









YOLO v1
YOLO v1的检测思路
YOLO v1的整体思路是将输入图像(448×448)均分为7×7个网格,在每个网格上直接预测2个目标物体的位置+2个目标物体的类别概率+整体网格属于某一分类的最大概率,若分类是20类,则每一张输入图片最后输出是 7×7×(20+2×(4+1))=7*7*50 维的向量。
v1的检测特点
v1检测的特点是速度快,但是根据物理位置分割检测区域没有充分利用到图像上物体之间的局部相关性。
v1网络结构
v1的训练
先用224×224的输入在ImageNet的1000个分类上训练识别网络。之后取该网络的前20层,加上YOLO v1的4个卷积层和2个全连接层,组成识别+定位网络,训练输入是448×448。使用了Leaky Relu激活和Dropout。
v1的坐标、大小转化
用CNN网络直接回归出物体的坐标是很难的,YOLO中对坐标和物体宽高进行了一些转化。 宽w和高h分别除以图片的宽和高,坐标点x和y分别对应于小方格左上角坐标点的偏移量(0~1)。 宽高和坐标偏移量都在0~1之间。
v1的损失函数
- 1. 位置坐标损失: 每个小网格上输出2×4维的位置信息,相比20维的类别信息,一是体量小,二是对于分类,还会在所有7×7的网格的结果上做最终的整合,单个网格分类就算有一点偏差也不至于影响太大,所以加强了位置损失的比重。作者设置位置和类别损失的比重为5:1。
- 2. 置信度损失函数: 每个小网格上输出2个目标是前景物体的置信度,由于大部分情况下是不含目标物体的,置信度为0,所以需要减弱不含目标物体网格的影响,防止网络不稳定或者发散。 所以取不含目标物体网格的权重为0.5,含目标物体网格权重正常取1。
- 3. 坐标边框转换:考虑到小目标的边框偏差更重要,将坐标的W和H分别求平方根代替原来的W和H,达到在同等差距下,小目标方框的偏差影响更大的目的。
YOLO v2
v2改进
1. 添加了BN层
2. 训练识别网络时候直接使用448×448,而不是224×224
3. 取消全连接层,改用Fast R-CNN中的anchor boxes来预测目标方框,使用聚类方法获得5个anchor box宽高的比例(而不是Faster R-CNN中固定比例)。 图像的输入从448×448改为416×416,这样是为了下采样32倍之后得到13×13奇数的特征图。 从这13×13特征图上每一个点映射回原图得到13×13×5个目标框。 并且从预测目标相对坐标改为预测目标相对于网格单元的直接位置坐标(sigmoid约束到0~1)。
4. 特征融合: 把倒数第二层26×26×512卷积层的特征,经过隔行和隔列提取,得到4个13×13×512的特征,再联合成13×13×2048的特征图,跟最后一层13×13×1024特征图融合起来检测,使得结果对小目标敏感。
5. 训练技巧上,每训练10个batch后随机选择新的不同尺寸的图像训练,图像大小以32的倍数增加或减小,以提高系统对不同尺寸图像的适应能力。
6. 检测类别的提升: (论文中使用设置)v1的种类最多可以有7×7×2=98个boxes(种类),v2中可以有13×13×5=745个boxes(种类)
YOLO v3
v3改进
- 1. 更深的网络,特征提取更充分,参考了ResNet,增加了直接连接 shortcut connections,层数达到53层。
- 2. 在多个尺度上的预测,在倒数第二和倒数第三层26×26和52×52层的特征上分别进行预测,每个尺度预测3个box,一共3个尺度共9个。由v2中每个点预测5个bbox改为预测9个。
- 3. 对每个建议框使用多个逻辑回归而不是softmax进行分类,这是考虑到实际中物体间叠加的情况很常见,softmax只能给出最大分类,导致漏检。
v3为什么比v2在小目标检测上更好
1. loss不同:v3中的分类使用了多个逻辑回归loss,而不是v2中的softmax
2. anchor boxes数量不同:v3中预测3×3一共9个,v2中是5个。提供了IOU。
3. 检测策略不同: v3是直接在3个尺度上检测,v2是在两个融合的尺度上检测。
4. 特征提取网络上的一些优化,更深。
v3为什么比v2更快
v3的网络虽然比v2更深,但是所需要的浮点运算次数比v2要少。
可能的原因:yolov2是一个纵向自上而下的网络架构,随着channel数目的不断增加,FLOPS是不断增加的,而v3网络架构是横纵交叉的,看着卷积层多,其实很多channel的卷积层没有继承性。
另外,虽然yolov3增加了anchor box从v2的5个提高到了9个,但是对ground truth的估计变得更加简单,每个ground truth只匹配一个先验框,而且每个尺度只预测3个框,v2预测5个框。这样的话也降低了复杂度。
更新:
相对v2,v3提高了mAP,对小目标的检测效果更好,但是速度方面,v3是慢于v2的,见下表(来自yolo官网):
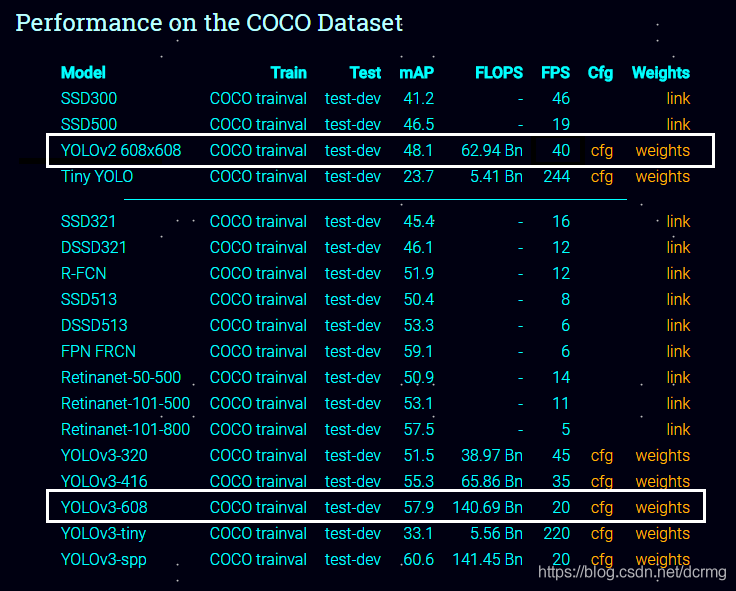
正常情况下v3比v2慢,速度约为v2的一半,但是v3-tiny检测速度快于v2,v3可以方便的调整模型,在准确率和速度上可以做一个权衡。














 1140
1140











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









