





hadoopde mapr
我们已经在运行Spark 1.5.2的5节点MapR 5.1集群上对CaffeOnSpark进行了试验,并将在此博客文章中分享我们的经验,困难和解决方案。
深度学习和Caffe
深度学习近来受到了广泛关注,AlphaGo在一款被认为非常复杂以至于仅仅在五年前就已经无法使用计算机的游戏中击败了世界顶级玩家。 深度学习不仅在Go上击败了人类,而且几乎在所有Atari电脑游戏中都击败了人类。
但是事实是,深度学习对于图像分类和语音识别 , AI聊天机器人和机器翻译等领域中具有清晰企业应用程序的任务也很有用。
Caffe是最初由伯克利视觉与学习中心(BVLC)开发的C ++ / CUDA深度学习框架。 对于与图像有关的应用程序,它尤其受到好评。 Caffe可以利用支持CUDA的GPU(例如任何NVIDIA消费类GPU)的功能,这意味着任何拥有游戏PC的人都可以自己运行最先进的深度学习。 凉!
而且,Caffe模型通常是公开可用的。 因此,我们可以自己尝试由该领域的领先研究人员在庞大的数据集上训练的绝对最新模型。 例如,可以在此处获得Microsoft的2015年获奖图像分类器。
这个开源项目可以在GitHub上找到,并且有一个主页,其中包含使它在Linux和MacOS X上运行的所有必要说明,甚至还有Windows发行版 。
CaffeOnSpark
Caffe和大多数消费者级别的深度学习的主要问题是它们只能在一台计算机上工作,而该计算机最多只能使用四个GPU。 对于真正的企业应用程序,数据集可以轻松扩展至数百GB的数据,即使在最快的单节点硬件上也需要数天的计算时间。
Google,百度和微软拥有构建专用的深度学习集群的资源,这些集群为深度学习算法提供了一定程度的处理能力,既可以加快训练时间,又可以提高模型的准确性。 此类计算怪物集群已成为通过深度学习模型达到最佳, 人为 (或更好 )性能的必要条件。
但是,雅虎采用了略有不同的方法,即脱离了专用的深度学习集群,并将Caffe与Spark结合在一起。 ML大数据团队的CaffeOnSpark软件使他们能够运行构建深度学习模型并将其部署到单个集群上的整个过程。 该软件已于去年下半年以开源形式发布,现已在GitHub上提供 。
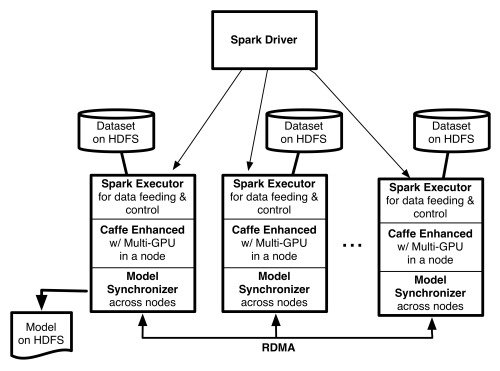
在MapR上运行CaffeOnSpark
我们的集群在部署在AWS EC2实例上的5个节点上运行MapR 5.1。 每个节点都是一个m4.4xlarge实例,具有12个vcore和30GB内存。 选择的操作系统是Ubuntu 14.04。 Spark的版本是MapR提供的版本1.5.2,对其进行了略微修改以适应MapR高性能C本地文件系统而不是HDFS。
首先,我们在一个节点上安装了Caffe,以确保自己的设置确实与Caffe兼容。 他们的Github上的Wiki页面是非常宝贵的说明手册,允许进行相当简单的安装。 我们的实例没有GPU,但是未安装CUDA会在安装CaffeOnSpark时导致编译错误,因此我们建议无论如何都要安装驱动程序。 我们安装了CUDA 7.5版本,这是撰写本文时的最新版本。 所有步骤均按原样进行。 无需安装PyCaffe,但这是确保安装真正完美的好方法。
我们运行了编译,运行了测试,还运行了示例MNIST数字任务。
对于该示例,从Caffe文件夹中,运行data / mnist / get_mnisn.sh,然后运行examples / mnist / create_mnist.sh,最后运行example / mnist / train_lenet.sh。
您可以通过运行make pycaffe来测试pycaffe的安装,然后转到Caffe / python文件夹并打开Python shell并键入。 import caffe如果一切都可以导入,尽管有一些Matplotlib警告,但是安装是完美的。
确认Caffe安装正确之后,我们得到了CaffeOnSpark,并按照GitHub Wiki页面上的说明进行了仔细地编译。 注意:在开始编译之前,请确保还安装了maven和zip(sudo apt-get install zip maven -y),这是必需的! 值得庆幸的是,如果您没有它们并且仍然开始编译,那么就很容易理解该错误,并且安装丢失的位并重新启动编译也会导致正确的安装。
将CaffeOnSpark文件夹复制到所有节点。 这是必不可少的! 文件夹位置在任何地方都必须相同。 我们以root用户身份运行所有内容,但这可能不是必需的。
说明中提到:
export LD_LIBRARY_PATH=${CAFFE_ON_SPARK}/caffe-public/distribute/lib:${CAFFE_ON_SPARK}/caffe-distri/distribute/lib
export LD_LIBRARY_PATH=${LD_LIBRARY_PATH}:/usr/local/cuda-7.0/lib64:/usr/local/mkl/lib/intel64/显然,我们需要将cuda-7.0更新为cuda-7.5,并且由于我们不使用它而将其删除到英特尔MKL中。 我们将此添加到.bashrc文件中。
export LD_LIBRARY_PATH=${CAFFE_ON_SPARK}/caffe-public/distribute/lib:${CAFFE_ON_SPARK}/caffe-distri/distribute/lib:/usr/local/cuda-7.5/lib64实际上,我们还添加了.bashrc:
export JAVA_HOME=/usr/lib/jvm/java-7-oracle/
export CUDA_HOME=/usr/local/cuda-7.5
export CAFFE_HOME=/root/caffe
export CAFFE_ON_SPARK=/root/CaffeOnSpark
export SPARK_HOME=/opt/mapr/spark/spark-1.5.2
export LD_LIBRARY_PATH=${CAFFE_ON_SPARK}/caffe-public/distribute/lib:${CAFFE_ON_SPARK}/caffe-distri/distribute/libexport LD_LIBRARY_PATH=${LD_LIBRARY_PATH}:/usr/local/cuda-7.5/lib64运行CaffeOnSpark
独立模式
首先,我们按照GitHub上的说明,以独立模式在MNIST示例上运行CaffeOnSpark。
一次成功的比赛鼓励我们尝试在YARN上进行尝试。
YARN群集模式
我们为YARN运行了说明,并可能很快使它工作,但要注意的是,每个工人仅使用一个vcore。
CaffeOnSpark的工作方式是使用集群工作者并行训练Caffe模型,然后使用REDUCE收集回模型。 对模型进行平均,然后将新任务发送给具有更新参数的工作人员。
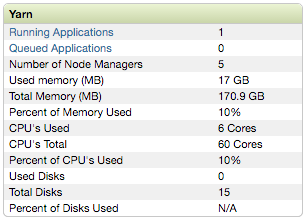
使用CaffeOnSpark指令建议的命令行参数,只有5个执行程序,每个执行程序都有1个vcore,加上1个vcore用于驱动程序,这极大地利用了群集的CPU功能。 实际上,每次Caffe迭代大约需要18秒。
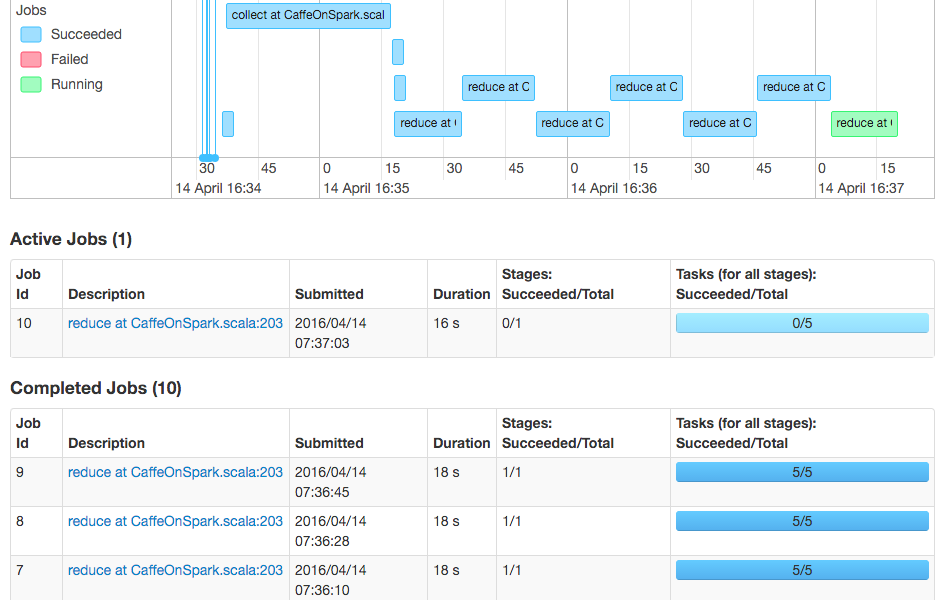
处理异常和性能调整
尝试使用–num-executors参数时,我们有随机错误; 由于找不到正确数目的执行程序,因此CaffeOnSpark将引发异常。 如果将-num-executors设置为5(与工作人员的数量相同),有时我们可以使它工作,但有时也会引发异常。
使用以下参数解决了此问题:
--conf spark.scheduler.minRegisteredResourcesWaitingTime=30
--conf spark.scheduler.minRegisteredResourcesRatio=1.0群集模式下的YARN将驱动程序提交为容器,并且在驱动程序开始执行时,所有工作执行程序可能尚未就绪且不可用,因此,当CaffeOnSpark检查正确数量的执行程序时,它会发现意外的计数并抛出一个例外。 通过提供更多时间并要求所有注册的资源都可用,可以修复此错误。
修复该错误后,我们可以使用以下参数增加内核数:
--num-executors X
--executor-cores YX是执行者的数量,Y是每个执行者的核心数量。 X * Y应该比YARN可用的vcore总数低一些。 在我们的案例中,共有60个vcore,因此我们使用了X和Y的各种组合,发现X = 25和Y = 2在8s时产生了最快的迭代,而X = 50和Y = 1使CPU的CPU最大化。集群,但迭代时间稍长一些,大约为9s。
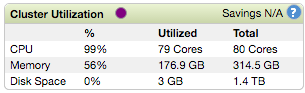
我们知道,在深度学习中,更多的计算能力对于更高的准确性和更快的培训时间都是有益的。 因此,我们认为随着执行程序数量的增加,最终模型的准确性会更好,但是考虑到我们的硬件和软件以及CaffeOnSpark的体系结构,训练时间最多只能将每次迭代限制在8 s之内。
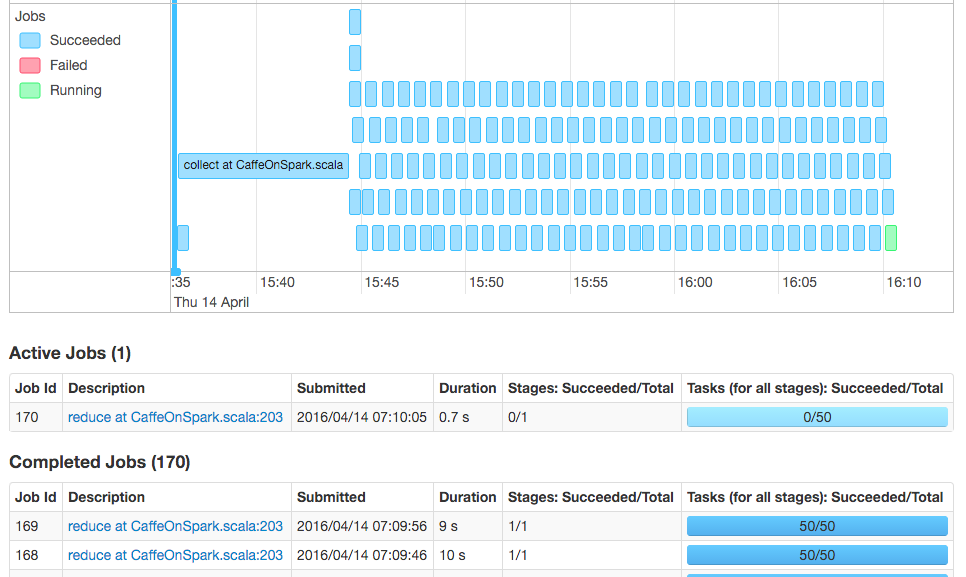
任务不受内存限制,集群使用的总内存不会超过60%。 IO瓶颈也不太可能出现,因为MNIST数据集是如此之小,火车集只有60MB,测试集只有10MB。 最后,从Spark Web UI查看DAG表明,CPU占每个地图任务花费的时间的95%以上,因此该数据集的网络或分发效率低下也可能不是瓶颈。
我们注意到的另一件事是,收敛之前的迭代次数与执行者的数量有关。 很难得出任何结论,因为此时MNIST任务被认为非常容易。 在真实的数据集上获取准确性和损失指标将对此处的实际情况具有指导意义。
结论
MapR Spark实现是运行CaffeOnSpark的完美目标。 作为后续项目,值得使用具有GPU的EC2实例在群集上再次进行测试,并观察性能差异。
首先,雅虎之所以开发CaffeOnSpark,是因为将其深度学习操作整合到一个集群中是很有意义的。 MapR融合数据平台是该项目的理想平台,可为您提供具有企业级鲁棒性的群集上分布式Caffe的所有功能,使您能够利用MapR高性能文件系统。
翻译自: https://www.javacodegeeks.com/2016/04/distributed-deep-learning-caffe-using-mapr-cluster.html
hadoopde mapr














 987
987











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









