









近来在了解卷积神经网络(CNN),后来查到CNN是受语音信号处理中时延神经网络(TDNN)影响而发明的。本篇的大部分内容都来自关于TDNN原始文献【1】的理解和整理。该文写与1989年,在识别"B", "D", "G"三个浊音中得到98.5%的准确率,高于HMM的93.7%。是CNN的先驱。
普通神经网络识别音素
在讲TDNN之前先说说一般的神经网络的是怎样识别音素的吧。假设要识别三个辅音"B", "D", "G",那么我们可以设计这样的神经网络:
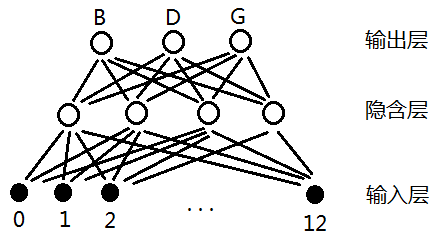
图1
其中输入0-12代表每一帧的特征向量(如13维MFCC特征)。那么有人可能会问了,即使在同一个因素"B"中,比如"B"包含20帧,那么第1帧与第15帧的MFCC特征也可能不一样。这个模型合理吗?事实上,"B"包含的20帧MFCC特征虽然有可能不一样,但变化不会太大,对于因素还是有一定区分度的,也就是说这个模型凑合凑合还能用,但效果不会非常好。GMM模型可以用这种模型来解释。
时延神经网络(TDNN)
考虑到上述模型只用了一帧特征,那么如果我们考虑更多帧,那么效果会不会好呢?
好,那么我们设计一个包含多帧的神经网络,如图2我们考虑延时为2,则连续的3帧都会被考虑。其中隐含层起到特征抽取的作用,输入层每一个矩形内共有13个小黑点,代表该帧的13维MFCC特征。假设有10个隐含层,那么连接的权重数目为3*13*10=390。
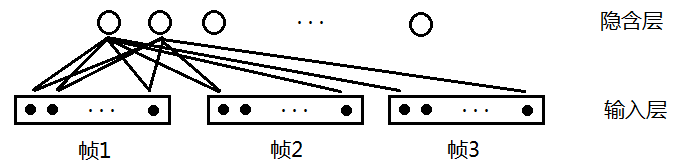
图2
为了结构紧凑显示,我们将其重绘为图3
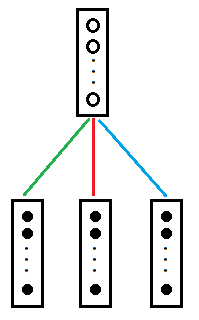
图3
图3与图2是等价的。其中每条彩色线代表13*10=130个权重值。三条彩色线为390个权重。也有资料称之为滤波器。
好,如果时间滚滚向前,我们不断地对语音帧使用滤波器,我们可以得到图4
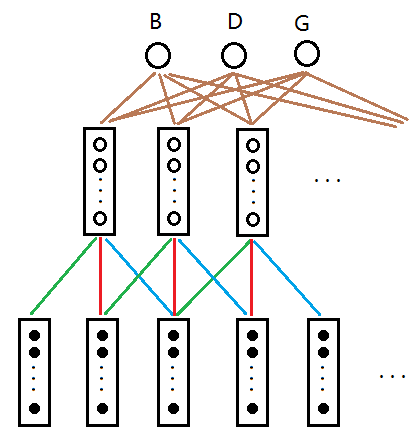
图4
这就是延时神经网络的精髓了!其中绿色的线权值相同,红色的线权值相同,蓝色的线权值相同。相当于把滤波器延时。输入与隐层共390个权值变量待确定。
每个隐层矩形内包含10个节点,那么每条棕色的线包含10个权值,假设输出层与隐层的延时为4,则接收5个隐层矩形内的数据,那么隐层与输出层合计权值为10*5*3=150。权值非常少!所以便于训练。
下面就不难理解文献【1】上的图了。思想与上文一样,不过文章多用了一层隐层(多隐层有更强的特征提取和抽象能力)
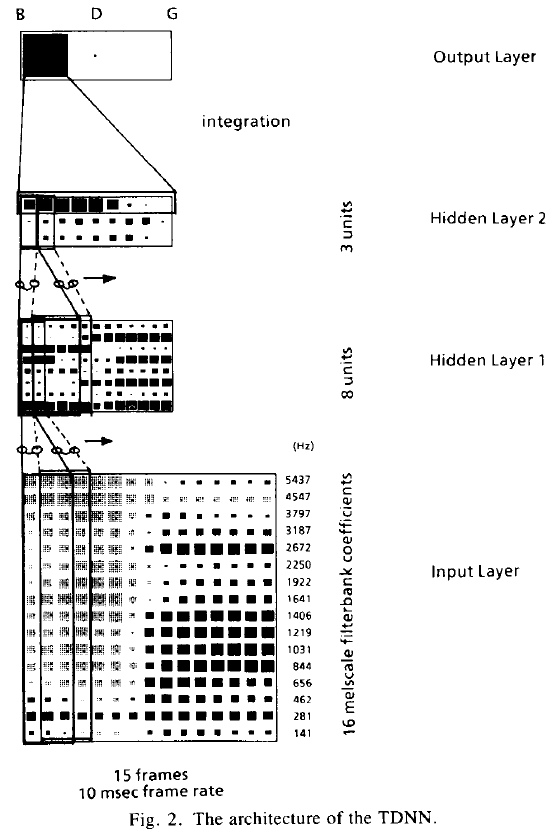
图5
介绍一下他的做法。Input Layer为语谱图,黑块为大值,灰块为小值。输入层纵向为经过mel滤波器的16个特征(没用MFCC),横向为帧。Input Layer 的延时为2,映射到Hidden Layer 1的关系为16*3 -> 8,权值个数为384。Hidden Layer 1 的延时为4,映射到Hidden Layer 2的关系为8*5 -> 3,权值个数为120。Hidden Layer 2 的延时为8,映射到输出层的关系为3*9 -> 3,权值个数为81。合计权值为384+120+81=585。输出的三个单元分别代表"B", "D", "G"的得分。
训练方法
(1)和传统的反向传播算法一样。
(2)TDNN有快速算法,有兴趣的读者可以搜索。
小结
总结TDNN的优点有以下:
(1)网络是多层的,每层对特征有较强的抽象能力。
(2)有能力表达语音特征在时间上的关系。
(3)具有时间不变性。
(4)学习过程中不要求对所学的标记进行精确的时间定为。
(5)通过共享权值,方便学习。
转载来源:http://blog.csdn.net/richard2357/article/details/16896837















 6078
6078

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









