







知名企业家、同时也是 NBA 小牛队的老板马克·库班(Mark Cuban)曾说过一句话:人工智能,深度学习和机器学习,不论你现在是否能够理解这些概念,你都应该学习。否则三年内,你就会像灭绝的恐龙一样被社会淘汰。马克·库班的这番话乍听起来有些耸人听闻,但仔细想想却不无道理。我们正经历一场大革命,这场革命就是由大数据和强大的电脑计算能力发起的。为了更好地面对和适应这场革命,了解一下相关的概念已经十分有必要了。


让我们花几分钟回想一下 20 世纪初的景象。那个时候很多人都不懂什么是电,在过去几十年,甚至几百年的时间里,人们一直沿用一种方式去做某件事情,但是突然间,好像身边的一切都变了。
以前需要很多人才能做成的事情,现在只需要一个人应用电力就能做成。而我们现在就正在经历相似的变革过程,今天这场变革的主角就是机器学习和深度学习。
如果你现在还不懂深度学习的巨大力量,那你真的要抓紧时间开始学啦!这篇文章就为大家介绍了深度学习领域常用的一些术语和概念。现在就从神经网络开始讲起。
神经网络基础概念
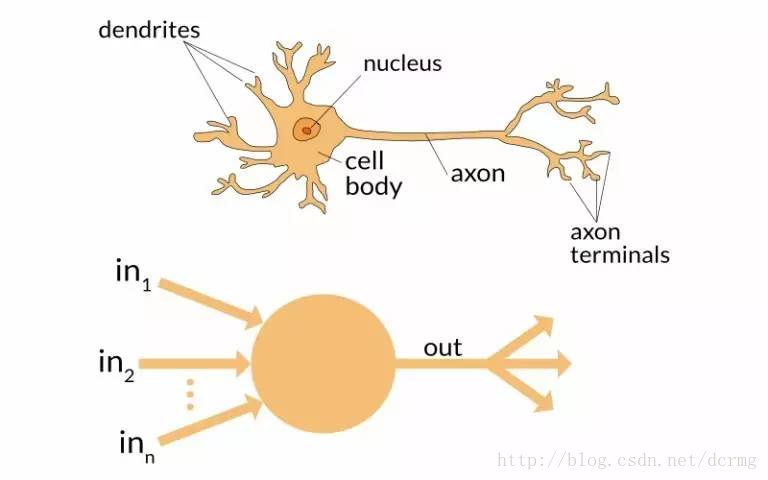
1. 神经元
正如神经元是大脑的基本单位一样,在神经网络结构中,神经元也是一个小单位。大家不妨想象一下当我们接触到新的信息时,大脑是如何运作的。
首先,我们会在脑中处理这个信息,然后产生输出信息。在神经网络中也是如此,神经元接收到一个输入信息,然后对它进行加工处理,然后产生输出信息,传输到其他神经元中进行进一步信息处理。
2. 权重
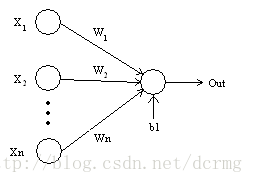
当输入信息到达神经元时,它就会乘上一个权重。举例来说,如果一个神经元包含两个输入信息,那么每个输入信息都被赋予它的关联权重。我们随机初始化权重,并在模型训练过程中更新这些权重。
接受训练后的神经网络会赋予它认为重要的输入信息更高的权重值,而那些不重要的输入信息权重值则会相对较小。权重值为零就意味着这个特征是无关紧要的。
我们不妨假设输入信息为 a,其关联权重为 W1,通过节点后,输入信息变为a*W1:
3. 偏置
除了权重之外,输入还有另一个线性分量,被称为偏置。输入信息乘上权重后再加上偏置,用来改变权重乘输入的范围。加上偏置之后,结果就变为 a*W1+bias,这就是输入信息变换的最终线性分量。
4. 激活函数
线性分量应用可以到输入信息,非线性函数也可以应用到输入信息。这种输入信息过程是通过激活函数来实现的。
激活函数将输入信号翻译成输出信号。激活函数产生的输出信息为 f(a*W1+b) ,其中 f(x) 就是激活函数。
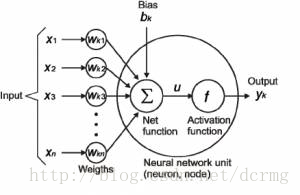
在下面的图表中,我们可以看到,输入信息数量为 n,表示为 X1 到 Xn,相应的权重为 Wk1 到 Wkn。将偏置设为 bk。权重乘以输入信息,再加偏置,我们设所得的值为 u:
u=∑w*x+b
将 u 带入激活函数中,最后我们就可以得到从神经元输出的 yk=f(u)
最常用的激活函数有 Sigmoid、ReLU 和 softmax。
-
Sigmoid——Sigmoid 是最常用的激活函数之一。它的定义为:
sigmoid(x) = 1/(1+e-x)
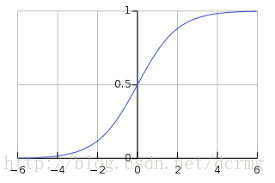
Sigmoid 函数会生成 0 到 1 之间的更平滑的取值范围。我们可能需要观察输出值的变化,同时输入值也会略有变化。而平滑的曲线更方便我们观察,因此它优于阶梯函数(step functions)。
-
ReLU(线性修正单位)——不同于 Sigmoid 函数,现在的网络更倾向于使用隐层 ReLu 激活函数。该函数的定义是:
f(x) = max(x,0)
当 X>0 时,函数的输出为 X,当 X<=0 时为 0。该函数如下所示:
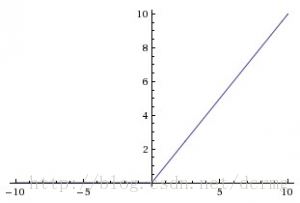
使用 ReLu 的好处主要是它对于大于 0 的所有输入值都有对应的不变导数值。而常数导数值可以加快对网络的训练。
-
Softmax——Softmax 激活函数常用于输出层的分类问题。它与 Sigmoid 函数类似,唯一的区别是在 Softmax 激活函数中,输出被归一化,总和变为 1。
如果我们遇到的是二进制输出问题,就可以使用 Sigmoid 函数,而如果我们遇到的是多类型分类问题,使用 Softmax 函数可以轻松地为每个类型分配值,并且可以很容易地将这个值转化为概率。
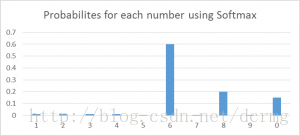
这样看可能更容易理解一些——假设你正在尝试识别一个看起来像 8 实际为 6 的数。该函数将为每个数字赋值,如下所示。我们可以很容易地看出,最高概率被分配给了 6,下一个最高概率则分配给 8,依此类推……
5. 神经网络
神经网络是深度学习的主干之一。神经网络的目标是找到未知函数的一个近似值。它由相互联系的神经元组成。
这些神经元具有权重,并且会根据出错情况,在网络训练期间更新偏置值。激活函数将非线性变换置于线性组合,之后生成输出。被激活的神经元组合再产生输出。
对神经网络的定义中,以 Liping Yang 的最为贴切:
神经网络由许多相互关联的概念化的人造神经元组成,这些人造神经元之间可以互相传递数据,并且具有根据网络「经验」调整的相关权重。
神经元具有激活阈值,如果结合相关权重组合并激活传递给他们的数据,神经元的激活阈值就会被解除,激活的神经元的组合就会开始「学习」。
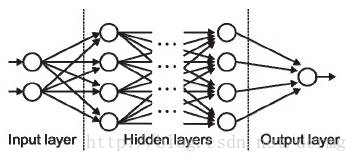
6. 输入层 / 输出层 / 隐藏层
顾名思义,输入层是接收输入信号的一层,也是该网络的第一层;输出层则是传递输出信号的一层,也是该网络的最后一层。
处理层则是该网络中的「隐含层」。这些「隐含层」将对输入信号进行特殊处理,并将生成的输出信号传递到下一层。输入层和输出层均是可见的,而其中间层则是隐藏起来的。
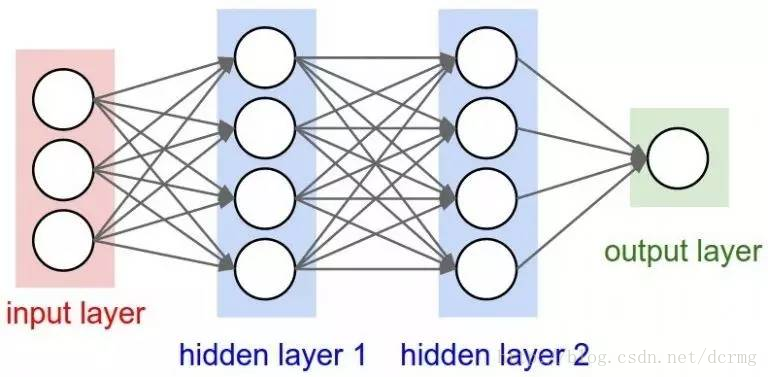
7. MLP(多层神经网络)
单一神经元无法执行高度复杂的任务。因此,需要大量神经元聚集在一起才能生成我们所需要的输出信号。
最简单的网络由一个输入层、一个输出层、一个隐含层组成,每一层上都有多个神经元,并且每一层上的神经元都和下一层上的神经元连接在了一起,这样的网络也被称为全互连网络(Fully Connected Networks)。
8. 正向传播(Forward Propagation)
正向传播指的是输入信号通过隐藏层传递到输出层的传递过程。
在正向传播中,信号仅沿单一方向向前正向传播,输入层将输入信号提供给隐藏层,隐藏层生成输出信号,这一过程中没有任何反向移动。
9. 成本函数(Cost Function)
当我们建立一个网络后,网络将尽可能地使输出值无限接近于实际值。我们用成本函数(或损失函数)来衡量该网络完成这一过程的准确性。成本函数(或损失函数)将在该网络出错时,予以警告。
运行网络时,我们的目标是:尽可能地提高我们的预测精度、减少误差,由此最小化成本函数。最优化的输出即当成本函数(或损失函数)为最小值时的输出。
若将成本函数定义为均方误差,则可写成:
C= 1/m ∑(y – a)2
m 在这里是训练输入值(Training Inputs),a 是预计值,y 是特定事例中的实际值。
学习过程围绕着如何最小化成本。
10. 梯度下降(Gradient Descent)
梯度下降是一种成本最小化的优化算法。想象一下,当你下山时,你必须一小步一小步往下走,而不是纵身一跃跳到山脚。
因此,我们要做的是:比如,我们从 X 点开始下降,我们下降一点点,下降 ΔH,到现在的位置,也就是 X-ΔH,重复这一过程,直到我们到达「山脚」。「山脚」就是最低成本点。
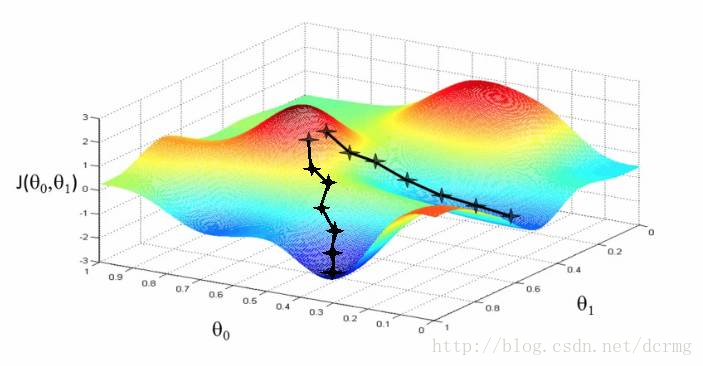
从数学的角度来说,要找到函数的局部极小值,须采取与函数梯度负相关的「步子」,即:梯度下降法是用负梯度方向为搜索方向的,梯度下降法越接近目标值,步长越小,前进越慢。
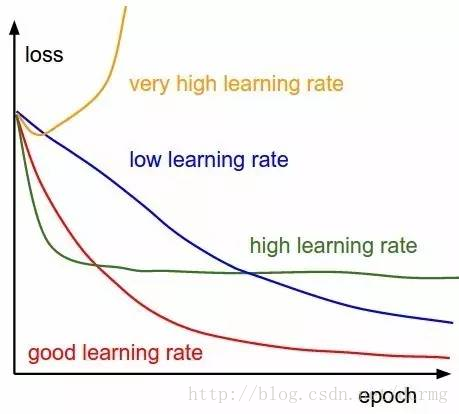
11. 学习速率(Learning Rate)
学习速率指每次迭代中对成本函数的最小化次数。简单来说,我们把下降到成本函数最小值的速率称为学习率。选择学习率时,我们必须非常小心,学习速率既不应过大——会错过最优解,也不应过小——使网络收敛将需要很多很多步、甚至永不可能。
12. 反向传播(Back Propagation)
在定义一个神经网络的过程中,每个节点会被随机地分配权重和偏置。
一次迭代后,我们可以根据产生的结果计算出整个网络的偏差,然后用偏差结合成本函数的梯度,对权重因子进行相应的调整,使得下次迭代的过程中偏差变小。
这样一个结合成本函数的梯度来调整权重因子的过程就叫做反向传播。在反向传播中,信号的传递方向是朝后的,误差连同成本函数的梯度从输出层沿着隐藏层传播,同时伴随着对权重因子的调整。
13. 分批(Batches)
当我们训练一个神经网路时,我们不应一次性发送全部输入信号,而应把输入信号随机分成几个大小相同的数据块发送。
与将全部数据一次性送入网络相比,在训练时将数据分批发送,建立的模型会更具有一般性。
14. 周期(Epochs)
一个周期表示对所有的数据批次都进行了一次迭代,包括一次正向传播和一次反向传播,所以一个周期就意味着对所有的输入数据分别进行一次正向传播和反向传播。
训练网络周期的次数是可以选择的,往往周期数越高,模型的准确性就越高,但是,耗时往往就越长。同样你还需要考虑如果周期 / 纪元的次数过高,那么可能会出现过拟合的情况。
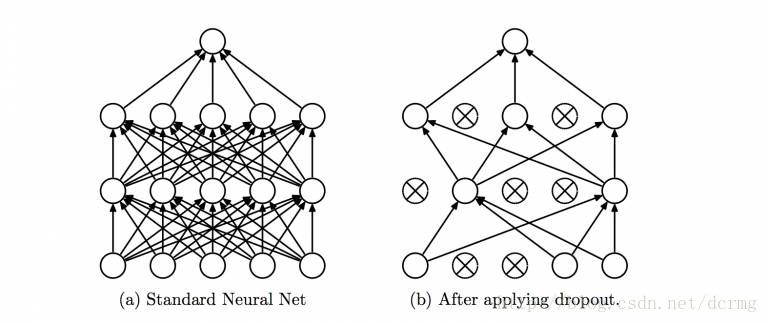
15. Dropout 方法
Dropout 是一个可以阻止网络过拟合的规则化方法。就像它的名字那样,在训练过程中隐藏的某些特定神经元会被忽略掉(drop)。
这意味着网络的训练是在几个不同的结构上完成的。这种 Dropout 的方式就像是一场合奏,多个不同结构网络的输出组合产生最终的输出结果。
16. 分批标准化(Batch Normalization)
分批标准化就像是人们在河流中用以监测水位的监察站一样。
这是为了保证下一层网络得到的数据拥有合适的分布。在训练神经网络的过程中,每一次梯度下降后权重因子都会得到改变,从而会改变相应的数据结构。
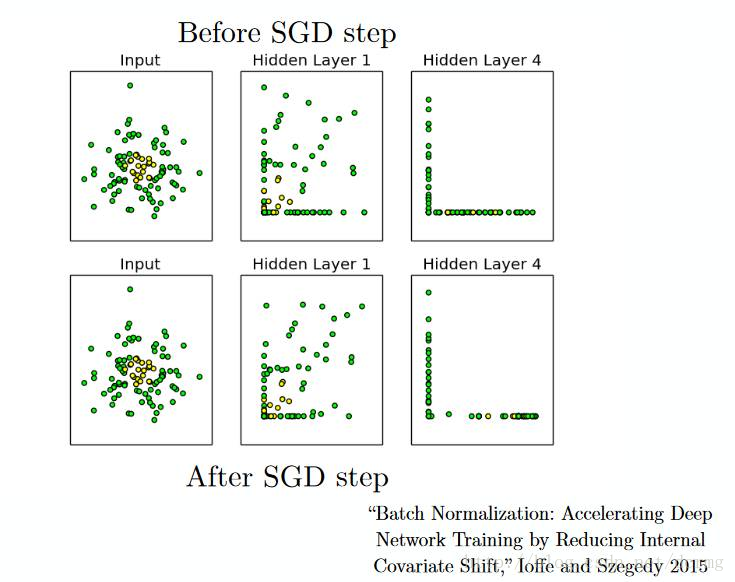
但是下一层网络希望能够得到与之前分布相似的数据,因此在每一次数据传递前都需要对数据进行一次正则化处理。

卷积神经网络
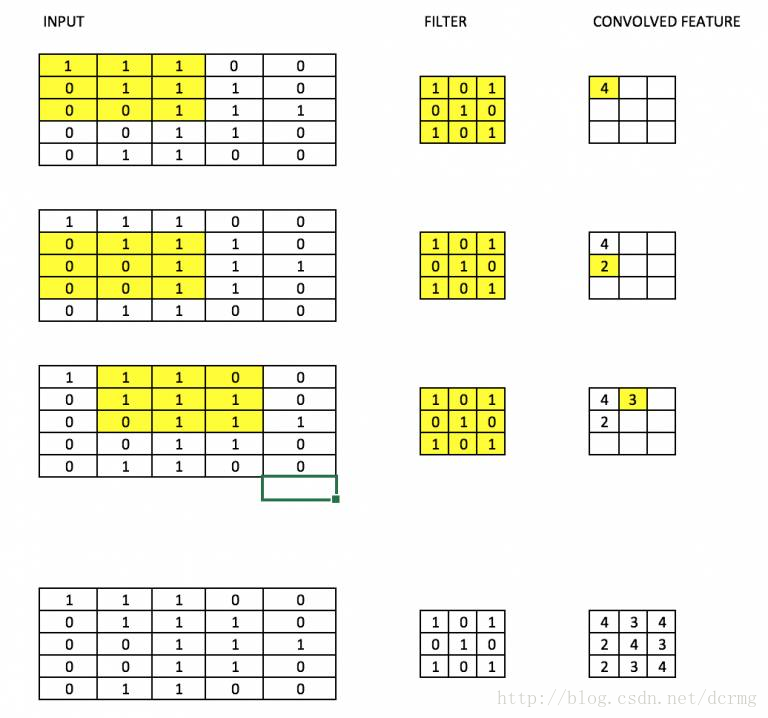
17. 过滤器 / 滤波器(Filters)
CNN 中的滤波器,具体是指将一个权重矩阵乘以输入图像的一个部分,产生相应的卷积输出。
比方说,对于一个 28×28 的图片而言,将一个 3×3 的滤波器与图片中 3×3 的矩阵依次相乘,从而得到相应的卷积输出。
滤波器的尺寸通常比原始图片要小,与权重相似,在最小化成本的反向传播中,滤波器也会被更新。就像下面这张图片一样,通过一个过滤器,依次乘以图片中每个 3×3 的分块,从而产生卷积的结果。
18. 卷积神经网络 CNN(Convolutional Neural Network)
卷积神经网络通常用来处理图像数据,假设输入数据的形状为 28×28×3(28pixels × 28pixels × RGBValue),那么对于传统的神经网络来说就会有 2352(28×28×3)个变量。随着图像尺寸的增加,那么变量的数量就会急剧增加。
通过对图片进行卷积,可以减少变量的数目(已在过滤器的概念中提及)。随着过滤器沿着图像上宽和高的两个方向滑动,就会产生一个相应的 2 维激活映射,最后再沿纵向将所有的激活映射堆叠在一起,就产生了最后的输出。
可以参照下面这个示意图。

19. 池化(Pooling)
为进一步减少变量的数目同时防止过拟合,一种常见的做法是在卷积层中引入池化层(Pooling Layer)。
最常用的池化层的操作是将原始图片中每个 4×4 分块取最大值形成一个新的矩阵,这叫做最大值池化(Max Pooling)。
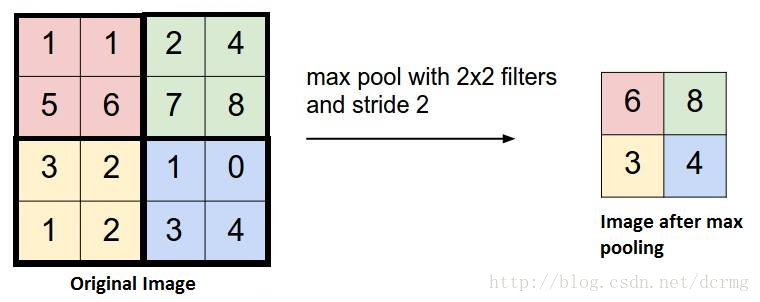
也有人尝试诸如平均池化(Average Pooling)之类的方式,但在实际情况中最大化池化拥有更好的效果。
20. 补白(Padding)
补白(Padding)通常是指给图像的边缘增加额外的空白,从而使得卷积后输出的图像跟输入图像在尺寸上一致,这也被称作相同补白(Same Padding)。
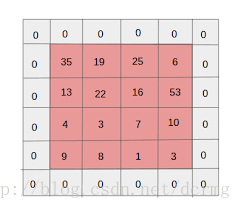
如应用过滤器,在相同补白的情况下,卷积后的图像大小等于实际图像的大小。
有效补白(Valid Padding)指的是保持图片上每个真实的像素点,不增加空白,因此在经历卷积后数据的尺寸会不断变小。
21. 数据增强(Data Augmentation)
数据增强指的是从已有数据中创造出新的数据,通过增加训练量以期望能够提高预测的准确率。
比如,在数字识别中,我们遇到的数字9可能是倾斜或旋转的,因此如果将训练的图片进行适度的旋转,增大训练量,那么模型的准确性就可能会得到提高。
通过「旋转」「照亮」的操作,训练数据的品质得到了提升,这种过程被称作数据增强。

递归神经网络
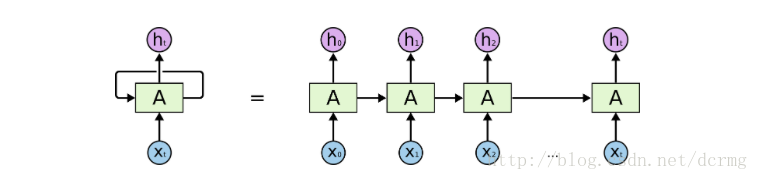
22. 递归神经元(Recurrent NeuralNetwork)
对于递归神经元来说,经由它自己处理过的数据会变成自身下一次的输入,这个过程总共会进行 t 次。
如下图所示,将递归神经元展开就相当于 t 个不同的神经元串联起来,这种神经元的长处是能够产生一个更全面的输出结果。
23. 递归神经网络(RNN-Recurrent NeuralNetwork)
递归神经网络通常被用于处理序列化的数据,即前一项的输出是用来预测下一项的输入。
递归神经网络通常被用于处理序列化的数据,即前一项的输出是用来预测下一项的输入。递归神经网络中存在环的结构,这些神经元上的环状结构使得它们能够存储之前的数据一段时间,从而使得能够预测输出。
与递归神经元相似,在 RNN 中隐含层的输出会作为下一次的输入,如此往复经历 t 次,再将输出的结果传递到下一层网络中。这样,最终输出的结果会更全面,而且之前训练的信息被保持的时间会更久。
隐藏层将反向传递错误以更新权重。这被称为 backpropagation through time(BPTT)。
24. 梯度消失问题
当激活函数的梯度非常小时,会出现梯度消失问题。在反向传播过程中,权重因子会被多次乘以这些小的梯度,因此会越变越小。随着递归的深入趋于「消失」,神经网络失去了长程可靠性。这在递归神经网络中是一个较普遍的问题,对于递归神经网络而言,长程可靠性尤为重要。
这一问题可通过采用 ReLu 等没有小梯度的激活函数来有效避免。
25. 梯度爆炸问题
梯度爆炸问题与梯度消失问题正好相反,梯度爆炸问题中,激活函数的梯度过大。
在反向传播过程中,部分节点的大梯度使得他们的权重变得非常大,从而削弱了其他节点对于结果的影响,这个问题可以通过截断(即设置一个梯度允许的最大值)的方式来有效避免。
写在最后
本文对深度学习的基本概念做出了高度的概括,希望各位在阅读这篇文章后,可以对这些概念有初步的了解。
作者:Dishashree Gupta
原题:25 Must Know Terms & concepts for Beginners in Deep Learning
出处:http://t.cn/RaDutTf
转载自「灯塔大数据(DTbigdata)」














 1390
1390











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









