






注:该文是上了开智学堂数据科学基础班的课后做的笔记,主讲人是肖凯老师。
数据绘图
数据可视化的原则
- 为什么要做数据可视化?
为什么要做数据可视化?因为可视化后获取信息的效率高。为什么可视化后获取信息的效率就高?因为人眼是个高带宽的巨量信号输入并行处理器,具有超强的模式识别能力,对可视符号的感知速度比对数字或文本快多个数量级,而可视化就是迎合了人眼的这种特点,才使得获取信息难度大大降低。(获取信息难度大大降低,也就是学习难度降低,也就能以有限的精力学到更多的东西,从而提高学习效率,所以可视化做得好就可以大大提高学习效率……)
这才会有一图胜前言的说法,一堆数据费劲看半天不明白,一生成图形就一目了然了。比如用图表达国际象棋对比围棋的复杂度:
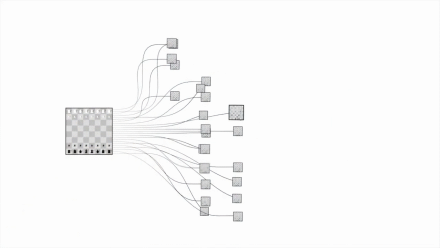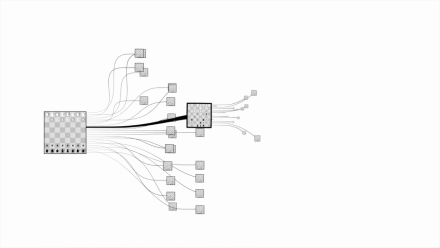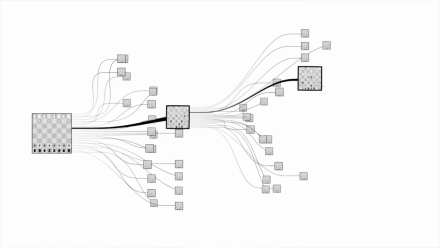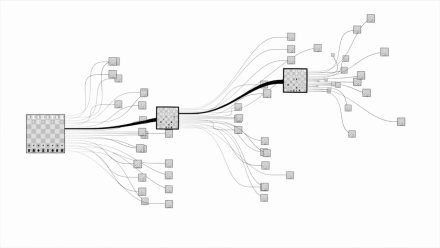
从信息加工的角度看,丰富的信息将消耗大量的注意力,需要有效地分配注意力。精心设计的可视化可作为某种外存,辅助人们在人脑之外保存待处理信息,从而补充人脑有限的记忆内存,有助于将认知行为从感知系统中剥离,提高信息认知的效率。另一方面,视觉系统的高级处理过程中包含一个重要部分,即有意识地集中注意力,但人们保持视觉搜索的效率通常只能保持几分钟,无法持久。图形化符号可高效地传递信息,将用户的注意力引导到重要的目标上,好刀用在刀刃上。
可视化的作用体现在多个方面,如揭示想法和关系、形成论点或意见、观察事物演化的趋势、总结或积聚数据、存档和汇整、寻求真相和真理、传播知识和探索性数据分析等。
虽然可视化这个名字今年来才被大众所熟知,但其实“可视化与山岳一样古老”,在地图、科学与工程制图、统计图表中,可视化的技术和理念已经应用和发展了数百年。这方面的例子很多,这里不再赘述。
在计算机学科的分类中,利用人眼的感知能力对数据进行交互的可视表达,以增强认知的技术,称为可视化。它将不可见、或难以直接显示的数据转化为可感知的图形、符号、颜色、纹理等,增强数据识别效率,传递有效信息。这方面的例子也很多,举些常见的例子,世界杯、奥运会期间的大型网站做的可视化就越来越好,还有针对一些新闻热点所做的社交网络分析也非常清晰。相信大家也碰到过不少可视化的优秀案例。
推荐个有趣的可视化排序算法网站。
再收藏个可视化优化算法的网站,说不定后面有用^_^
- 要用什么数据表达什么信息?
考虑你想传达什么知识,想要回答什么问题,或者想要讲述什么故事。这个阶段就是抽象地规划可视化功能,这时考虑实现细节还为时过早。这是个关键步骤,很值得投入时间。
- 受众是谁?
这是可视化必须要考虑的问题。一旦确定了可视化要传递的信息或达到的目标,接下来就要思考如何使用可视化。受众的需求、行话和需求必须纳入考虑,在这个阶段,明确他们需要从可视化中获取的知识将很有帮助。
- 如何使图更好看?
如何使图更好看?问题很简单,却不容易回答。什么叫好看?显然,这里的好看绝不是颜色搭配、线条粗细的设置这么简单,最重要的是要表达出足够的信息,要能够帮助到读者理解并获得新知识。要用图来表达大量的信息,且能够使读者快速、愉快地接收到,这绝不是件简单的事儿。下面是《数据可视化之美》第一章对该问题的解读。
美丽的可视化可反映出所描述数据的品质,显式地揭示出源数据中内在和隐式的属性和关系,读者了解了这些属性和关系之后,可以因此而获取新的知识、洞察力和乐趣。
一个称得上“美”的可视效果,不但必须美观,而且必须新颖、充实和高效。
新颖:指用一种崭新的视角观察数据,或者用一种风格可以激发读者的激情从而达到新的理解高度。当然,好的可视化绝非为了新颖而设计,而是为了更加高效,新颖性只是展示新洞察的副产品,绝大多数情况下,还是应当遵从标准的格式和惯例,因为它们易于创建、为多数读者所熟悉,且具有自明性。采用新颖可视化必须是为了传递信息而非多样化。
高效:可视化不能包含太多和主题无关的内容或信息,不相关的数据如同噪音,如果无益,则很可能有害。
充实:首先考虑你想要传达什么知识,想要回答什么问题,或者想要讲述什么故事;然后理解受众的需求和目标,读者的需求、行话和偏好必须纳入考虑之中,然后有效选择数据,判断哪些数据是没用的,更糟的是分散你的注意力。
美观:图形化构建——包括坐标轴、布局、形状、色彩、线条和排版——是实现可视化之美的必要因素,合理利用这些因素来引导用户传播信息、揭示关系、突出结论以及提高视觉魅力是必要的。例如,在某些情况下,可以对信息进行冗余编码,如一个给定的值或分类可用位置和颜色来描述,可以使用文字标签和形状大小来描述,与单一编码相比,冗余编码可以帮助读者更快、更容易地区分感知和了解更多信息。也可以选择熟悉的色彩板、图标、布局以及和使用场景相关的全局风格,可以使读者更轻松或者舒适地接受展现处理的信息。
门捷列夫的化学元素周期表是可视化的杰作。
Matplotlib 的基本操作
- 如何定义画布?
%pylab inline
import matplotlib.pyplot as pltPopulating the interactive namespace from numpy and matplotlibMatplotlib 的图像都位于 Figure 画布中,可以使用 plt.figure 创建一个新画布。
如果要在一个图表中绘制多个子图,可使用 subplot。
fig = plt.figure() # 创建一个新的 Figure
ax1 = fig.add_subplot(2, 2, 1) # 不能通过空 Figure 绘图,必须用 add_subplot 创建一个或多个 subplot 才行
ax2 = fig.add_subplot(2, 2, 2)
ax3 = fig.add_subplot(2, 2, 3)
from numpy.random import randn
plt.plot(randn(50).cumsum(),'k--') # 这条没有指定具体 subplot 的绘图命令会在最后一个用过的 subplot 上进行绘制
_ = ax1.hist(randn(100), bins=20, color='k', alpha=0.3)
ax2.scatter(np.arange(30), np.arange(30) + 3*randn(30)) ; # 这里加分号可以屏蔽不必要的输出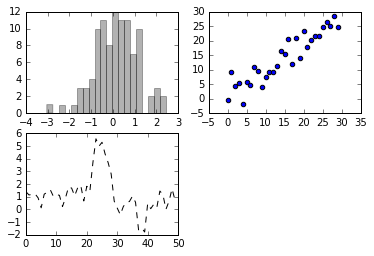
如果要同时绘制多个图表,可以给 figure() 传递一个整数参数指定 Figure 对象的序号,如果序号所指定的Figure对象已经存在,将不创建新的对象,而只是让它成为当前的Figure对象。如下例所示:
import numpy as np
plt.figure(1) # 创建图表1
plt.figure(2) # 创建图表2
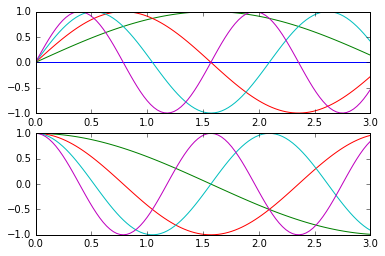
ax1 = plt.subplot(211) # 在图表2中创建子图1
ax2 = plt.subplot(212) # 在图表2中创建子图2
x = np.linspace(0, 3, 100)
for i in xrange(5):
plt.figure(1) # 选择图表1
plt.plot(x, np.exp(i*x/3))
plt.sca(ax1) # 选择图表2的子图1
plt.plot(x, np.sin(i*x))
plt.sca(ax2) # 选择图表2的子图2
plt.plot(x, np.cos(i*x))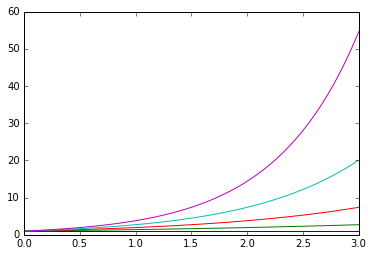
plt.figure 有一些选项,特别是 figsize,它用于确保当图片保存到磁盘时具有一定的大小和纵横比。
x = np.linspace(0, 10, 1000)
y = np.sin(x)
plt.figure(figsize=(14,4))
plt.plot(x,y,label="$sin(x)$",color="red",linewidth=2)
plt.legend()<matplotlib.legend.Legend at 0x7f09ef935610>
现在问题来了,之前章节我们在使用 Matplotlib 的 plot 函数绘图时并没有创建 figure,怎么也能画出图呢?
import numpy as np
x = np.linspace(-5, 5, num = 100)
y = np.e**x
plt.plot(x,y)[<matplotlib.lines.Line2D at 0x7f09efba06d0>]
其实这里的 plt.plot() 是通过 plt.gca() 获得当前 Axes 对象的 ax,如果没有会创建一个,然后再调用 ax.plot 方法实现真正的绘图。
Matplotlib 是一套面向对象的绘图库,它所绘制的图表中的每个图表元素,如线条 Line2D、文字 Text、刻度等在内存中都有一个对象与之对应。
为了将面向对象的绘图库包装成只使用函数的调用接口,pyplot模块的内部保存了当前图表以及当前子图等信息。当前的图表和子图可以使用plt.gcf()和plt.gca()获得,分别表示"Get Current Figure"和"Get Current Axes"。在pyplot模块中,许多函数都是对当前的Figure或Axes对象进行处理,比如说:
plt.plot()实际上会通过plt.gca()获得当前的Axes对象ax,然后再调用ax.plot()方法实现真正的绘图。
- 画图有许多细节可以手动调整,需要慢慢熟悉
图形的类型
- 常用图形有哪些?
线图 line、条形图 bar、饼图 pie、直方图 histgram、散点图 scatter
- 思考什么情况下更适合使用哪种图形
表现一个连续的数值变化时,用线图,如表现 PM2.5 随时间的变化。
如果要处理离散的数据,如要展示不同城市的不同 PM2.5 均值,就可以用条形图画不同的城市。
如果要表示 PM2.5 不同成分的构成,就可以用饼图表现不同比例成分的大小。
在初学者看来,直方图和条形图很相似,其实是有很严格的区别,条形图是画离散数据的,而直方图是画连续数据的,如要看一群人身高的分布,身高是连续值,所以用直方图表示身高的分布。
如果要探索两个因素的相关性,如要探索一群人身高和体重的相关性,就可以用散点图。
上面是肖老师视频里讲的内容,下面是课外阅读内容。
之前总结过该问题,可参考我的博客:SPSS 统计图形。
根据统计图呈现变量的数量将其分为单变量图、双变量图、多变量图,然后再根据测试尺度进行细分。变量主要分为3类:无序、有序和连续型变量。
1、单变量图:连续型变量。包括直方图、茎叶图、箱图、P-P图等。
2、单变量图:分类变量。包括饼图、简单条图、Pareto图。
3、双变量图:连续应变量。即应变量为连续性变量的情形。注意此处 “应” 字并非笔误,应变量可理解为数学方程中的因变量。
此时又可分为三种情况,当另一个主动变化的变量(自变量)为:
(1)无序分类变量:简单条图。
(2)有序分类变量:线图,条图。用于直观表现随着有序变量的变化,应变量是如何上升或下降的。
(3)连续性变量:散点图。用散点的疏密程度和变化趋势来对两个连续变量间的数量联系进行呈现。
4、双变量图:分类应变量。当自变量为:
(1)分类变量:条图。按具体呈现方式,又可分为:复式条图、分段条图和马塞克图3种。
(2)连续变量:目前没有很好的图形可用。常见处理方式是,将自/应变量交换后用条图呈现。
以上介绍的双变量图仅是正规和常见的,其实还可利用单变量图的特性,当自变量为分类变量时,可分类别绘制相应单变量图进行呈现,常见的有分组箱图、复式饼图、直方图组。
5、多变量图。此处仅介绍 3 变量图,切勿将统计图做得太复杂,不然将失去统计图 “直观明了” 的优点。
要表现3个变量的关联,最好是采用三维坐标的立体统计图,但由于实际上还是在平面上对三维图呈现,立体图在使用上并不方便。
(1)当其中有变量为分类变量时,可以对二维图进行扩充,使二维图能够表现更多信息。例如在散点图中用点的形状或者颜色区分不同类别,其实就是呈现了两个连续变量和一个分类变量的数量关联信息。类似的还有多线图。
(2)当所有变量均为连续变量时,则上面的方法就不可用了。需要高维的散点图才行,SPSS提供了一系列功能,如散点图矩阵、立体散点图和动态旋转等。
6、其它特殊用途的统计图。
(1)满足某一行业特殊需求:如用于将统计数据与地域分布相结合的统计地图、用于工业质量控制的控制图、用于股票分析的高低图。
(2)解决某种专门的统计分析问题:用于描述样本指标可信区间或分布范围的误差条图、用于诊断性试验效果分析的ROC曲线、用于时间序列数据预分析的序列图。
数据可视化的高级特性
- matplotlib 还有哪些高级特性?
复杂的图需要注意一些细节,比如要画一些图例、一些丰富的数学标注、在一个画布里容纳多个图、画中画等。这些都是画图的高级特性。
- 何时需要用到这些特性?
画一些图例、丰富的数学标注、在一个画布里容纳多个图,这些都是很常用的。
双坐标图在探索两种尺度不同的数据的关系时会用到。
fig, ax1 = plt.subplots(figsize=(8, 4))
r = np.linspace(0, 5, 100)
a = 4 * np.pi * r ** 2 # area
v = (4 * np.pi / 3) * r ** 3 # volume
ax1.set_title("surface area and volume of a sphere", fontsize=16)
ax1.set_xlabel("radius [m]", fontsize=16)
ax1.plot(r, a, lw=2, color="blue")
ax1.set_ylabel(r"surface area ($m^2$)", fontsize=16, color="blue")
for label in ax1.get_yticklabels():
label.set_color("blue")
ax2 = ax1.twinx()
ax2.plot(r, v, lw=2, color="red")
ax2.set_ylabel(r"volume ($m^3$)", fontsize=16, color="red")
for label in ax2.get_yticklabels():
label.set_color("red")
fig.tight_layout()
画中画在需要局部放大时会用到。
fig = plt.figure(figsize=(8, 4))
def f(x):
return 1/(1 + x**2) + 0.1/(1 + ((3 - x)/0.1)**2)
def plot_and_format_axes(ax, x, f, fontsize):
ax.plot(x, f(x), linewidth=2)
ax.xaxis.set_major_locator(mpl.ticker.MaxNLocator(5))
ax.yaxis.set_major_locator(mpl.ticker.MaxNLocator(4))
ax.set_xlabel(r"$x$", fontsize=fontsize)
ax.set_ylabel(r"$f(x)$", fontsize=fontsize)
# main graph
ax = fig.add_axes([0.1, 0.15, 0.8, 0.8], axisbg="#f5f5f5")
x = np.linspace(-4, 14, 1000)
plot_and_format_axes(ax, x, f, 18)
# inset
x0, x1 = 2.5, 3.5
ax = fig.add_axes([0.5, 0.5, 0.38, 0.42], axisbg='none')
x = np.linspace(x0, x1, 1000)
plot_and_format_axes(ax, x, f, 14)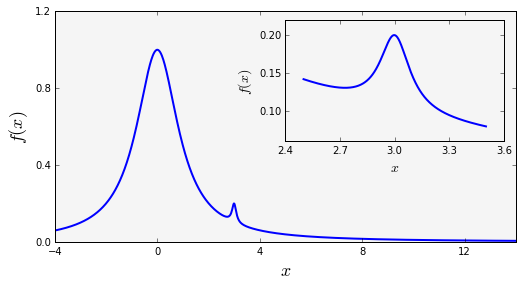
小结
可视化是对数据进行提炼和展现信息的重要手段
Matplotlib 可用于高质量的通用绘图工具
其他绘图模块可参考 seaborn 或者 bokeh
补充阅读
- Matplotlib 官网
- 利用 Python 进行数据分析 第 8 章
- Numerical Python 第 4 章
- Scipy Lectures 第 4 章
- 鲜活的数据:数据可视化指南
- Choose the Right Chart Typefor your Data














 771
771











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









