






1.编译:
指的是将高级语言翻译成汇编语言或者机器语言的过程
2.汇编:
汇编语言翻译成机器语言的过程
3.源程序到机器代码的过程
源程序 ——预处理器处理——经过预处理器处理的源程序 ——编译器处理——汇编程序——汇编器处理——可重定位的机器代码——连接器/加载器处理——目标机器代码
预处理器的作用:把存储在不同文件中的源程序聚合到一起,把被称为宏的缩写语句转换为原生语句
可重定位的意思是:在内存中存放的起始位置L不是固定的。代码中的所有地址都是相对这个起始位置的相对地址。起始位置+相对地址=绝对地址
加载器作用:修改可重定位地址,将修改后的指令和数据放到内存中的适当位置
链接器的作用:将多个可重定位的机器代码(包括库文件)连接到一起;解决外部内存地址问题(一个文件中的代码可能引用另一个文件中的数据对象或过程,那么这些文件中的数据对象和过程相的地址对这个文件来讲就是外部地址)
4.编译系统的结构
编译的阶段在逻辑组织方式上分为前端 中间 后端,具体实现方式上可能会被组合到一起。具体的组成看下图
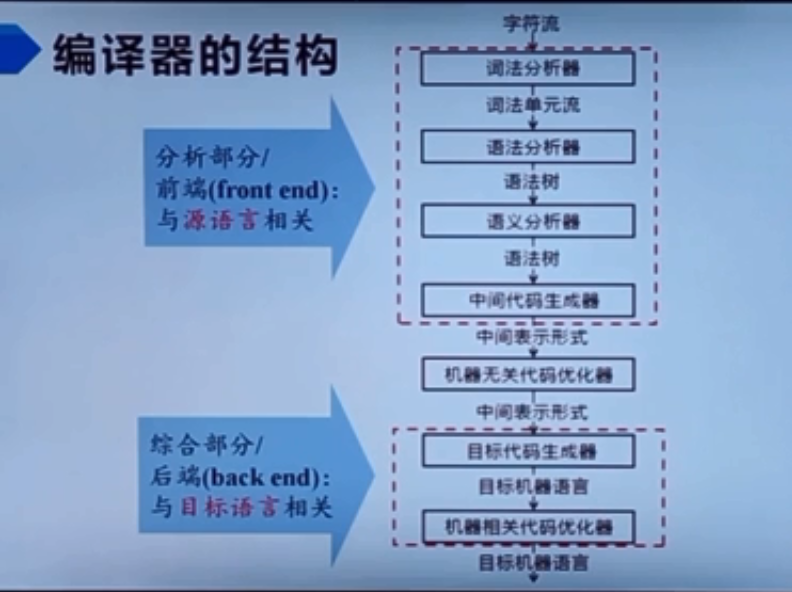
词法分析的主要任务:
从左向右逐行扫描源程序的字符,识别出各个单词,确定单词的类型,将识别出的单词转换成统一的机内表示——词法单元(token)形式:<种别码,属性值>:属性值存放具体的值
单词类型:关键字(一词一码),标识符(变量名,数组名,记录名,过程名等)(多词一码,就这个是特殊的),常量(整型,布尔型,字符型等)(一型一码),运算符(一型一码),界限符(一词一码)
语法分析的主要任务:
从词法分析器输出的token序列中识别出各类短语,并构造语法分析树
变量声明语句的文法:
<D>——><T><IDS>;
<T>——>int|real|char\bool
<IDS>——>id|<IDS>,id
其中D:表示声明;T表示类型;IDS表示标识符序列
语义分析的主要任务:
1)收集标识符的属性信息,包括以下:
种属Kind:简单变量还是复合变量,过程等;
类型Type:int类型,布尔类型等;
存储位置和长度
· 值
作用域
参数和返回值信息:参数个数,参数类型,参数传递方式,返回值类型
该阶段收集到的属性信息存放在 名字叫做 符号表的数据结构中
2)语义检查
变量或过程未经声明就使用
变量或过程名重复声明
运算分量类型不匹配
操作符与操作数之间的类型不匹配














 3424
3424











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









