






Windows上Eclipse安装Hadoop插件
在Windows上安装eclipse插件的安装,连接远程centos上的Hadoop环境并进行wordcount测试。Hadoop版本2.8.4。
1.下载Hadoop插件hadoop2x-eclipse-plugin-master
下载地址:https://github.com/winghc/hadoop2x-eclipse-plugin,下载完成后解压,将release/hadoop-eclipse-plugin-2.6.0.jar文件复制到eclipse下的plugins目录下,启动eclipse。
2. 本地配置Hadoop环境
(1)下载Hadoop软件包hadoop-2.8.4.tar.gz,解压并配置环境变量,为了防止出错,我本机的Hadoop和远程centos上的Hadoop版本和配置都是一样的。
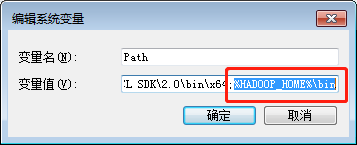
(2)本地环境变量配置如下图:

HADOOP_HOME=H:\Hadoop\hadoop-2.8.4,将HADOOP_HOME放到path变量中,
3.启动eclipse
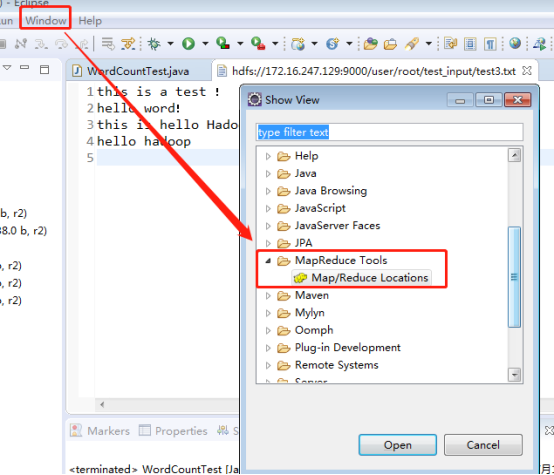
(1)打开Window->show view ,如下图,打开MapReduce tools
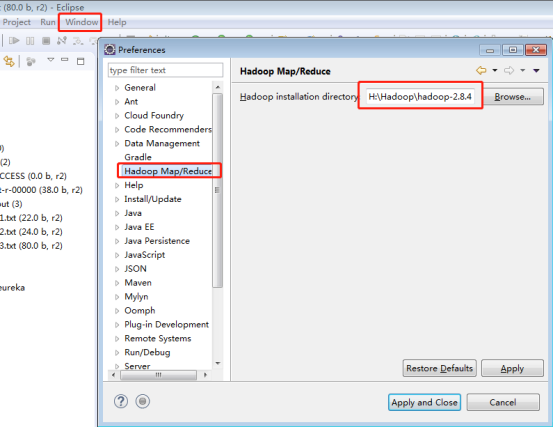
(2)选择本地Hadoop目录
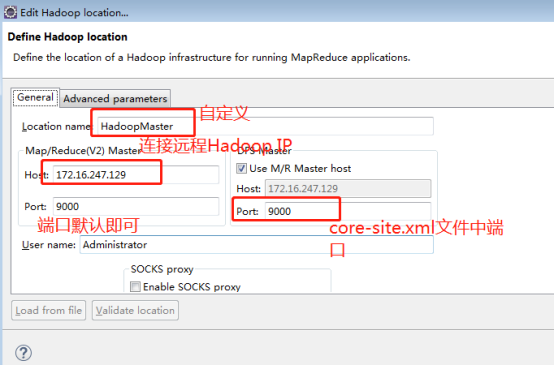
(3)配置Hadoop location
配置完成后出现DFS Locations
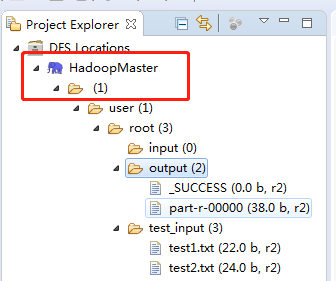
Output和test_input下的文件是我在远程服务器上,通过命令执行的结果,此时刷新后下载下来的。
4.编写程序
(1)新建MapReduce工程hadoop01
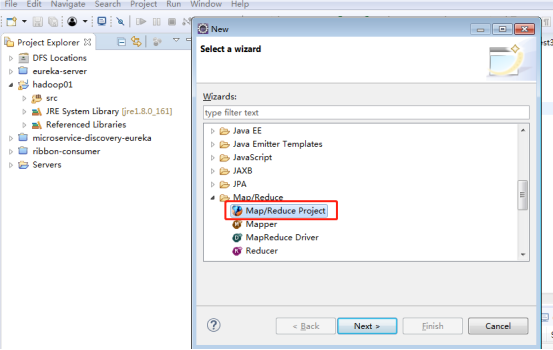
(2)新建WordCount测试类
程序功能:统计指定文件内单词出现的次数。
package com.hadoop.test; import java.io.IOException; import java.util.StringTokenizer; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.Mapper; import org.apache.hadoop.mapreduce.Reducer; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.input.TextInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat; public class WordCountTest { public static class WordCountMap extends Mapper<LongWritable, Text, Text, IntWritable> { private final IntWritable one = new IntWritable(1); private Text word = new Text(); public void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException { String line = value.toString(); StringTokenizer token = new StringTokenizer(line); while (token.hasMoreTokens()) { word.set(token.nextToken()); context.write(word, one); } } } public static class WordCountReduce extends Reducer<Text, IntWritable, Text, IntWritable> { public void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException { int sum = 0; for (IntWritable val : values) { sum += val.get(); } context.write(key, new IntWritable(sum)); } } @SuppressWarnings("deprecation") public static void main(String[] args) throws Exception{ Configuration conf = new Configuration(); Job job = new Job(conf); job.setJarByClass(WordCountTest.class); job.setJobName("wordcount"); job.setOutputKeyClass(Text.class); job.setOutputValueClass(IntWritable.class); job.setMapperClass(WordCountMap.class); job.setReducerClass(WordCountReduce.class); job.setInputFormatClass(TextInputFormat.class); job.setOutputFormatClass(TextOutputFormat.class); FileInputFormat.addInputPath(job, new Path("hdfs://172.16.247.129:9000/user/root/test_input")); FileOutputFormat.setOutputPath(job, new Path("hdfs://172.16.247.129:9000/user/root/output/result")); job.waitForCompletion(true); } }
(3)在DFS Locations test_input下新建测试文件test3.txt,如果存在权限问题参考5
(4)运行 Run as -->Run on Hadoop
5.遇到的问题
在编写程序过程中会有问题出现,在此简单总结一下:
(1)错误信息:
| log4j:WARN See http://logging.apache.org/log4j/1.2/faq.html#noconfig for more info. Exception in thread "main" java.lang.RuntimeException: java.io.FileNotFoundException: Could not locate Hadoop executable: H:\Hadoop\hadoop-2.8.4\bin\winutils.exe -see https://wiki.apache.org/hadoop/WindowsProblems at org.apache.hadoop.util.Shell.getWinUtilsPath(Shell.java:716) at org.apache.hadoop.util.Shell.getSetPermissionCommand(Shell.java:250) at org.apache.hadoop.util.Shell.getSetPermissionCommand(Shell.java:267) at org.apache.hadoop.fs.RawLocalFileSystem.setPermission(RawLocalFileSystem.java:771) at org.apache.hadoop.fs.RawLocalFileSystem.mkOneDirWithMode(RawLocalFileSystem.java:515) at org.apache.hadoop.fs.RawLocalFileSystem.mkdirsWithOptionalPermission(RawLocalFileSystem.java:555) at org.apache.hadoop.fs.RawLocalFileSystem.mkdirs(RawLocalFileSystem.java:533) at org.apache.hadoop.fs.FilterFileSystem.mkdirs(FilterFileSystem.java:320) at org.apache.hadoop.mapreduce.JobSubmissionFiles.getStagingDir(JobSubmissionFiles.java:133) at org.apache.hadoop.mapreduce.JobSubmitter.submitJobInternal(JobSubmitter.java:146) at org.apache.hadoop.mapreduce.Job$11.run(Job.java:1341) at org.apache.hadoop.mapreduce.Job$11.run(Job.java:1338) at java.security.AccessController.doPrivileged(Native Method) at javax.security.auth.Subject.doAs(Subject.java:422) at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1840) at org.apache.hadoop.mapreduce.Job.submit(Job.java:1338) at org.apache.hadoop.mapreduce.Job.waitForCompletion(Job.java:1359) at com.hadoop.test.WordCountTest.main(WordCountTest.java:59) Caused by: java.io.FileNotFoundException: Could not locate Hadoop executable: H:\Hadoop\hadoop-2.8.4\bin\winutils.exe -see https://wiki.apache.org/hadoop/WindowsProblems at org.apache.hadoop.util.Shell.getQualifiedBinInner(Shell.java:598) at org.apache.hadoop.util.Shell.getQualifiedBin(Shell.java:572) at org.apache.hadoop.util.Shell.<clinit>(Shell.java:669) at org.apache.hadoop.util.StringUtils.<clinit>(StringUtils.java:79) at org.apache.hadoop.conf.Configuration.getBoolean(Configuration.java:1555) at org.apache.hadoop.security.SecurityUtil.getLogSlowLookupsEnabled(SecurityUtil.java:497) at org.apache.hadoop.security.SecurityUtil.<clinit>(SecurityUtil.java:90) at org.apache.hadoop.security.UserGroupInformation.initialize(UserGroupInformation.java:289) at org.apache.hadoop.security.UserGroupInformation.ensureInitialized(UserGroupInformation.java:277) at org.apache.hadoop.security.UserGroupInformation.loginUserFromSubject(UserGroupInformation.java:833) at org.apache.hadoop.security.UserGroupInformation.getLoginUser(UserGroupInformation.java:803) at org.apache.hadoop.security.UserGroupInformation.getCurrentUser(UserGroupInformation.java:676) at org.apache.hadoop.mapreduce.task.JobContextImpl.<init>(JobContextImpl.java:72) at org.apache.hadoop.mapreduce.Job.<init>(Job.java:142) at org.apache.hadoop.mapreduce.Job.<init>(Job.java:129) at com.hadoop.test.WordCountTest.main(WordCountTest.java:48) |
winutils.exe是在Windows系统上需要的hadoop调试环境工具,里面包含一些在Windows系统下调试hadoop、spark所需要的基本的工具类,另外在使用eclipse调试hadoop程序是,也需要winutils.exe。
解决方案:
下载工具:https://github.com/steveloughran/winutils
解压winutils-master文件,选择版本,将H:\Hadoop\winutils-master\hadoop-2.8.3\bin下的
winutils.exe和hadoop.dll分别复制到本地Hadoop安装目录下H:\Hadoop\hadoop-2.8.4\bin和C:\Windows\System32下
(2)
| Exception in thread "main" java.lang.UnsatisfiedLinkError: org.apache.hadoop.io.nativeio.NativeIO$Windows.access0(Ljava/lang/String;I)Z at org.apache.hadoop.io.nativeio.NativeIO$Windows.access0(Native Method) at org.apache.hadoop.io.nativeio.NativeIO$Windows.access(NativeIO.java:606) at org.apache.hadoop.fs.FileUtil.canRead(FileUtil.java:958) at org.apache.hadoop.util.DiskChecker.checkAccessByFileMethods(DiskChecker.java:100) at org.apache.hadoop.util.DiskChecker.checkDir(DiskChecker.java:65) at org.apache.hadoop.fs.LocalDirAllocator$AllocatorPerContext.confChanged(LocalDirAllocator.java:314) at org.apache.hadoop.fs.LocalDirAllocator$AllocatorPerContext.getLocalPathForWrite(LocalDirAllocator.java:377) at org.apache.hadoop.fs.LocalDirAllocator.getLocalPathForWrite(LocalDirAllocator.java:151) at org.apache.hadoop.fs.LocalDirAllocator.getLocalPathForWrite(LocalDirAllocator.java:132) at org.apache.hadoop.fs.LocalDirAllocator.getLocalPathForWrite(LocalDirAllocator.java:116) at org.apache.hadoop.mapred.LocalDistributedCacheManager.setup(LocalDistributedCacheManager.java:125) at org.apache.hadoop.mapred.LocalJobRunner$Job.<init>(LocalJobRunner.java:171) at org.apache.hadoop.mapred.LocalJobRunner.submitJob(LocalJobRunner.java:758) at org.apache.hadoop.mapreduce.JobSubmitter.submitJobInternal(JobSubmitter.java:242) at org.apache.hadoop.mapreduce.Job$11.run(Job.java:1341) at org.apache.hadoop.mapreduce.Job$11.run(Job.java:1338) at java.security.AccessController.doPrivileged(Native Method) at javax.security.auth.Subject.doAs(Subject.java:422) at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1840) at org.apache.hadoop.mapreduce.Job.submit(Job.java:1338) at org.apache.hadoop.mapreduce.Job.waitForCompletion(Job.java:1359) at com.hadoop.test.WordCountTest.main(WordCountTest.java:59) |
解决方案:
下载Hadoop源码并解压,找到NativeIO.java,
hadoop-2.8.4-src\hadoop-2.8.4-src\hadoop-common-project\hadoop-common\src\main\java\org\apache\hadoop\io\nativeio\NativeIO.java将其复制到工程hadoop01的src下并做如下修改:
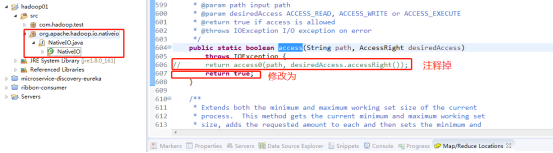
(3)涉及到权限的问题
如果涉及到文件的权限问题,例Permission denied: user=root, access=WRITE
解决方案1:修改服务器上hadoop-2.8.4/etc/hadoop/hdfs-site.xml
添加如下:
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>
解决方案2:
修改权限:sudo -u hdfs hadoop fs -mkdir /user/root (未测)
6.测试
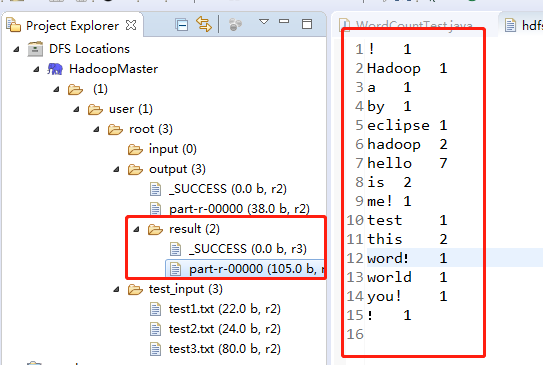
新建test3.txt并上传,test_input右键单击upload files to DFS...,选择上传的文件test3.txt,
上传后我的test_input下有三个文件,test1和test2是我之前测试的文件
运行 Run as -->Run on Hadoop,
运行完成后,刷新DFS Locations,结果统计的是test_input下的三个文件















 2187
2187











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









