





纪事本 乱码
在这一部分中,我们着眼于将微服务作为服务的集合放在一起,并考虑如何评估这些服务的性能。 我们引入了JLBH(Java Latency Benchmark Harness)来测试这些服务。
构建服务包装器。
对于更复杂的服务,我们在编年史线程中使用EventLoop来管理多个并发任务。 在此示例中,我们只有一项任务,因此拥有一个自定义类来支持它比较简单。
此类可从ServiceWrapper获得 。
public class ServiceWrapper<I extends ServiceHandler> implements Runnable, Closeable {
private final ChronicleQueue inputQueue, outputQueue;
private final MethodReader serviceIn;
private final Object serviceOut;
private final Thread thread;
private final Pauser pauser = new LongPauser(1, 100, 500, 10_000, TimeUnit.MICROSECONDS); (1)
private volatile boolean closed = false;
public ServiceWrapper(String inputPath, String outputPath, I serviceImpl) {
Class outClass = ObjectUtils.getTypeFor(serviceImpl.getClass(), ServiceHandler.class); (2)
outputQueue = SingleChronicleQueueBuilder.binary(outputPath).build(); (3)
serviceOut = outputQueue.createAppender().methodWriter(outClass);
serviceImpl.init(serviceOut); (4)
inputQueue = SingleChronicleQueueBuilder.binary(inputPath).build();
serviceIn = inputQueue.createTailer().methodReader(serviceImpl); (5)
thread = new Thread(this, new File(inputPath).getName() + " to " + new File(outputPath).getName());
thread.setDaemon(true);
thread.start(); (6)
}
@Override
public void run() {
AffinityLock lock = AffinityLock.acquireLock(); (7)
try {
while (!closed) {
if (serviceIn.readOne()) { (8)
pauser.reset(); (9)
} else {
pauser.pause(); (9)
}
}
} finally {
lock.release();
}
}
@Override
public void close() {
closed = true;
}
@Override
public boolean isClosed() {
return closed;
}
}This Pauser controls the back off strategy in which no events are coming through. It will retry once, yield 100 times, then start sleeping from half a millisecond to 10 milliseconds. 获取ServiceHandler的参数类型,在本例中为Service 。 创建一个输出队列。 并将其传递给实现,以便它可以写入其输出队列。 为输入队列创建一个阅读器。 启动一个将从serviceIn阅读器读取的线程。 尽可能将此线程绑定到隔离的CPU。 阅读并处理一条消息。 如果出现消息,则reset()暂停器,否则调用它以获取可能的暂停。
定时我们的服务。
简单的服务可以自己计时。 这可以作为包装器实现,但是对于更复杂的服务,您可以在历史记录中使用构建,并且仅在最后检查结果。
class ServiceImpl implements Service, ServiceHandler<Service> {
private final NanoSampler nanoSampler;
private final NanoSampler endToEnd;
private Service output;
public ServiceImpl(NanoSampler nanoSampler) {
this(nanoSampler, t -> {
});
}
public ServiceImpl(NanoSampler nanoSampler, NanoSampler endToEnd) {
this.nanoSampler = nanoSampler;
this.endToEnd = endToEnd;
}
@Override
public void init(Service output) {
this.output = output;
}
@Override
public void simpleCall(SimpleData data) {
data.number *= 10; // do something.
long time = System.nanoTime();
nanoSampler.sampleNanos(time - data.ts); (1)
data.ts = time; // the start time for the next stage.
output.simpleCall(data); // pass the data to the next stage.
endToEnd.sampleNanos(System.nanoTime() - data.ts0); (2)
}
}Take the timing since the last stage
Take the timing from the start使用JLBH Java Latency Benchamrk线束
该工具基于JMH(Java Microbenchmark Harness),主要区别在于支持测试异步过程,您需要在异步过程中检查不同阶段(可能在不同主题中)的时序。
JLBHOptions jlbhOptions = new JLBHOptions()
.warmUpIterations(50_000)
.iterations(MESSAGE_COUNT)
.throughput(THROUGHPUT) (1)
.runs(6)
.recordOSJitter(true) (2)
.pauseAfterWarmupMS(500)
.accountForCoordinatedOmmission(ACCOUNT_FOR_COORDINATED_OMMISSION) (3)
.jlbhTask(new MultiThreadedMainTask());
new JLBH(jlbhOptions).start();Benchmark for a target throughput.
Add a thread to record the OS jitter over the interval.
Turn on correction for coordinated ommission.为了设置测试,我们创建了三个服务。 这将对网关进行建模,该网关接受来自外部系统(如Web服务或FIX Engine)的数据。 这由一个服务拾取,该服务将消息传递给第二个服务,最后将其写入网关服务,该网关服务可以将数据传递到外部系统。
UUID uuid = UUID.randomUUID();
String queueIn = OS.TMP + "/MultiThreadedMain/" + uuid + "/pathIn";
String queue2 = OS.TMP + "/MultiThreadedMain/" + uuid + "/stage2";
String queue3 = OS.TMP + "/MultiThreadedMain/" + uuid + "/stage3";
String queueOut = OS.TMP + "/MultiThreadedMain/" + uuid + "/pathOut";
@Override
public void init(JLBH jlbh) {
serviceIn = SingleChronicleQueueBuilder.binary(queueIn).build().createAppender().methodWriter(Service.class); (1)
service2 = new ServiceWrapper<>(queueIn, queue2, new ServiceImpl(jlbh.addProbe("Service 2"))); (2)
service3 = new ServiceWrapper<>(queue2, queue3, new ServiceImpl(jlbh.addProbe("Service 3"))); (3)
serviceOut = new ServiceWrapper<>(queue3, queueOut, new ServiceImpl(jlbh.addProbe("Service Out"), jlbh)); (4) (5)
}Just a writer
Reads that message and writes to the third service
Reads from the second service and writes to the outbound service.
The output gateway reads from the third service and writes its result to a log/queue.
The last service also sets the end to end timing.每个消息在每个阶段都将保留,并且在重新启动时可用。 由于每个输入消息都有一条输出消息,因此可以通过缠绕到与输出相同的索引来重新启动。 一种更可靠的策略是在输出中记录历史记录,如前一篇文章所述。
运行测试
运行性能测试时,有两个重要注意事项
- 您关心的百分位数是多少?
- 典型,
- 您要测试的吞吐量是多少?
控制测试的吞吐量很重要,这样才能了解系统在不同的持续吞吐量下的性能。 您的系统将在短期内尽可能快地运行,但是缓冲区和高速缓存会Swift填满,并且无法在没有较大延迟的情况下支持此速率。
看典型的表现。
在E5-2650 v2上的此测试中,此测试可达到的吞吐量为600,000条消息/秒。 但是,长时间执行此操作是不切实际的,因为系统会很快到达延迟的地步,延迟的时间越长则越长。 这是因为没有足够的空间来处理系统中的任何抖动或延迟。 随着系统努力跟上步伐,每一次延迟都会累积。 那么,此模拟系统的更实用的吞吐量是多少。
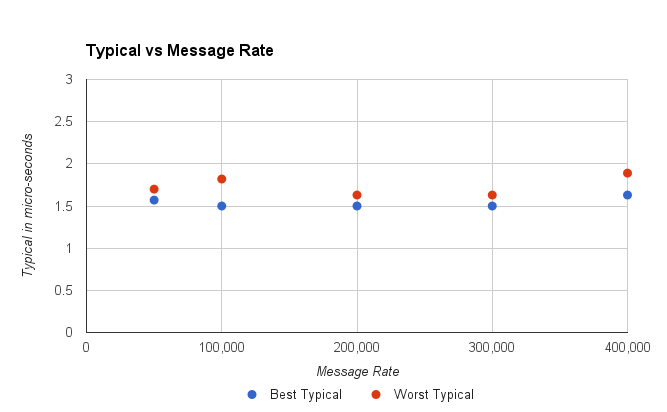
图1.最差典型值是15分钟和2分钟的最高记录。
看起来不错,对于每秒高达400,000条消息的所有吞吐量,典型的性能是一致的。 但是,对于每秒450,000条消息的吞吐量,该服务可能会遇到延迟,而该延迟将很难恢复,并且典型的延迟将跳至20 – 40秒。
简而言之,通过查看典型性能,我们可能更喜欢的吞吐量估计值已从600K / s降至400K / s
看着九头肌。
通过查看较高的百分位数(最差结果),我们可以确定哪些延迟是可以接受的,以及延迟的频率。 通常,我会考虑99%的平铺率,这是典型值的4倍,而99.9%的平铺率是典型的延迟的10倍。 这是我使用的经验法则,但是结果在系统之间有所不同。
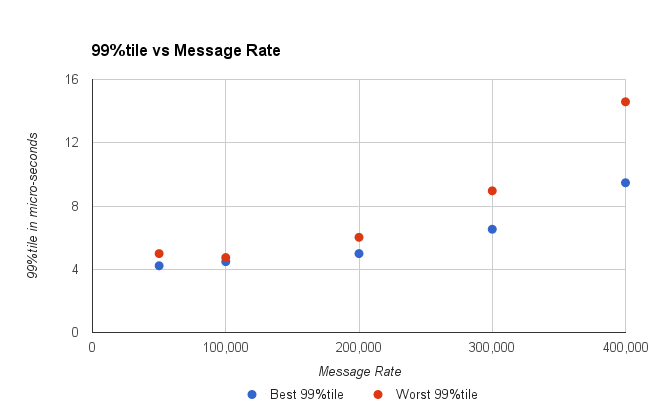
图2.随着吞吐量的增加,最差的一百分之一会变得更高。
您可能会认为99%tile应该小于10微秒,并得出结论,系统每秒可以处理300K消息。
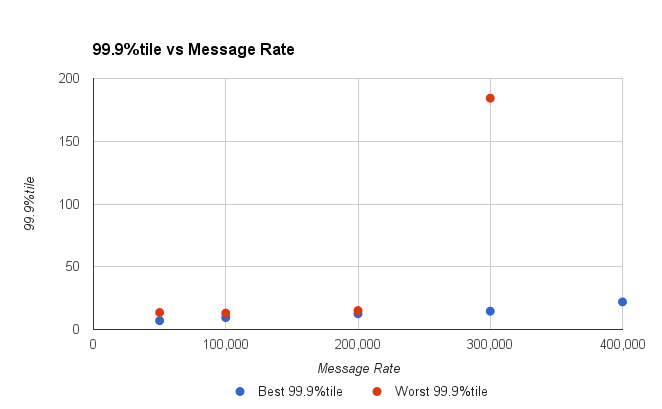
图3.随着吞吐量的增加,最差的千分之一会变得更高。
查看99.9%的平铺率,您会发现200K msg /秒以上的延迟会增加。 高达200 K / s的系统延迟非常稳定。
我们能否维持200 K msg /秒?
出现的问题是我们不想长期维持这一速度。 爆发很好,但是整天这样做会产生大量数据。 如果所有消息都记录下来,每条入站消息总计为1/2 KB,则这将产生200 MB / s的速度,而SSD可以轻松做到这一点,它将很快耗尽空间。 200 MB / s是每天9 TB。 九TB的可用高性能SSD仍然很昂贵。
假设我们希望每天记录少于2 TB。 几个大容量硬盘可以将您的所有消息保留一周。 这是每秒23 MB。 每条消息总共512字节(总),您所看到的是每秒更适度的50K消息,但根据您的要求,突发速度高达200K / s – 600K / s。
综上所述
我们有一个用于多线程异步进程的测试工具,它可以帮助您探索服务在各种吞吐量负载下的行为。 虽然您的系统可能能够在很短的时间内支持高吞吐量,但是持续吞吐量如何影响系统的延迟。
翻译自: https://www.javacodegeeks.com/2017/03/microservices-chronicle-world-part-5.html
纪事本 乱码















 88
88

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









