






第2节 mapreduce深入学习:6、 MapReduce当中的计数器
计数器是收集作业统计信息的有效手段之一,用于质量控制或应用级统计。计数器还可辅助诊断系统故障。如果需要将日志信息传输到map 或reduce 任务, 更好的方法通常是看能否用一个计数器值来记录某一特定事件的发生。对于大型分布式作业而言,使用计数器更为方便。除了因为获取计数器值比输出日志更方便,还有根据计数器值统计特定事件的发生次数要比分析一堆日志文件容易得多。
hadoop内置计数器列表
| MapReduce任务计数器 | org.apache.hadoop.mapreduce.TaskCounter |
| 文件系统计数器 | org.apache.hadoop.mapreduce.FileSystemCounter |
| FileInputFormat计数器 | org.apache.hadoop.mapreduce.lib.input.FileInputFormatCounter |
| FileOutputFormat计数器 | org.apache.hadoop.mapreduce.lib.output.FileOutputFormatCounter |
| 作业计数器 | org.apache.hadoop.mapreduce.JobCounter |
每次mapreduce执行完成之后,我们都会看到一些日志记录出来,其中最重要的一些日志记录如下截图:
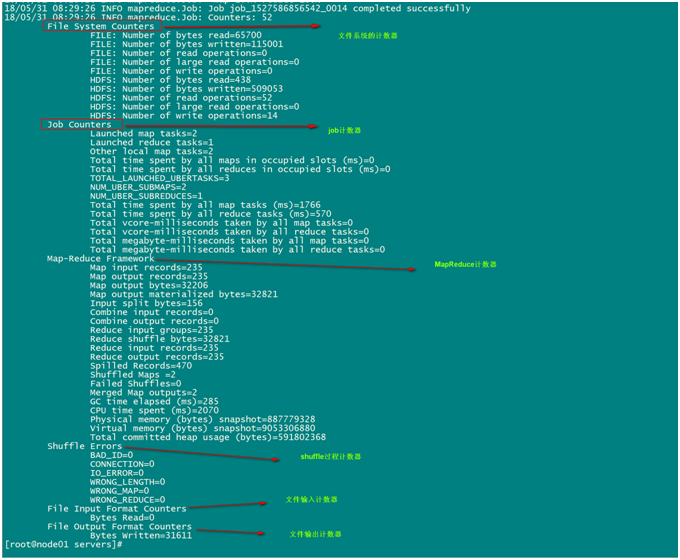
所有的这些都是MapReduce的计数器的功能,既然MapReduce当中有计数器的功能,我们如何实现自己的计数器???
需求1:以上面排序以及序列化为案例,统计map接收到的数据记录条数;需求2:统计reduce端数据的输入的key有多少个,对应的value有多少个。
第一种方式定义计数器,通过context上下文对象可以获取我们的计数器,进行记录。
第二种方式定义计数器,通过enum枚举类型来定义计数器。
详见代码
运行结果:
19/06/14 20:52:37 INFO mapred.JobClient: MAP_COUNTER
19/06/14 20:52:37 INFO mapred.JobClient: MAP_INPUT_RECORDS=8
19/06/14 20:52:37 INFO mapred.JobClient: cn.itcast.demo2.sort.SortReducer$Counter
19/06/14 20:52:37 INFO mapred.JobClient: REDUCE_INPUT_KEY_TOTAL=7
19/06/14 20:52:37 INFO mapred.JobClient: REDUCE_INPUT_VALUE_TOTAL=8















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









