







向AI转型的程序员都关注了这个号👇👇👇
大数据挖掘DT机器学习 公众号: datayx
图片情感分析,重点是颜色特征的提取,将每一个像素点的颜色特征转换成一个值,最终效果是把一个图片转换成一个二维矩阵,矩阵中每一个值都代表该像素点的颜色特征。概括来说就是将每个像素点的RGB值转换为HSV,然后对HSV三个值进行加权求和,得出一个值来表示颜色特征,RGB值转换为HSV有标准公式,对HSV三个值进行加权求和时权值的选择参考自一篇对服装图像进行分类的论文。具体过程如下:
可以用img.load()直接提取图片每个像素点的RGB参数,但它并不直接与色调、饱和度和亮度等人的主观感觉相对应,所以还需要把RGB参数转换为HSV(色调H、饱和度S、亮度V),变换方法如下:
max= max ( R , G , B );
min= min ( R , G , B );
V= max ( R , G , B );
S= ( max – min ) / max;
if( R = max ) H = ( G – B ) / ( max – min) * 60;
if( G = max ) H = 120 + ( B – R ) / ( max– min ) * 60;
if( B = max ) H = 240 + ( R – G ) / ( max– min ) * 60;
if( H < 0 ) H = H + 360;
其中, R , G , B , S , V ∈[ 1,0 ] , H∈[ 0 , 360 ]
在HSV空间中,H从0°到360°变化时,色调依次呈现为红、橙、黄、绿、青、蓝、紫、粉。将H分量根据视觉对颜色的心理感觉,分为不相等间隔的8份,饱和度S分成2份,亮度V分成1份,并根据色彩的不同范围进行量化,当V足够小(V<0. 15时),视觉感知的颜色基本上接近黑色,可以忽略H的影响,仅需一个量化值就可以表示。当S足够小,比如说s小于0.1时,视觉感知的颜色已经基本上接近灰度图像,这时候可以忽略H的影响。量化后的色调、饱和度和亮度值分别为H, S , V:
当H的值位于330– 360以及0 – 25时,H赋值为0,代表色彩粉色;
当H的值位于25– 41时,H赋值为1,代表色彩红色;
当H的值位于41– 75时,H赋值为2,代表色彩橙色;
当H的值位于75– 156时,H赋值为3,代表色彩黄色;
当H的值位于156– 201时,H赋值为4,代表色彩绿色;
当H的值位于201–272时,H赋值为5,代表色彩青色;
当H的值位于272 – 285时,H赋值为6,代表色彩蓝色;
当H的值位于285– 330时,H赋值为7,代表色彩紫色;
当S的值位于0.1– 0.65时,S赋值为0,代表暗色;
当S的值位于0.65– 1时,S赋值为1,代表明色;
当V的值位于0.15– 1时,V赋值为0;
按照以上的量化级,把3个颜色分量合成为一维特征矢量:
L= H*Qs*Qv+ S*Qv+ V (1)
其中:Qs和Qv分别是分量S和V的量化级数,取Qs=2,Qv= 1。因此,式(1)可以表示为:
L=2H+ S+ V (2)
这样,量化后的3个分量H、S、V依式(2)合为一个值,根据式(2),L的取值范围为[0,1,… ,15]
接下来展示一下图片处理后的形态:
imgl:: 0 0 11 imgl:: 0 1 1 imgl:: 0 2 10 imgl:: 0 3 0 imgl:: 0 4 3 imgl::0 5 3
imgl:: 0 6 3 imgl:: 0 7 3 imgl:: 0 8 3 imgl:: 0 9 3 imgl::1 0 10 imgl:: 1 1 10
上面展示的是图片处理后的部分数据,以第一个imgl::0 0 11为例,imgl:::是为了展示做的标记,可以忽略,00 是像素下标,代表是第一行第一列也就是第一个像素,11代表该像素点的值,也就是进行预处理后能够体现改点颜色特征的值。全部观察来看,所有像素点的颜色特征值均处于0到15之间,符合预期。
这一部分代码实现如下:
def rgb2hsv(r, g, b):
r, g, b = r/255.0, g/255.0, b/255.0
number=500 # 总的图片数量
本文完整源码地址 ,和数据集:
关注微信公众号datayx 然后回复“情感分析”即可获取。
图像情感分析模型是基于卷积神经网络建立的,卷积神经网络的构建用了keras库
模型包括3个卷积层、2个池化层、4个激活函数层、2个Dropout层、2个全连接层、1个Flatten层和最终分类层。
图片初始化是100*100大小,卷积层卷积核的个数都是32个,大小是13*13,经过三层卷积和两层池化,每张图片处理为4*4大小,经Flatten层压扁成一维进入全连接层,第一个全连接层指定了128个神经元,进入Dropout层,目的是为了防止过拟合,当然在Flatten层之前还有一个Dropout层,最后是一个全连接层和一个分类层,激活函数层伴随着每一个卷积层之后和第一个全连接层之后。模型训练迭代次数选择13次。
具体实现过程如图1所示:
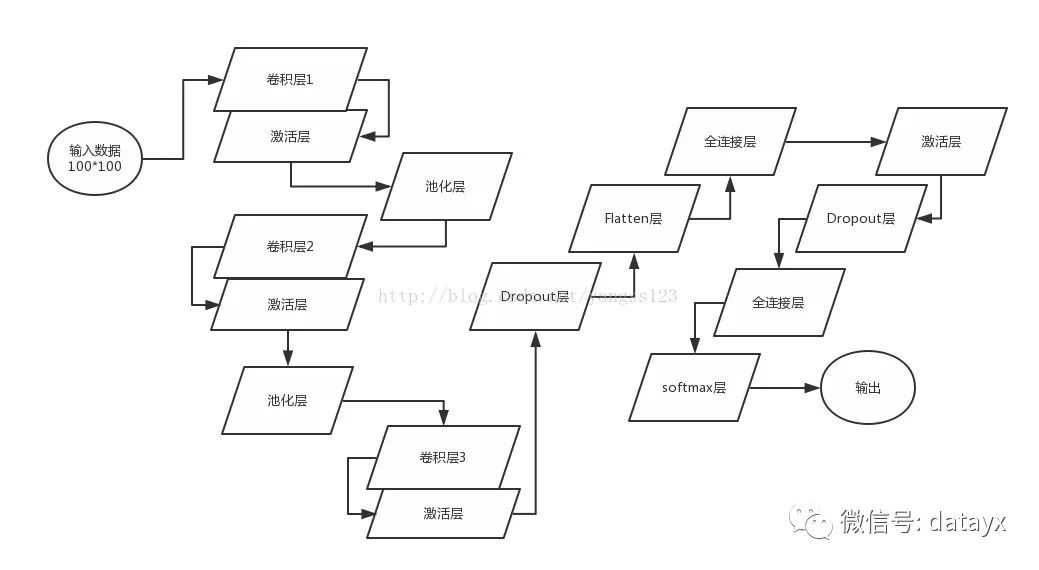
图1 图像情感分析模型
建立模型
卷积层:主要是Convolution2D()函数。2D代表这是一个2维卷积,其功能为对2维输入进行卷积计算。我们的图像数据尺寸为100 * 100,所以在这里需要使用2维卷积函数计算卷积。所谓的卷积计算,其实就是利用卷积核逐个像素、顺序进行计算,简化过程如图2:
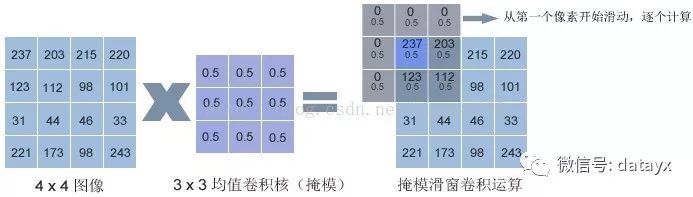
图2 卷积计算
上图中事例是保留边界像素算法,也就是卷积过后和原图像大小一致,处理边界值过程中,如果部分区域越界,就可以用0进行填充。计算过程中,将卷积核中心对准图像第一个像素,在这里就是像素值为237的那个像素。卷积核覆盖的区域,其下所有像素取均值然后相加:
C(1)= 0 * 0.5 + 0 * 0.5 + 0 * 0.5 + 0 *0.5 + 237 * 0.5 + 203 * 0.5 + 0 * 0.5 + 123 * 0.5 + 112 * 0.5
通过类似的计算,将计算结果作为原来像素点处的特征学习值,接着学习下一个卷积核中心覆盖的像素点,直到所有像素点都被学习完。在这个过程中,卷积核依次覆盖所有像素点,最终结果还是得到一个二维矩阵,是学习过的图像。二维矩阵可以和原矩阵大小相同,也可以不相同,这取决于是否保留边界,保留边界的话会得到一个大小相同的矩阵图像,若丢掉边界像素,那么在卷积过程中就会以卷积核覆盖区域不越界的像素开始计算。如图3.8所示,如果选择丢掉图像边界特征,卷积核就会从(2,2)像素点开始卷积计算,到(3,3)像素点结束计算,这样得到的是一个2 * 2的矩阵表示的图像。在本次毕设的模型中,卷积层采用丢掉边界特征的方式来处理图像边界:

第一个卷积层包含32个卷积核,每个卷积核大小为13 * 13, 值为“same”意味着我们采用保留边界特征的方式进行卷积计算,而值“valid”则代表丢掉边界像素。图像经过第一层卷积层,大小变为32* 88 * 88大小。
激活函数层:以relu(Rectified Linear Units,修正线性单元)函数为例,它的数学形式如下:
f(x)=max(0,x)
这个函数非常简单,小于0的输入,输出全部为0,大于0的则输出与输入相等。该函数的优点是收敛速度快,对于不同的需求,我们可以选择不同的激活函数,一般的激活函数包括:softplus、softsign、tanh、sigmoid、hard_sigmoid、linear,激活函数层属于人工神经元的一部分,所以我们可以在构造层对象时通过传递activation参数设置。
池化层:可以缩小输入的特征图,简化网络计算复杂度,而且能够进行特征压缩,突出主要特征。我们通过调用MaxPooling2D()函数建立池化层,这个函数采用最大值池化法,这个方法选取覆盖区域的最大值作为区域主要特征组成新的缩小后的特征图,具体过程简化后如图3所示:
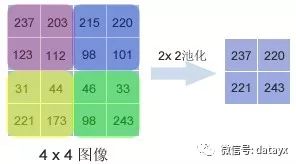
图3 池化过程
池化层最重要的地方是可以降低维度,因为它是将最大值作为此学习范围的输出,所以能够保留住此范围里的显著特征,虽然只能知道显著特征是什么,却得不到显著特征的发生位置,但很多问题不需要我们得到具体位置,只需要知道这一区域学习的最大特征。由此池化层能够为图像识别提供平移和旋转不变性。即使图像平移或旋转几个像素,得到的输出值也基本一样,因为每次最大值运算得到的结果总是一样的。经过第一层池化层,图片数据变为32* 44 * 44。采用maxpooling,poolsize为(2,2)。代码如下:
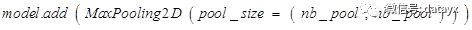
Dropout 层:随机断开一定百分比的输入神经元连接,以防止过拟合。过拟合意思是训练数据预测准确率很高,测试数据预测准确率很低,用图形表示就是拟合曲线较尖,不平滑。导致这种现象的原因是模型的参数很多,但训练样本太少,导致模型拟合过度。为了解决这个问题,Dropout 层将随机减少模型参数,让模型变得简单,而越简单的模型越不容易产生过拟合。代码中Dropout ()函数只有一个输入参数,即指定抛弃比率,范围为0~1之间的浮点数,其实就是百分比。这个参数亦是一个可调参数,我们可以根据训练结果调整它以达到更好的模型成熟度。本次模型中,比率选择是0.5。
Flatten层:截止到Flatten层之前,在网络中流动的数据还是多维的(对于我们的程序就是2维的),经过多次的卷积、池化、 之后,到了这里就可以进入全连接层做最后的处理了。全连接层要求输入的数据必须是一维的,因此,我们必须把输入数据“压扁”成一维后才能进入全连接层,Flatten层的作用即在于此。
全连接层 :全连接层的作用就是用于分类或回归,对于我们来说就是分类。keras将全连接层定义为Dense层,其含义就是这里的神经元连接非常“稠密”。我们通过Dense()函数来定义全连接层。这个函数的一个必填参数就是神经元个数,其实就是指定该层有多少个输出。在我们的代码中,第一个全连接层指定了512个神经元,也就是保留了512个特征输出到下一层。添加512节点的全连接并且进行激活,激活函数用relu。再经过一层Dropout层,防止过拟合。添加输出2个节点,经过softmax层,进行输出。

搜索公众号添加: datayx
不断更新资源
深度学习、机器学习、数据分析、python

长按图片,识别二维码,点关注














 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









