





在《 从Docker Swarm集群内部任何地方运行的所有容器转发日志》一文中,我们设法将集中式日志记录添加到了集群中。 来自在任何节点内运行的任何容器的日志都被传送到中央位置。 它们存储在ElasticSearch中,可通过Kibana获得。 但是,我们可以轻松访问所有日志的事实并不意味着我们拥有调试问题或从一开始就避免发生所需的所有信息。 我们需要用有关系统的其余信息来补充日志。 我们需要的不仅仅是日志本身所能提供的。
集群监控系统的要求
带有网络流量图的Grafana仪表板[/ caption]通过使用群集调度程序,我们可以同时降低和增加系统的复杂性。 与单独使用容器相比,使用Docker Swarm扩展服务更容易,也更简单。 事实是,Docker已经大大简化了我们之前的流程。 加上带有服务发现的新网络,结果几乎太简单了,难以置信。 另一方面,表面之下隐藏着复杂性。 如果我们尝试将迄今为止使用的动态工具与不同时代创建的动态工具相结合,则可以很容易地观察到这种复杂性表现出来的一种方式。
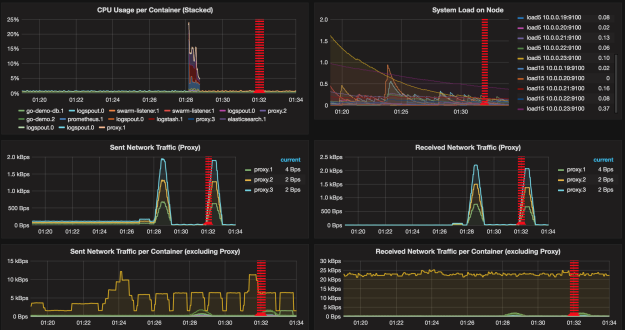
具有网络流量图的Grafana仪表板
以Nagios为例。 我不会说我们不能使用它来监视我们的系统(我们当然可以)。 我要说明的是,这将与我们围绕集群内运行的容器设计的新系统的体系结构发生冲突。 我们的系统变得比以前复杂得多。 副本数量在波动。 今天我们有四个服务实例,明天早上可能有六个实例,但下午下降到三个。 它们分布在群集的多个节点上并在周围移动。 正在创建和销毁服务器。 我们的集群及其内部的一切都是真正的动态和弹性。
我们正在构建的系统的这种动态特性不适用于Nagios,后者期望服务和服务器相对静态。 它期望我们提前定义事物。 这种方法的问题是我们没有预先的信息。 虫群呢。 即使我们获得了所需的信息,它也会很快改变。
我们正在构建的系统是高度动态的,并且我们应该用来监视此类系统的工具需要能够应对这种动态性。
不仅如此。 大多数“传统”工具都倾向于将整个系统视为黑匣子。 一方面,这具有一定的优势。 最主要的是,它使我们能够将服务与系统的其余部分分离。 在很多(但不是全部)情况下,白盒监视意味着我们需要添加到服务监视库中并在它们周围编写一些代码,以便它们可以公开我们服务的内部结构。
在选择向您的服务中添加严格不属于其工作的内容之前,请三思而后行。 当我们采用微服务方法时,我们应该努力使服务在功能上限于其主要目标。 如果是购物车,则应该使用API,以便我们添加和删除商品。 添加将扩展此类服务的库和代码,以使其可以在服务发现存储中注册自己,或将其指标暴露给监视工具会产生过多的耦合。 一旦这样做,我们将来的选择将非常有限,并且系统的更改可能需要相当长的时间。
我们已经设法避免将服务发现与我们的服务耦合在一起。 go-demo服务不具备服务发现的任何知识,但是,我们的系统具有所需的所有信息。 当组织陷入陷阱并开始将其服务与周围的系统耦合时,还有许多其他示例。 在这种情况下,我们的主要任务是通过监视是否可以完成相同的任务。 我们是否可以避免将指标的创建与为服务编写的代码相结合?
再说一次,能够进行白盒监控可以提供黑盒所没有的很多好处。 首先,了解服务的内部结构可以使我们以更精细的细节进行操作。 它使我们知道,如果将系统视为黑匣子,则无法获得。
在为实现高可用性和快速响应时间而设计的分布式系统中,仅将其限制为运行状况检查以及CPU,内存和磁盘使用情况监视是不够的。 我们已经有了Swarm,可以确保服务运行状况良好,并且我们可以轻松制作脚本来检查基本资源的使用情况。 我们不仅需要更多。 我们需要一个不会引入不必要耦合的白盒监控。 我们需要智能警报,当出现问题或什至自动解决问题时,该警报将通知我们。 理想情况下,甚至在问题发生之前,我们都会执行警报和自动更正。
我们从监视系统中需要的一些要求如下。
- 一种分散的方式来生成指标 ,该指标将能够应对集群的高动态性。
- 可以跨多个维度查询所需的多维数据模型 。
- 一种高效的查询语言 ,使我们能够利用我们的监视数据模型并创建有效的警报和可视化。
- 简单易用 ,几乎无需任何培训即可使几乎任何人使用该系统
在本文中,我们将探索导出一组不同指标的方法,一种收集,查询和通过仪表板公开它们的方法。
在做所有这些之前,我们应该做出一些选择。 我们应将哪些工具用于监控解决方案?
选择正确的数据库来存储系统指标
在DevOps 2.0 Toolkit中 ,我反对使用Nagios和Icinga等“传统”监视工具。 相反,我们选择对日志和系统指标都使用ElasticSearch。 在从Docker Swarm集群内部任何地方运行的所有容器转发日志中 ,我重申了使用ElasticSearch作为日志记录解决方案的选择。 我们可以通过存储指标来扩展其用途吗? 我们可以。 我们应该这样做吗? 我们应该使用它作为存储系统指标的地方吗? 有更好的解决方案吗?
如果将ElasticSearch用作数据库来存储系统指标,则最大的问题是它不是时间序列类型的数据库。 日志从ElasticSearch功能中受益匪浅,可以执行自由文本搜索并以非结构化方式存储数据。 但是,对于系统指标,我们可能会利用其他类型的数据存储。 我们需要一个时间序列数据库。
时间序列数据库是围绕优化的方法来设计的,用于存储和检索时间序列数据。 它们的最大好处之一是,它们以非常紧凑的格式存储信息,从而可以承载大量数据。 如果在其他类型的数据库(包括ElasticSearch)中比较基于时间的数据的存储需求,则会发现时间序列数据库效率更高。 换句话说,如果您的数据是基于时间的指标,请使用为此类数据设计的数据库。
大多数(如果不是全部)时间序列数据库的最大问题是分布式存储。 使用复制来运行它们是不可能的,或者充其量是挑战。 坦率地说,此类数据库旨在运行单个实例。 幸运的是,我们通常不需要在此类数据库中存储长期数据,并且可以定期清理它们。 如果必须长期存储,解决方案是将聚合数据导出到其他类型的数据库中,例如ElasticSearch,顺便说一句,当涉及复制和分片时,它会发光。 但是,在“疯狂”并开始导出数据之前,请确保您确实需要执行类似操作。 时间序列数据库可以轻松地在单个实例中存储大量信息。 很有可能由于容量原因而无需扩展它们。 另一方面,如果数据库发生故障,则Swarm会重新安排它的时间,并且您只会丢失几秒钟的信息。 这种情况不应该是灾难,因为我们正在处理汇总数据,而不是单个事务。
InfluxDB是最杰出的时间序列数据库之一。 普罗米修斯是一种常用的替代方法。 我们将跳过对这两个产品的比较,只是注意,我们将使用后面的产品。 两者都是值得您选择的普罗米修斯监测解决方案的候选人,它具有潜在的优势,我们不容忽视。 社区计划是以Prometheus格式本地公开Docker指标。 在撰写本文时,尚无确定的日期,但是我们将尽最大努力根据该计划设计系统。 如果您想自己监视进度,请观看Docker问题27307 。
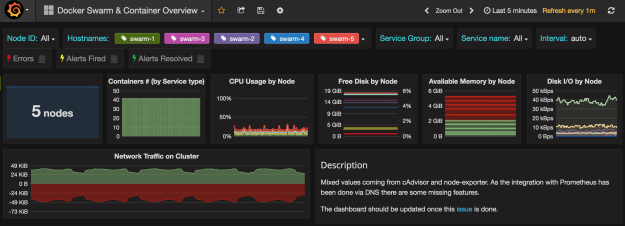
带有节点指标的Docker Swarm Grafana仪表板
您刚读完的文章是DevOps 2.1 Toolkit:Docker Swarm一书中“ 收集度量标准和监视群集”一章的摘录(略作修改)。
DevOps 2.1工具包:Docker Swarm
如果您喜欢本文,则可能对DevOps 2.1 Toolkit:Docker Swarm一书感兴趣。 与本系列的前一篇文章( DevOps 2.0工具包:使用容器化微服务自动化持续部署管道 )提供了对一些最新DevOps实践和工具的总体了解不同,本书完全致力于Docker Swarm及其过程和工具。我们可能需要构建,测试,部署和监视集群中运行的服务 。

这本书仍在“发展中”。 您可以从LeanPub获取副本。 它也可以作为DevOps Toolkit系列软件包使用。 如果您现在下载它,请在其完全完成之前,获得有关新章节和更正的频繁更新。 更重要的是,您可以通过向我发送反馈意见来影响本书的发展方向。
我选择精益方法进行图书出版,因为我相信早期反馈是生产优质产品的最佳方法。 请帮助我,使本书成为任何想要采用Docker Swarm进行集群编排和调度的人的参考。
翻译自: https://www.javacodegeeks.com/2016/11/collecting-metrics-monitoring-docker-swarm-clusters.html















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









