







向AI转型的程序员都关注了这个号👇👇👇
机器学习AI算法工程 公众号: datayx
▌短时记忆

梯度更新规则
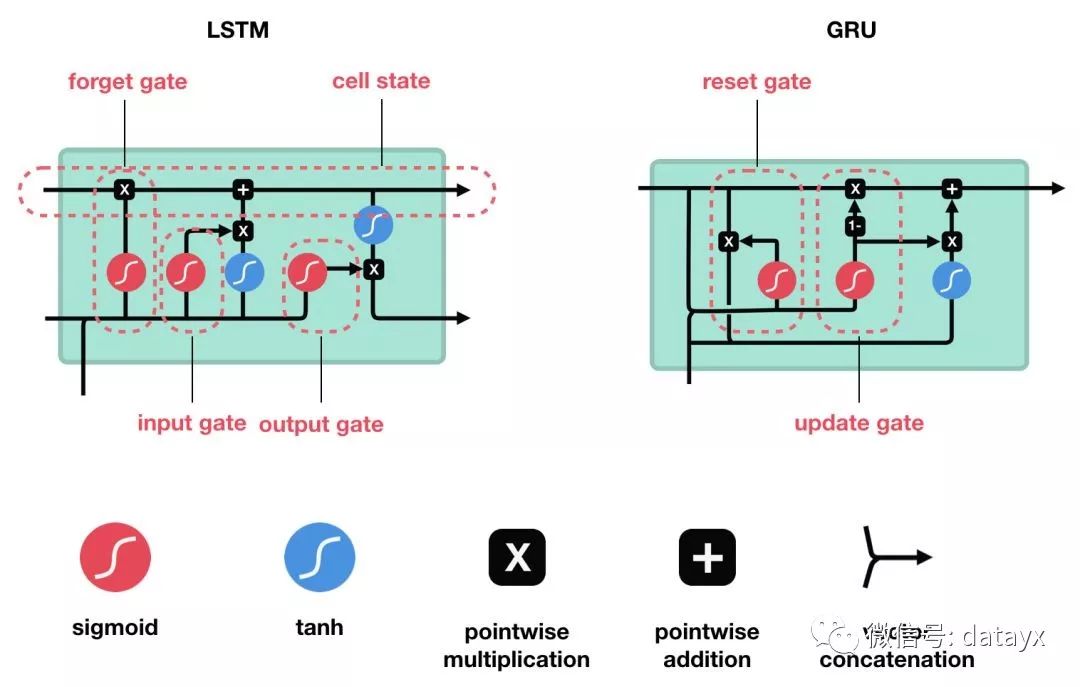
▌作为解决方案的 LSTM 和 GRU
AI项目体验地址 https://loveai.tech
本质
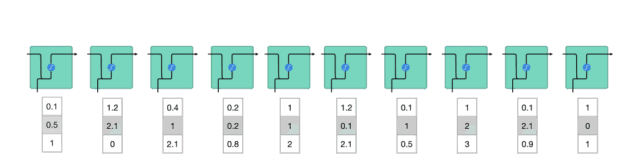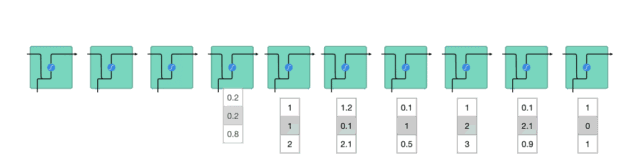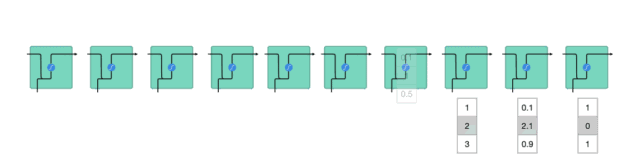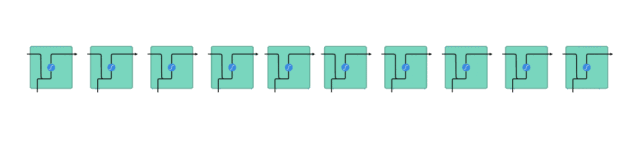
将隐藏状态传递给下一个时间步
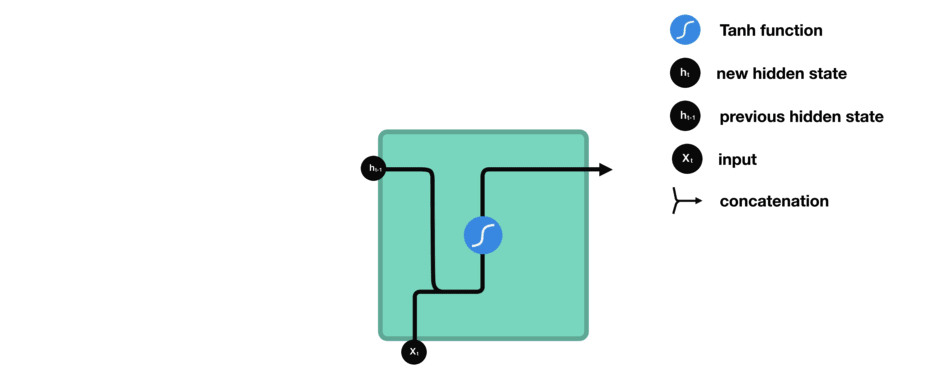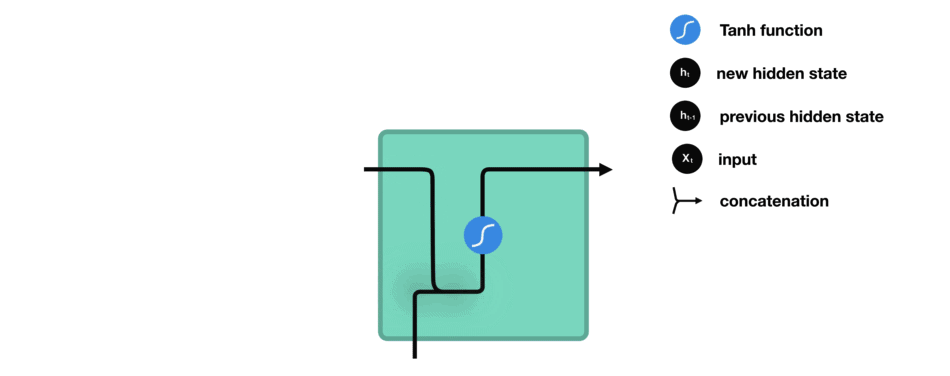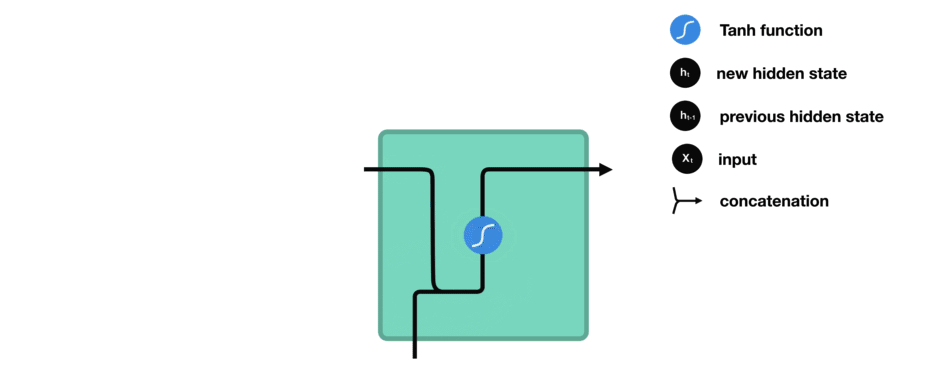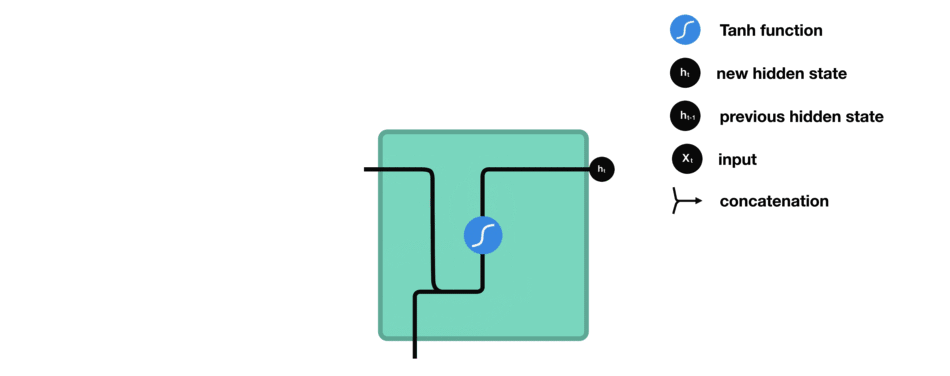
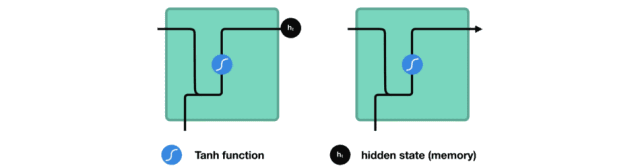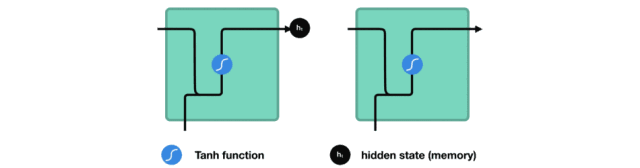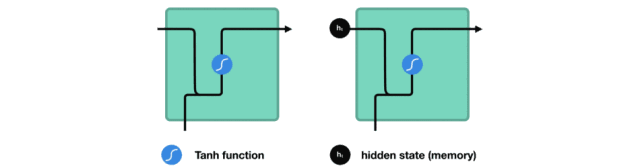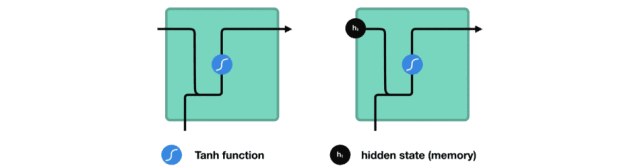
RNN 细胞
激活函数 Tanh
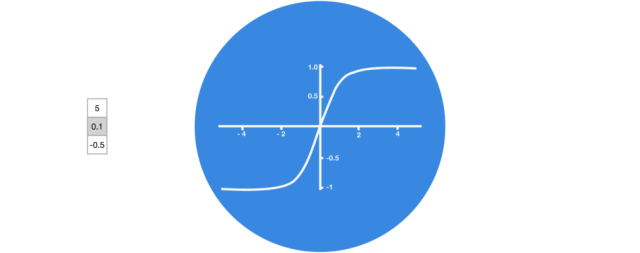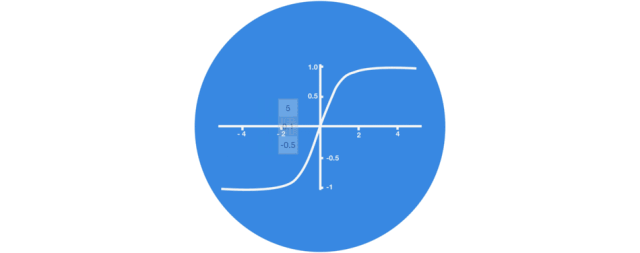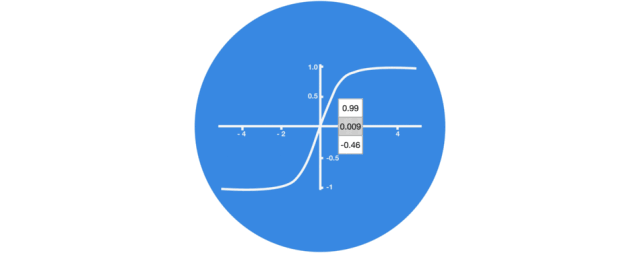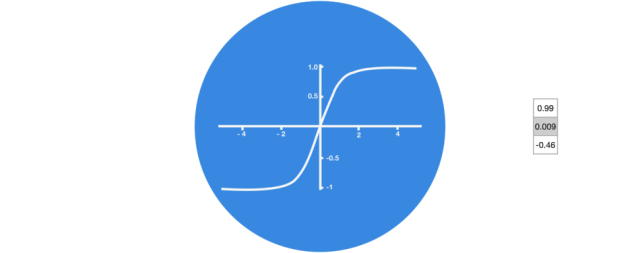

没有 tanh 函数的向量转换

有 tanh 函数的向量转换
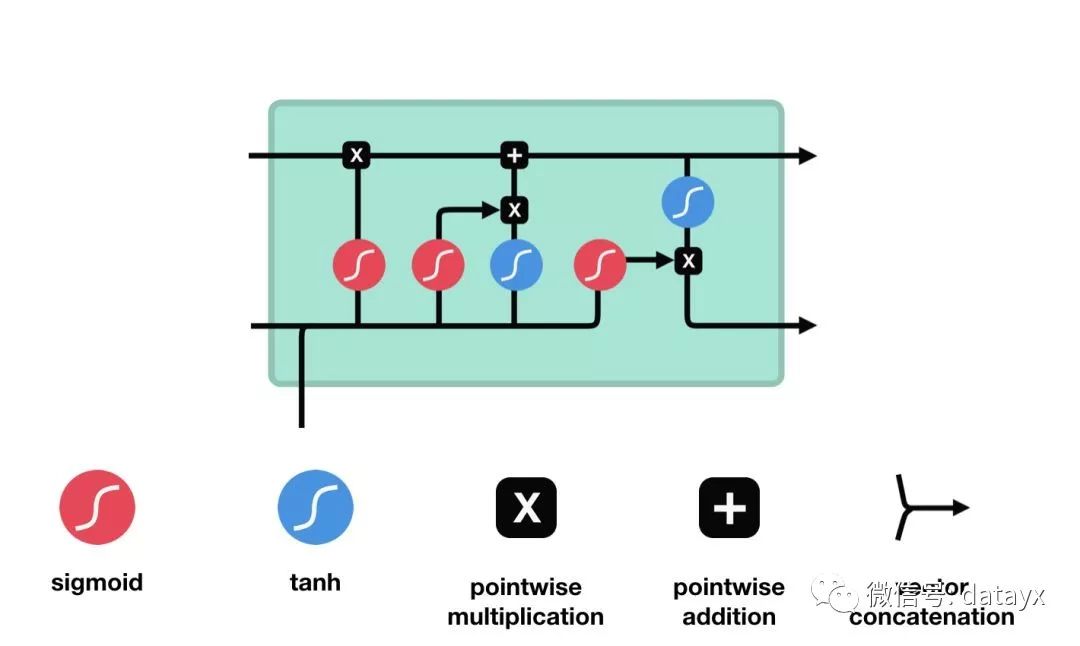
LSTM 的细胞结构和运算
核心概念
Sigmoid
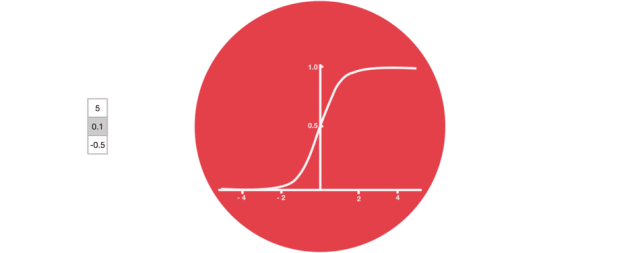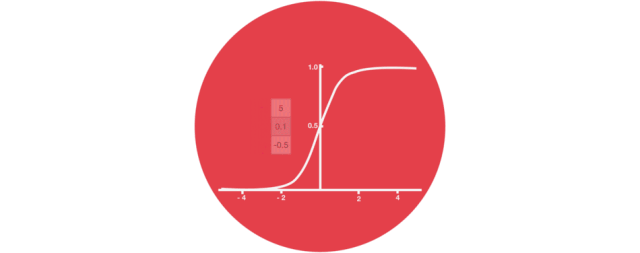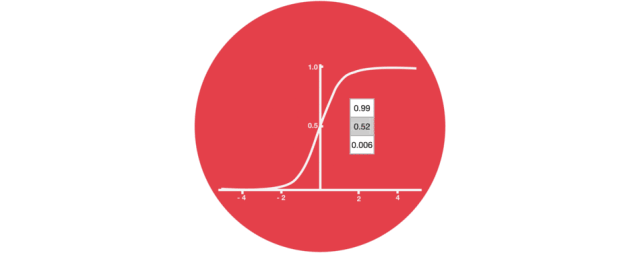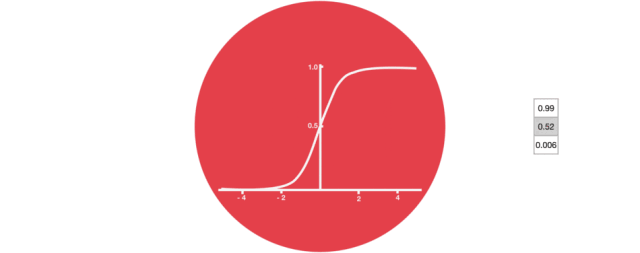
Sigmoid 将值压缩到 0~1 之间遗忘门
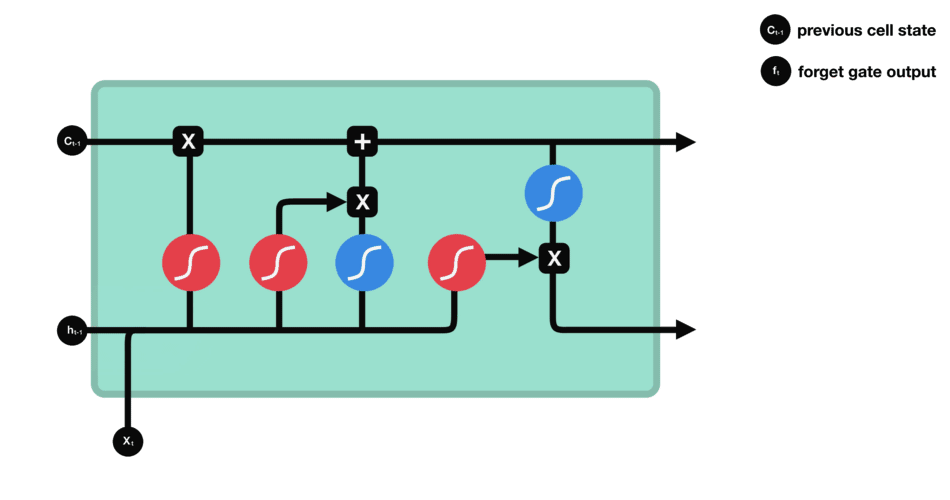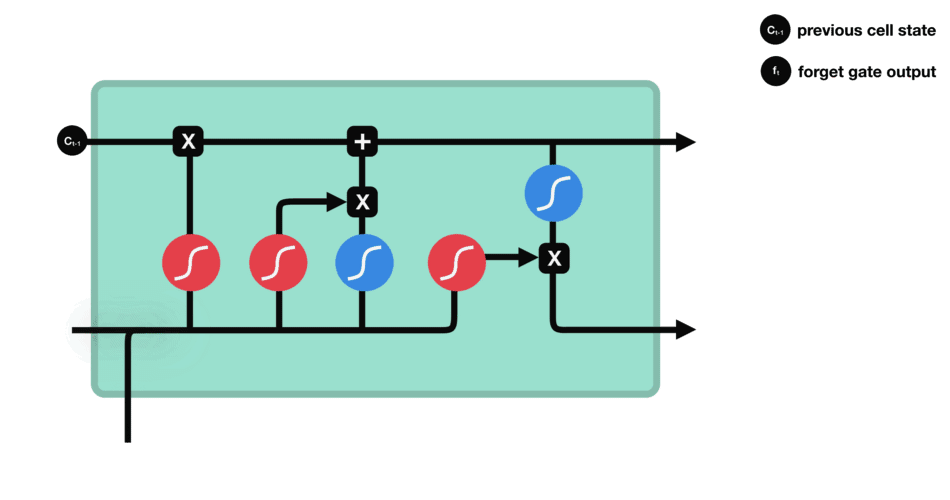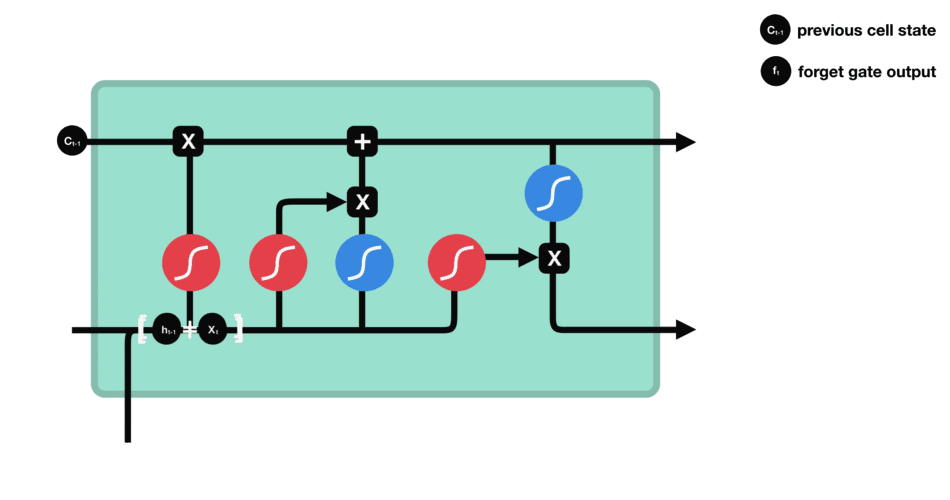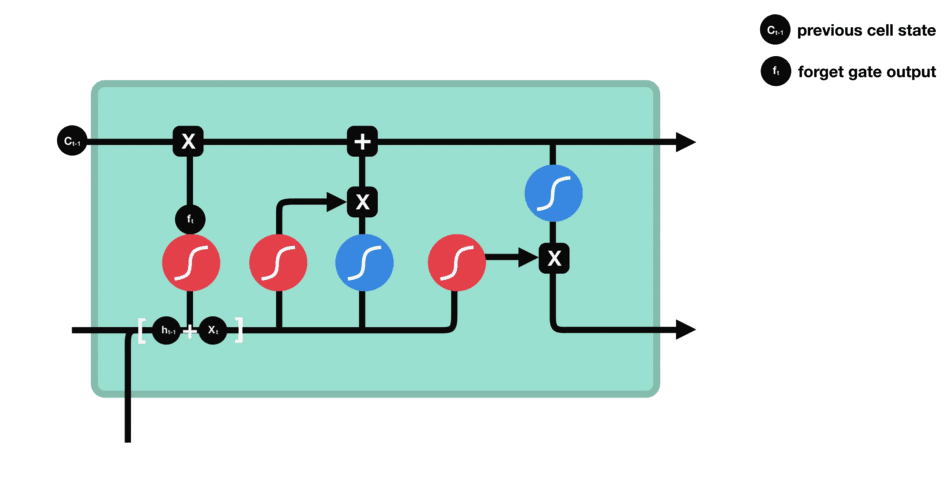 输入门
输入门

输入门的运算过程细胞状态
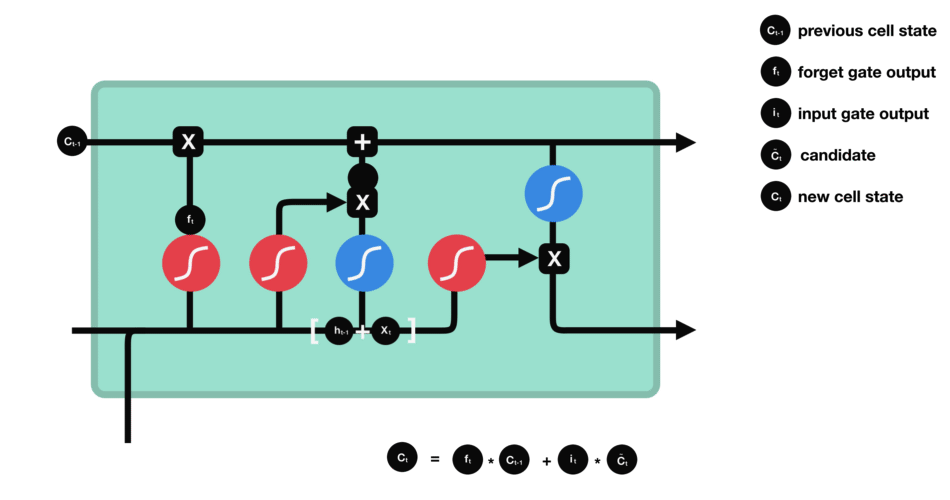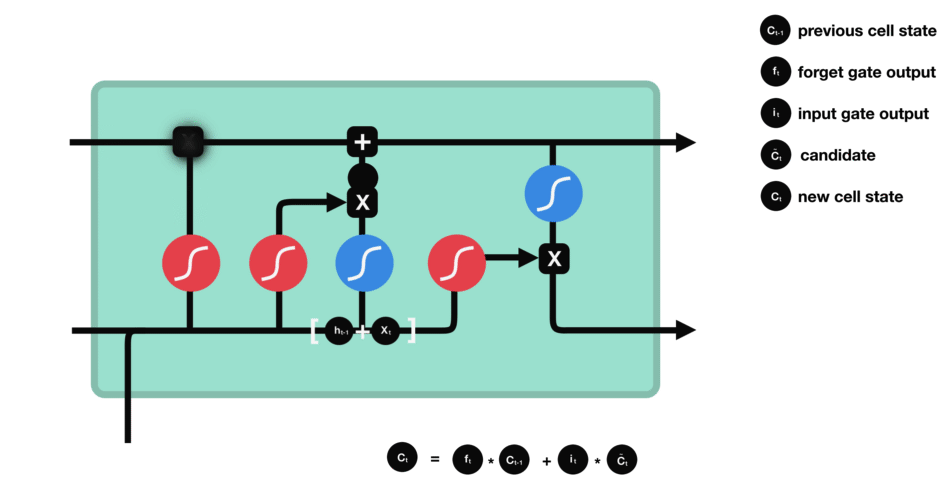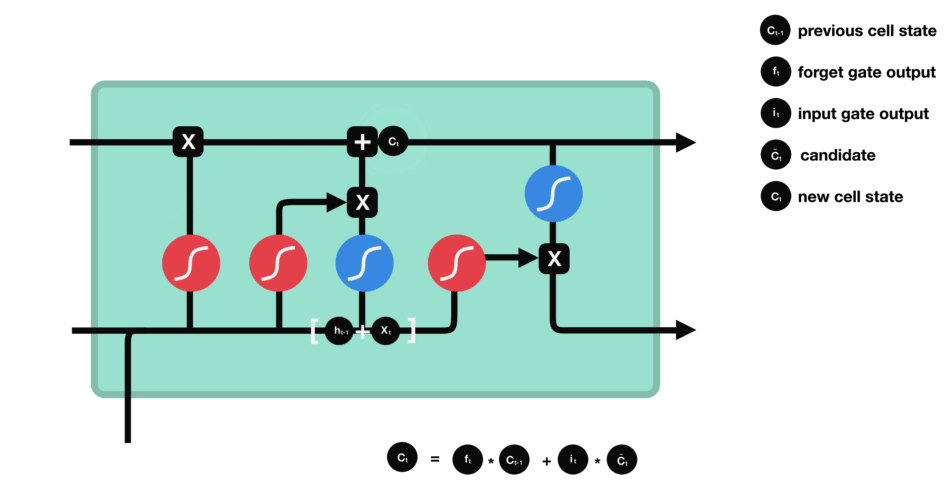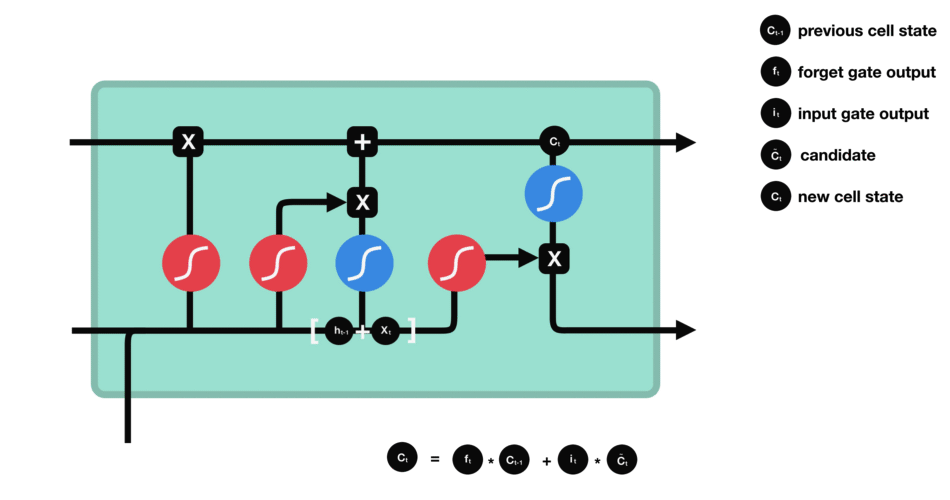
细胞状态的计算输出门
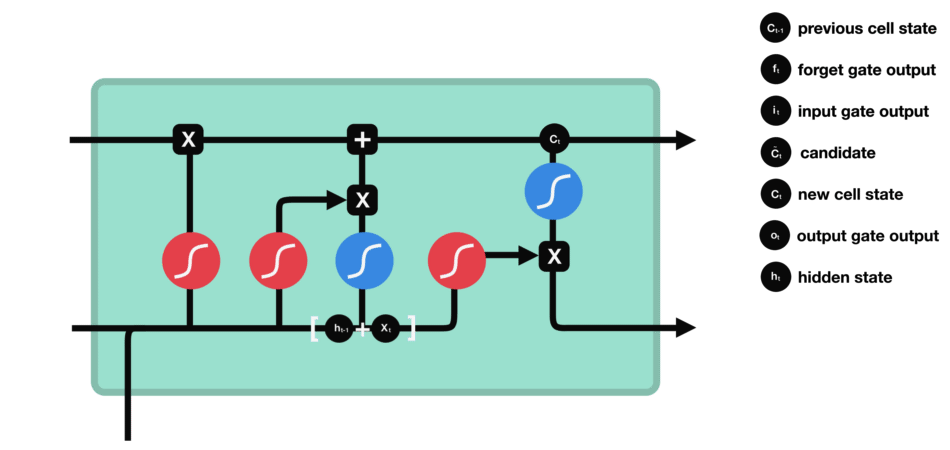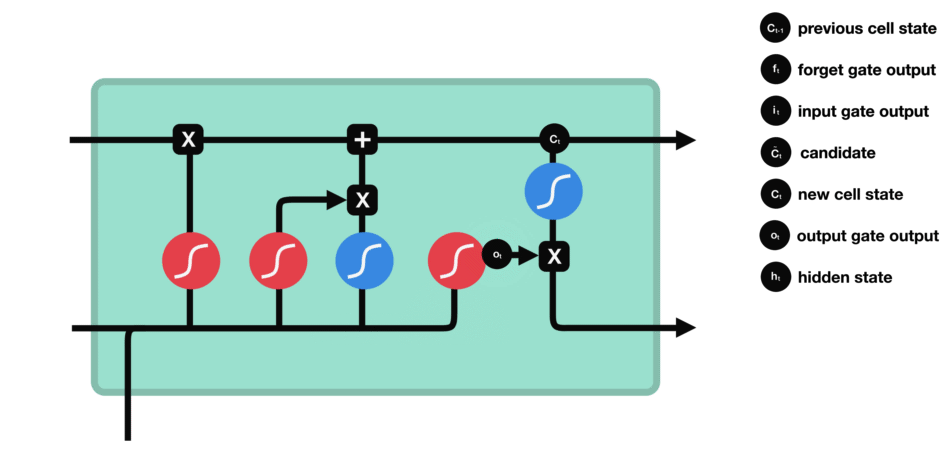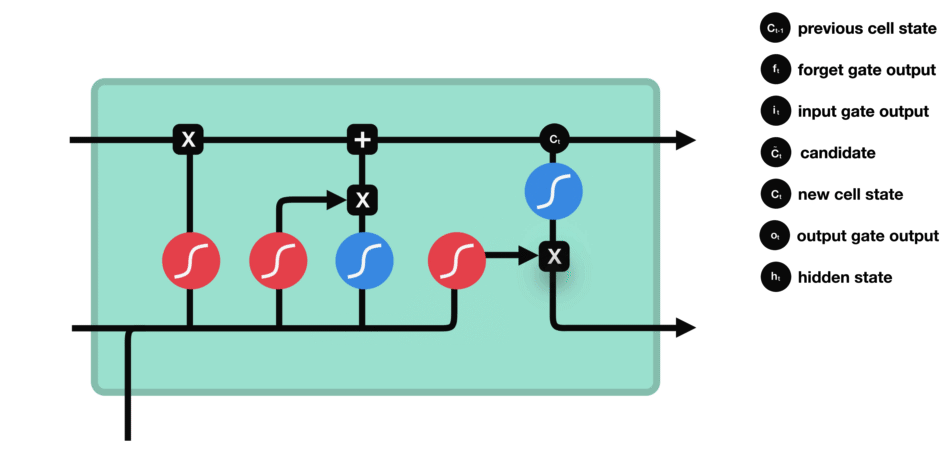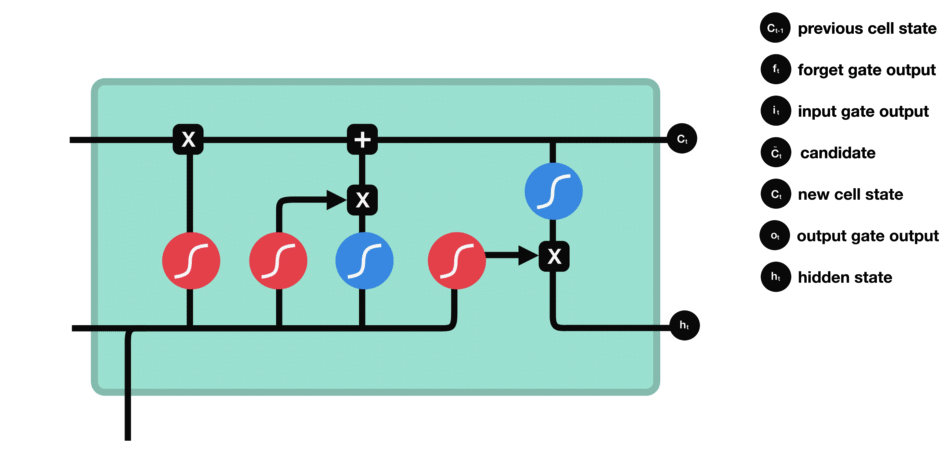
输出门的运算过程
代码示例
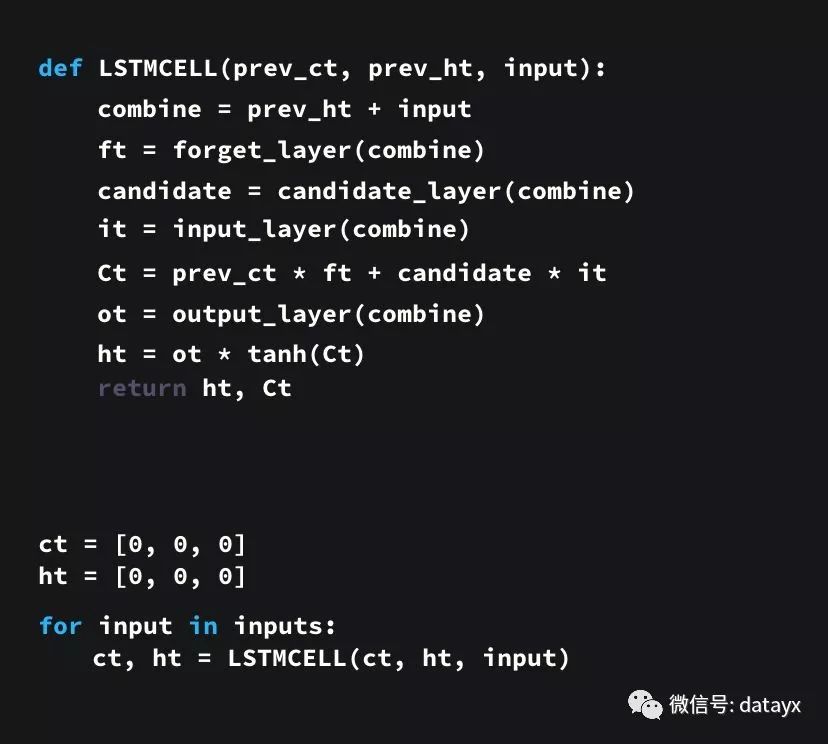
python 写的伪代码
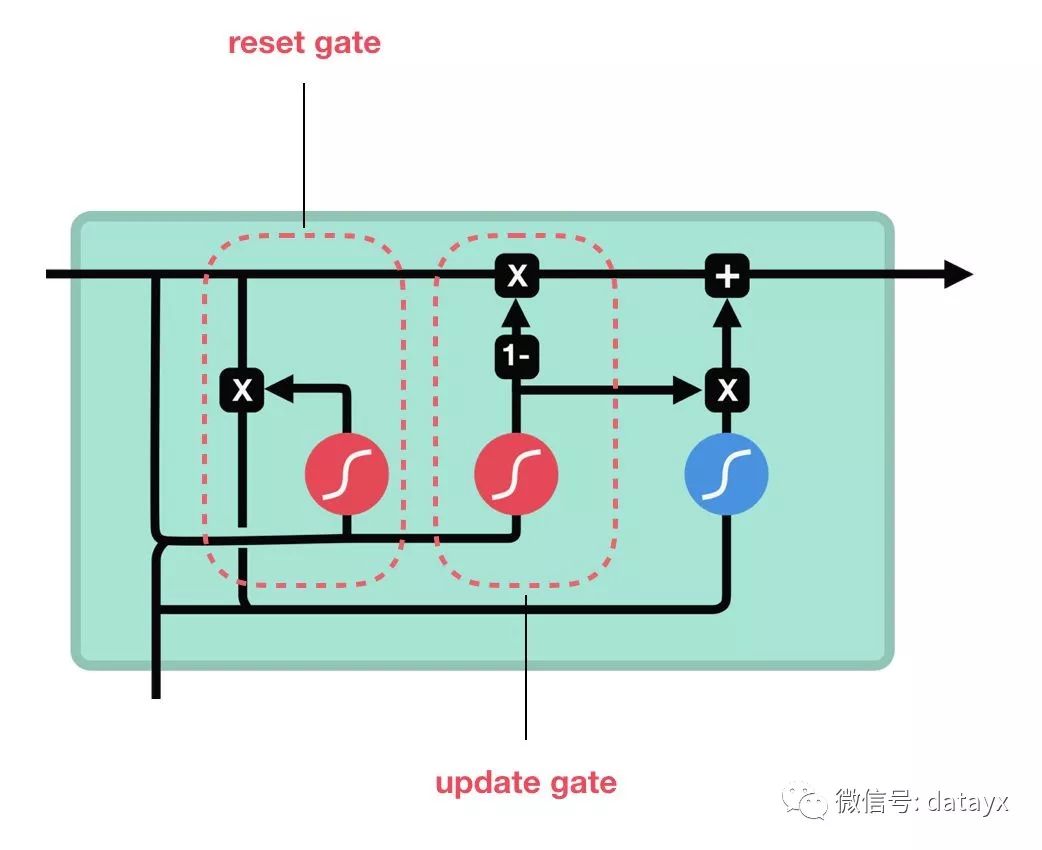
GRU 的细胞结构和门结构
更新门重置门https://towardsdatascience.com/illustrated-guide-to-lstms-and-gru-s-a-step-by-step-explanation-44e9eb85bf21
阅读过本文的人还看了以下:
不断更新资源
深度学习、机器学习、数据分析、python
搜索公众号添加: datayx

长按图片,识别二维码,点关注
AI项目体验
https://loveai.tech















 2561
2561











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









