




一般单机的情况我们用一个 Lock,synchronized锁锁住了就行了,为什么还要分布式锁呢,什么情况下会用分布式锁呢,带着问题,我们开始今天的精彩博弈---------------
什么时候用分布式锁?
诊所只有一个医生,很多患者前来就诊。
医生在同一时刻只能给一个患者提供就诊服务。
如果不是这样的话,就会出现医生在就诊肾亏的「肖菜鸡」准备开药时候患者切换成了脚臭的「谢霸哥」,这时候药就被谢霸哥取走了。
治肾亏的药被有脚臭的拿去了。
当并发去读写一个【共享资源】的时候,我们为了保证数据的正确,需要控制同一时刻只有一个线程访问。
分布式锁就是用来控制同一时刻,只有一个 JVM 进程中的一个线程可以访问被保护的资源。
分布式锁应该具备哪些特性?
1 互斥:在任何给定时刻,只有一个客户端可以持有锁;
2 无死锁:任何时刻都有可能获得锁,即使获取锁的客户端崩溃;
3 容错:只要大多数 Redis的节点都已经启动,客户端就可以获取和释放锁。
SETNX 命令是原子性的,那么为什么在分布式的时候不考虑它呢
带着场景去看看:
SETNX key value 命令是实现「互斥」特性。这个命令来自于SET if Not eXists的缩写,意思是:如果 key 不存在,则设置 value 给这个key,否则啥都不做。Redis 官方地址说的:
命令的返回值:
1:设置成功;
0:key 没有设置成功。
如下场景:
敲代码一天累了,想去放松按摩下肩颈。
168 号技师最抢手,大家喜欢点,所以并发量大,需要分布式锁控制。
同一时刻只允许一个「客户」预约 168 技师。
肖菜鸡申请 168 技师成功:
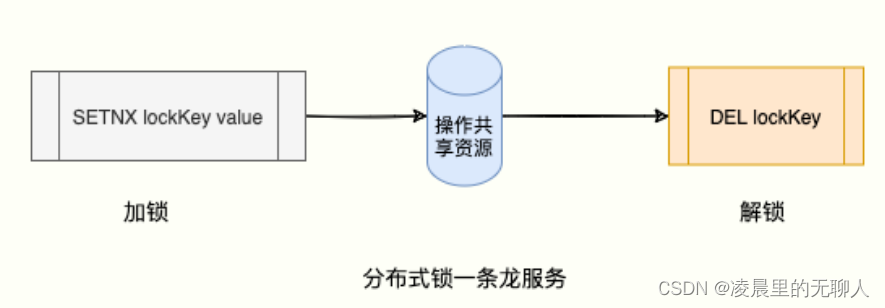
> SETNX lock:168 1
(integer) 1 # 获取 168 技师成功
谢霸哥后面到,申请失败:
> SETNX lock 2
(integer) 0 # 客户谢霸哥 2 获取失败
此刻,申请成功的客户就可以享受 168 技师的肩颈放松服务「共享资源」。
享受结束后,要及时释放锁,给后来者享受 168 技师的服务机会。
如何释放锁呢
> DEL lock:168
(integer) 1
肖菜鸡,事情可没这么简单。
这个方案存在一个存在造成锁无法释放的问题,造成该问题的场景如下:
客户端所在节点崩溃,无法正确释放锁;
业务逻辑异常,无法执行 DEL指令。
这样,这个锁就会一直占用,锁在我手里,我挂了,这样其他客户端再也拿不到这个锁了。
加超时释放锁----谁要这么写,就糟透了。
我可以在获取锁成功的时候设置一个「超时时间」比如设定按摩服务一次 60 分钟,那么在给这个 key 加锁的时候设置 60 分钟过期即可:
SETNX lock:168 1 // 获取锁
(integer) 1
EXPIRE lock:168 60 // 60s 自动删除
(integer) 1
这样,到点后锁自动释放,其他客户就可以继续享受 168 技师按摩服务了。
「加锁」、「设置超时」是两个命令,他们不是原子操作。
如果出现只执行了第一条,第二条没机会执行就会出现「超时时间」设置失败,依然出现锁无法释放。
setnx命令迭代升级
Redis 2.6.X 之后,官方拓展了 SET 命令的参数,满足了当 key 不存在则设置 value,同时设置超时时间的语义,并且满足原子性。
SET resource_name random_value NX PX 30000
NX:表示只有 resource_name 不存在的时候才能 SET 成功,从而保证只有一个客户端可以获得锁;
PX 30000:表示这个锁有一个 30 秒自动过期时间。
我们还要防止不能释放不是自己加的锁。我们可以在 value 上做文章。
把别人的锁拿去释放掉了
1 客户 1 获取锁成功并设置设置 30 秒超时;
2 客户 1 因为一些原因导致执行很慢(网络问题、发生 FullGC……),过了 30 秒依然没执行完,但是锁过期「自动释放了」;
3 客户 2 申请加锁成功;
4 客户 1 执行完成,执行 DEL 释放锁指令,这个时候就把客户 2 的锁给释放了。
--------》有个关键问题需要解决:自己的锁只能自己来释放。《------------
我要如何删除是自己加的锁呢?
我在加锁的时候设置一个「唯一标识」作为 value 代表加锁的客户端。
SET resource_name random_value NX PX 30000
在释放锁的时候,客户端将自己的「唯一标识」与锁上的「标识」比较是否相等,匹配上则删除,否则没有权利释放锁。
伪代码如下:
// 比对 value 与 唯一标识
if (redis.get("lock:168").equals(random_value)){
redis.del("lock:168"); //比对成功则删除
}
有没有想过,这是 GET + DEL 指令组合而成的,这里又会涉及到原子性问题
我们可以通过 Lua 脚本来实现,这样判断和删除的过程就是原子操作了。
// 获取锁的 value 与 ARGV[1] 是否匹配,匹配则执行 del
if redis.call("get",KEYS[1]) == ARGV[1] then
return redis.call("del",KEYS[1])
else
return 0
end
秒杀时候,下单扣减缓存也是这样操作的
StringBuilder lua = new StringBuilder();
lua.append("if (redis.call('exists', KEYS[1]) == 1) then");
lua.append(" local stock = tonumber(redis.call('get', KEYS[1]));");
lua.append(" if (stock == -1) then");
lua.append(" return 1;");
lua.append(" end;");
lua.append(" if (stock > 0) then");
lua.append(" redis.call('incrby', KEYS[1], -1);");
lua.append(" return stock;");
lua.append(" end;");
lua.append(" return 0;");
lua.append("end;");
lua.append("return -1;");
这样通过唯一值设置成 value 标识加锁的客户端很重要,仅使用 DEL 是不安全的,因为一个客户端可能会删除另一个客户端的锁。
使用上面的脚本,每个锁都用一个随机字符串“签名”,只有当删除锁的客户端的“签名”与锁的 value 匹配的时候,才会删除它。
超时时间设置多长合适呢
这个时间不能瞎写,一般要根据在测试环境多次测试,然后压测多轮之后,比如计算出平均执行时间 200 ms。
那么锁的超时时间就放大为平均执行时间的 3~5 倍。
为啥要放放大呢?
因为如果锁的操作逻辑中有网络 IO 操作、JVM FullGC 等,线上的网络不会总一帆风顺,我们要给网络抖动留有缓冲时间。
加锁的时候设置一个过期时间,同时客户端开启一个「守护线程」,定时去检测这个锁的失效时间。
如果快要过期,但是业务逻辑还没执行完成,自动对这个锁进行续期,重新设置过期时间。
怎么实现上面这个业务呢,那就是我们今天的主角—Redisson
在使用分布式锁时,它就采用了「自动续期」的方案来避免锁过期,这个守护线程我们一般也把它叫做「看门狗」线程。
一路优化下来,方案似乎比较「严谨」了,抽象出对应的模型如下。
1 通过 SET lock_resource_name random_value NX PX expire_time,同时 启动守护线程为快要过期但还没执行完的客户端的锁续命;
2 客户端执行业务逻辑操作共享资源;
3 通过 Lua 脚本释放锁,先 get 判断锁是否是自己加的,再执行 DEL
加锁,锁的位置放哪里比较合适
根据前面的分析,我们已经有了一个「相对严谨」的分布式锁了。
于是「谢霸哥」就写了如下代码将分布式锁运用到项目中,以下是伪代码逻辑:
public void doSomething() {
redisLock.lock(); // 上锁
try {
// 处理业务
.....
redisLock.unlock(); // 释放锁
} catch (Exception e) {
e.printStackTrace();
}
}
有没有想过:一旦执行业务逻辑过程中抛出异常,程序就无法执行释放锁的流程。
所以释放锁的代码一定要放在 finally{} 块中。
加锁的位置也有问题,放在 try 外面的话,如果执行 redisLock.lock() 加锁异常,但是实际指令已经发送到服务端并执行,只是客户端读取响应超时,就会导致没有机会执行解锁的代码。
所以 redisLock.lock() 应该写在 try 代码块,这样保证一定会执行解锁逻辑。
public void doSomething() {
try {
// 上锁
redisLock.lock();
// 处理业务
...
} catch (Exception e) {
e.printStackTrace();
} finally {
// 释放锁
redisLock.unlock();
}
}
可重入锁
Redisson 类库就是通过 Redis Hash 来实现可重入锁
当线程拥有锁之后,往后再遇到加锁方法,直接将加锁次数加 1,然后再执行方法逻辑。
退出加锁方法之后,加锁次数再减 1,当加锁次数为 0 时,锁才被真正的释放。
可以看到可重入锁最大特性就是计数,计算加锁的次数。
所以当可重入锁需要在分布式环境实现时,我们也就需要统计加锁次数。
加锁逻辑
我们可以使用 Redis hash 结构实现,key 表示被锁的共享资源, hash 结构的 fieldKey 的 value 则保存加锁的次数。
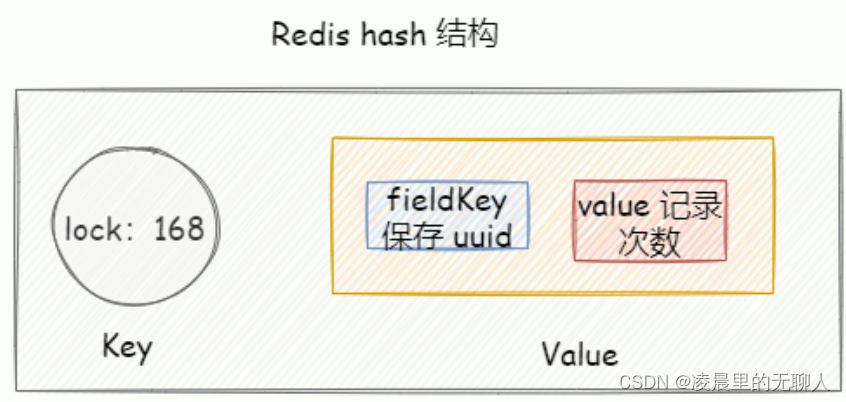
通过 Lua 脚本实现原子性,假设 KEYS1 = 「lock」, ARGV「1000,uuid」:
---- 1 代表 true
---- 0 代表 false
if (redis.call('exists', KEYS[1]) == 0) then
redis.call('hincrby', KEYS[1], ARGV[2], 1);
redis.call('pexpire', KEYS[1], ARGV[1]);
return 1;
end ;
if (redis.call('hexists', KEYS[1], ARGV[2]) == 1) then
redis.call('hincrby', KEYS[1], ARGV[2], 1);
redis.call('pexpire', KEYS[1], ARGV[1]);
return 1;
end ;
return 0;
加锁代码首先使用 Redis exists 命令判断当前 lock 这个锁是否存在。
如果锁不存在的话,直接使用 hincrby创建一个键为 lock hash 表,并且为 Hash 表中键为 uuid 初始化为 0,然后再次加 1,最后再设置过期时间。
如果当前锁存在,则使用 hexists判断当前 lock 对应的 hash 表中是否存在 uuid 这个键,如果存在,再次使用 hincrby 加 1,最后再次设置过期时间。
最后如果上述两个逻辑都不符合,直接返回。
解锁逻辑
-- 判断 hash set 可重入 key 的值是否等于 0
-- 如果为 0 代表 该可重入 key 不存在
if (redis.call('hexists', KEYS[1], ARGV[1]) == 0) then
return nil;
end ;
-- 计算当前可重入次数
local counter = redis.call('hincrby', KEYS[1], ARGV[1], -1);
-- 小于等于 0 代表可以解锁
if (counter > 0) then
return 0;
else
redis.call('del', KEYS[1]);
return 1;
end ;
return nil;
首先使用 hexists 判断 Redis Hash 表是否存给定的域。
如果 lock 对应 Hash 表不存在,或者 Hash 表不存在 uuid 这个 key,直接返回 nil。
若存在的情况下,代表当前锁被其持有,首先使用 hincrby使可重入次数减 1 ,然后判断计算之后可重入次数,若小于等于 0,则使用 del 删除这把锁。
解锁代码执行方式与加锁类似,只不过解锁的执行结果返回类型使用 Long。这里之所以没有跟加锁一样使用 Boolean ,这是因为解锁 lua 脚本中,三个返回值含义如下:
1 代表解锁成功,锁被释放
0 代表可重入次数被减 1
null 代表其他线程尝试解锁,解锁失败.
这一篇就到这里把,太长了阅读性不是很好,下一篇重点介绍Redisson
本文参考:
https://mp.weixin.qq.com/s?__biz=Mzg2MzU3Mjc3Ng==&mid=2247485064&idx=1&sn=06a9b0313707436f222a559a7e30d54e&chksm=ce77c0cff90049d975b93b6a37b9dc4bca9165872073b0ec273d1a8b02cfd4d06bc786c52c21&mpshare=1&scene=23&srcid=0820Pwg3JazA6bp0667cVWMB&sharer_sharetime=1661006754336&sharer_shareid=5e1f720976235b1e81fd0d6731dbec3a#rd

















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









