







CTC
CTC网络的输入
CTC网络的输入是一个样本(图像)经过网络(一般是CNN+RNN)计算后生成的特征向量(特征序列)。
特征序列里各个向量是按序排布的,是从图像样本上从左到右的一个个小的区间映射过来的,可以设置区间的大小(宽度),宽度越小,获得的特征序列里的特征向量个数越多,极端情况下,可以设置区间宽度为1,这样就会生成width(图像宽度)个特征向量。
CTC网络的计算过程
CTC网络的计算是为了得到特征序列最可能对应的标签对象,对语音识别是一段话,对文本识别是一段文字。
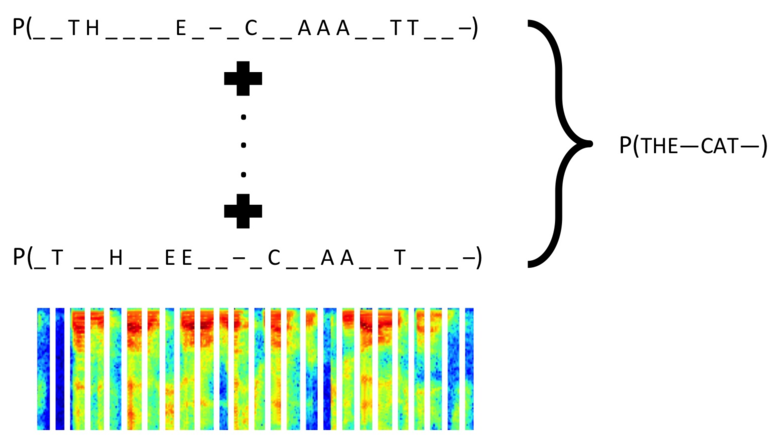
1. 计算特征序列里N个特征向量分别对应的n个可能结果的概率。如果当前的特征向量的预测结果不在样本标签列表里,就置预测结果为blank空格或下划线。计算结果从一个N维的特征序列,得到一个N×n的预测序列。
2. 计算N×n的预测序列对应的所有可能的结果的概率,中间涉及到去除重复字母和blank的操作。N×n个特征向量对应的所有可能结果有n的N次方个,涉及到组合学,计算所有可能概率的成本会很高,但是CTC运用了动态规划以大幅降低计算的复杂性。
CTC网络的输出
对训练过程,取最大概率对应的结果跟真实标签之间的差异(计算编辑距离等方法),作为训练Loss,反向传输给前端网络。
CTC计算过程示意图:
pytorch安装
GPU版本的:
conda install pytorch=0.3.0 cuda80 -c soumithCPU版本的:
conda install pytorch=0.3.0 -c soumith参考官网: https://pytorch.org/#pip-install-pytorch
warp-CTC安装
warp-CTC安装:
git clone https://github.com/SeanNaren/warp-ctc.git
cd warp-ctc
mkdir build; cd build
cmake ..
make
cd ../pytorch_binding
python setup.py install添加环境变量:
gedit ./.bashrc
export WARP_CTC_PATH=/home/xxx/warp-ctc/build验证pytorch中warp-CTC是否可用GPU例子:
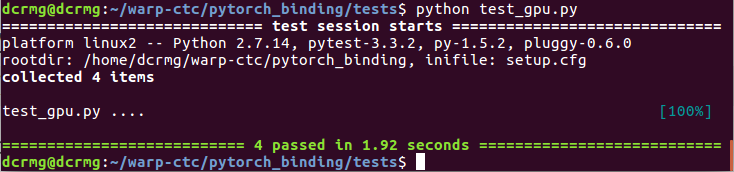
cd /home/xxx/warp-ctc/pytorch_binding/tests
python test_gpu.pyOK输出:
或:
import torch
from torch.autograd import Variable
from warpctc_pytorch import CTCLoss
ctc_loss = CTCLoss()
# expected shape of seqLength x batchSize x alphabet_size
probs = torch.FloatTensor([[[0.1, 0.6, 0.1, 0.1, 0.1], [0.1, 0.1, 0.6, 0.1, 0.1]]]).transpose(0, 1).contiguous()
labels = Variable(torch.IntTensor([1, 2]))
label_sizes = Variable(torch.IntTensor([2]))
probs_sizes = Variable(torch.IntTensor([2]))
probs = Variable(probs, requires_grad=True) # tells autograd to compute gradients for probs
cost = ctc_loss(probs, labels, probs_sizes, label_sizes)
cost.backward()
print('PyTorch bindings for Warp-ctc')PyTorch bindings for Warp-ctc参考: https://github.com/SeanNaren/warp-ctc














 6207
6207











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









