







向AI转型的程序员都关注公众号 机器学习AI算法工程
在金融行业中,财报分析是帮助企业和投资者做出决策的关键环节。随着科技的快速发展,自动化、智能化的财报分析变得越来越重要。传统的人工财报分析不仅费时费力,而且容易受到人为错误的影响,因此企业急需借助先进的技术来提高效率和准确性。TextIn平台与DeepSeek R1 API 的结合,提供了一种高效、智能的财报分析解决方案,极大地提高了财报处理的自动化水平,助力企业做出精准决策。
一、TextIn的精准文档OCR解析技术
1. TextIn平台介绍
TextIn平台是一款基于OCR(光学字符识别)技术的智能文档解析工具,能够高效提取文档中的结构化数据。特别是在财报分析中,TextIn的OCR技术能够精准识别财务报表中的表格和文本,并将其转换为可处理的Markdown格式。这样,企业不仅可以避免人工输入带来的错误,还可以大大提升财报处理的速度和准确性。
2. 王牌功能:通用文档解析
TextIn的通用文档解析功能,特别适用于PDF格式的财报文件,通过高度优化的算法,它可以高效地从扫描的财务报表中提取关键信息。其主要特点包括:
高精度OCR识别:TextIn能够准确识别PDF中的文本内容和表格数据,避免手动录入的繁琐。
结构化数据输出:解析后,TextIn将财报中的表格和数据转化为结构化的Markdown格式,便于进一步处理和分析。
3. API调用通用文档解析接口
我们可以访问合合信息的控制台免费开通API的调用权限。首次开通有1000页额度赠送!
然后我们去通用文档解析的API调试窗口进行调试。
上传测试文件,得到返回结果。
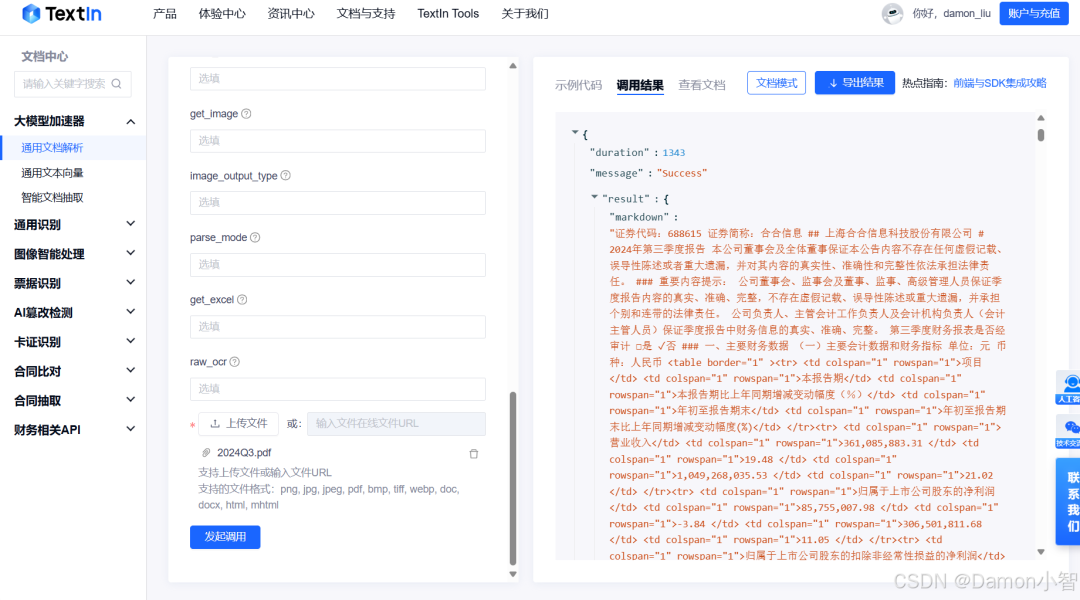
通过通用文档解析功能,TextIn为财务数据的自动提取和后续处理提供了坚实的基础。
欢迎体验文档解析
https://cc.co/16YSQ3
二、DeepSeek R1:深度AI分析财务数据
在获取财务数据后,下一步便是进行智能化分析。这正是DeepSeek R1的强项,作为一款基于AI的财务分析工具,DeepSeek能够基于提取的数据自动进行深度分析,识别出财务报表中的关键风险、亮点和估值建议,帮助决策者做出明智的选择。
1. 获取DeepSeek-API的调用凭证
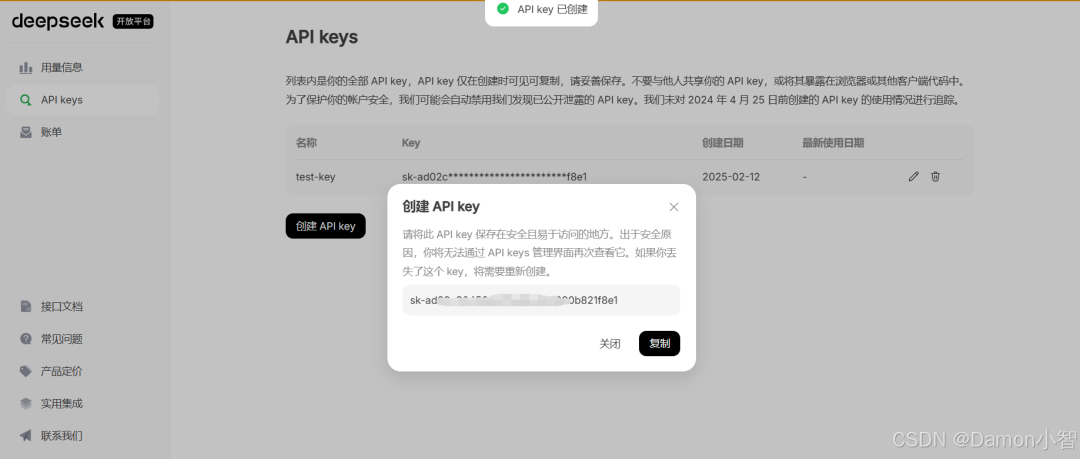
首先,我们要注册DeepSeek,注册完成后,进入API keys控制台创建token。
复制保存API Key
2. 通过API调用DeepSeek大模型
编写Python代码测试调用。
from openai import OpenAIclient = OpenAI(api_key="<DeepSeek API Key>", base_url="https://api.deepseek.com")
# Round 1messages = [{"role": "user", "content": "9.11 and 9.8, which is greater?"}]response = client.chat.completions.create( model="deepseek-reasoner", messages=messages)
reasoning_content = response.choices[0].message.reasoning_contentcontent = response.choices[0].message.content
# Round 2messages.append({'role': 'assistant', 'content': content})messages.append({'role': 'user', 'content': "How many Rs are there in the word 'strawberry'?"})response = client.chat.completions.create( model="deepseek-reasoner", messages=messages)# ...DeepSeek R1通过与合合信息TextIn平台的结合,能够全面处理从财报中提取出来的数据,并生成详细的分析报告。这些报告不仅涵盖了财务风险、业务增长亮点,还提供了估值建议,为投资决策提供了重要参考。
三、TextIn API结合DeepSeek R1的实践用例
1. 文档上传与处理
合合信息TextIn通过其强大的OCR技术,将上传的财务报表(通常为PDF格式)进行识别。用户只需上传财报文件,TextIn会自动将其中的文本和表格数据提取出来,并以Markdown格式输出。此时,财务数据已经被转化为结构化的信息,为后续分析做好了准备。
# 接收文件并保存file = request.files.get('file')if not file or not file.filename.lower().endswith('.pdf'): return jsonify(error="请选择正确的PDF文件"), 400filename = secure_filename(file.filename)filepath = os.path.join(app.config['UPLOAD_FOLDER'], filename)file.save(filepath)2. 财务数据解析与提取
通过调用合合信息TextIn的接口,系统将PDF文件转化为Markdown格式。这个过程将财报中的表格、数据等信息结构化,便于后续分析。
# 调用合合信息TextIn接口进行PDF解析resp = textin_client.recognize_pdf2md(filepath, { 'page_start': 0, 'page_count': 1000, # 设置解析页数为1000页 'table_flavor': 'md', 'parse_mode': 'scan', # 设置解析模式为scan模式 'page_details': 0, # 不包含页面细节 'markdown_details': 1, 'apply_document_tree': 1, 'dpi': 144 # 分辨率设置为144 dpi})financial_data = json.loads(resp.text)['result']['markdown']3. 财务数据分析与报告生成
一旦数据被成功提取,DeepSeek R1将分析这些数据,并生成详细的财务分析报告。DeepSeek R1不仅仅是一个简单的数据计算工具,它还运用深度学习技术对数据进行上下文分析,识别潜在的财务风险、突出增长亮点和给出估值建议。
# 使用DeepSeek进行AI分析analysis = deepseek_client.analyze_financials(financial_data)通过AI分析,DeepSeek R1返回了一份内容丰富、结构清晰的报告,分析报告以Markdown格式展示财务风险、增长亮点和估值建议等内容。
# 结构化分析结果html_content = convert_markdown_to_html(analysis)4. 结果展示
生成的分析报告将展示给用户,帮助他们快速了解财报的关键信息。报告中包括:
风险点:DeepSeek R1会自动标记出财报中的主要风险,帮助决策者识别潜在问题。
增长亮点:在报告中突出财务数据中的增长亮点,帮助企业发现未来的业务机会。
估值建议:DeepSeek还会根据财报数据给出估值建议,帮助投资者评估企业的市场价值
<!-- 渲染财报分析结果 --><div id="analysisResult"> <h3>🚨 三大核心风险点</h3> <ol> <li> <p><strong>净利润增速放缓</strong><br> 第三季度归母净利润同比下降3.84%(扣非后-7.84%),与营收增长(+19.48%)背离,显示成本压力(研发、销售费用激增)或市场竞争加剧。</p> </li> <!-- ... --> </ol> <hr> <h3>💡 三大增长亮点</h3> <ol> <!-- ... --> </ol> <hr> <h3>📈 估值建议</h3> <ol> <!-- ... --> </ol></div>四、完整案例
1. 案例完整代码
① app.py
# -*- coding: utf-8 -*-
# app.pyfrom flask import Flask, render_template, request, jsonifyimport osimport jsonfrom werkzeug.utils import secure_filenameimport requestsimport pandas as pdfrom openai import OpenAIimport loggingfrom datetime import datetimeimport markdownimport re
def get_file_content(filePath): with open(filePath, 'rb') as fp: return fp.read()
class TextinOcr(object): def __init__(self, app_id, app_secret): self._app_id = app_id self._app_secret = app_secret self.host = 'https://api.textin.com'
def recognize_pdf2md(self, image_path, options, is_url=False): """ pdf to markdown :param options: request params :param image_path: string :param is_url: bool :return: response options = { 'pdf_pwd': None, 'dpi': 144, # 设置dpi为144 'page_start': 0, 'page_count': 1000, # 设置解析的页数为1000页 'apply_document_tree': 0, 'markdown_details': 1, 'page_details': 0, # 不包含页面细节信息 'table_flavor': 'md', 'get_image': 'none', 'parse_mode': 'scan', # 解析模式设为scan } """ url = self.host + '/ai/service/v1/pdf_to_markdown' headers = { 'x-ti-app-id': self._app_id, 'x-ti-secret-code': self._app_secret } if is_url: image = image_path headers['Content-Type'] = 'text/plain' else: image = get_file_content(image_path) headers['Content-Type'] = 'application/octet-stream'
return requests.post(url, data=image, headers=headers, params=options)
class FinancialAnalyst: def __init__(self, api_key): self.client = OpenAI( api_key=api_key, base_url="https://api.deepseek.com", )
def analyze_financials(self, financial_data): """ 执行深度财务分析(使用官方SDK) """ prompt = f"""你是一位顶级证券分析师,请根据以下财务数据进行专业分析: {financial_data} 要求用中文输出: 1. 三个最重要的风险点(用🚨标记) 2. 三个最突出的增长亮点(用💡标记) 3. 估值建议(用📈标记) 格式要求:Markdown列表,每个分类最多3条"""
try: response = self.client.chat.completions.create( model="deepseek-reasoner", messages=[ {"role": "system", "content": "你是拥有20年经验的证监会持牌财务分析师,擅长发现数据背后的商业逻辑"}, {"role": "user", "content": prompt} ], temperature=0.2, max_tokens=2000 ) return response.choices[0].message.content except Exception as e: return f"⚠️ 分析失败:{str(e)}"
app = Flask(__name__)app.config['UPLOAD_FOLDER'] = './uploads'app.config['MAX_CONTENT_LENGTH'] = 100 * 1024 * 1024 # 16MB
# 初始化API客户端textin_client = TextinOcr( app_id="971357873**********2bef0f5c", app_secret="2d5b5b6267************dbdde26a0")
deepseek_client = FinancialAnalyst( api_key="sk-k3k2jeB**********************78XharBWnYAJHneI")
# 配置日志(在Flask应用初始化后添加)logging.basicConfig( level=logging.INFO, format='%(asctime)s - %(name)s - %(levelname)s - %(message)s', handlers=[ logging.FileHandler('financial_analysis.log'), logging.StreamHandler() ])logger = logging.getLogger(__name__)
@app.route('/')def index(): return render_template('index1.html')
@app.route('/analyze', methods=['POST'])def analyze(): start_time = datetime.now() filepath = None try: # ========== 1. 接收文件 ========== logger.info("收到分析请求 | Headers: %s", request.headers)
file = request.files.get('file') if not file: logger.error("未接收到文件") return jsonify(error="请选择要上传的文件"), 400
if not file.filename.lower().endswith('.pdf'): logger.error("文件类型错误: %s", file.content_type) return jsonify(error="仅支持PDF文件"), 400
# ========== 2. 保存文件 ========== filename = secure_filename(file.filename) filepath = os.path.join(app.config['UPLOAD_FOLDER'], filename) file.save(filepath) logger.info("文件暂存成功 | 路径: %s | 大小: %dKB", filepath, os.path.getsize(filepath)//1024)
# ========== 3. 解析财报 ========== logger.info("开始解析财报...")
resp = textin_client.recognize_pdf2md(filepath, { 'page_start': 0, 'page_count': 1000, # 设置解析页数为1000页 'table_flavor': 'md', 'parse_mode': 'scan', # 设置解析模式为scan模式 'page_details': 0, # 不包含页面细节 'markdown_details': 1, 'apply_document_tree': 1, 'dpi': 144 # 分辨率设置为144 dpi }) logger.info("request time: %s", resp.elapsed.total_seconds())
financial_data = json.loads(resp.text)['result']['markdown']
# 记录解析后的财报数据 logger.info("原始解析数据: %s", json.dumps(financial_data, indent=2, ensure_ascii=False))
# ========== 5. 生成分析报告 ========== logger.info("开始AI分析...")
# 获取AI分析结果 analysis = deepseek_client.analyze_financials(financial_data) logger.info("分析完成 | 结果长度: %d字符", len(analysis)) logger.info("分析完成 | 结果内容: %s", analysis)
# 结构化分析内容 html_content = convert_markdown_to_html(analysis)
result_text = re.sub(r'<think>.*?</think>', '', html_content, flags=re.DOTALL).replace("```markdown", "<br /><hr />") think_text = re.sub(r'```markdown.*?```', '', html_content, flags=re.DOTALL) logger.info(json.dumps(think_text, indent=2, ensure_ascii=False)) logger.info(json.dumps(result_text, indent=2, ensure_ascii=False))
# ========== 6. 响应结果 ========== duration = (datetime.now() - start_time).total_seconds() logger.info("请求处理完成 | 耗时: %.2fs", duration)
return jsonify(html=result_text)
except ValueError as ve: logger.error("业务逻辑错误: %s", str(ve), exc_info=True) return jsonify(error=str(ve)), 400 except requests.exceptions.RequestException as re: logger.error("API请求异常: %s", str(re), exc_info=True) return jsonify(error="后台服务暂不可用"), 503 except Exception as e: logger.critical("未处理异常: %s", str(e), exc_info=True) return jsonify(error="系统内部错误"), 500 finally: # 清理临时文件 if filepath and os.path.exists(filepath): try: os.remove(filepath) logger.info("已清理临时文件: %s", filepath) except Exception as e: logger.warning("文件清理失败: %s", str(e))
def convert_markdown_to_html(markdown_text): # 将 Markdown 转换为 HTML html_content = markdown.markdown(markdown_text) return html_content
if __name__ == '__main__': os.makedirs(app.config['UPLOAD_FOLDER'], exist_ok=True) app.run(debug=True)② index.html
<!-- templates/index.html --><!DOCTYPE html><html><head> <title>智能财报分析系统</title> <link href="https://cdn.bootcdn.net/ajax/libs/twitter-bootstrap/5.3.0/css/bootstrap.min.css" rel="stylesheet"> <script src="https://cdn.bootcdn.net/ajax/libs/echarts/5.4.2/echarts.min.js"></script></head><body><div class="container mt-5"> <h2 class="mb-4">上市公司财报智能分析</h2>
<!-- 上传区域 --> <div class="card mb-4"> <div class="card-body"> <input type="file" id="pdfUpload" accept=".pdf" class="form-control"> <div id="loading" class="mt-3" style="display:none;"> <div class="spinner-border text-primary"></div> <span class="ms-2">分析中...</span> </div> </div> </div>
<!-- 结果显示 --> <div id="resultPanel" style="display:none;" class="row"> <!-- 左侧分析文本 --> <div class="col-md-6"> <div class="card mb-4"> <div class="card-header">AI分析结论</div> <div class="card-body"> <div id="textAnalysis" style="white-space: pre-line;"></div> </div> </div> </div>
<!-- 右侧表格 --> <div class="col-md-6"> <div class="card"> <div class="card-header">财务报表数据</div> <div class="card-body"> <div id="tablesArea"></div> </div> </div> </div> </div></div>
<script>document.getElementById('pdfUpload').addEventListener('change', function(e) { const file = e.target.files[0]; const formData = new FormData(); formData.append('file', file);
// 显示加载状态 document.getElementById('loading').style.display = 'block'; document.getElementById('resultPanel').style.display = 'none';
fetch('/analyze', { method: 'POST', body: formData }) .then(response => response.json()) .then(data => { if(data.error) { alert('错误: ' + data.error); return; }
// 渲染分析文本 document.getElementById('textAnalysis').textContent = data.analysis
// 渲染表格 renderTables(data.tables)
document.getElementById('resultPanel').style.display = 'block'; }) .finally(() => { document.getElementById('loading').style.display = 'none'; });});
function renderTables(tables) { const container = document.getElementById('tablesArea') container.innerHTML = ''
// 定义表格样式 const tableStyle = `style="width:100%; margin-bottom:2rem; border-collapse:collapse;"` const thStyle = `style="padding:12px; background:#f8f9fa; border:1px solid #dee2e6;"` const tdStyle = `style="padding:12px; border:1px solid #dee2e6; text-align:right;"`
// 遍历所有表格类型 const tableTypes = { 'income_statement': '利润表', 'balance_sheet': '资产负债表', 'cash_flow': '现金流量表' }
Object.entries(tableTypes).forEach(([key, title]) => { const data = tables[key] if(data.length === 0) return
// 创建表格标题 const titleEl = document.createElement('h5') titleEl.className = 'mt-4 mb-3 text-primary' titleEl.textContent = title container.appendChild(titleEl)
// 创建表格 const table = document.createElement('table') table.className = 'financial-table' table.setAttribute('style', tableStyle)
// 处理表头 const thead = document.createElement('thead') const headerCells = data[0].split('|').filter(c => c.trim()) thead.innerHTML = ` <tr> ${headerCells.map(c => `<th ${thStyle}>${c.trim()}</th>`).join('')} </tr> ` table.appendChild(thead)
// 处理表格体 const tbody = document.createElement('tbody') data.slice(1).forEach(row => { const cells = row.split('|').filter(c => c.trim()) if(cells.length === 0) return
const tr = document.createElement('tr') tr.innerHTML = cells.map(c => ` <td ${tdStyle}>${c.trim().replace(/(\d)(?=(\d{3})+(?!\d))/g, '$1,')}</td> `).join('') tbody.appendChild(tr) }) table.appendChild(tbody)
container.appendChild(table) container.appendChild(document.createElement('div')).className = 'mb-4' // 添加空行 })}
</script><style>.financial-table { margin-bottom: 2rem;}.financial-table th { background-color: #f8f9fa; min-width: 120px;}.financial-table td { font-family: 'Courier New', monospace;}</style></body></html>2. 案例运行效果
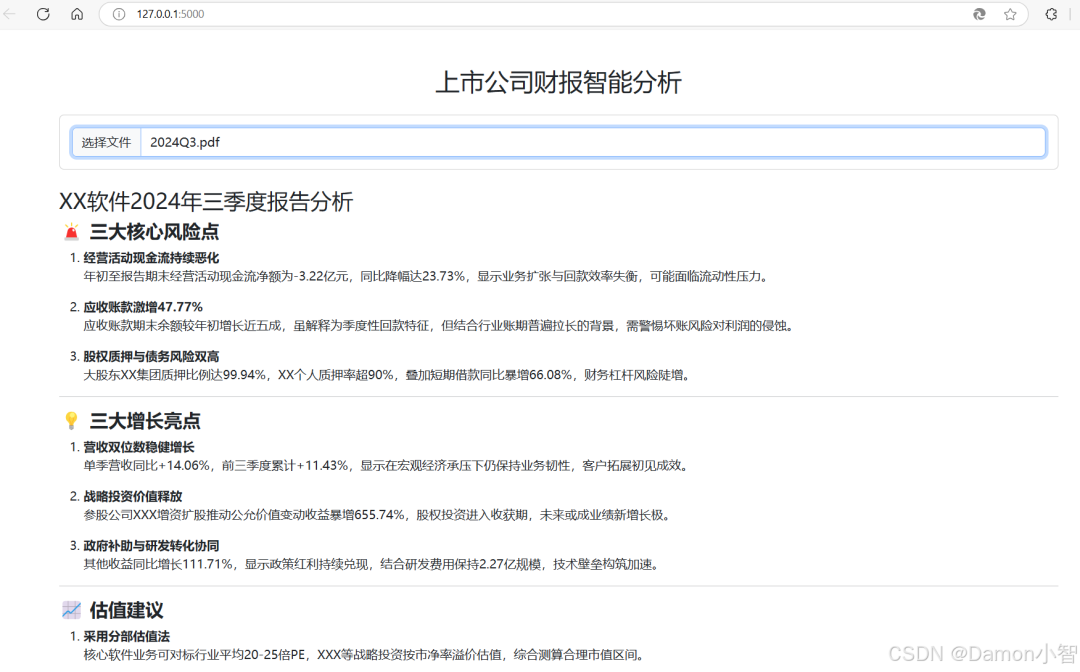
我们从雪球上下载某软件公式的2024Q3财报,上传到我们的智能分析项目。
五、行业应用案例
1. 金融行业
金融行业对精确的财报分析有着强烈的需求。通过合合信息TextIn与DeepSeek的结合,金融机构能够自动化处理财报文档,并获取AI分析的结果,极大提高了分析效率。无论是用于投资决策还是企业评估,系统都能提供准确、及时的分析报告,帮助决策者抓住市场机会。
2. 制造业
对于制造业企业来说,财报中往往涉及大量的供应链数据、采购订单和合同等文档。通过合合信息TextIn的自动化文档解析与DeepSeek的财务分析,制造业能够迅速获取财报中的核心数据,识别财务风险,并优化资源配置,提高运营效率。
六、总结
合合信息的TextIn与DeepSeek R1的结合,提供了一种全面、自动化的财报分析解决方案。通过自动化文档解析和深度AI分析,企业不仅能够高效提取财务数据,还能精准识别财务中的潜在问题和业务机会。这一智能化的解决方案正在成为金融、制造等行业财报处理的核心工具,助力企业在复杂的市场环境中做出更加明智的决策。
机器学习算法AI大数据技术
搜索公众号添加: datanlp

长按图片,识别二维码
阅读过本文的人还看了以下文章:
整理开源的中文大语言模型,以规模较小、可私有化部署、训练成本较低的模型为主
基于40万表格数据集TableBank,用MaskRCNN做表格检测
《深度学习入门:基于Python的理论与实现》高清中文PDF+源码
2019最新《PyTorch自然语言处理》英、中文版PDF+源码
《21个项目玩转深度学习:基于TensorFlow的实践详解》完整版PDF+附书代码
PyTorch深度学习快速实战入门《pytorch-handbook》
【下载】豆瓣评分8.1,《机器学习实战:基于Scikit-Learn和TensorFlow》
李沐大神开源《动手学深度学习》,加州伯克利深度学习(2019春)教材
【Keras】完整实现‘交通标志’分类、‘票据’分类两个项目,让你掌握深度学习图像分类
如何利用全新的决策树集成级联结构gcForest做特征工程并打分?
Machine Learning Yearning 中文翻译稿
斯坦福CS230官方指南:CNN、RNN及使用技巧速查(打印收藏)
中科院Kaggle全球文本匹配竞赛华人第1名团队-深度学习与特征工程
不断更新资源
深度学习、机器学习、数据分析、python
搜索公众号添加: datayx



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









