







Kibana
一个开源的分析和可视化平台,用于与elasticsearch一起使用;可以搜索,查看并和存储在elasticsearch索引中的数据进行交互;可以轻松地执行高级数据分析,并且以各种图标、表格和地图的形式可视化数据。Kibana使得理解大量数据变得很容易,它简单的、基于浏览器的界面可以快速创建和共享动态仪表板,实时显示elasticsearch查询的变化。
下载地址
https://www.elastic.co/cn/downloads/past-releases/kibana-6-4-2
这里我们下载的版本跟elasticsearch的版本是对应的。
下载后复制到linux服务器
1.解压
2.修改配置文件
vi kibana-6.4.2-linux-x86_64/config/kibana.yml
将下列注释掉的配置去掉注释并修改
server.port: 5601
server.host: "1192.168.45.128"
elasticsearch.url: "http://192.168.45.128:9200"
3.启动
启动kibana跟elasticsearch一样,是不能用root的,这里我们可以给上篇博客中创建的ela角色赋予权限,然后切换成ela角色启动kibana。
- chown -R ela kibana-6.4.2-linux-x86_64
- su ela
- ./kibana-6.4.2-linux-x86_64/bin/kibana
打开浏览器访问http://192.168.45.128:5601/app/kibana
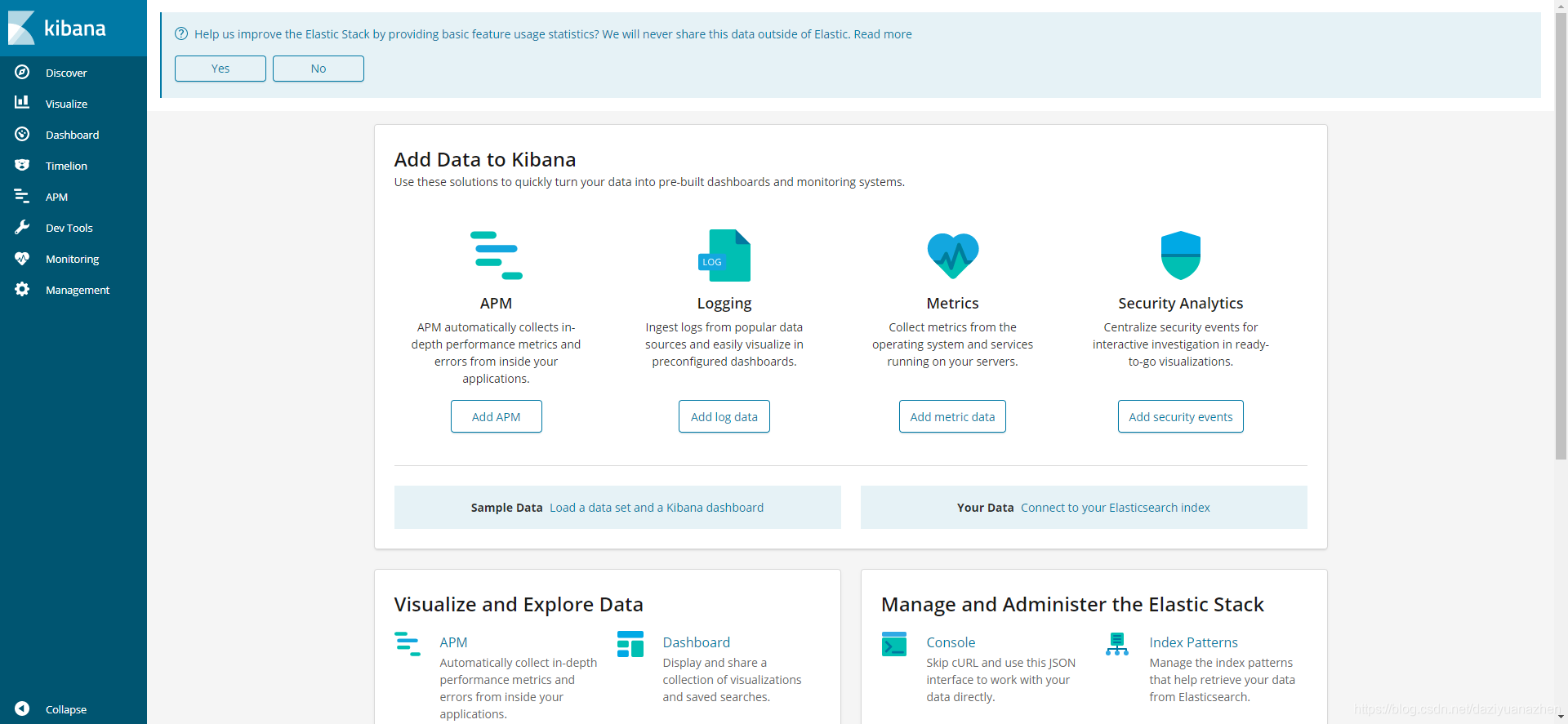
点击左侧菜单栏中的Dev Tools菜单,进入开发工具页面
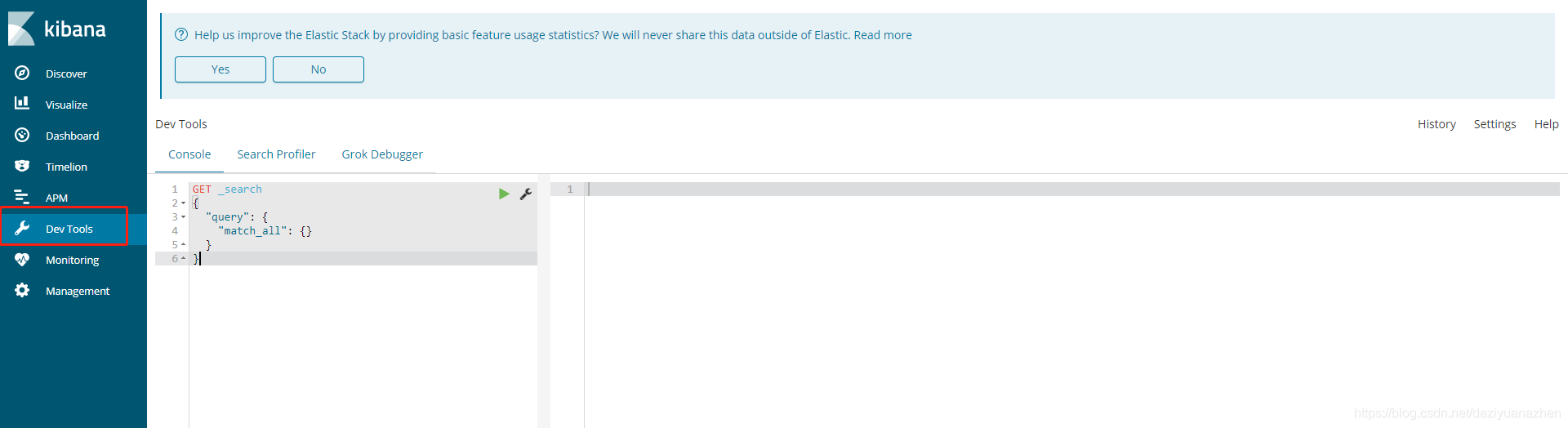
在这里可以对elasticsearch进行增删改查。
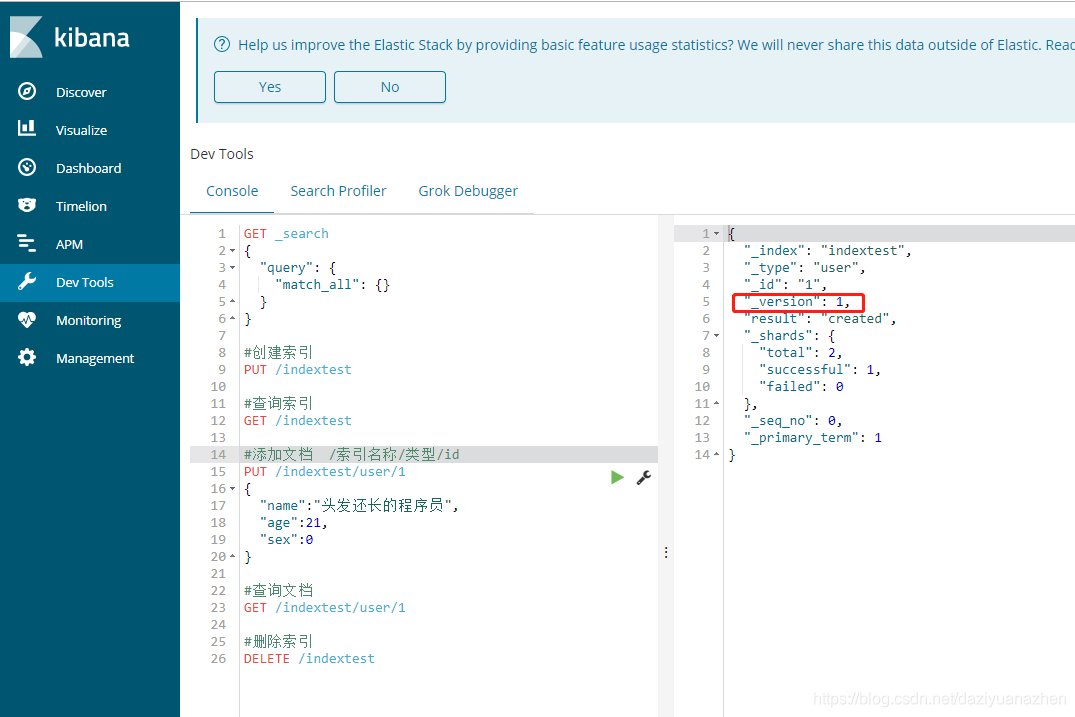
添加文档语句执行后可以发现返回的结果中有一个version字段,多执行几次添加文档语句,会发现version字段一直累加;这个字段是用于版本控制。
版本控制是为了保证数据在多线程操作下的准确性。
采用了乐观锁的概念:假设不会发生冲突,只在提交操作时检查是否违反数据完整性,即查询当前version值是不是最新的。
PUT /indextest/user/1?version=2
{
"name":"头发还长的程序员",
"age":21,
"sex":0
}
通过在语句中携带version参数,执行时会检查当前的version值是否一致;当es存储的数据version是2的时候,语句执行成功,否则语句执行失败。
高级查询

DSL语言查询与过滤
es中的查询请求有两种方式,一种是简易版查询,另外一种是使用json请求体,叫做结构化查询(DSL)。
DSL查询是POST请求,由于POST请求是json格式的,所以很灵活,也有很多形式,更直观,所以大都使用这种方式。
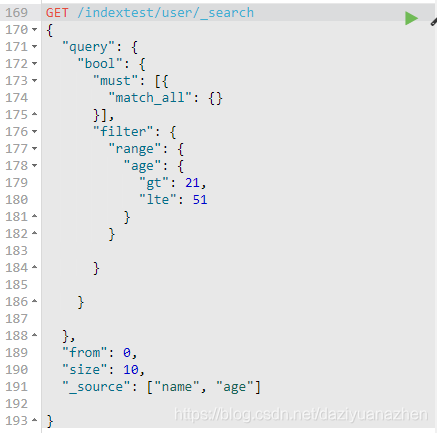

其中term被称为词条查询。
查询时分两种情况,一种是字段采用了分词,一种是字段没有采用分词,分词这个概念下边会讲到,简单的说就是将字段数据进行拆分。
1.当字段采用了分词时,词条查询只能支持小写的单个词条,否则匹配不到任何文档。
在es默认的分词器中,中文会按单个字分,例如头发还长的程序员,就会被分成头,发,还,长,的,程,序,员。那么在词条查询中,我们可以用这八个字中的其中一个查询到文档,其它诸如头发、程序员之类的关键词都查询不到。
如果是英文的话,默认分词器会按照名词等常见词分,例如
Quick Foxes, 那么会分成 quick,foxes,是小写的,那么词条查询时,可以用quick或foxes查询到文档,否则查询不到。2.当字段没有采用分词时,词条查询只能支持全部匹配,即查询字符串完全匹配的文档。
例如字段name没有使用分词器,那么只有用"头发还长的程序员"才能查询到文档。
而match则被称为全文查询,也是匹配查询
不同于词条查询,匹配查询会对查询字符串进行分词,然后再进行查询,只要文档中包含了其中一个分词出来的词条,就会被查询出来。例如查询字符串是“Microsoft Azure Party”,那么会分词成microsoft,azure,party;当文档中包含了这三个词条的其中一个时,就会被查询到。
es的索引概念
es使用的索引是倒排索引。
一般类似mysql等数据库用的都是正向索引,以ID为关键字,表中记录每个字段的位置信息,当查询没有使用到索引时,
查找时扫描表中的每条数据字段信息直到找出包含查询关键字的数据。结构简单,建立方便且易于维护,但是检索效率低。
而倒排索引以字或词为关键字进行索引,表中关键字所对应的记录表项记录了出现这个字或词的所有文档,一个表项就是一个字表段,记录该文档的id和字符在该文档中出现的位置情况。
由于每个字或词对应的文档数量在动态变化,所以倒排表的建立和维护较为复杂,但是在查询的时候可以一次得到查询关键字所对应的所有文档,所以虽然索引建立效率相对低一些,但是查询效率高于正排表。
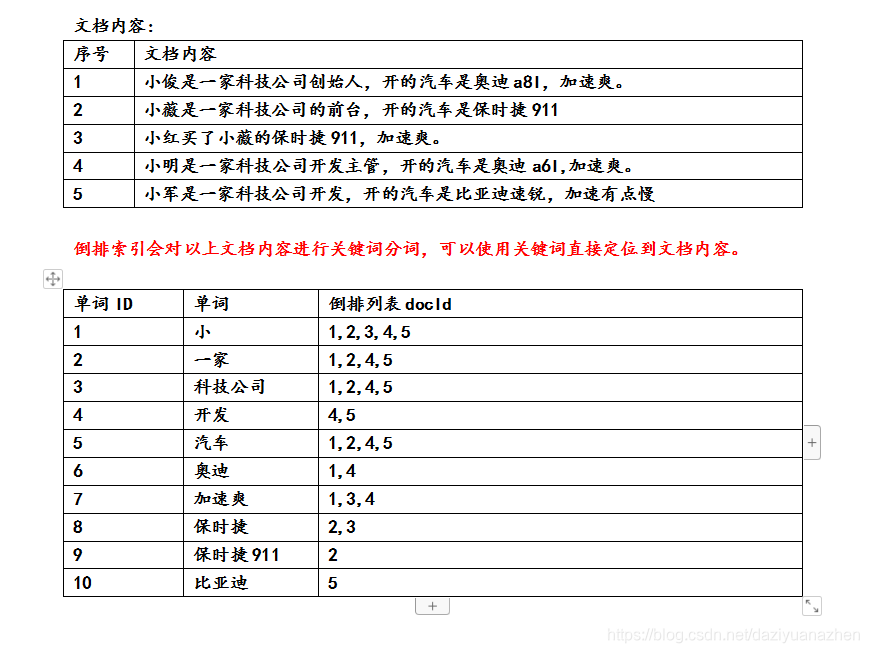
简单来说,正向索引是记录文档(查询时已知文档,要查关键字),而倒排索引是记录关键字(已知关键字,要查文档)。
分词器
对数据进行拆分,一般用常用的词语来进行拆分,利于我们进行查询,在默认的分词器中,由于是外国人写的,所以只对英语进行了常用词的拆分,例如Quick Foxes, 那么会分成 quick,foxes,利于查询;而中文的话是不支持常用词来拆分的,会按单个汉字的形式进行拆分,例如头发还长的程序员,那么会分成头,发,还,长,的,程,序,员;但是我们查询的时候经常使用的可能是头发还有程序员这两个词,所以这样子分词不利于我们查询。
所以我们要引入中文分词器ik插件
下载地址:需要下载跟es同版本的
https://github.com/medcl/elasticsearch-analysis-ik/releases
下载zip格式的,然后用unzip语句解压到elasticsearch的plugins目录
unzip elasticsearch-analysis-ik-6.4.2.zip -d /elasticsearch-6.4.2/plugins/ik
重启es之后就可以了,可以在打印的日志中看到带有ik的信息
测试中文分词
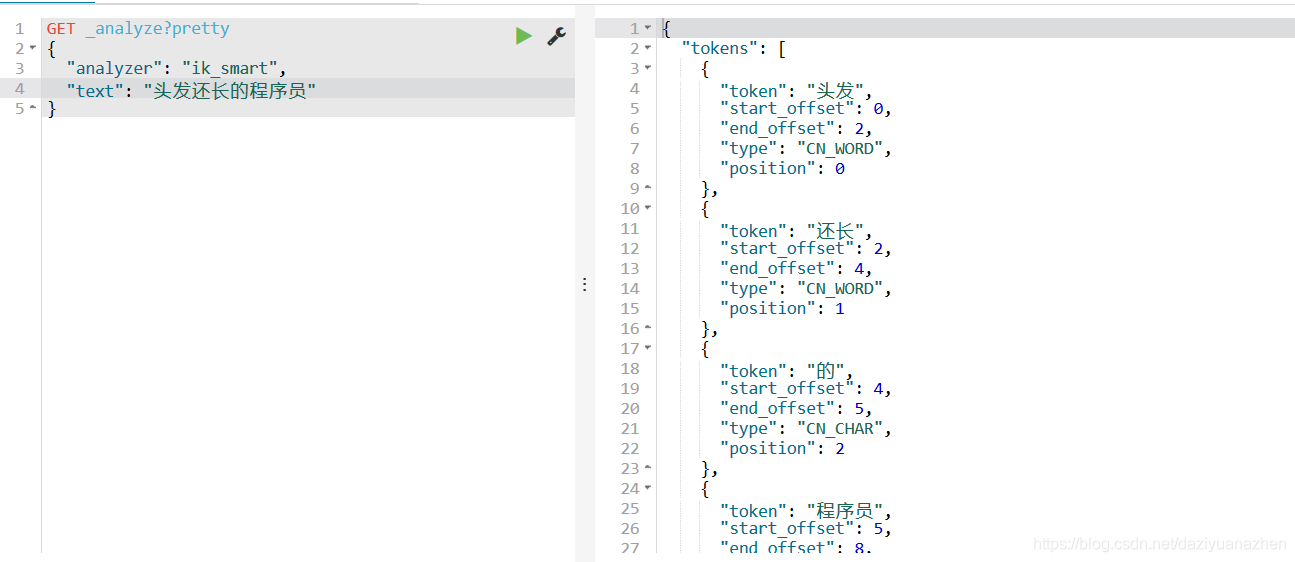
测试term查询,删除indextest索引,重新创建一个索引,
然后设置一个user类型,content字段使用ik_smart类型的分词器
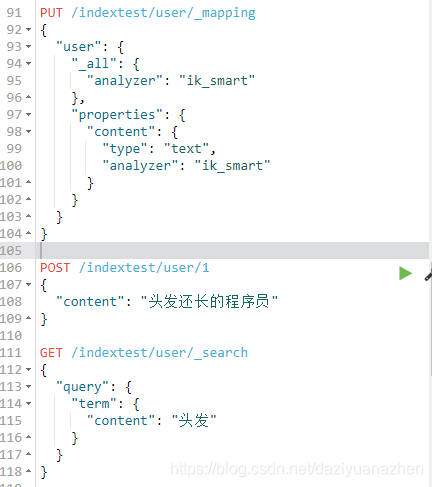
用term查询,使用头发关键字,可以查到数据。
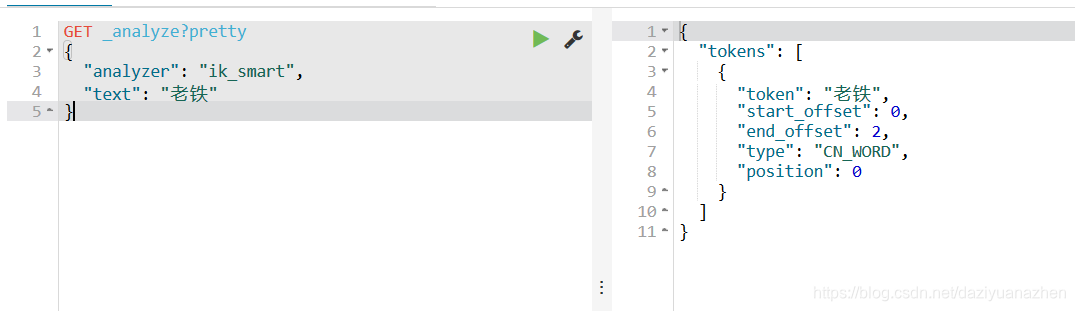
再测试一下热词“老铁”
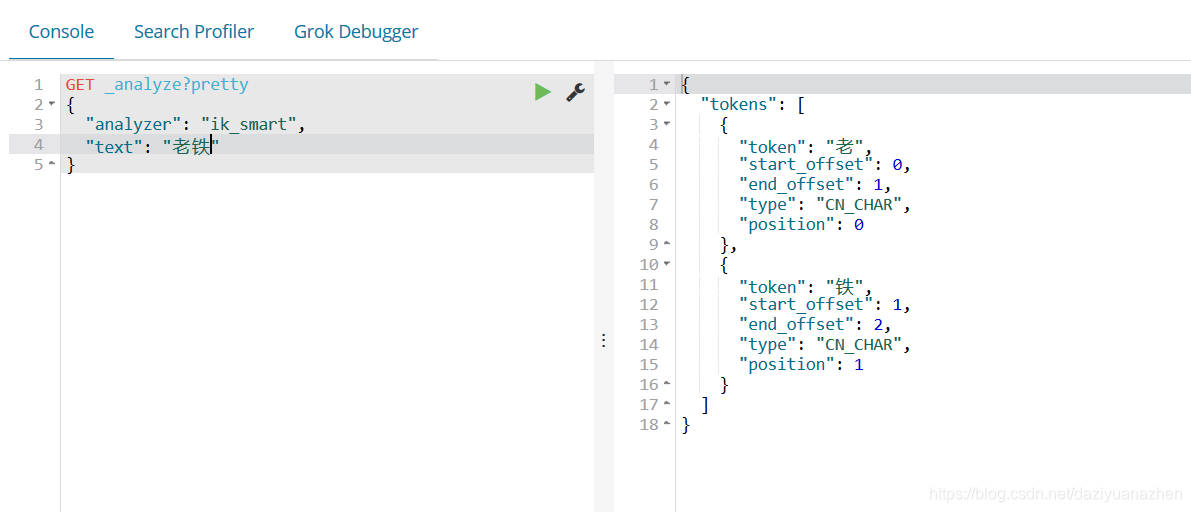
发现ik分词器是没有定义老铁这个词的,所以是按单个汉字分词。
那我们想要给ik添加这个词的话。
可以设置ik自定义扩展字典。
- cd elasticsearch-6.4.2/plugins/ik/config
- vi extra_main.dic 在此文件添加老铁这个词
- vi IKAnalyzer.cfg.xml 将扩展词典文件配置进去

重启es,然后测试
文档映射
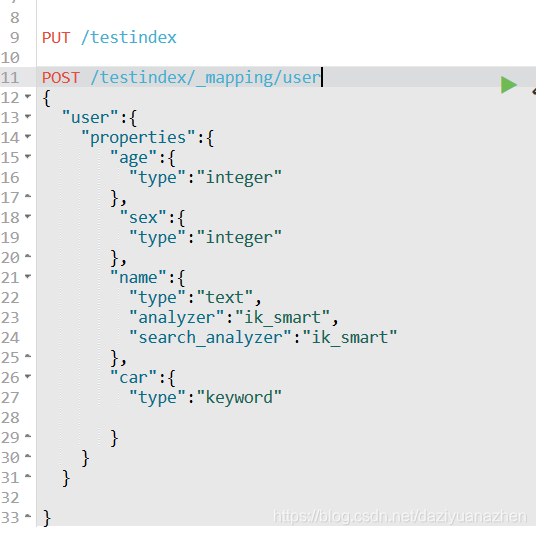
映射用于定义一个文档,可以定义所包含的字段以及字段的类型,分词器及属性等等。
文档映射就是给文档中的字段指定字段类型、分词器。
1.动态映射
es可以不需要事先定义映射,文档写入es时,会根据文档字段自动识别类型,这种机制称之为动态映射。
2.静态映射
在es中也可以事先定义好映射,包含文档的各个字段及其类型等。
es类型支持
1.基本类型
符串:string,string包含text和keyword。
text可以被用来索引长文本,在创建索引前会将这些文本进行分词,转化为词的组合,建立索引;允许es来检索这些词,但是text类型不能用来排序和聚合。
keyword不需要进行分词,可以被用来检索过滤、排序和聚合,只能完全匹配检索,不能模糊搜索。
keyword不能分词,text可以分词查询。
数类型:long、integer、short、byte、double、float
日期型:date
布尔型:boolean
二进制:binary
数组型:array datetype
2.复杂类型
地理位置类型(Geo datatypes)
地理坐标类型(Geo-point datatype):geo_point 用于经纬度坐标
地理形状类型(Geo-Shape datatype):geo_shape 用于类似于多边形的复杂形状
特定类型(Specialised datatypes)
Pv4 类型(IPv4 datatype):ip 用于IPv4 地址
Completion 类型(Completion datatype):completion 提供自动补全建议
Token count 类型(Token count datatype):token_count 用于统计做子标记的字段的index数目,该值会一直增加,不会因为过滤条件而减少
mapper-murmur3 类型:通过插件,可以通过_murmur3_来计算index的哈希值
附加类型(Attachment datatype):采用mapper-attachments插件,可支持_attachments_索引,例如 Microsoft office 格式,Open Documnet 格式, ePub,HTML等
Analyzer 索引分词器,索引创建的时候使用的分词器 比如ik_smart
Search_analyzer 搜索字段的值时,指定的分词器














 2711
2711











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









