






作业要求来自:https://edu.cnblogs.com/campus/gzcc/GZCC-16SE2/homework/3319
1.用自己的话阐明Hadoop平台上HDFS和MapReduce的功能、工作原理和工作过程。
HDFS(Hadoop Distributed File System,Hadoop分布式文件系统),它是一个高度容错性的系统,适合部署在廉价的机器上。HDFS能提供高吞吐量的数据访问,适合那些有着超大数据集(large data set)的应用程序。
易于扩展的分布式文件系统
运行在大量普通廉价机器上,提供容错机制
为大量用户提供性能不错的文件存取服务
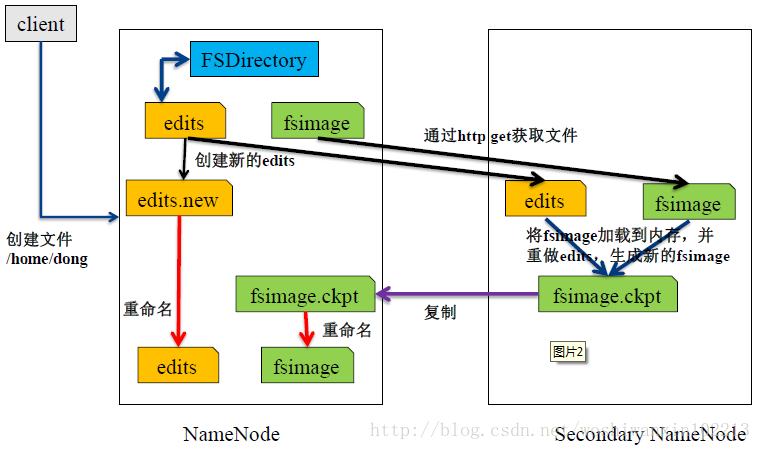
MapReduce是并行处理框架,实现任务分解和调度。
其实原理说通俗一点就是分而治之的思想,将一个大任务分解成多个小任务(map),小任务执行完了之后,合并计算结果(reduce)。
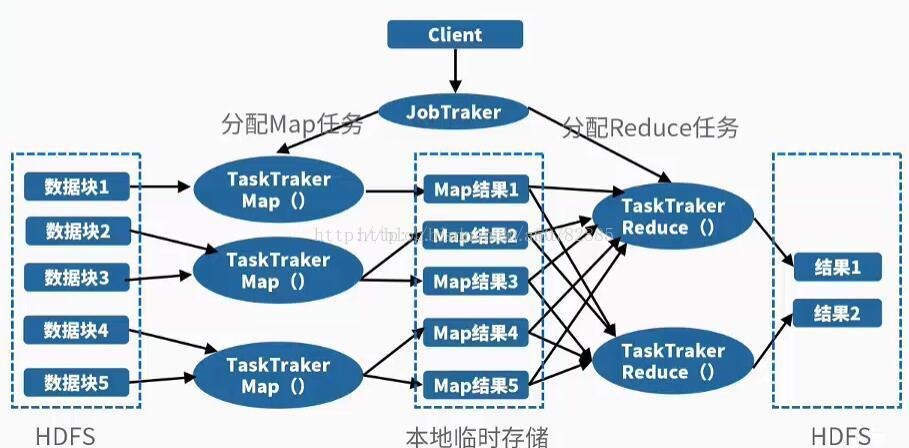
也就是说,JobTracker拿到job之后,会把job分成很多个maptask和reducetask,交给他们执行。 MapTask、ReduceTask函数的输入、输出都是<key,value>的形式。HDFS存储的输入数据经过解析后,以键值对的形式,输入到MapReduce()函数中进行处理,输出一系列键值对作为中间结果,在Reduce阶段,对拥有同样Key值的中间数据进行合并形成最后结果。
2.HDFS上运行MapReduce
1)查看是否已经安装python:
1)准备文本文件,放在本地/home/hadoop/wc

2)编写map函数和reduce函数,在本地运行测试通过


3)启动Hadoop:HDFS, JobTracker, TaskTracker
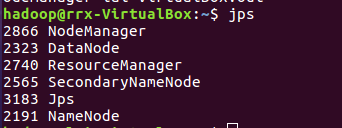
4)把文本文件上传到hdfs文件系统上 user/hadoop/input

5)streaming的jar文件的路径写入环境变量,让环境变量生效

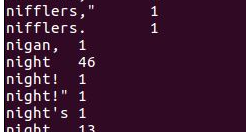
6)source run.sh来执行mapreduce
















 734
734











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









