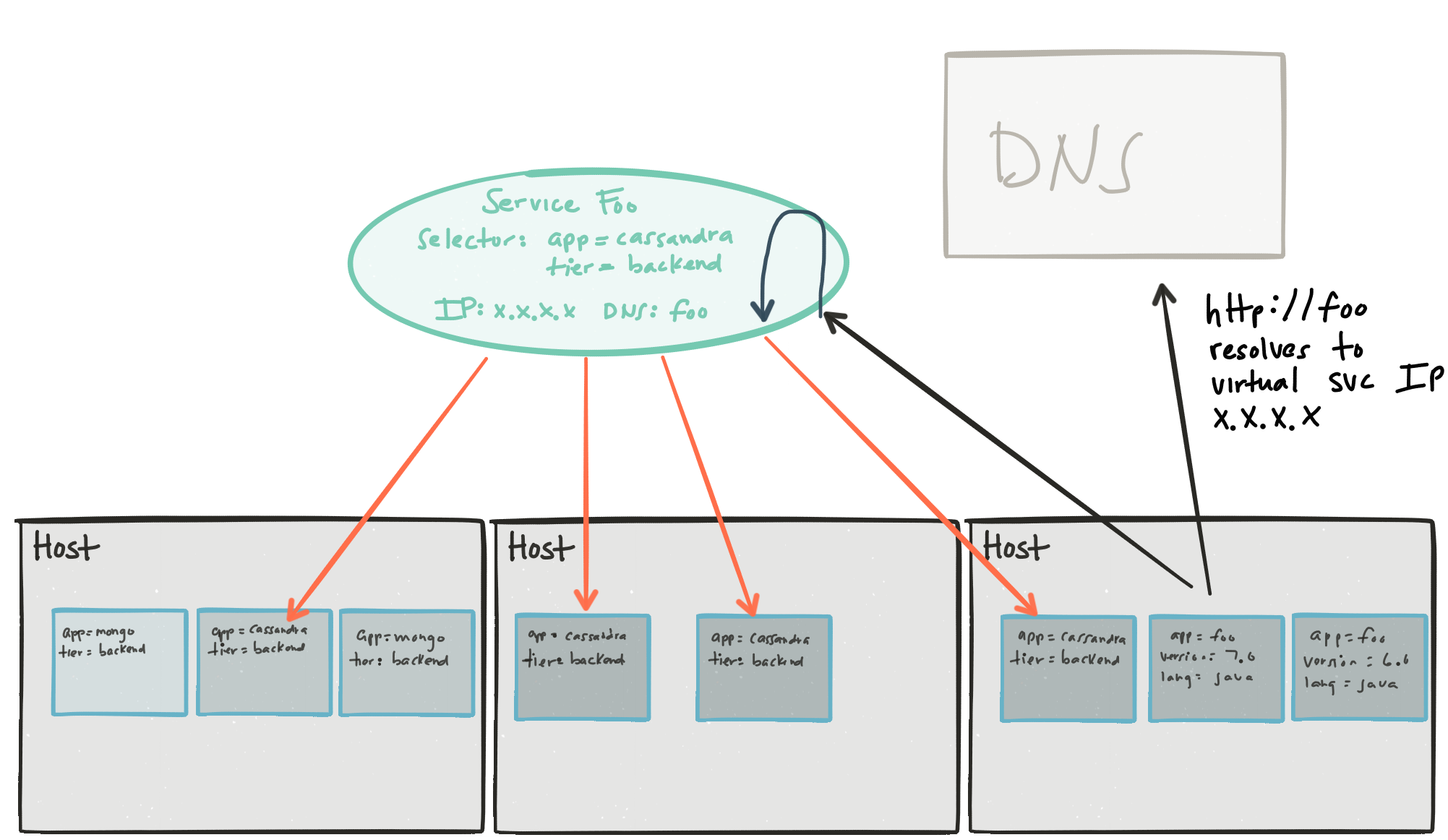
我们不需要其他配置,也不需要担心DNS缓存/ SRV记录,自定义库客户端和管理其他服务发现基础结构。 现在可以将Pod添加到群集(或从群集中取出),并且Kubernetes Service的标签选择器将根据标签对群集进行有效地分组。 无论您是Java应用程序,Python,Node.js,Perl,Go,.NET,Ruby,C ++,Scala,Groovy,您的应用程序都可以与http:// awesomefooservice /进行对话。 此服务发现机制不强加特定的客户端。 只需使用它。
服务发现变得容易得多。
客户端负载平衡如何?
这个很有趣。 Netflix编写了Eureka和Ribbon ,通过这些组合,您可以启用客户端负载平衡。 基本上,发生的情况是服务注册表(Eureka / Consul / Zookeeper / etc)跟踪群集中存在哪些服务,并将该数据发送给对此感兴趣的客户端。 然后,由于客户端具有有关群集中哪些节点的信息,因此它可以选择一个(随机,粘性或某些自定义算法),然后调用它。 在下一次调用时,它可以根据需要在集群中选择其他服务。 这样做的好处是我们不需要物理/软负载平衡器,它很快就会成为瓶颈。 另一个重要方面:由于客户端知道服务的位置,因此客户端可以直接与服务提供商联系,而无需其他跃点。
IMHO客户端负载平衡是5%的用例。 让我解释。
我们想要的是一种理想的方式来实现可伸缩的负载平衡,而无需任何其他设备和客户端库。 在大多数情况下,我们可能并不在乎中间有一个负载平衡器的额外跃点(考虑一下。现在,可能有99%的应用程序都已经以这种方式部署)。 我们可能会遇到这样的情况:对服务A的调用调用了对服务B的调用,服务B调用了服务C,D和E,然后您得到了图片。 在这种情况下,如果每个人都跳了一跳,我们会产生很多额外的延迟。 因此,可能的解决方案可能是“删除多余的跃点”。这是……但不仅限于负载均衡器的跃点:在您必须对下游服务进行的调用数中:)关注我的事件驱动系统博客以及有关“ 自治权与授权”的讨论,以了解我的打算:)
像我们在上面的服务发现部分中一样,使用Kubernetes Services,我们可以完成适当的负载平衡(同样,也没有服务注册表,自定义客户端,DNS缺陷等所有开销)。 当我们通过其DNS(或IP)与Kubernetes服务进行交互时,默认情况下,Kubernetes将在集群中各个Pod之间进行负载平衡(请记住,集群是由标签和标签选择器定义的)。 如果您不希望在负载平衡中增加额外的跃点,则不必担心。 该虚拟IP直接路由到Pods,它不会访问物理网络
好极了! 轻松适用于95%的用例。 而且很有可能,您处于用例的95%分布中,因此不需要过度设计。 把事情简单化。
那5%的情况呢? 在某些情况下,您可能必须在运行时做出一些业务决策,以决定您真正要调用的集群中的哪个确切后端端点。 基本上,您想使用一些自定义算法,而不仅仅是“循环”,“随机”,“粘性会话”,并且特定于您的应用程序。 为此,请使用客户端负载平衡。 在此模型中,您仍然可以利用Kubernetes的服务发现来找出集群中有哪些Pod,然后使用您自己的代码来决定直接调用哪个Pod(基于标签等)。 fabric8.io社区的Kubeflix项目具有用于使用Ribbon的发现插件 ,例如,从Kubernetes REST API获取服务的所有Pod的列表,然后让用户使用Java代码来决定要向哪个Pod进行业务决策。打电话 。 对于其他语言,也可以执行相同的操作,只需使用Kubernetes REST API来查询Pod等。对于这些用例,投资于特定于客户端的发现库可能是有意义的。 更合适的方法是将此自定义逻辑分解为自己的模块,以便其依赖项与应用程序分离。 使用Kubernetes,您可以将此单独的模块作为辅助工具部署到您的应用程序/服务中,并在其中保留自定义负载平衡逻辑。
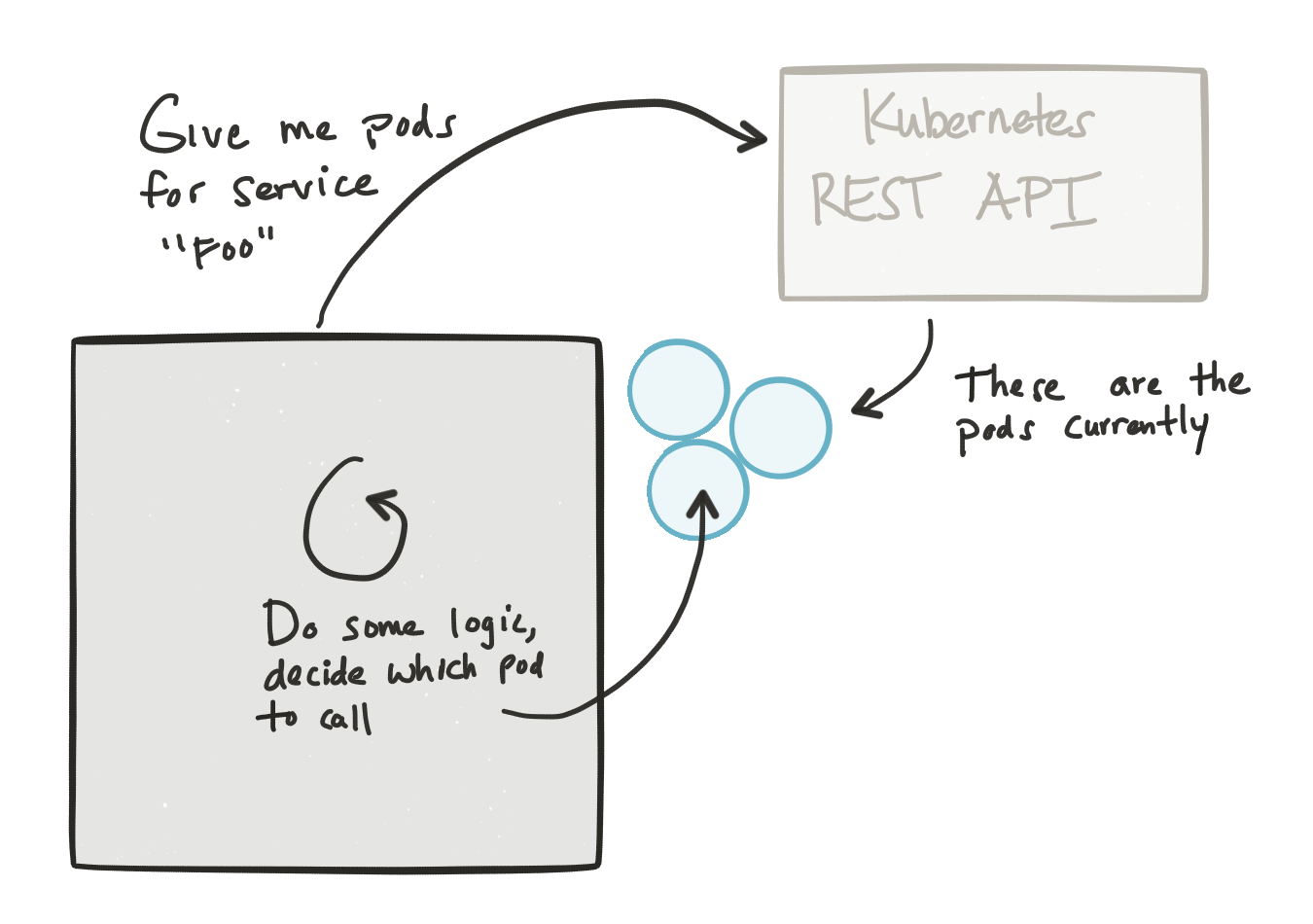
同样,恕我直言,这是5%的用例,并且具有额外的复杂性。 对于95%的用例,只需使用内置的功能,而无需使用任何花哨的特定于语言的客户端。
容错呢?
具有依赖性的系统在构建时应始终牢记承诺 。 这意味着,即使从属系统不可用或崩溃,他们也应始终意识到自己应承担的责任。 我们是否应该问一下Kubernetes的容错方式?
好吧,Kubernetes确实具有自我修复功能。 如果某个容器中的容器或容器发生故障,Kubernetes可以将其恢复以维护其ReplicaSet不变式(基本上,如果您告诉Kubernetes我想要10个“ foo”容器,即使容器停止运行,它也将始终尝试保持该状态)降低;它将使他们恢复正常以维持其副本数(在本例中为10)。
自我修复基础架构很棒,并且与Kubernetes兼容,但是我们感兴趣的是当应用程序的依赖项(数据库,其他服务等)出现故障时,应用程序会发生什么变化? 好吧,这取决于应用程序来确定如何处理。 例如,在Netflix,如果您尝试观看特定电影,则会致电“授权”服务,该服务知道您拥有观看电影的特权。 如果该服务中断,我们是否应该阻止用户观看该电影? 我们应该显示异常堆栈跟踪吗? netflix方法是让用户观看电影。 最好让订阅者在服务依赖性错误期间偶尔观看一次他们无权获得的电影,而不是在他们确实有权获得该电影的权利时炸毁或说“不”。
我们想要的是一种优雅降级或寻找替代方法的方法,以兑现我们对服务合同的承诺。 Netflix Hystrix是Java开发人员的绝佳解决方案。 Netflix Hystrix实现了一种“笨拙” , “断路”和“后备”的方法 。 这些都是特定于应用程序的实现,因此在这种情况下,有针对不同语言的特定客户端库是合理的。

Kubernetes完全可以帮助您吗? 是!
再次,查看令人敬畏的Kubeflix项目,您可以使用Netflix Turbine项目来聚合和可视化群集中运行的所有断路器。 Hystrix可以将服务器端事件公开为可由Turbine使用的流。 但是,涡轮如何发现其中包含豆荚的豆荚? 好问题:)我们可以为此使用Kubernetes标签。 如果我们将使用Hystrix的Pod标记为hystrix.enabled=true则Kubeflix Turbine引擎可以自动发现每个hystrix断路器的SSE流 ,并将其显示在Turbine网页上。 谢谢Kubernetes!
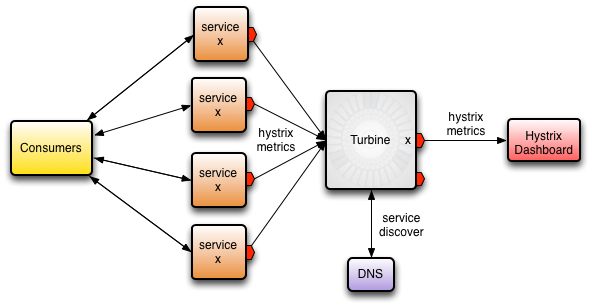
感谢约瑟夫·威尔克的上图。
那配置呢?
Netflix Archaius旨在处理云中服务的分布式配置管理。 为此,就像使用Eureka和Ribbon一样,您需要设置配置服务器并使用Java库来查找配置值。 它还支持动态配置更改等(请记住,Netflix是为AWS建立的。.它们是netflix;作为CI / CD管道的一部分,他们将构建AMI并进行部署。构建AMI或任何VM映像可能会很耗时。并在大多数情况下有很多不必要的开销……使用Docker / linux容器,事情变得更加敏捷,如我将在几秒钟后从配置角度进行解释)。
那95%的用例又如何呢? 我们希望将特定于环境的配置(这是一个重要的区别……并非“每一个”配置都是特定于环境的配置,需要根据我们正在运行的环境进行更改)存储在我们的应用程序外部,然后将其注入在我们运行的环境(DEV,QA,PROD等)上。 但是,我们确实希望以一种与语言无关的方式来查找配置,而不是强迫每个人都使用Java和/或将其类路径与其他Java库进行复杂的配置。
在Kubernetes中,我们有三种构造用于注入基于环境的配置。
基本上,我们可以通过大多数语言可以读取的环境变量(可以轻松读取Java,NodeJS,Go,ruby,python等)将配置数据注入linux容器。 我们可以将配置存储在git中(这是个好主意),我们可以将配置库直接绑定到我们的pod(作为文件系统上的文件),然后可以使用存在使用应用程序配置文件的任何框架工具来使用它。 最后,我们可以使用Kubernetes ConfigMaps将版本配置保存到ConfigMap中,从而稍微分离git repo,然后将其作为文件系统安装到pod中。 同样,您将以与使用相应语言/框架中的文件系统中的任何配置文件相同的方式使用配置文件。
5%的用例呢?
在5%的用例中,您可能希望在运行时动态更改配置。 Kubernetes为此提供了帮助。 您可以在ConfigMap中更改配置文件,并使这些更改动态地传播到安装它们的Pod。 在这种情况下,您需要具有一个客户端库,该库能够检测这些配置更改并将其公开给您的应用程序。 Netflix Archais有一个可以做到这一点的客户。 用于Java的Spring Cloud Kubernetes使此操作在Kubernetes中更容易实现(使用ConfigMaps)。
那么,Spring Cloud呢?
使用Spring开发微服务的Java人士通常将Spring Cloud与Netflix OSS等同起来,因为其中很多都是基于Netflix OSS。 fabrjc8.io社区也有很多在Kubernetes上运行Spring Cloud的好处。 请查看https://github.com/fabric8io/spring-cloud-kubernetes了解更多信息。 这些模式中的许多模式(包括配置,跟踪等)可以在Kubernetes上很好地运行,而无需其他复杂的基础架构(例如服务发现引擎,配置引擎等)。
摘要
如果您正在考虑构建微服务,并且偏爱Netflix OSS / Java / Spring / Spring Cloud,请注意您不是Netflix,则无需直接使用AWS EC2原语并通过这样做使应用程序复杂化所以。 如果您想使用Docker,则采用Kubernetes是一个明智的选择,并且开箱即用地附带了许多这样的“分布式系统功能”。 在需要时对适当的应用程序级库进行分层,并避免一开始就因为Netflix在5年前提出了这种方法而使您的服务复杂化(因为他们必须!如果5年前使用Kubernetes,他们的Netflix OSS堆栈看起来就可以了)相当不同:))是一个明智的选择:)
翻译自: https://www.javacodegeeks.com/2016/06/netflix-oss-spring-cloud-kubernetes.html















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










{kind=link}