







向AI转型的程序员都关注了这个号👇👇👇
机器学习AI算法工程 公众号:datayx
虽然说做文本不像图像对gpu依赖这么高,但是当需要训练一个大模型或者拿这个模型做预测的时候,也是耗费相当多资源的,尤其是BERT出来以后,不管做什么用BERT效果都能提高,万物皆可BERT。
然而想要在线上部署应用,大公司倒还可以烧钱玩,毕竟有钱任性,小公司可玩不起,成本可能都远大于效益。这时候,模型压缩的重要性就体现出来了,如果一个小模型能够替代大模型,而这个小模型的效果又和大模型差不多,何乐而不为。
在讲知识蒸馏时一定会提到的Geoffrey Hinton开山之作Distilling the Knowledge in a Neural Network当然也是在图像中开的山,下面简单做一个介绍。
知识蒸馏使用的是Teacher—Student模型,其中teacher是“知识”的输出者,student是“知识”的接受者。知识蒸馏的过程分为2个阶段:
1.原始模型训练: 训练"Teacher模型", 它的特点是模型相对复杂,可以由多个分别训练的模型集成而成。
2.精简模型训练: 训练"Student模型", 它是参数量较小、模型结构相对简单的单模型。
模型结构
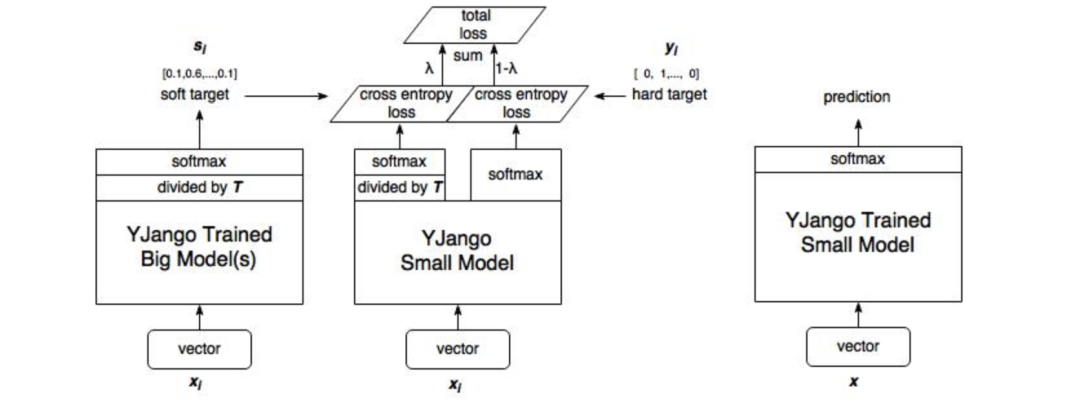
借用YJango大佬的图,这里我简单解释一下我们怎么构建这个模型
1.训练大模型
首先我们先对大模型进行训练,得到训练参数保存,这一步在上图中并未体现,上图最左部分是使用第一步训练大模型得到的参数。
2. 计算大模型输出
训练完大模型之后,我们将计算soft target,不直接计算output的softmax,这一步进行了一个divided by T蒸馏操作。(注:这时候的输入数据可以与训练大模型时的输入不一致,但需要保证与训练小模型时的输入一致)
3. 训练小模型
小模型的训练包含两部分。
-soft target loss
-hard target loss
通过调节λ的大小来调整两部分损失函数的权重。
4. 小模型预测
预测就没什么不同了,按常规方式进行预测。
代码 获取方式:
关注微信公众号 datayx 然后回复 知识蒸馏 即可获取。
模型实现
模型基本上是对论文Distilling Task-Specific Knowledge from BERT into Simple Neural Networks的复现,下面介绍部分代码实现
代码结构
Teacher模型:BERT模型
Student模型:一层的biLSTM
LOSS函数:交叉熵 、MSE LOSS
知识函数:用最后一层的softmax前的logits作为知识表示
学生模型输入
Student模型的输入句向量由句中每一个词向量求和取平均得到,词向量为预训练好的300维中文向量,训练数据集为Wikipedia_zh中文维基百科。

学生模型结构
学生模型为单层biLSTM,再接一层全连接。

教师模型结构
教师模型为BERT,并对最后四层进行微调,后面也接了一层全连接。

损失函数
损失函数为学生输出s_logits和教师输出t_logits的MSE损失与学生输出与真实标签的交叉熵。

模型效果
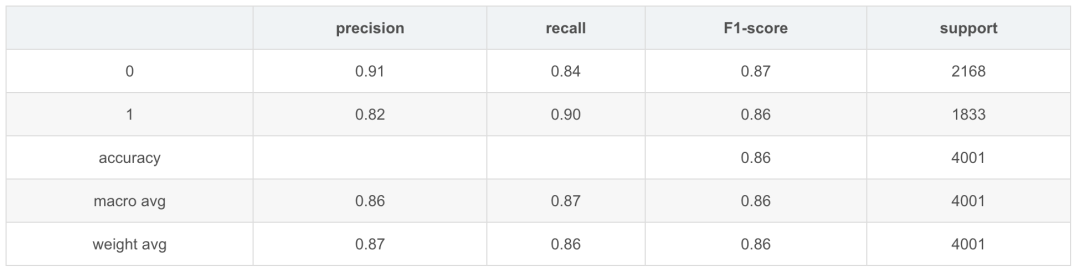
Teacher
Running time: 116.05915258956909 s
Student
Running time: 0.155623197555542 s
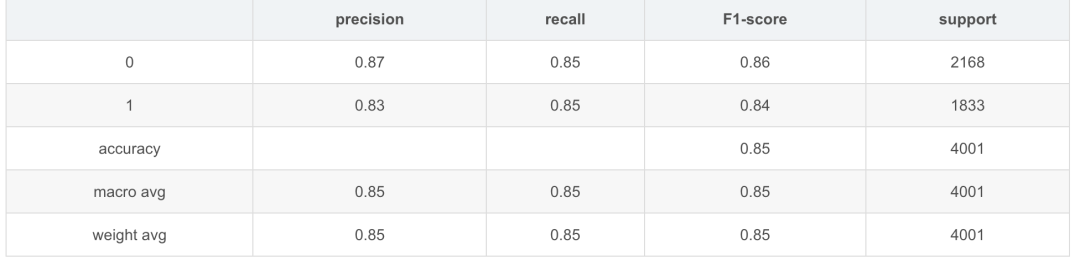
可以看出student模型与teacher模型相比精度有一定的丢失,这也可以理解,毕竟student模型结构简单。而在运行时间上大模型是小模型的746倍(cpu)。
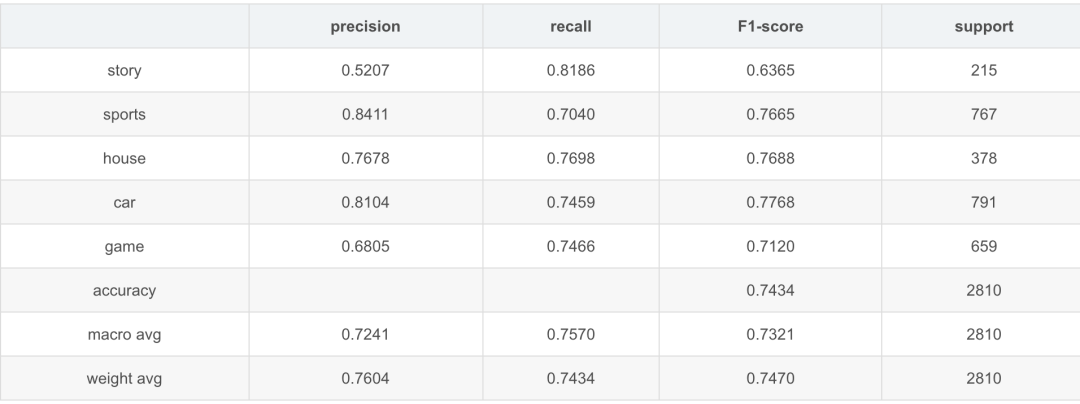
TNEWS测试效果
在数据集中选了5类并做了下采样。(此部分具体说明后续完善)
Student alone
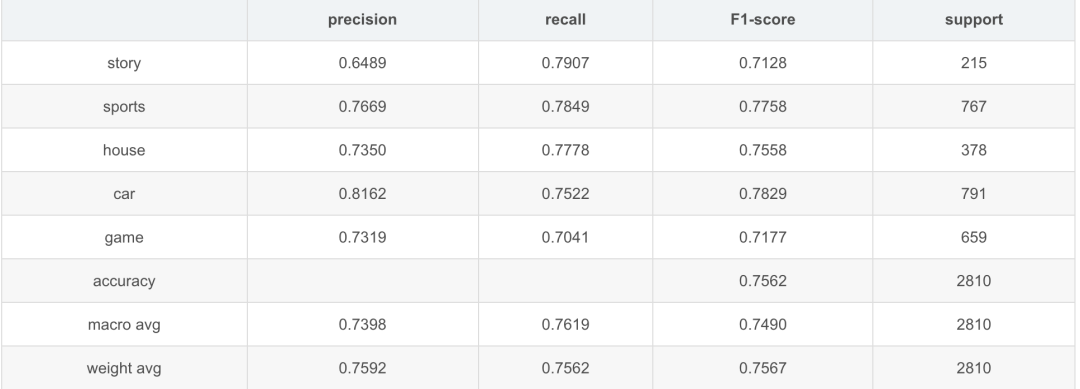
Teacher

Student
机器学习算法AI大数据技术
搜索公众号添加: datanlp

长按图片,识别二维码
阅读过本文的人还看了以下文章:
基于40万表格数据集TableBank,用MaskRCNN做表格检测
《深度学习入门:基于Python的理论与实现》高清中文PDF+源码
2019最新《PyTorch自然语言处理》英、中文版PDF+源码
《21个项目玩转深度学习:基于TensorFlow的实践详解》完整版PDF+附书代码
PyTorch深度学习快速实战入门《pytorch-handbook》
【下载】豆瓣评分8.1,《机器学习实战:基于Scikit-Learn和TensorFlow》
李沐大神开源《动手学深度学习》,加州伯克利深度学习(2019春)教材
【Keras】完整实现‘交通标志’分类、‘票据’分类两个项目,让你掌握深度学习图像分类
如何利用全新的决策树集成级联结构gcForest做特征工程并打分?
Machine Learning Yearning 中文翻译稿
斯坦福CS230官方指南:CNN、RNN及使用技巧速查(打印收藏)
中科院Kaggle全球文本匹配竞赛华人第1名团队-深度学习与特征工程
不断更新资源
深度学习、机器学习、数据分析、python
搜索公众号添加: datayx



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









