





您需要遵循的Java性能指标来了解应用程序在生产中的行为
与过去将软件装在包装盒中且无法了解其在生产中的性能的时代不同,如今几乎可以想到并报告所有您能想到的指标。 我们现在要解决的问题来自信息过载和规模扩展,而不是没有足够的信息。 随着数十或数百台服务器的运行,这变得更加难以跟踪。 那些装箱的软件时代剩下的一件事是日志,至今已经有20多年的历史了。 大多数开发人员仍然依赖那些开发人员来了解他们的生产系统,但是现在他们正逐渐被替换。
在本文中,我们决定收集一些最有见地的指标,您可以遵循这些指标来了解应用程序在生产中的行为,而无需以任何方式依赖日志文件。 除了用户负载(或AWS停机)之类的外部因素之外,新部署可能是对Java性能指标行为的最普遍影响。 因此,在新部署之后的敏感时刻,对它们的跟进变得更加关键。
如果其中有数字,则必须为真!
在继续讨论每个指标之前,让我们重点说明一个主要警告。 有一个想法是,如果您支持自己的数据,那么您一定是对的。 这里的问题是,错误表示数据真的很容易。 比向您证明错误时要容易得多。 让我们在这里区分两种方法,分别是查看简单的时间序列数据,查看某个基本指标随时间变化的行为,与从不同角度查看数据并控制性能百分位数 。 最重要的是,我们需要注意所关注指标的影响,并进行一些合理性检查以评估它们。
例如,假设我们正在查看中位数/第50个百分点的交易响应时间。 许多公司将其用作主要KPI的一种流行指标。 实际上,当单个网页浏览量具有数十个或更多这些请求(通常超过40个)时,这意味着用户有99.999%的可能性比中位数要差(结果很简单:1 –(0.5 ^ 40 ))。 那么,关注哪个百分位有意义? 即使我们查看的是第95个百分位数,由于每页可能有40个以上的请求,因此大多数用户的响应甚至会更差。 乘以几个综合浏览量,就更难了。 要了解有关百分位数以及数据误导性的更多信息,请在此处查看Gil Tene的博客。
现在,让我们仔细看看我们的选择指标,确切地了解它们代表什么,以及如何获得它们:
1.响应时间和吞吐量
应用程序响应时间衡量应用程序中的事务完成需要多长时间。 也可以从HTTP请求级别(即数据库级别)查看它。 使您可以缩小最慢的查询,这些查询可能需要一些优化帮助。 吞吐量指示器从另一个角度查看事务,并显示您的应用程序在任何给定时间(通常是每分钟(rpm))正在处理多少个请求。
一种测量方法是使用APM(例如New Relic或AppDynamics)(我们在之前的博客文章中进行了对比)。 使用这些工具,您可以跟踪平均响应时间,并将其与主要报告仪表板中的昨天或上周的直接响应时间进行比较。 这可以帮助我们了解新部署如何影响应用程序的运行状况。 另一个视图使您可以查看Web事务百分比,并测量完成HTTP请求所需的时间。
也可以在内部进行监控,但可能需要进行硬编码,例如使用Dropwizard指标发送数据并将其发布到Graphite。 当您将数据与其他指标相关联时,似乎最有用的见识会出现。 我们将在下面介绍的以下措施中对此进行更多说明。
要点1:确保所使用的收集方法可以让您从不同角度查看数据并降至百分位水平。
检查工具:
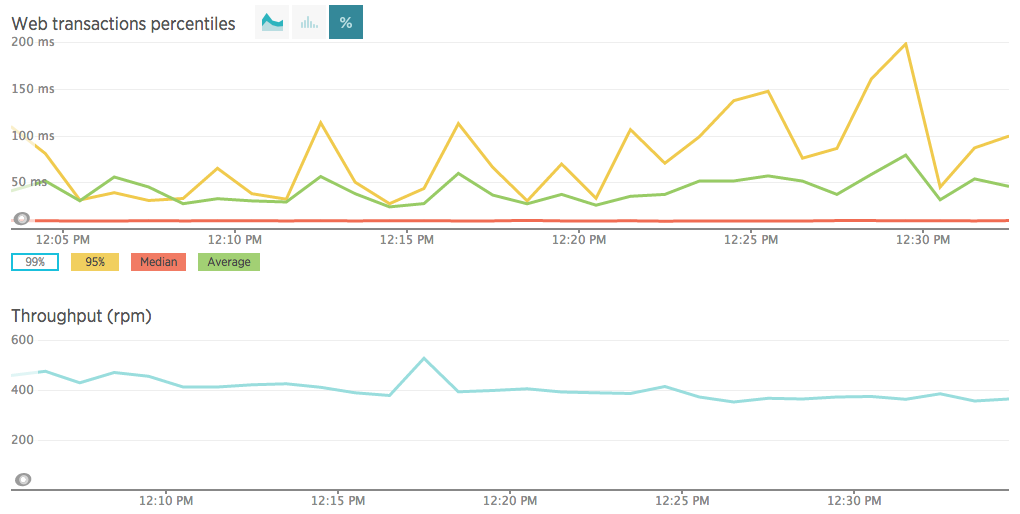
New Relic中的Web事务百分位数和吞吐量报告
2.平均负载
我们广泛遵循的第二个指标是服务器上的平均负载。 传统上,“平均负载”是一个指标,分为3个,显示最近1分钟,5分钟和15分钟(从左到右)的结果。 只要您的分数低于您的计算机所拥有的内核数,就可以了。 一旦超过核数。 这意味着您的机器承受压力。
除了简单地衡量CPU利用率之外,平均负载还考虑了每个内核队列中有多少个进程。 一个状态是100%使用了一个内核,但很快就会完成一个任务,而队列中还有6个任务的状态则完全不同。 单靠CPU利用率并不能解决这个问题,但平均负载要考虑更大的范围。
Hisham Muhammad使用htop跟踪Linux上服务器平均负载的一种很棒的方法。 出色的彩色实时显示,使您的命令行感觉就像是NASA仪表板:)
要点2:利用资源不足以确定资源的负载,您需要注意队列中的任务才能充分了解情况。
检查工具: htop
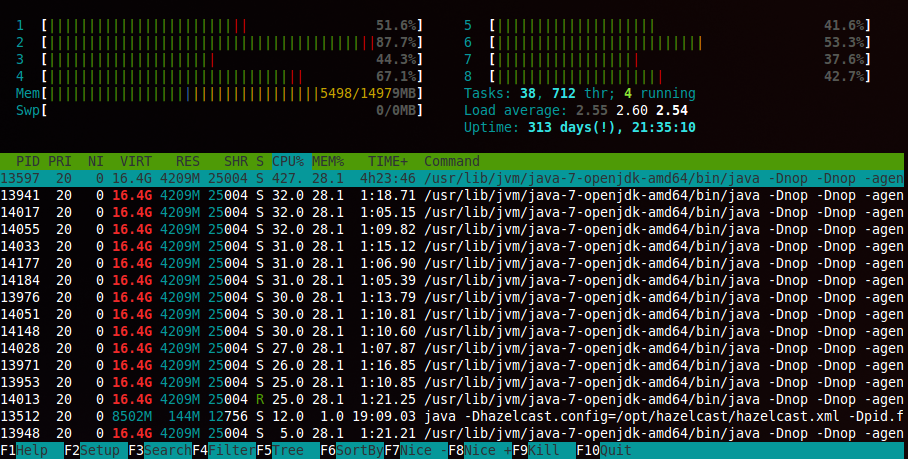
运行htop以检查我们一台服务器上的负载,平均负载出现在右上角
3.错误率(以及解决方法)
有几种不同的方法来查看错误率,并且大多数开发人员都采用高级度量标准–在整个应用程序级别上查看错误率,例如,整个HTTP请求中失败的HTTP事务总数。 但是,通常有一个被忽略的深度层,对您的应用程序运行状况具有直接影响:特定事务的错误率。 显示代码中某个方法失败的次数,并在调用该方法的总次数中产生记录的错误或异常。
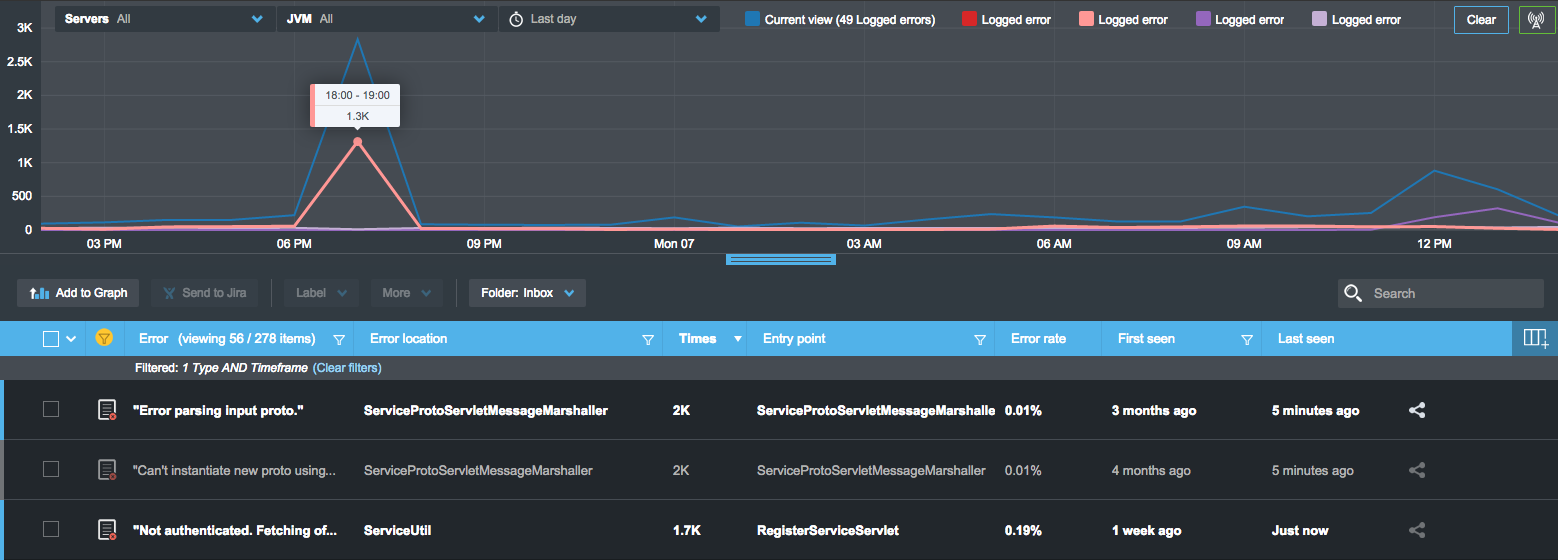
塔基皮(Takipi)中特定事件导致的错误率细分,缩小了导致错误量达到峰值的根本原因
但是,这些数据本身并不意味着太多,对吧? 在确定最紧急事件(无论是记录的错误还是异常)的优先级之后,第二步是找出其真正的根本原因并加以解决。 我们还为这个问题建立了解决方案。 使用Takipi时,您无需拉出日志文件即可开始寻找线索。 可从同一屏幕访问有关服务器状态的所有信息。 这包括跨每个错误调用的多个实例的堆栈跟踪,实际源代码和变量值。
要点3:高级数据不足以找出增加错误率的真正根本原因。 您需要偏爱使用收集方法来生成有关您所关注指标的最丰富数据的方法。
检查工具: 塔基皮
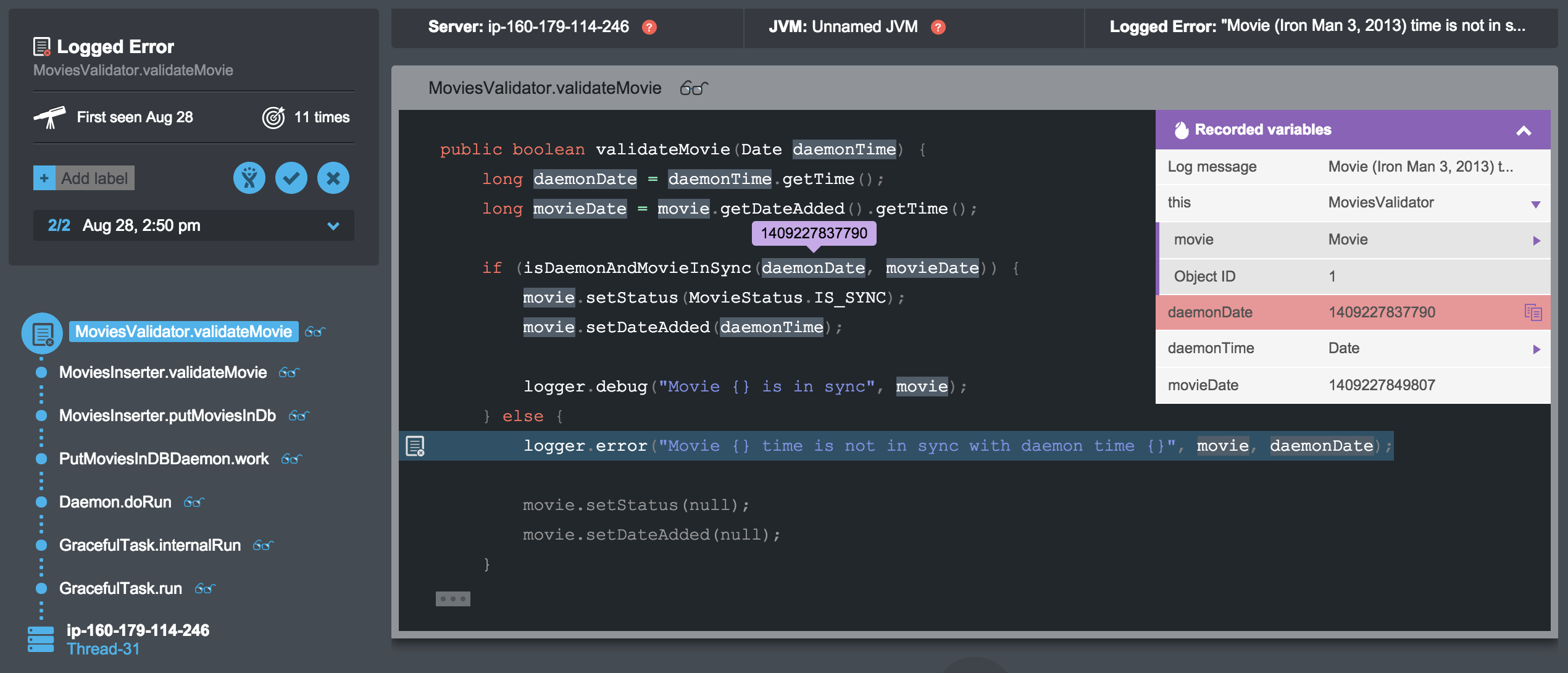
将错误分析放大到导致每个错误的特定变量
4. GC速率和暂停时间
垃圾收集器行为异常是导致应用程序吞吐量和响应时间深入研究的主要原因之一。 因此,当深入查找导致这些症状的原因时,一个常见的解决方案是该应用程序处于世界GC暂停停止的中间。 要了解有关优化垃圾收集的过程及其相关指标的更多信息,可以查看我们发布的有关GC问题解决方案策略的文章 。
了解GC暂停频率和持续时间的关键在于分析GC日志文件。 如果您不自行分析或使用jClarity之类的工具进行分析,这不是一个开箱即用的指标。 要对此进行分析,您需要确保使用适当的JVM参数打开GC日志收集。
要点4:请记住要广泛地将不同指标之间的数据关联起来,以了解它们如何相互影响。
检查工具:
5.业务指标
应用程序的性能不仅取决于它的响应速度,还取决于其错误率。 不利的一面是业务指标,而这些指标的责任不仅仅在于产品/销售人员。 诸如收入,用户数量以及与应用程序特定区域的交互之类的指标对于理解其性能至关重要。 将这些与新部署的时间戳并排放置,对于查看部署的修补程序和新功能如何影响业务的底线非常重要。 当然希望会更好,但是如果情况变得更糟–将所有数据放在一个位置后,很容易知道需要解决的问题。
此外,将这些业务指标与错误率和等待时间有关的数据实时绑定在一起的能力非常强大。 这样,您就可以深入了解到底是哪个错误或异常给您带来了最大的麻烦,因此您可以根据它们对业务目标的影响来确定它们的优先级。 了解所有异常情况和日志错误。 做到这一点的方法是使用对集成开放的监视工具,并与附近的其他孩子一起玩耍。 这就是为什么保持所有数据开放并可以选择将其导出到我们选择的服务非常重要的原因。
假设您正在使用Graphite集中报告的业务指标,则需要使用用于打开的工具向其发送数据。 例如,我们的工程团队启用此功能的方式是打开要报告的指标,然后通过StatsD发布这些指标,然后可以将其定向到用户选择使用的任何报告仪表板。
要点5:孤立的数据已成为过去。 您选择的用于提取指标的方法还应该使您将其与来自不同来源的数据相关联。
检查工具:
6.正常运行时间和服务健康
这个指标为整个shebang定下基调。 除了将其用作警报介质外,它还使您可以随着时间的推移定义SLA。 查看您为用户提供功能全面的服务的时间百分比。
我们跟踪此问题的方式是通过运行状况检查,我们使用Pingdom在单个servlet上运行。 该检查将调查参与我们应用程序中事务的所有服务,包括数据库和S3。
要点六:正常运行时间可能是一个二元指标,但查看汇总问题以找到堆栈中的薄弱环节有很多价值。
检查工具: Pingdom
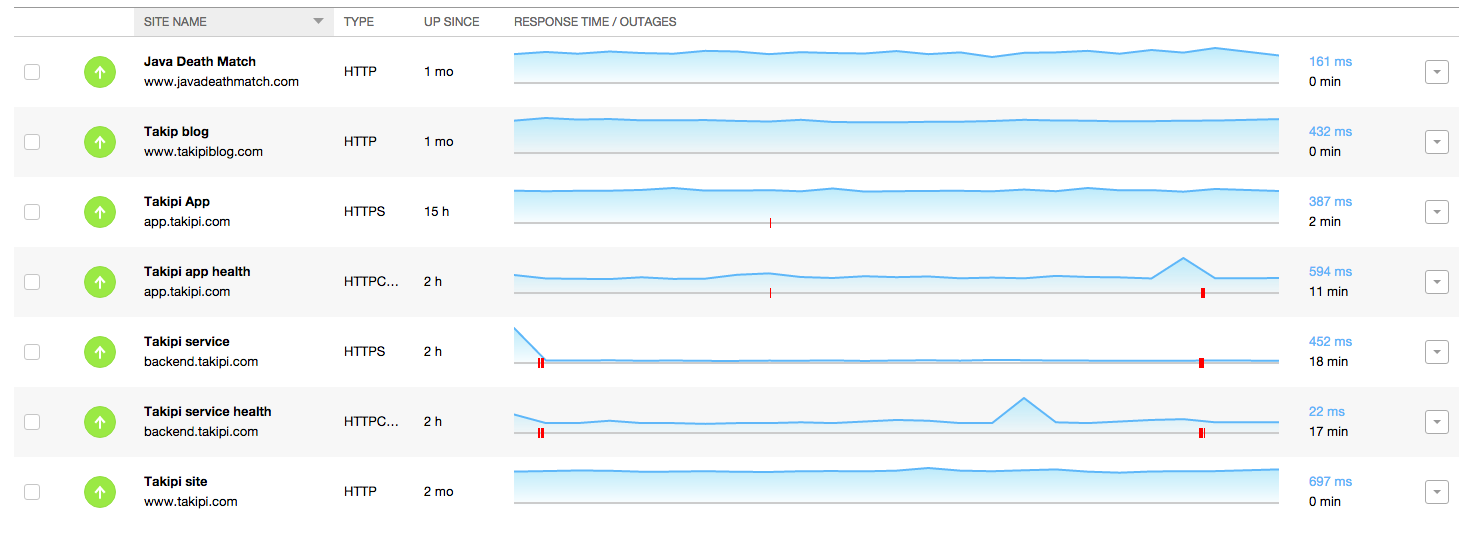
监控Pingdom中的正常运行时间和应用程序运行状况
7.日志大小
到目前为止,我们讨论的所有指标都完全跳过了日志,除了GC日志。 但是我们仍然不能完全忽略日志。 日志的副作用是它们永远不会停止增长。 如果您不注意它们的大小和控制它们的流程,那么可能会发生坏事。 当日志变松时,硬盘驱动器会哭。 您的服务器开始充满垃圾,一切都变慢了。 因此,密切关注它们很重要。 这是无休止的破坏源。
最受欢迎的解决方案是使用logstash等服务在服务器上对日志进行分区,然后使用Splunk,ELK, 其他日志管理工具或S3上的普通存储将它们发送到存储中。 另一种方法可能只是在某个时刻进行过渡或截断它们,但是由于与大多数开发人员一样,我们还没有减少对日志的依赖,因此我们冒着信息丢失的风险。
要点7:日志是一个巨大的痛苦,特别是因为如果您需要一些外部服务,则GB会向您收费,因为GBs会为您提供服务。 现在是时候重新考虑问题并开始减少日志大小了。
最后的想法
我们看到了一种趋势,即从生产中的应用程序收集数据的方式正在逐渐摆脱对日志文件的完全依赖。 软件分析的新世界更加开放,拥有更智能的数据,这些数据超越了普通数字,并拥有丰富的上下文信息。 看到一切都将是令人兴奋的,我们期待与您一起建立这个新的未来。
翻译自: https://www.javacodegeeks.com/2015/09/7-java-performance-metrics-to-watch-after-a-major-release.html














 2443
2443











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










{kind=link}