







 本文探讨了人工智能中的不公平性和偏见问题,特别是在推荐系统中的体现,如TikTok和淘宝如何根据用户画像推送不同内容。作者认为解决不公平性需要从数据多样性和模型客观性两方面着手。此外,文章还讨论了社会偏见如何影响我们对问题的看法,以产品评价和疫情封锁态度为例,揭示了主观视角如何塑造算法并可能导致错误结果。
本文探讨了人工智能中的不公平性和偏见问题,特别是在推荐系统中的体现,如TikTok和淘宝如何根据用户画像推送不同内容。作者认为解决不公平性需要从数据多样性和模型客观性两方面着手。此外,文章还讨论了社会偏见如何影响我们对问题的看法,以产品评价和疫情封锁态度为例,揭示了主观视角如何塑造算法并可能导致错误结果。
IIT CS 480 - Introduction to Artificial Intelligence
Assignments_Week13_Participation
github: https://github.com/IIT-MAI-2020Fall
论文文档
https://arxiv.org/pdf/1908.09635.pdf
下载地址: https://download.csdn.net/download/dearsq/13204734
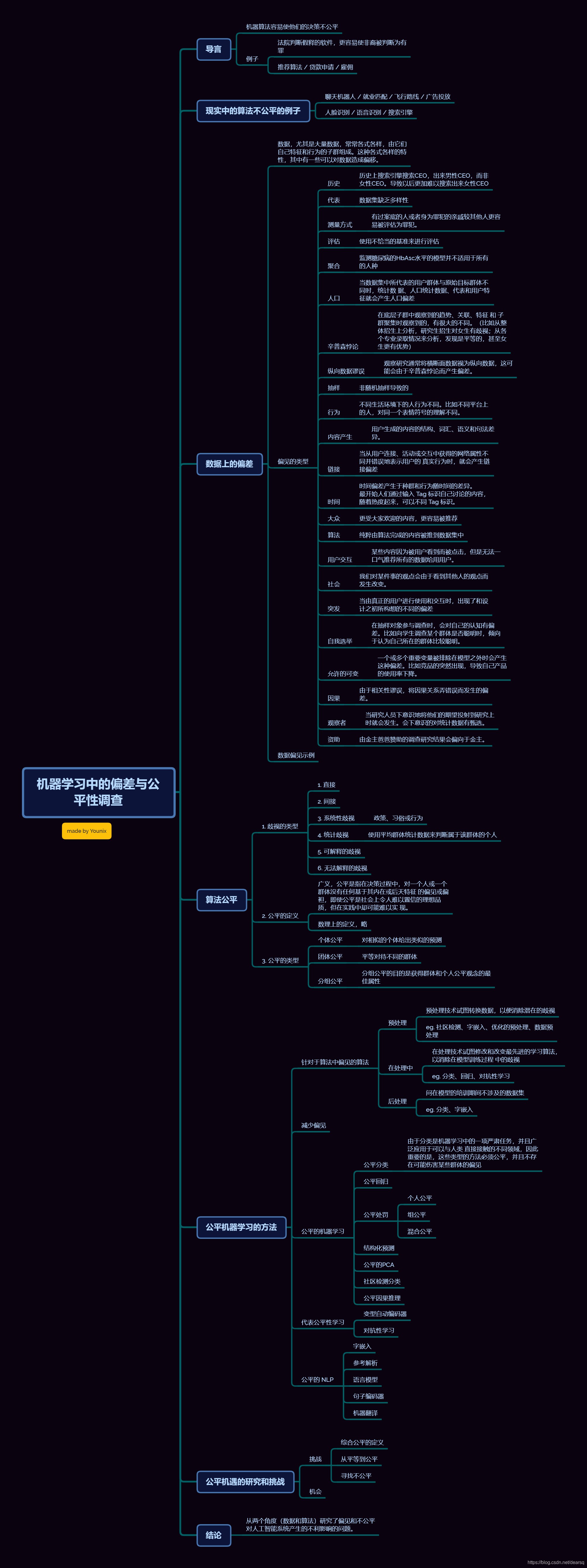
思维导图
Two questions
Share your general thoughts on this topic. This is an open question. You can focus on any aspect of it you like. I need you to write at least one paragraph (roughly 200 words or more) on this question. This should be a general discussion of this topic; do not focus on a single problem. Next question asks you to focus on a single problem.
Pick one type of bias from section 3.1. There are 23 to choose from. Research that type of bias. The paper has references that you can read; you can also Google that topic. Share your thoughts on that problem. How does it affect your life? How does it affect other people’s lives? Why is it an important problem? I need you to write at least one paragraph (roughly 200 words or more) on this question.
Assignments
总体看法
Unfairness and bias are common in computer software. TikTok will recommend different products according to users’ portraits. It will push Tesla to you if you often watch cars, and Steam discount coupons to you if you watch game videos. Taobao will even offer you more expensive or uncoupon-free items based on your actual purchasing power. The algorithm is determined by the data and the model. If the data itself is biased, or if the designer of the model is biased. Then of course the results are biased. Therefore, In my opinion, to solve the problem of fairness, we need to start from two aspects: 1. Try to make the data set more diverse. 2. Make the model as objective as possible.
关于 Social Bias 的看法
I want to talk about Social Bias. When we face a problem, we have an opinion, which is derived from our personal experience. But when we see someone else’s better perspective on the issue, we often change our perspective.
For myself, for example, to judge the quality of a product, I think the product is badly designed, but some people think the product is not bad. I wonder if I’m being mean and make comments that don’t belong in my head. If the user feedback algorithm is trained based on such data, a biased model is inevitable. Algorithms tend to overestimate the value of products.
Another example. Take the lockdown of the city. Some would accept sacrificing a period of their freedom in exchange for an early end to the epidemic. But some people think that the country’s economy is more important and cannot stop production. The former believes that the latter viewpoint is more mission and selfless. So they give up and agree with the latter. But from a macro point of view, this seemingly selfless view is clearly wrong.
If we train polling algorithms based on such data, we will also get wrong results.


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









