






### Rstudio环境配置
1 更新R
在R原软件中逐个运行下面的代码(仅适用Windows系统)。macOS直接打开CRAN官网下载最新版本的R覆盖安装,重启RStudio即可完成R的更新,原R包都在。
install.packages("installr")
library(installr)
updateR()2 更新R包
运行下面的代码或通过右下角的Packages选项卡进行R包的更新
old.packages() # 检查是否有需要更新的R包
update.packages(ask = F) # 更新所有R包
news(package = "limma") # 参看R包的更新内容
BiocManager::valid() # 查看是否有需要更新的bioconductor包。根据提示安装更新3 从bioconductor安装R包
BiocManager::install("biomaRt",update = TRUE,ask = FALSE)4 清除当前加载的程序包
detach("package:dplyr", unload=TRUE)
# 或用pacman包内的p_unload函数
pacman::p_unload("dplyr")如果要从环境中移除所有用户包,则可通过pacman包的p_loaded()+p_unload()函数实现:
pacman::p_unload(pacman::p_loaded(), character.only = TRUE)5 更改当前R脚本运行目录
setwd("/Users/totoshihiro/Library/Mobile Documents/com~apple~CloudDocs/Documents/科研/医学统计学/数据基本处理与标准化")
getwd()#查看当前R脚本运行目录6 环境查看和清理
rm(mydata)
rm(list = ls())#移除当前环境中的所有对象
cat("\014")#清空所有输出结果
sessionInfo()#收集有关当前R项目的信息7 自动安装所需的R包
packages <-c("GEOquery", "limma","ggplot2", "pheatmap")#列出所需的R包
#检查所需的R包是否已安装,若未安装则从CRAN或Bioconductor安装包
packagecheck <- function(x) {
if (!require("BiocManager")) {
install.packages("BiocManager")
} else if (!require(x, character.only = T)) {
CRANpackages <- available.packages()
if (x %in% rownames(CRANpackages)) {
install.packages(x)
} else {
BiocManager::install(x, update = TRUE, ask = FALSE)
}
}
}
lapply(packages, packagecheck)8 调整矢量/内存分配上限
8.1 提高矢量大小上限
在R语言中如果我们要处理的数据集较大,如在处理单细胞数据时,可能会出现如下报错:
Error: cannot allocate vector of size *** Mb这是因为 R 中有对象大小的限制(默认值为 500 1024 ^ 2 = 500 Mb)。可以通过如下代码进行调整:
# 调整允许对象大小限制为6GB
options(future.globals.maxSize = 6 * 1024 * 1024^2)8.2 提高R内存分配上限(macOS)
如果在运行大量的数据处理时,出现如下报错:
Error: vector memory exhausted (limit reached?)那么说明脚本的运行超出了R语言内存分配的上限,这一般就是Mac的物理内存大小。但是,我们可以通过如下的方式来通过分配SWAP虚拟内存的方式,使得代码能够继续运行(来自stackoverflow上的这篇帖子)。
【方法一:通过usethis包配置】
在R中运行:
usethis::edit_r_environ()Tip
usethis is a package that facilitates interactive workflows for R project creation and development
运行后会在RStudio中以新标签页的方式打开一个.Renviron文件。在其中输入:
R_MAX_VSIZE=50GbCaution
注意这里的内存数值包括了物理内存和虚拟内存,所以如果你的电脑的实际内存为16GB,那么在这里需要输入比16GB更大的数值,输入16GB是不会有帮助的。
保存这个文件后,重启RStudio,这时候内存上限就被修改好了。
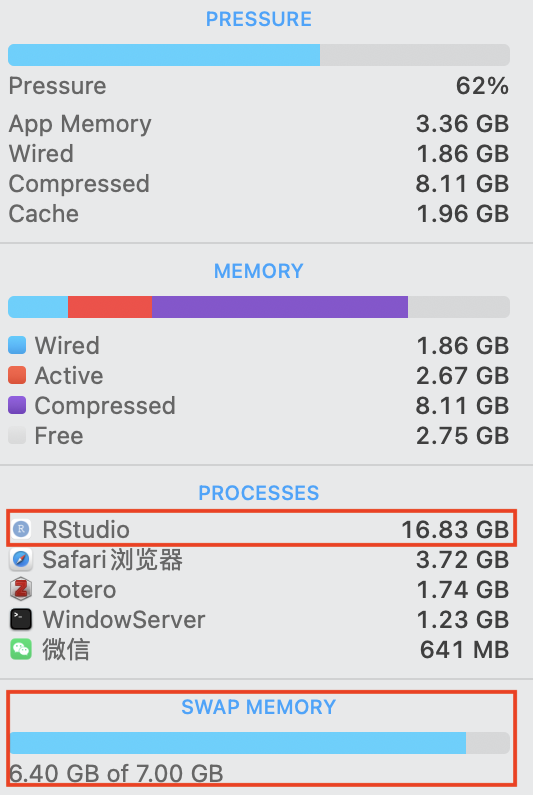
RStudio调用虚拟内存执行脚本
【方法二:通过终端配置】
打开终端(Terminal),在其中输入:
cd ~
touch .Renviron
open .Renviron这时会打开.Renviron文件,在其中输入:
R_MAX_VSIZE=50Gb保存文件,重启RStudio。
9 RStudio常用快捷键
| 操作 | MacOS快捷键 |
|---|---|
| 新建R脚本 | Command + Shift + N |
| 重启R | Command + Shift + 0。或点击菜单栏 Session > Restart R。 |
| 复制并粘贴代码 | 在一行代码末尾或者选中需要复制的代码后按Command + Shift + D |
| 多行注释 | 先选中所要注释的代码,然后按Command + Shift + C。如果想取消注销,再选中代码,再后按 Command + Shift + C。 |
| 创建可折叠注释 | Command + Shift + R |
| 插入管道函数 | Command + Shift + M |
| 赋值 | Option + - |
| 打开帮助 | 将光标放到函数中间,然后按F1键 |
| 查找此前运行过的代码 | 在Console面板中,按 Command + 方向上键,就可以浏览此前运行过的代码。 |
| 自动包装函数 | 选中需要包装成函数的代码后,按 Option + Command + X,会弹出对话框,填写自定义函数的名称后,选中的代码被自动转换成函数,并且其中需要输入的变量会被自动识别并填写到函数名后的括号中(见 Figure 1 )。 |
| 批量更改自定义函数内的输入变量名 | 有时候我们需要修改自定义函数中的某个输入变量的名称,如果手动修改可能会发生遗漏。这时我们可选中需要修改名称的输入变量,然后按 如果记不住该快捷键,也可以在RStudio的菜单栏中选择 |
| 批量添加逗号 | 如果有一连串对象需要添加逗号,则可以在按住 Option 的同时用鼠标在这些对象的后方下拉拖拽,这时候可以发现有多个光标被定位到了这些对象之后,然后就可以输入逗号(见 Figure 3 )。 |
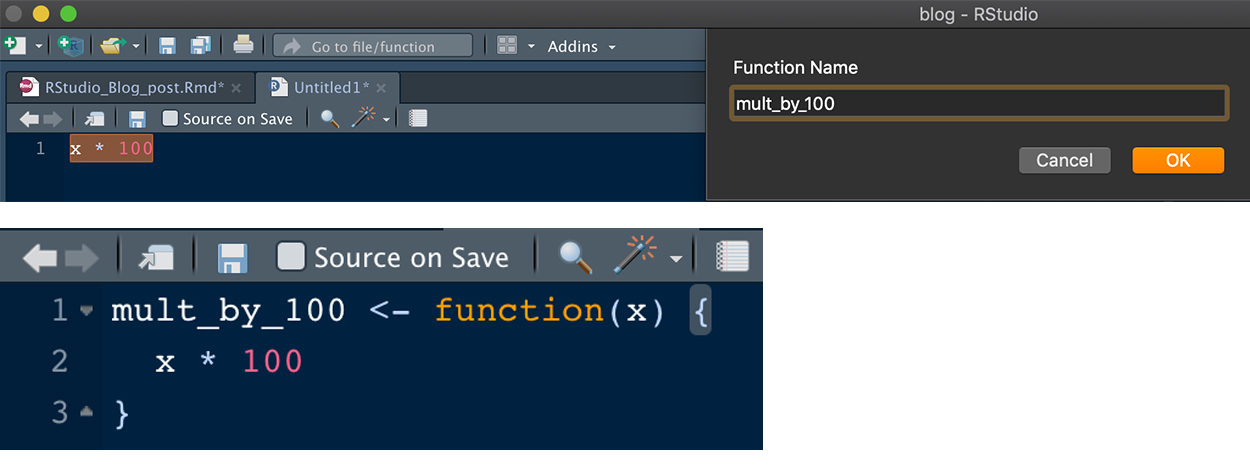
Figure 1: 自动包装函数示例
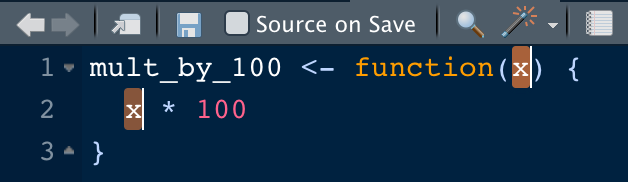
Figure 2: Rename in scope示例
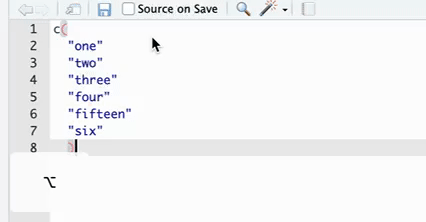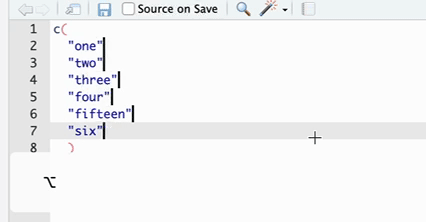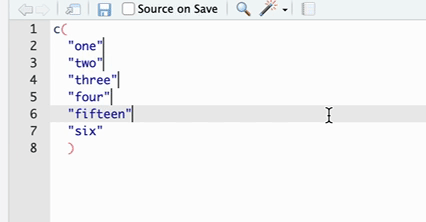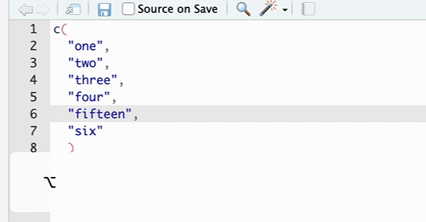
Figure 3: 批量添加逗号示例
Tip
-
在Windows中相应的快捷键把上面的
Command替换成Control,Option替换成Alt即可。 -
记不住快捷键?可以通过在RStudio的菜单栏中选择
Tools>Keyboard Shortcuts Help来显示所有快捷键。
10 自动整理代码
The tidyverse style guide对代码编写时的规范格式进行了详细说明。通过styler包可以实现对代码的自动整理,有助于保持不同项目之间的代码风格一致,并促进协作。安装styler后通过运行下面的命令即可自动整理当前打开的文档的代码。
install.packages("styler")
styler:::style_active_file()也可以用通过打开Rstudio的插件(Addins),选择”Style active file”来实现对当前R脚本的代码整理。或者选择一段代码后,点击”Style selection”来对选中的代码进行整理。
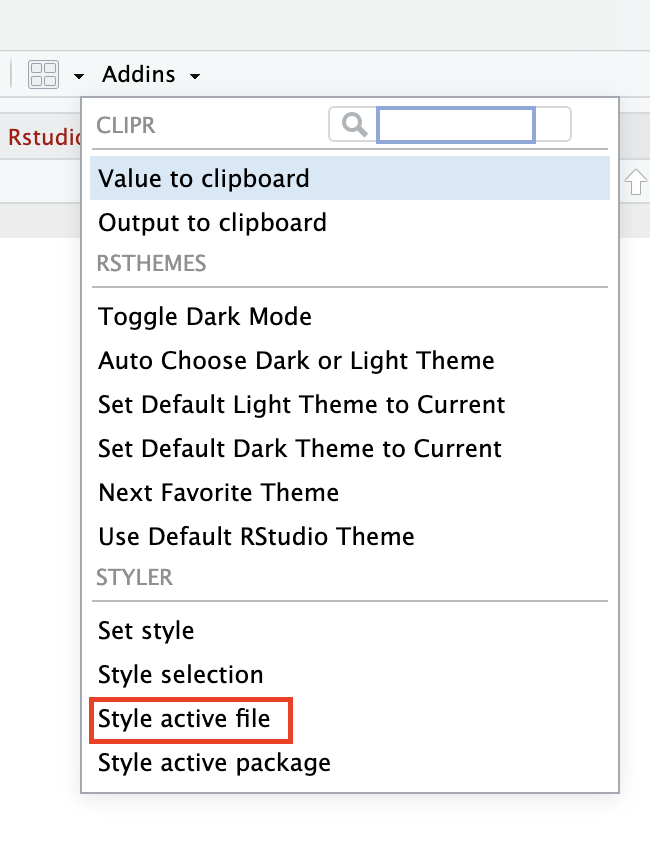
Figure 4: Rstudio插件
Tip
R for Data Science中详细说明了规范的代码风格。
11 Rstudio主题
rsthemes包提供了多种额外的主题。
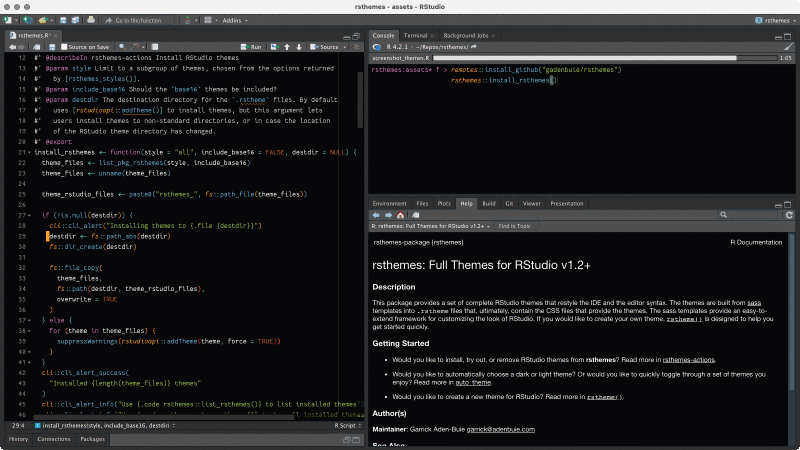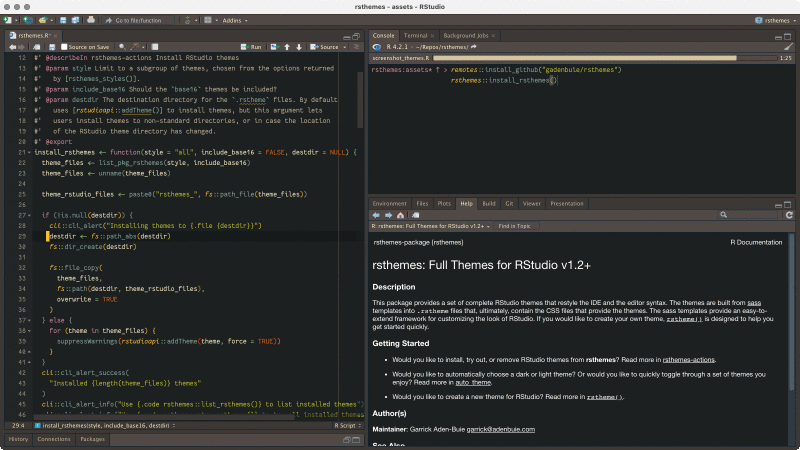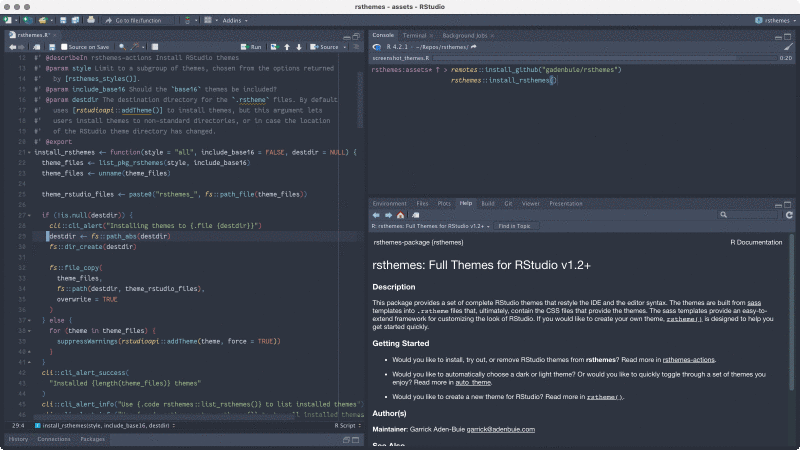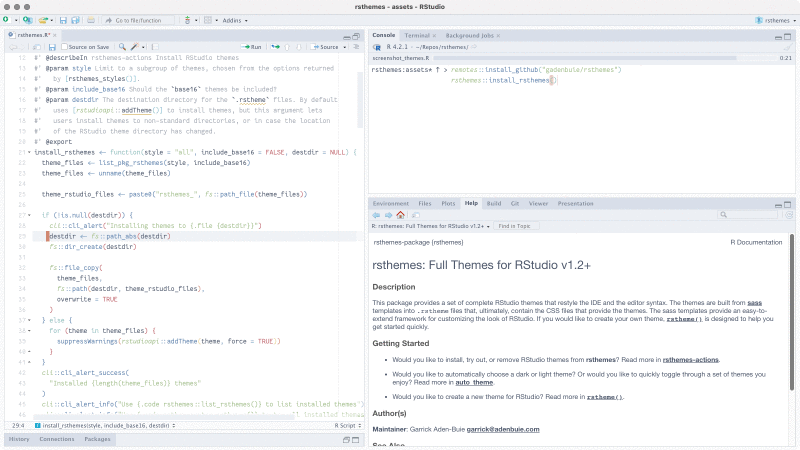
该包通过r-universe进行安装:
install.packages(
"rsthemes",
repos = c(gadenbuie = 'https://gadenbuie.r-universe.dev', getOption("repos"))
)然后安装主题:
rsthemes::install_rsthemes()使用:
# 列出所有来自rsthemes的主题
rsthemes::list_rsthemes()
# 依次尝试所有主题
rsthemes::try_rsthemes()
# 只尝试浅色主题
rsthemes::try_rsthemes("light")通过Tools > Global Options > Appearance也可以浏览和应用这些主题。
安装该包后还会在Rstudio的插件中显示,可以方便的进行深色和浅色模式的切换。要实现这一点,需要打开R的配置文件(~/.Rprofile),可以通过下面的方式快速打开:
usethis::edit_r_profile()然后将下面的代码粘贴进配置文件:
if (interactive()) {
rsthemes::set_theme_light("Chrome") # 默认的浅色主题
rsthemes::set_theme_dark("Cobalt") # 默认的深色主题
rsthemes::set_theme_favorite( # 再添加一些主题作为备选
c(
"GitHub {rsthemes}",
"Material Palenight {rsthemes}"
)
)
}现在就可以通过点击插件中的”Toggle Dark Mode”来一键切换深色和浅色主题了(Figure 4 )。同时,点击”Next Favorite Theme”可以切换上面设置的set_theme_favorite()里面的主题。
### 数据的读取与输出
1 基于R基础包的数据读取
1.1 读取.CSV数据文件
read.csv或read.table均可
csvdata <- read.csv(
file = "ovary_data.csv",
header = T,
sep = ",",
stringsAsFactors = F
) -
header:第一行是否是列名 -
sep:字段分隔符。文件每行上的值由此字符分隔。read.table的默认值为sep = “”,表示分隔符为‘空白’,即一个或多个空格、制表符、换行符或回车。read.csv的默认值为sep = ",",表示分隔符为英文逗号 -
stringsAsFactors:是否将字符向量转换为因子
csvdata <- read.table(
"ovary_data.csv",
header = T,
sep = ",",
row.names = "patientID",
colClasses = c("character", "character", "character", "numeric", "numeric", "numeric")
) colClasses: (可选)指定每一列的变量类型as.is:该参数用于确定read.table()函数读取字符型数据时是否转换为因子型变量。当其取值为FALSE时,该函数将把字符型数据转换为因子型数据,取值为TRUE时,仍将其保留为字符型数据。
1.2 读取.txt文件
refGene <- read.table(
"refGene.txt",
header = F,
sep = "\t"
)1.3 读取.xlsx/.xls文件
MacOS 首选 gdata 包(因自带perl语言);Windows首选 xlsx 包
library(gdata)
xlsdata <- read.xls(
"ovary_data.xlsx",
sheet = 1 # 要读取的工作表的名称或编号
)1.4 读取.sav文件
.sav文件是SPSS的输出文件,可以通过foreign包的read.spss()函数来读取。
library(foreign)
savdata <- read.spss(
"lweight.sav",
to.data.frame = T # 将.sav格式数据转换成数据框
) 1.5 读取程序包中的案例数据集
data(Arthritis, package="vcd")
#或
mydata <- vcd::Arthritis1.6 下载和读取压缩包
1.6.1 解压.zip文件
unzip(
zipfile = "test.zip",
files = "ferroptosis_suppressor.csv",
overwrite = T
)-
zipfile:压缩包的位置及文件名 -
files:(可选)需要提取的文件的文件名,默认解压压缩包内的所有文件 -
overwrite:解压后是否覆盖同名文件
1.6.2 解压.tar文件
untar(
"test.tar", # 压缩包的位置及文件名
files = "ferroptosis_suppressor.csv" # 提取指定文件,默认解压压缩包内的所有文件
) 1.6.3 下载和解压.gz或.bz2文件
这两个压缩文件与前面的相比比较特别,因为.gz或.bz2文件,可以称之为压缩文件,也可以直接作为一个数据文件进行读取。
#下载gz文件
download.file(
"http://hgdownload.soe.ucsc.edu/goldenPath/hg38/database/refGene.txt.gz",
destfile = "refGene.txt.gz") # 目标下载位置,注意需要添加后缀名
#直接以数据的形式读取.gz文件
mydata <- read.table("refGene.txt.gz")列出指定目录中的文件
list.files()在批量读取文件时十分有用,因为它能够获取指定目录下的文件名
list.files(
path = "folder_name",
pattern = ".docx$",
full.names = T
)-
path:需要列出的文件所在的路径,若忽略此项则列出当前工作路径下的所有文件 -
pattern:列出目录中包含指定字符的文件。如pattern = "\\.docx$"表示列出所有以“.docx”为后缀的文件;pattern = "^G"列出所有文件名以“G”开头的文件 -
full.names:FALSE:仅输出文件名;TRUE(默认):输出路径+文件名
1.7 手动生成数据框
framdata <- data.frame(
y = c(6, 8, 12, 14, 14, 15, 17, 22, 24, 23),
x1 = c(2, 5, 4, 3, 4, 6, 7, 5, 8, 9),
x2 = c(14, 12, 12, 13, 7, 8, 7, 4, 6, 5)
)
framdata y x1 x2
1 6 2 14
2 8 5 12
3 12 4 12
4 14 3 13
5 14 4 7
6 15 6 8
7 17 7 7
8 22 5 4
9 24 8 6
10 23 9 5# 使用文本编辑器直接在窗口中编辑数据。macOS需要安装XQuartz(www.xquartz.org)才能运行此代码。
framdata <- edit(framdata)2 基于readr包的数据读取

readr包是tidyverse中用于数据读取的R包。相较于R基础包自带的数据读取函数,基于readr包的数据读取有以下优势:
-
一般来说,
readr比基础包中的函数要更快(快大约10-100倍);如果只要求快速读取大容量数据的话,也可以使用data.tabale包中的fread()函数。在某些情况下fread()比readr的读取速度略快,但是readr能够更好的兼容基于tidyverse的数据处理流程。 -
readr可以生成数据框tibble,并且不会将字符向量转换为因子,不使用行名称,也不会随意改动列名称。这些都是R基础包使用中令人沮丧的事情。 -
readr更易于重复使用。R基础包则需要继承操作系统的功能,并依赖环境变量,同样的代码在另一个电脑上不一定能正常运行。
library(tidyverse)2.1 读取.csv文件
这里我们使用students.csv案例数据,该数据可以从此处下载。对于.csv文件,我们可以通过read_csv()读取:
students <- read_csv("data/r_basic/students.csv")# 也可以直接从URL读取
students <- read_csv("https://pos.it/r4ds-students-csv")当运行 read_csv() 时,它会打印出一条消息,报告数据的行数和列数、使用的分隔符和列类型。int 代表整数型数据,dbl 代表数值型数据,chr 代表字符型数据,dttm 代表日期时间型数据。这些变量非常重要,因为对列进行的操作在很大程度上取决于该列的 “类型”。它还告诉我们可以通过spec()来提取所有列的类型信息。
students# A tibble: 6 × 6
...1 `Student ID` `Full Name` favourite.food mealPlan AGE
<dbl> <dbl> <chr> <chr> <chr> <chr>
1 1 1 Sunil Huffmann Strawberry yoghurt Lunch only 4
2 2 2 Barclay Lynn French fries Lunch only 5
3 3 3 Jayendra Lyne N/A Breakfast and lu… 7
4 4 4 Leon Rossini Anchovies Lunch only <NA>
5 5 5 Chidiegwu Dunkel Pizza Breakfast and lu… five
6 6 6 Güvenç Attila Ice cream Lunch only 6 同时,我们注意到通过read_csv读取后的数据是一个 tibble,这是一种升级版的data.frame,被 tidyverse 用来避免一些data.frame的常见问题。Tibbles 和data.frame之间的一个重要的区别在于 tibbles 打印数据的方式:tibbles 是为大型数据集设计的,因此只显示前几行和适应屏幕宽度的列。可以使用 print(flights, width = Inf) 显示所有列,或者使用 glimpse()(见基于dplyr包的数据处理)。因为这里的数据本身只有6行6列,所以所有数据都被显示了出来。
另一个问题是,“Student ID”和“Full Name”列名被单引号扩起来。这是因为这两列的列名中包含了空格,这不符合R语言列名规范,也体现了tibble不会改变原有列名的特点。如果是用read.csv()读取的话,这两列中间的空格会被”.”替换。下面我们将这两个列名中的空格用下划线“_”替换以符合规范:
rename(
students,
student_id = `Student ID`,
full_name = `Full Name`
)# A tibble: 6 × 6
...1 student_id full_name favourite.food mealPlan AGE
<dbl> <dbl> <chr> <chr> <chr> <chr>
1 1 1 Sunil Huffmann Strawberry yoghurt Lunch only 4
2 2 2 Barclay Lynn French fries Lunch only 5
3 3 3 Jayendra Lyne N/A Breakfast and lunch 7
4 4 4 Leon Rossini Anchovies Lunch only <NA>
5 5 5 Chidiegwu Dunkel Pizza Breakfast and lunch five
6 6 6 Güvenç Attila Ice cream Lunch only 6 rename()要求新变量名在 = 的左侧,旧变量名在右侧。和其他dplyr中的函数一样,rename不会对原始数据进行修改,因此需要将rename后的数据重新赋值给新的对象或覆盖原来的对象以应用对变量名的修改(更多关于rename()的说明详见后续章节)。这里为了后续演示,没有重新赋值。
另一种方法是使用 janitor 包中的 clean_names() 函数,一次性将不符合规范的列名规范化重命名:

janitor::clean_names(students)2.1.1 定义缺失值
通过检查该数据,发现”favourite.food“一列中有一个“N/A”字符,这在原始数据的录入时表示缺失值。但是read_csv()默认将空字符串(“”)识别为缺失值NA。我们可以在读取数据时添加额外的参数让read_csv()能够将“N/A”识别为缺失值:
students <- read_csv(
"data/r_basic/students.csv",
na = c("N/A", "")
)
students# A tibble: 6 × 5
`Student ID` `Full Name` favourite.food mealPlan AGE
<dbl> <chr> <chr> <chr> <chr>
1 1 Sunil Huffmann Strawberry yoghurt Lunch only 4
2 2 Barclay Lynn French fries Lunch only 5
3 3 Jayendra Lyne <NA> Breakfast and lunch 7
4 4 Leon Rossini Anchovies Lunch only NA
5 5 Chidiegwu Dunkel Pizza Breakfast and lunch five
6 6 Güvenç Attila Ice cream Lunch only 6 2.1.2 定义列类别
读入数据后的另一个常见操作是更改变量/列类型。例如,这个数据中“favourite_food”,“meal_plan”应该是因子型变量;“age”应该是数值型变量,因此我们需要对其进行转换。
这里我们使用管道符|>来简化代码,对其的详细说明参考后续章节。mutate()的作用是根据现有列计算并添加新列(见基于dplyr包的数据处理-mutate())。对于因子变量的转换,使用base包的factor(),转换后的变量仍命名为“meal_plan”,所以它会覆盖原有的“meal_plan”变量。对于数值型变量的转换,这里用readr中的parse_number()函数:
students |>
janitor::clean_names() |>
mutate(
favourite_food = factor(favourite_food),
meal_plan = factor(meal_plan),
age = parse_number(age)
)Warning: There was 1 warning in `mutate()`.
ℹ In argument: `age = parse_number(age)`.
Caused by warning:
! 1 parsing failure.
row col expected actual
5 -- a number five# A tibble: 6 × 5
student_id full_name favourite_food meal_plan age
<dbl> <chr> <fct> <fct> <dbl>
1 1 Sunil Huffmann Strawberry yoghurt Lunch only 4
2 2 Barclay Lynn French fries Lunch only 5
3 3 Jayendra Lyne <NA> Breakfast and lunch 7
4 4 Leon Rossini Anchovies Lunch only NA
5 5 Chidiegwu Dunkel Pizza Breakfast and lunch NA
6 6 Güvenç Attila Ice cream Lunch only 6⚠️注意,此时的输出结果中出现了警告信息。提示部分“age”数据出现了解析失败,具体在第五行,是一个“five”值,它不能被解析成数值,所以我们对其进行以下处理:
students <- students |>
janitor::clean_names() |>
mutate(
favourite_food = factor(favourite_food),
meal_plan = factor(meal_plan),
age = parse_number(if_else(age == "five", "5", age))
)
students# A tibble: 6 × 5
student_id full_name favourite_food meal_plan age
<dbl> <chr> <fct> <fct> <dbl>
1 1 Sunil Huffmann Strawberry yoghurt Lunch only 4
2 2 Barclay Lynn French fries Lunch only 5
3 3 Jayendra Lyne <NA> Breakfast and lunch 7
4 4 Leon Rossini Anchovies Lunch only NA
5 5 Chidiegwu Dunkel Pizza Breakfast and lunch 5
6 6 Güvenç Attila Ice cream Lunch only 6readr提供了一系列函数用于转换变量类型:
-
parse_factor():类似于base包的factor(),但是如果通过levels参数指定了因子水平,并且该变量的某些值在这些水平中找不到,则会给出警告并将这些值转换成缺失值NA。而factor()则不会给出警告信息。x <- c("cat", "dog", "caw") animals <- c("cat", "dog", "cow") factor(x, levels = animals)[1] cat dog <NA> Levels: cat dog cowparse_factor(x, levels = animals)[1] cat dog <NA> attr(,"problems") # A tibble: 1 × 4 row col expected actual <int> <int> <chr> <chr> 1 3 NA value in level set caw Levels: cat dog cow -
parse_number():转换数值型变量。这个函数会解析它找到的第一个数字,然后删除第一个数字之前的所有非数字字符和第一个数字之后的所有字符,同时也会忽略千分位分隔符“,”。parse_number("$1,000") # leading `$` and grouping character `,` ignored[1] 1000parse_number("euro1,000") # leading non-numeric euro ignored[1] 1000parse_number("t1000t1000") # only parses first number found[1] 1000parse_number("1,234.56")[1] 1234.56# explicit locale specifying European grouping and decimal marks parse_number("1.234,56", locale = locale(decimal_mark = ",", grouping_mark = "."))[1] 1234.56# SI/ISO 31-0 standard spaces for number grouping parse_number("1 234.56", locale = locale(decimal_mark = ".", grouping_mark = " "))[1] 1234.56 -
parse_integer():转换整数型变量。较少使用,因为整数型变量和数值型变量或称doubles型变量的本质是一样的。 -
parse_datetime():转换日期/时间变量。parse_datetime("01/02/2010", "%d/%m/%Y")[1] "2010-02-01 UTC"parse_datetime("01/02/2010", "%m/%d/%Y")[1] "2010-01-02 UTC"parse_datetime("2010/01/01 12:00 US/Central", "%Y/%m/%d %H:%M %Z")[1] "2010-01-01 18:00:00 UTC"
Tip
这些变量类型转换函数都通过了缺失值定义参数,如:
# Specifying strings for NAs
parse_number(c("1", "2", "3", "NA"))[1] 1 2 3 NAparse_number(c("1", "2", "3", "NA", "Nothing"), na = c("NA", "Nothing"))[1] 1 2 3 NA NA因此,既可以像上面的定义缺失值中一样在数据读取时就定义数据集中的缺失值,也可以在转换变量类型时分别定义每一列的缺失值。
2.1.3 非标准数据的读取
通常,read_csv()使用数据的第一行作为列名,这是一种非常常见的约定。但在有时候数据的顶部可能包含几行元数据。这时候可以通过添加skip参数让read_csv()跳过前n行,也可以通过comment参数让其跳过以特定字符(例如“#”)开头的所有行。
read_csv(
"The first line of metadata
The second line of metadata
x,y,z
1,2,3",
skip = 2
)# A tibble: 1 × 3
x y z
<dbl> <dbl> <dbl>
1 1 2 3read_csv(
"# A comment I want to skip
x,y,z
1,2,3",
comment = "#" # 跳过以“#”开头的行
)# A tibble: 1 × 3
x y z
<dbl> <dbl> <dbl>
1 1 2 3在其他情况下,数据可能没有列名。可以使用 col_names = FALSE 告知 read_csv() 不要将第一行视为列名,而是按从 “X1” 到 “Xn” 的顺序标记它们:
read_csv(
"1,2,3
4,5,6",
col_names = FALSE
)# A tibble: 2 × 3
X1 X2 X3
<dbl> <dbl> <dbl>
1 1 2 3
2 4 5 6或者,可以用 col_names 参数以包含列名的字符向量来自定义列名:
read_csv(
"1,2,3
4,5,6",
col_names = c("x", "y", "z")
)# A tibble: 2 × 3
x y z
<dbl> <dbl> <dbl>
1 1 2 3
2 4 5 62.2 其他类型数据文件的读取
一旦掌握了read_csv()的语法,其他数据格式的读取只需调用特定的函数即可,语法和read_csv()类似:
-
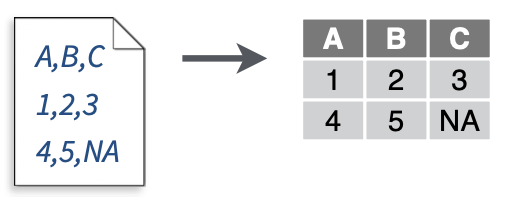
read_csv2():读取以分号“;”分隔的数据。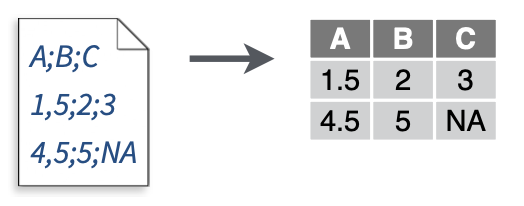
-
read_tsv()和read_table():读取以制表符分隔的数据。 -
read_fwf():读取固定宽度数据文件,其中列以空格分隔。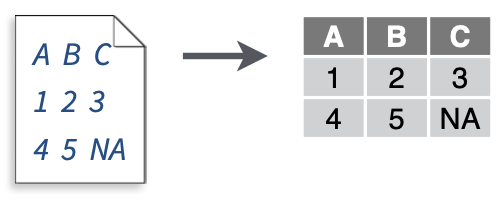
-
read_delim():读取以任意分隔符(例如“|”)分隔的数据。如果没有指定分隔符那么read_delim()会尝试自动猜测分隔符。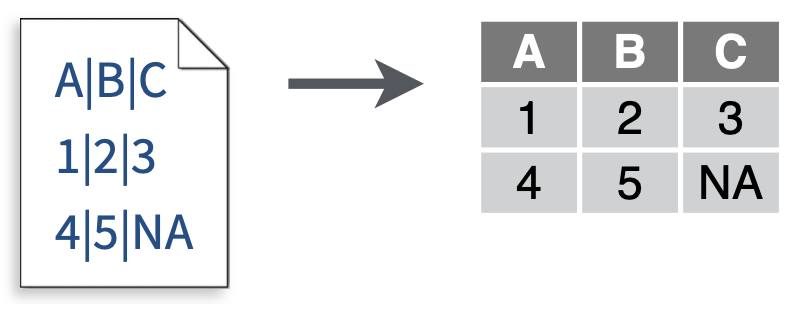
2.3 从多个文件读取数据
有时,数据会拆分到多个文件中,而不是包含在单个文件中。例如,假设这里有多个月的销售数据,每个月的数据都在一个单独的文件中,分别是: 1月的销售数据“01-sales.csv”、2月的销售数据“02-sales.csv”和三月的销售数据“03-sales.csv”。通过使用 read_csv() ,可以一次读取这些数据,并合并成一个数据。
list.files(
"data/r_basic",
pattern = "sales\\.csv$",
full.names = TRUE
) %>%
read_csv(id = "file")# A tibble: 19 × 6
file month year brand item n
<chr> <chr> <dbl> <dbl> <dbl> <dbl>
1 data/r_basic/01-sales.csv January 2019 1 1234 3
2 data/r_basic/01-sales.csv January 2019 1 8721 9
3 data/r_basic/01-sales.csv January 2019 1 1822 2
4 data/r_basic/01-sales.csv January 2019 2 3333 1
5 data/r_basic/01-sales.csv January 2019 2 2156 9
6 data/r_basic/01-sales.csv January 2019 2 3987 6
7 data/r_basic/01-sales.csv January 2019 2 3827 6
8 data/r_basic/02-sales.csv February 2019 1 1234 8
9 data/r_basic/02-sales.csv February 2019 1 8721 2
10 data/r_basic/02-sales.csv February 2019 1 1822 3
11 data/r_basic/02-sales.csv February 2019 2 3333 1
12 data/r_basic/02-sales.csv February 2019 2 2156 3
13 data/r_basic/02-sales.csv February 2019 2 3987 6
14 data/r_basic/03-sales.csv March 2019 1 1234 3
15 data/r_basic/03-sales.csv March 2019 1 3627 1
16 data/r_basic/03-sales.csv March 2019 1 8820 3
17 data/r_basic/03-sales.csv March 2019 2 7253 1
18 data/r_basic/03-sales.csv March 2019 2 8766 3
19 data/r_basic/03-sales.csv March 2019 2 8288 6这些数据可以从https://pos.it/r4ds-01-sales, https://pos.it/r4ds-02-sales, https://pos.it/r4ds-03-sales下载。下载后的数据被翻到了”data”文件夹下的“r_basic”子文件夹内。因此,我们可以通过list.files()并结合pattern参数列出我们需要的销售数据文件,pattern中应用了正则表达式,这在接下来的章节中会详细说明。read_csv中的id参数会在结果数据中添加一个新列,用于标识数据来自哪个文件。
2.4 手动生成tibble
有时需要在R脚本中“手动”输入一些数据来生成一个tibble。有两个函数可以做到这一点,这两个函数的不同之处在于是按列还是按行布局tibble。其中 tibble() 按列工作,类似于base包中的data.fram():
tibble(
x = c(1, 2, 5),
y = c("h", "m", "g"),
z = c(0.08, 0.83, 0.60)
)# A tibble: 3 × 3
x y z
<dbl> <chr> <dbl>
1 1 h 0.08
2 2 m 0.83
3 5 g 0.6 按列布局数据很难看到行之间是如何关联的,因此可以选择 tribble() ,这是“Transsposed Tibble”的缩写,它允许逐行布局数据。列标题以 ~ 开头,条目之间用逗号分隔。这使得以易于阅读的形式布局少量数据成为可能:
tribble(
~x, ~y, ~z,
1, "h", 0.08,
2, "m", 0.83,
5, "g", 0.60
)# A tibble: 3 × 3
x y z
<dbl> <chr> <dbl>
1 1 h 0.08
2 2 m 0.83
3 5 g 0.6 3 数据的导出
3.1 基于base包的数据导出
3.1.1 导出.csv文件
write.csv(
mydata,
row.names = F,#是否输出行名称
"mydata.csv"
)3.1.2 导出.xlsx/.xls文件
library(openxlsx2)
write_xlsx(
coxtable1,
"coxtable1.xlsx"
)3.1.3 储存为.Rdata/.RDS文件
在R中保存数据的更好的方法是通过save()将数据导出为.Rdata文件或通过saveRDS()保存为.RDS文件,它们以R的定制二进制格式存储数据。这意味着当重新加载这些对象时,加载的是与当时存储时的完全相同的R对象。它们能够最大程度的保持数据的原貌,如对变量类型的定义,同时可以将图像、列表等对象导出。
# 保存为.Rdata文件
save(object1, object2, file = "filepath/name.rdata")
# 保存目前环境中的所有对象
save(list = ls(), file = "filepath/name.rdata")
# 保存为.RDS文件
saveRDS(object, file = "filepath/name.rds")-
.Rdata文件的读取是通过load()函数,该函数不能对读取的对象重命名,它会保留当时在储存这些对象时原本的名称;而读取.RDS文件是通过
readRDS()函数,支持重命名:
# 载入.Rdata文件
load("filepath/name.rdata")
# 载入.RDS文件
new_object <- readRDS("filepath/name.rds")3.2 基于readr包的数据导出
3.2.1 导出.csv/.txt文件
Readr提供了两个用于将数据写回磁盘的函数: write_csv() 和 write_tsv() 。这些函数最重要的参数是 x (要保存的数据集的名字)和 file (要保存的位置)。还可以使用 na 指定如何写入缺失值,以及通过 append 定义是否覆盖写入现有文件。
现在我们将之前的“students”数据导出,然后重新读取:
write_csv(students, file = "output/r_basic/students.csv")
read_csv("output/r_basic/students.csv")用这种方式导出的文件无法保留我们定义的变量类型信息。因此,更好的方式是和上面一样保存为.Rdata文件或.RDS文件。和base包的saveRDS()和readRDS()对应的,readr包中也有两个函数,write_rds() 和 read_rds():
write_rds(students, "output/r_basic/students.rds")
students <- read_rds("output/r_basic/students.rds")### 数据处理基本函数
1 加载包
library(tidyverse)
library(nycflights13)2 数据展示
载入示例数据:
mydata <- readRDS("data/r_basic/lms_ess.rds")2.1 展示最大值、最小值、平均数、中位数、缺失值数量
summary(mydata) year year2 age race marriage
2010:111 2010-2011:216 Min. :23.00 White :554 Married :386
2011:105 2012-2013:217 1st Qu.:48.00 Black : 99 Single/Unmarried:166
2012:118 2014-2016:300 Median :55.00 Others: 76 Others :148
2013: 99 Mean :55.77 NA's : 4 NA's : 33
2014:100 3rd Qu.:64.00
2015:101 Max. :95.00
2016: 99
grade grade2 tumor_size
Well differentiated; Grade I : 58 Low-grade :181 Min. : 4.0
Moderately differentiated; Grade II :123 High-grade:323 1st Qu.: 60.0
Poorly differentiated; Grade III :105 Gx :229 Median : 95.0
Undifferentiated; anaplastic; Grade IV:218 Mean :107.9
NA's :229 3rd Qu.:135.0
Max. :950.0
NA's :79
his T_stage T_stage_plus N_stage M_stage figo figo_plus
LMS:448 T1:499 T1b :340 N0 :680 M0:628 I :442 IB :290
ESS:285 T2:131 T1a :114 N1 : 49 M1:105 II : 82 IA :109
T3: 85 T2a : 67 NA's: 4 III: 89 IVB :105
T4: 18 T3a : 57 IV :120 IIIA : 39
T2b : 55 IIIC : 32
T1 : 45 (Other): 30
(Other): 55 NA's :128
peri surg alnd plnd lnd rad
Negtive :674 TH+BSO:629 No :586 No :417 No :412 No :609
Malignant: 59 TH : 47 Yes :111 Yes :282 Yes :288 Yes :117
RH/EH : 57 NA's: 36 NA's: 34 NA's: 33 NA's: 7
chem dead status time income
No :365 0:365 0 :365 Min. : 2.00 <$60,000 :186
Yes :314 1:368 1 :332 1st Qu.: 15.00 $60,000-$74,999:293
NA's: 54 2 : 29 Median : 43.00 >$75,000 :254
NA's: 7 Mean : 47.53
3rd Qu.: 76.00
Max. :119.00
2.2 展示变量数量和样本数量
2.2.1 展示变量(列)数
dim(mydata)[2]#dim()函数获取数据的维度,即行、列数。所以[1]输出行数,[2]输出列数[1] 26ncol(mydata)#另一种方式[1] 262.2.2 展示行数
dim(mydata)[1][1] 733#或者
nrow(mydata)[1] 7332.2.3 综合展示
print(paste0("该数据集有 ",dim(mydata)[1]," 个样本; ",dim(mydata)[2]," 个变量"))[1] "该数据集有 733 个样本; 26 个变量"2.2.4 展示所有变量名
colnames(mydata) [1] "year" "year2" "age" "race" "marriage"
[6] "grade" "grade2" "tumor_size" "his" "T_stage"
[11] "T_stage_plus" "N_stage" "M_stage" "figo" "figo_plus"
[16] "peri" "surg" "alnd" "plnd" "lnd"
[21] "rad" "chem" "dead" "status" "time"
[26] "income" #或者通过dput函数将所有变量名输出为向量
dput(names(mydata))c("year", "year2", "age", "race", "marriage", "grade", "grade2",
"tumor_size", "his", "T_stage", "T_stage_plus", "N_stage", "M_stage",
"figo", "figo_plus", "peri", "surg", "alnd", "plnd", "lnd", "rad",
"chem", "dead", "status", "time", "income")2.2.5 展示所有行名称
```{r}
#| eval: false
rownames(mydata)
```2.2.6 展示某个变量的所有值及其频数
table(mydata$his)
LMS ESS
448 285 hist(mydata$age, col="coral")#以直方图的形式展示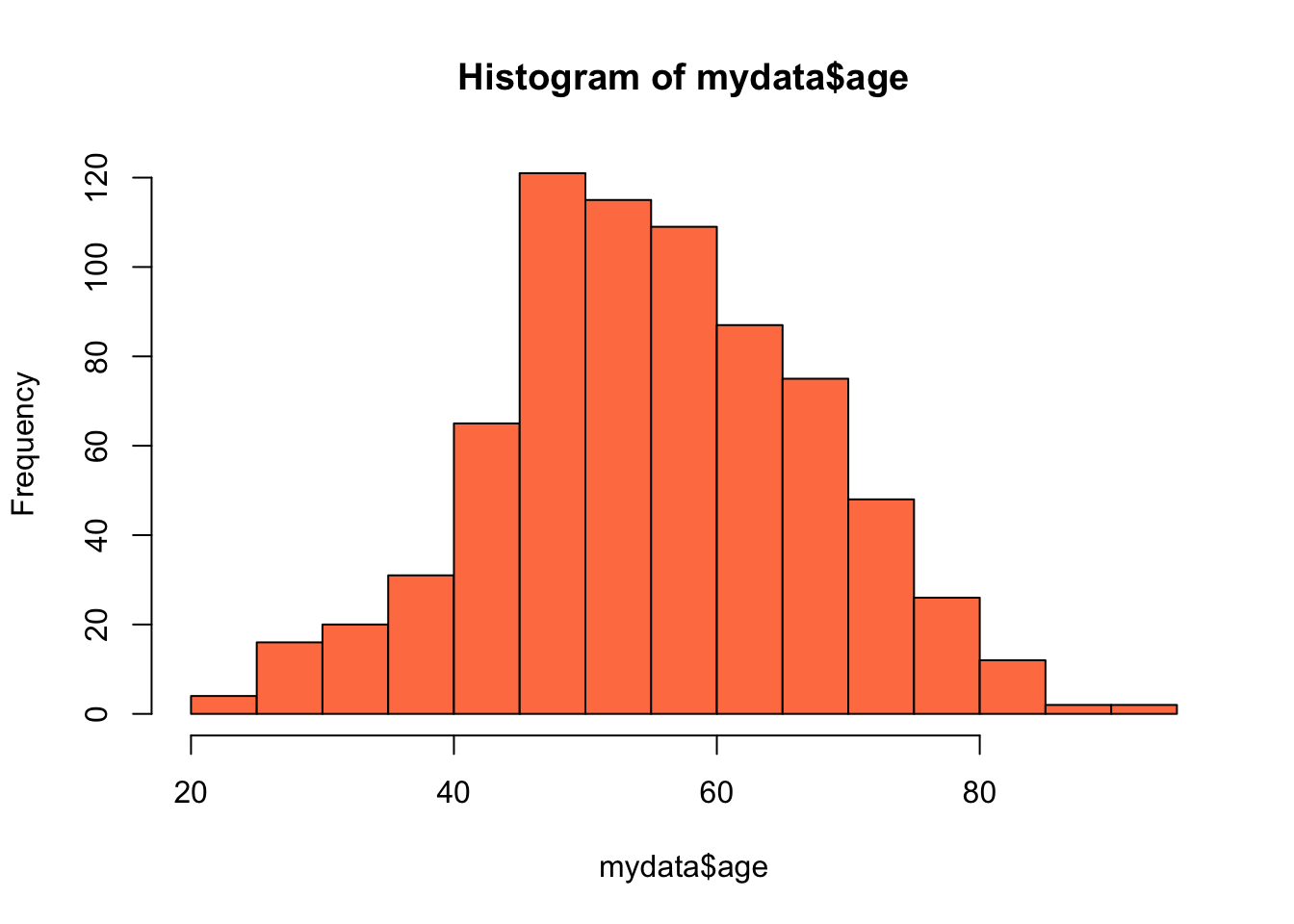
3 数据整理
3.1 排序
library(dplyr)
mydata <- arrange(mydata, age)#按照某列升序排序
mydata$age[1:10] [1] 23 24 24 24 26 27 27 27 27 28mydata <- arrange(mydata, desc(age))#按照某列降序排序
mydata$age[1:10] [1] 95 92 89 87 85 85 85 84 82 82mydata <- arrange(mydata, his, tumor_size)#根据多列排序
mydata[1:5,c("his", "tumor_size")] his tumor_size
1 LMS 10
2 LMS 12
3 LMS 12
4 LMS 15
5 LMS 17mydata[445:455,c("his", "tumor_size")] his tumor_size
445 LMS NA
446 LMS NA
447 LMS NA
448 LMS NA
449 ESS 4
450 ESS 5
451 ESS 5
452 ESS 9
453 ESS 10
454 ESS 10
455 ESS 12也可用自带base包内的order()函数排序:
mydata <- mydata[order(mydata$age),]
mydata <- mydata[order(-mydata$age),]
mydata <- mydata[order(mydata$age, mydata$his, mydata$tumor_size),]3.2 重新命名行、列
3.2.1 重新命名变量(列)
names(mydata) <- c("N","patient_ID","diagnosis") # 连续命名
colnames(mydata)[2] <- 'patient_ID'# 重新命名指定列名3.2.2 设置行名
rownames(mydata) <- mydata$ID # 将ID列设置为行名(注意不能有重复值)3.3 数据筛选
3.3.1 提取某几列数据形成新的数据集
vnumber <- mydata[, 4:16] # 提取第4-16列的数据形成新的“vnumber”数据集
vnumber <- mydata[,c(2:12,16)] # 提取2-12列和第16列的数据3.3.2 提取指定行数的数据
mydata_less <- mydata[1:100, ]#提取1-100行的数据3.3.3 筛选数据
筛选出低级别、接受了放疗的病例,并生成新的”new_data”数据集
#方法一
new_data<-subset(mydata,grade == "Well differentiated; Grade I" & rad == "Yes")
new_data[,c("grade", "rad")] grade rad
140 Well differentiated; Grade I Yes
160 Well differentiated; Grade I Yes
486 Well differentiated; Grade I Yes
541 Well differentiated; Grade I Yes
593 Well differentiated; Grade I Yes
697 Well differentiated; Grade I Yes#也可用“|”(或者),“!”(NOT)连接
#方法二
new_data <- mydata[which((mydata$grade == "Well differentiated; Grade I") &
(mydata$rad == "Yes")),]
new_data[,c("grade", "rad")] grade rad
140 Well differentiated; Grade I Yes
160 Well differentiated; Grade I Yes
486 Well differentiated; Grade I Yes
541 Well differentiated; Grade I Yes
593 Well differentiated; Grade I Yes
697 Well differentiated; Grade I Yes3.4 合并两个数据集
3.4.1 纵向合并
即增加个案,要求两个数据集具有相同的列名及列数
rbind_data <- rbind(mydata, mydata2)3.4.2 横向合并
直接通过cbind()函数合并数据集,要求两个数据集具有相同的行数及顺序
total <- cbind(dataframeA, dataframeB)3.4.3 以某一列(如学号等)匹配两个数据集
详细解读:merge()函数--R语言_merge函数-CSDN博客
# 以"probe_id"为匹配标准匹配探针id和gene symbol
exptab1 <- merge(x = ids,
y = expset1,#x、y为要合并的数据框或者对象
by ="probe_id", #指定以哪一列为标准匹配两个数据集。
#如果有多个匹配项,则所有可能的匹配项各贡献一行。
all.x=F,#是否将没有匹配到y数据集的行也保留下来,并以NA替代。
#默认为FALSE,只有x与y数据框相匹配的行会被包含在输出结果中
all.y=F)#与上面类似如果两个数据集要用来匹配的列的列名不同则可用by.x和by.y指定。如下面的代码就是用id2symbol数据集中的ENSEMBL列去匹配rawcount数据集中的GeneID列
rawcount <- merge(id2symbol,
rawcount,
by.x="ENSEMBL",
by.y="GeneID",
all.y=T)#对于没有匹配到的GeneID以NA替代
3.5 去重(保留唯一值)
生成带有重复值的示例数据
set.seed(123)
mydata = data.frame(ID = c(1:10,9,4,4,9,9,2), y = rnorm(16))
mydata <- rbind(mydata, mydata)
mydata ID y
1 1 -0.56047565
2 2 -0.23017749
3 3 1.55870831
4 4 0.07050839
5 5 0.12928774
6 6 1.71506499
7 7 0.46091621
8 8 -1.26506123
9 9 -0.68685285
10 10 -0.44566197
11 9 1.22408180
12 4 0.35981383
13 4 0.40077145
14 9 0.11068272
15 9 -0.55584113
16 2 1.78691314
17 1 -0.56047565
18 2 -0.23017749
19 3 1.55870831
20 4 0.07050839
21 5 0.12928774
22 6 1.71506499
23 7 0.46091621
24 8 -1.26506123
25 9 -0.68685285
26 10 -0.44566197
27 9 1.22408180
28 4 0.35981383
29 4 0.40077145
30 9 0.11068272
31 9 -0.55584113
32 2 1.78691314通过duplicated()函数检查某一列是否有重复值,及有多少重复值
table(duplicated(mydata$ID))
FALSE TRUE
10 22 通过unique()函数去除完全相同的行。unique()函数:一行的所有数据都相同认定为重复
mydata <- unique(mydata)
mydata ID y
1 1 -0.56047565
2 2 -0.23017749
3 3 1.55870831
4 4 0.07050839
5 5 0.12928774
6 6 1.71506499
7 7 0.46091621
8 8 -1.26506123
9 9 -0.68685285
10 10 -0.44566197
11 9 1.22408180
12 4 0.35981383
13 4 0.40077145
14 9 0.11068272
15 9 -0.55584113
16 2 1.78691314通过distinct()函数,去除ID列重复的数据
library(dplyr)
mydata <- distinct(mydata, # 需要去重的数据集名称
ID, # 按照哪一列去重(可为多个条件)
.keep_all = T) # 去重后保留所有列
mydata ID y
1 1 -0.56047565
2 2 -0.23017749
3 3 1.55870831
4 4 0.07050839
5 5 0.12928774
6 6 1.71506499
7 7 0.46091621
8 8 -1.26506123
9 9 -0.68685285
10 10 -0.445661973.6 转换变量类型
将结局变量转换成因子变量,ordered=F,用于定义无序多分类变量,起到设置哑变量的作用;ordered=T用于定义有序多分类变量。如果变量的取值以英文字符表示,那么默认以变量首字母的顺序编号赋值;如果变量的取值已经转换成数字,那么默认按照编号的大小依次赋值。可以通过指定”levels”选项来覆盖默认排序。
savdata$stage <- factor(savdata$stage,
levels = c(1,2,3,4),
labels = c("I","II","III","IV"),
ordered = T)
savdata$stage <- relevel(savdata$stage,ref="IV") # 设置因子的参照水平,仅限无序因子变量通过lapply函数批量转换因子变量
mydata[2:14] <- lapply(mydata[2:14], factor) # 转换几个连续列的因子变量批量转换多个指定因子变量
catvars<-c("year", "race", "single", "grade", "T_stage", "N_stage", "M_stage",
"surgery", "lymphadenectomy", "radiotherapy", "chemotherapy")
mydata[catvars] <- lapply(mydata[catvars], factor)转换为数值型变量
mydata$grade <- as.numeric(mydata$grade)
mydata = lapply(mydata, as.numeric) # 将所有的变量转换成数值型3.7 哑变量设置
# 因种族为无序多分类变量,需要设置三个哑变量(race1~3)
savdata$race1 <- ifelse(savdata$race == "白种人", 1, 0)
savdata$race2 <- ifelse(savdata$race == "黑种人", 1, 0)
savdata$race3 <- ifelse(savdata$race == "其他种族", 1, 0)4 数学函数
abs(-4) #取绝对值[1] 4sqrt(16) #开平方根[1] 4log(4,base=2) #取2为底的对数[1] 2log10(100) #取10为底的对数[1] 2log(2) #取2的自然对数[1] 0.6931472exp(2) #取e的指数函数[1] 7.389056#设置小数位数
ceiling(3.14159) #取不小于x的最小整数(有小数点一律进一位)[1] 4floor(3.99999) #取不大于x的最大整数(忽略小数点)[1] 3sprintf("%0.3f", 3.14159) #四舍五入保留3位小数[1] "3.142"round(3.14159,digits=3) #同上。注意该函数在处理科学计数法时无法有效保留目标小数位数[1] 3.1425 自定义函数
R语言可以自定义函数,也可以使用其自带的函数。
R语言中,自定义函数的一般格式为:
函数名 <- function(输入1,……,输入n){
函数体
return(返回值)
}其中,return并不是必需的,默认函数体最后一行的值作为返回值,即return完全可以换成”返回值”。下面以判断score为优良及格差的代码进行讲解。案例来源:https://zhuanlan.zhihu.com/p/441710174。
首先对于不用函数的情况
score = 73
if(score >= 90){
res = "优"
}else if(score >=70){
res = "良"
}else if(score >= 60){
res = "及格"
}else{
res = "不及格"
}
res#输出判断结果[1] "良"接下来我们自定义一个scorejudge()函数实现对单个成绩对判断。实际上就是把上面的代码封装起来
scorejudge<-function(x){
if(score >= 90){
res = "优"
}else if(score >=70){
res = "良"
}else if(score >= 60){
res = "及格"
}else{
res = "不及格"
}
paste0("该同学的分数等级为",res)
}
scorejudge(score)#就像调用R自带函数一样调用我们自己编写的函数[1] "该同学的分数等级为良"如若想要同时查询多个分数,则需要对原来的代码进行修改,加入for循环语句
scorejudge<-function(x){
n = length(x)#首先确定循环次数,即x中有多少个分数,下面的for循环就要运行多少次
res = vector("character",n)#建立一个和输入的分数个数相同的空向量,用来放每次for循环的输出结果
for(i in 1:n){
if(x[i] >= 90){
res[i] = paste0(i,"号同学的分数等级为","优")
} else if(x[i] >=70){
res[i] = paste0(i,"号同学的分数等级为","良")
} else if(x[i] >= 60){
res[i] = paste0(i,"号同学的分数等级为","及格")
} else{
res[i] = paste0(i,"号同学的分数等级为","不及格")
}
}
res #输出最终的res向量
}
scorejudge(c(34,67,89,95))[1] "1号同学的分数等级为不及格" "2号同学的分数等级为及格"
[3] "3号同学的分数等级为良" "4号同学的分数等级为优" ### 基于dplyr包的数据整理
Code
参考:
Data transformation chapter in R for Data Science

1 介绍
dplyr包是tidyverse的核心包之一,为数据处理提供了一系列方便快捷的函数。本章将以nycflights13包中的flights案例数据来介绍基于dplyr包的数据处理语法。该数据集包含 2013 年从纽约市起飞的所有 336,776 次航班的信息。
library(dplyr)
data(flights, package = "nycflights13")
flights# A tibble: 336,776 × 19
year month day dep_time sched_dep_time dep_delay arr_time sched_arr_time
<int> <int> <int> <int> <int> <dbl> <int> <int>
1 2013 1 1 517 515 2 830 819
2 2013 1 1 533 529 4 850 830
3 2013 1 1 542 540 2 923 850
4 2013 1 1 544 545 -1 1004 1022
5 2013 1 1 554 600 -6 812 837
6 2013 1 1 554 558 -4 740 728
7 2013 1 1 555 600 -5 913 854
8 2013 1 1 557 600 -3 709 723
9 2013 1 1 557 600 -3 838 846
10 2013 1 1 558 600 -2 753 745
# ℹ 336,766 more rows
# ℹ 11 more variables: arr_delay <dbl>, carrier <chr>, flight <int>,
# tailnum <chr>, origin <chr>, dest <chr>, air_time <dbl>, distance <dbl>,
# hour <dbl>, minute <dbl>, time_hour <dttm>这里的flights数据是一个 tibble,这是一种升级版的data.frame,被 tidyverse 用来避免一些data.frame的常见问题。Tibbles 和data.frame之间的一个重要的区别在于 tibbles 打印数据的方式:tibbles 是为大型数据集设计的,因此只显示前几行和适应屏幕宽度的列(如上)。可以使用 print(flights, width = Inf) 显示所有列,或者使用 glimpse():
glimpse(flights)Rows: 336,776
Columns: 19
$ year <int> 2013, 2013, 2013, 2013, 2013, 2013, 2013, 2013, 2013, 2…
$ month <int> 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1…
$ day <int> 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1…
$ dep_time <int> 517, 533, 542, 544, 554, 554, 555, 557, 557, 558, 558, …
$ sched_dep_time <int> 515, 529, 540, 545, 600, 558, 600, 600, 600, 600, 600, …
$ dep_delay <dbl> 2, 4, 2, -1, -6, -4, -5, -3, -3, -2, -2, -2, -2, -2, -1…
$ arr_time <int> 830, 850, 923, 1004, 812, 740, 913, 709, 838, 753, 849,…
$ sched_arr_time <int> 819, 830, 850, 1022, 837, 728, 854, 723, 846, 745, 851,…
$ arr_delay <dbl> 11, 20, 33, -18, -25, 12, 19, -14, -8, 8, -2, -3, 7, -1…
$ carrier <chr> "UA", "UA", "AA", "B6", "DL", "UA", "B6", "EV", "B6", "…
$ flight <int> 1545, 1714, 1141, 725, 461, 1696, 507, 5708, 79, 301, 4…
$ tailnum <chr> "N14228", "N24211", "N619AA", "N804JB", "N668DN", "N394…
$ origin <chr> "EWR", "LGA", "JFK", "JFK", "LGA", "EWR", "EWR", "LGA",…
$ dest <chr> "IAH", "IAH", "MIA", "BQN", "ATL", "ORD", "FLL", "IAD",…
$ air_time <dbl> 227, 227, 160, 183, 116, 150, 158, 53, 140, 138, 149, 1…
$ distance <dbl> 1400, 1416, 1089, 1576, 762, 719, 1065, 229, 944, 733, …
$ hour <dbl> 5, 5, 5, 5, 6, 5, 6, 6, 6, 6, 6, 6, 6, 6, 6, 5, 6, 6, 6…
$ minute <dbl> 15, 29, 40, 45, 0, 58, 0, 0, 0, 0, 0, 0, 0, 0, 0, 59, 0…
$ time_hour <dttm> 2013-01-01 05:00:00, 2013-01-01 05:00:00, 2013-01-01 0…在这两种视图中,变量名下方或后面都有相应的缩写,代表每个变量的类型:<int> 代表整数型数据, 代表数值型数据, 代表字符型数据, 代表日期时间型数据。这些变量非常重要,因为对列进行的操作在很大程度上取决于该列的 “类型”。更多关于tibble的说明参考tibble包的官方文档。

dplyr语法的共同特点:
-
第一个参数始终是数据集(tibble或data.frame)的名字。
-
后面的参数通常使用变量名(不带引号)来描述要对哪些列进行操作。
-
输出总是一个新的tibble或data.frame。
dplyr 的函数可以根据它们的操作对象分为四类:分别是对行进行操作的函数、对列进行操作的函数、对表进行操作的函数以及分组统计函数,同时还包括一个特殊的管道符号%>%。本章将介绍除对表进行操作之外的函数。
2 管道操作符
R中有两种管道操作符(pipe operator),分别是R自带的来自base包的|>,和来自magrittr包(上级包是dplyr和tidyverse)的%>%。我们可以将管道操作符理解为车间里的流水线,经过前一步加工的产品才能进入后一步进一步加工,其作用是将上一步的结果直接传参给下一步的函数,从而省略了中间的赋值步骤,可以大量减少中间变量,节省内存。例如:
# 不使用管道操作服
x <- rnorm(10)
y <- sort(x)
plot(y)
# 管道调用
rnorm(10) |> sort() |> plot()
# or
10 |> rnorm() |> sort() |> plot()如果x, y并不会被后面的代码用到的话,那么减少这种中间变量的产生是有利于代码的整洁和降低变量冲突的风险的。
如果不使用管道操作,同时要避免产生中间变量的话就需要嵌套代码,而管道操作则通过一种链式调用的方式去写嵌套调用的代码,使代码更清晰和易于理解。比如:
# 嵌套调用
plot(sort(rnorm(10)))
# 管道调用
rnorm(10) |> sort() |> plot()很明显管道的调用逻辑要比嵌套调用更加清晰而符合直觉。
Tip
-
来自
magrittr包的管道符%>%和base包的|>存在一些语法上的区别,%>%的功能更多(见下文)。 -
在一般使用时,如果不需要
%>%的高级功能,建议直接用从2021年的R 4.1.0开始原生支持的|>作为默认管道符。如果需要用到高级功能,或习惯tidyverse包的数据处理语法,则再考虑使用%>%。 -
RStudio目前通过快捷键
Command+Shift+M默认插入的是%>%符号,可以通过在设置中勾选如下选项来让该快捷键默认插入|>。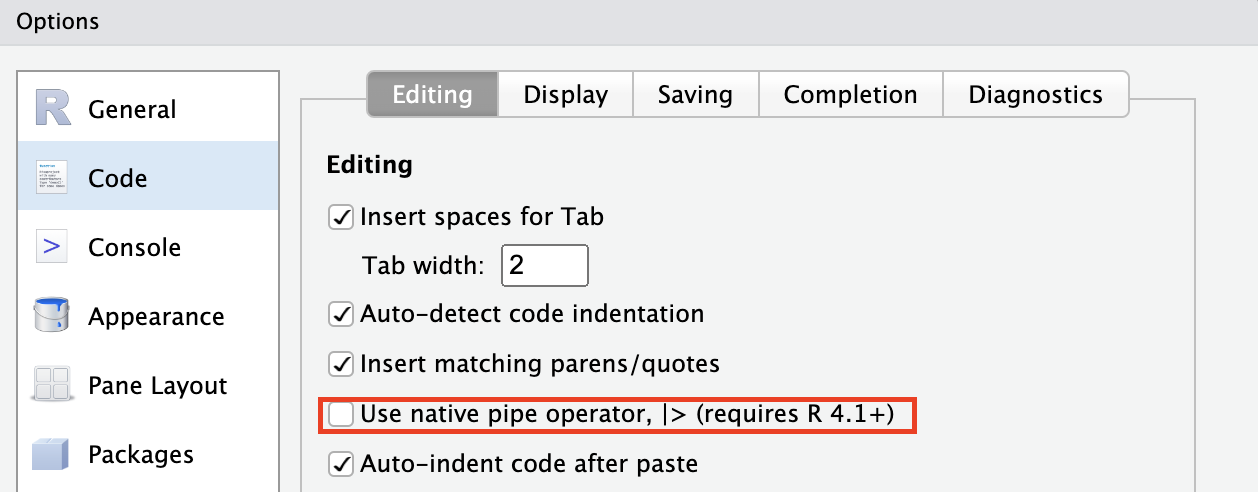
2.1 管道的基本用法
管道的用法就是通过管道符|>或%>%串联起来前后的两个函数调用,先计算管道符号左边的函数调用,然后将其结果自动传递给管道符号右边函数的第一个参数(默认),然后对运行这个函数,正如上面的例子中提到的一样。如果不想把值传递给第一个参数,则可以用占位符_(适用于|>)或.(适用于%>%)的形式指定把前面的运算结果传递给哪个参数。
比如想在mtcars数据集的车名中寻找所有以“M”开头的车名,则可以通过如下方式寻找:
mtcars |> rownames() |> grep("^M", x = _) [1] 1 2 8 9 10 11 12 13 14 31#或用%>%形式
library(magrittr) # 也可以直接加载dplyr或tidyverse包,便于后续调用其他tidyverse函数
mtcars %>% rownames() %>% grep(pattern = "^M", x = .) [1] 1 2 8 9 10 11 12 13 14 31解释如下:在grep函数那里,由于我们想在车名(这里是行名)中找到符合特定pattern的车名位置,因此需要把车名传给grep的第二个参数x,所以就可以.或_的形式将前面的值传给grep的x。
⚠️注意:传给其他位置的.必须是独立的,不能在一个表达式(函数)中,比如如下情况,我只想寻找前10个车名中以“M”开头的车名位置:
# 错误 ---------------
mtcars %>% rownames %>% grep("^M", x = .[1:10])Warning in grep(., "^M", x = .[1:10]): argument 'pattern' has length > 1 and
only the first element will be used[1] 1 2# 正确 ---------------
mtcars[1:10, ] %>% rownames %>% grep("^M", x = .)[1] 1 2 8 9 10上面的错误调用中,传递给grep的x参数的是一个表达式.[1:10],不是一个单独的.了,因此失去了调整前面值的位置的作用,它就等价于如下调用:
# 错误 ---------------
mtcars %>% rownames %>% grep("^M", x = .[1:10])
# 等价于 --------------
# 还是把前面的值传递给第一个参数:
mtcars %>% rownames %>% grep(., "^M", x = .[1:10])2.2 管道的进阶用法
我们可以通过“{}”符号包裹后续函数,在“{}”内的代码,可以任意的使用多个占位符.去传递管道前的值。还是上面的例子:
mtcars[1:10, ] %>% rownames() %>% grep("^M", x = .) %>% plot()
# 用“{}”的形式 ---------------
mtcars %>% rownames %>% {
grep("^M", x = .[1:10])} %>% plot()⚠️注意,|>不支持“{}”形式:
# 错误:
mtcars |> rownames() |> {grep("^M", x = _[1:10])}这也反映出base包|>功能的局限性。
本质上“{}”是magrittr改写的一个匿名函数,只有唯一的一个参数,也就是. :
function(.) {
# any code
}比如想要获取mtcars的前5行前5列,然后更改行名和列名后,再返回这个数据框:
df <- mtcars %>% .[1:5, 1:5] %>%
{
rownames(.) <- paste0("row", 1:5)
colnames(.) <- paste0("col", 1:5)
. # <---------- 不要忘了返回这个数据框
}
df col1 col2 col3 col4 col5
row1 21.0 6 160 110 3.90
row2 21.0 6 160 110 3.90
row3 22.8 4 108 93 3.85
row4 21.4 6 258 110 3.08
row5 18.7 8 360 175 3.15⚠️注意,在整个“{}”包括的语句中,如果再使用管道要注意这时的占位符.代表的是“{}”内的对象。
mtcars %>% .[1:5, 1:5] %>%
{
rownames(.) <- paste0("row", 1:5)
colnames(.) <- paste0("col", 1:5)
.[1:3, ] %>% cbind(., .) # cbind里面的.不指代{}外面的值
} col1 col2 col3 col4 col5 col1 col2 col3 col4 col5
row1 21.0 6 160 110 3.90 21.0 6 160 110 3.90
row2 21.0 6 160 110 3.90 21.0 6 160 110 3.90
row3 22.8 4 108 93 3.85 22.8 4 108 93 3.85# 等价:
mtcars %>% .[1:5, 1:5] %>%
{
rownames(.) <- paste0("row", 1:5)
colnames(.) <- paste0("col", 1:5)
.
} %>%
.[1:3, ] %>%
cbind(., .) col1 col2 col3 col4 col5 col1 col2 col3 col4 col5
row1 21.0 6 160 110 3.90 21.0 6 160 110 3.90
row2 21.0 6 160 110 3.90 21.0 6 160 110 3.90
row3 22.8 4 108 93 3.85 22.8 4 108 93 3.852.3 特殊管道符
magrittr包内除了%>%管道符外,还提供了%$%、%<>%、%T>%、%!>%,他们的作用简述如下:
2.3.1 %$%
用于传递管道左侧数据的names:
colnames(mtcars) [1] "mpg" "cyl" "disp" "hp" "drat" "wt" "qsec" "vs" "am" "gear"
[11] "carb"# mtcars的每个元素都可以被后面的函数所使用
mtcars %$% plot(mpg, cyl)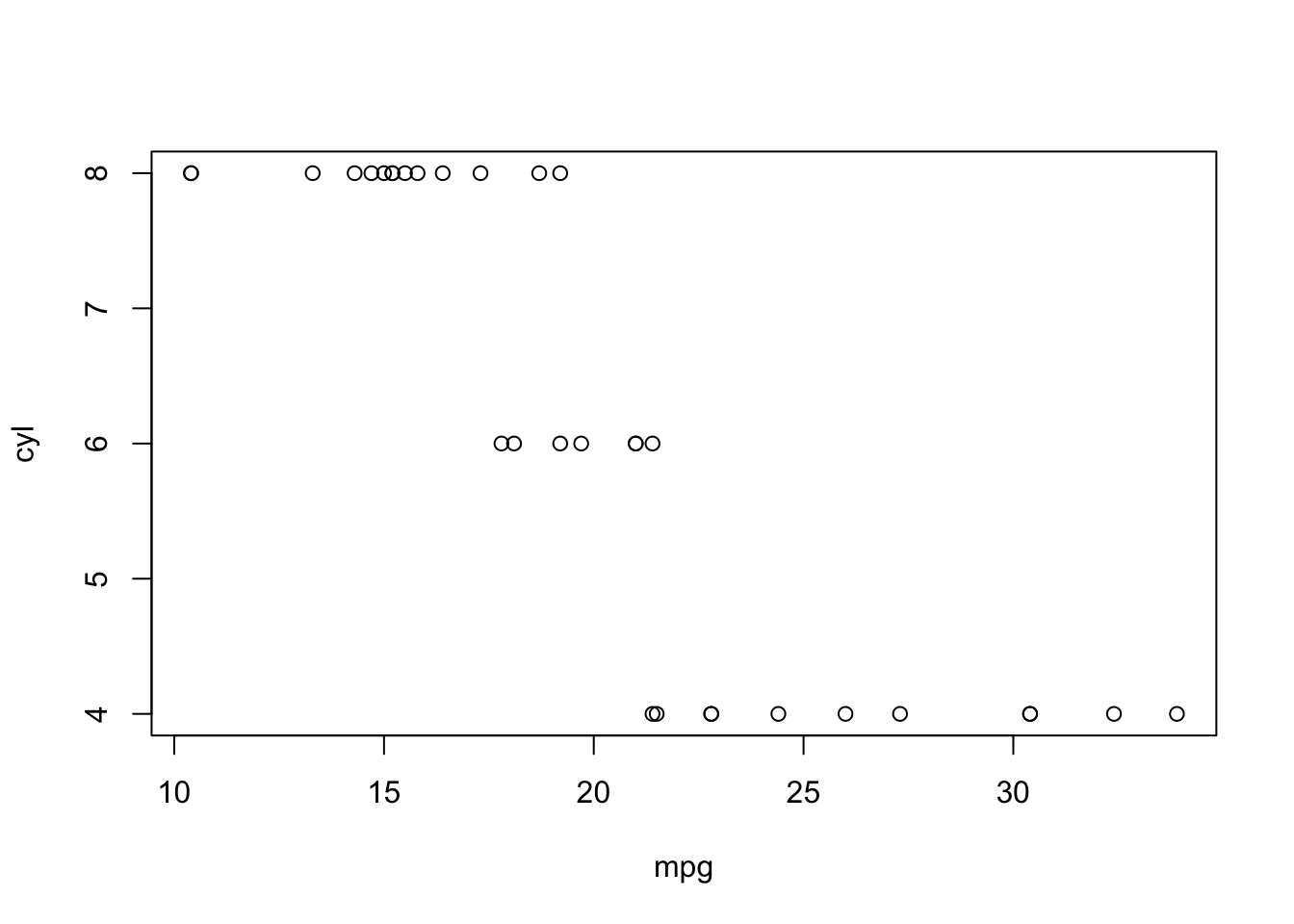
# 等价于
mtcars %>% {
plot(.[,"mpg"], .[, "cyl"])}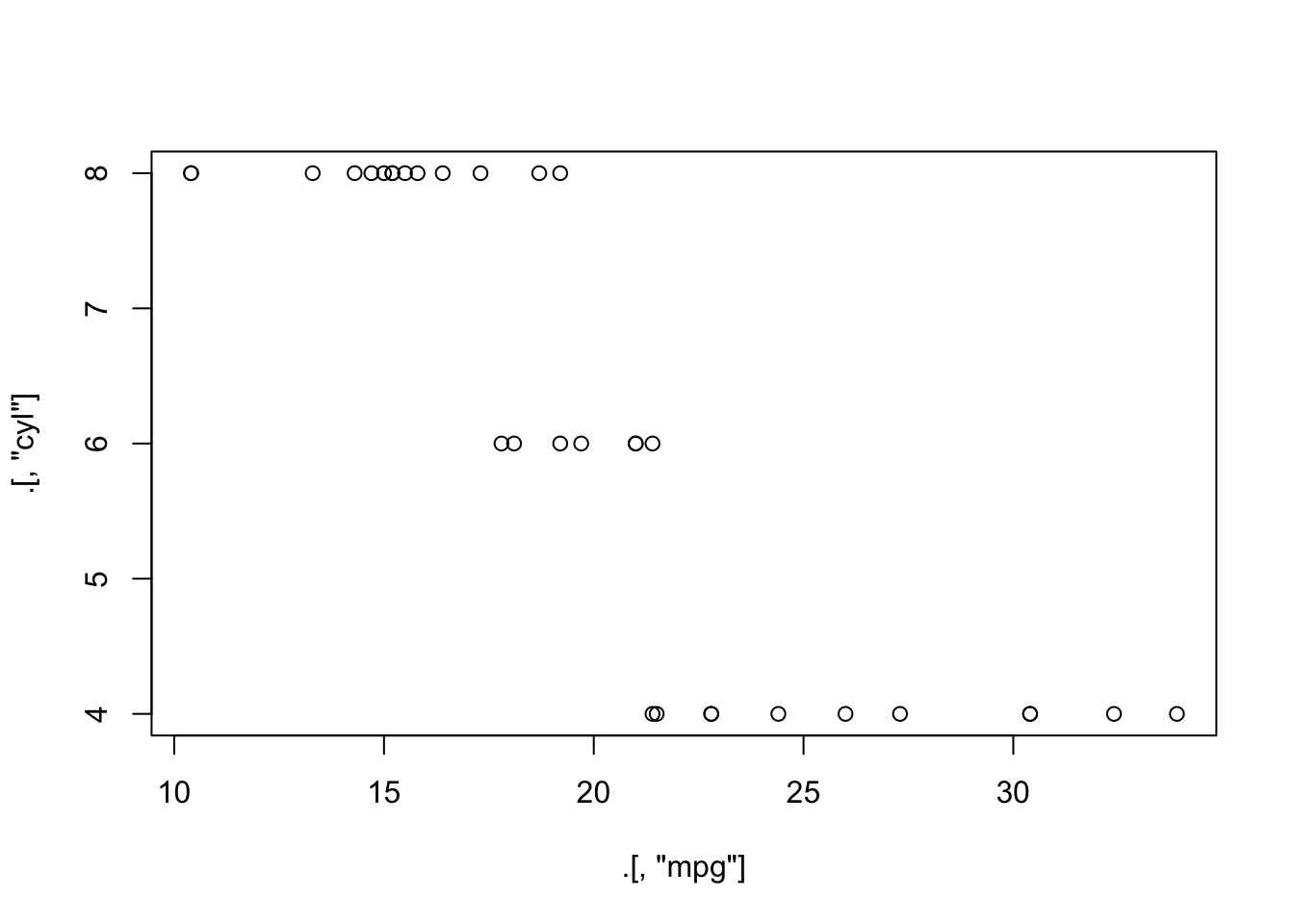
sum(mtcars$mpg, mtcars$cyl)[1] 840.92.3.2 %<>%
将管道的结果最终再赋值回最左侧的变量:
set.seed(1234)
x <- rnorm(5)
x[1] -1.2070657 0.2774292 1.0844412 -2.3456977 0.4291247# x排序后加上10,最后再赋值给x
x %<>% sort() %>% {. + 10}
x[1] 7.654302 8.792934 10.277429 10.429125 11.084441# 等价于
x <- x %>% sort() %>% {. + 10}2.3.3 %T>%
分支管道,传入左侧的值并运算后将原始值而不是运算结果传递给后续管道。这在多个管道中间使用print()、plot()或summary()这些函数返回信息时非常有用。
1:5 %>% plot() %>% sum() # 传递给sum()的是前面所有函数的运算结果,由于plot()不返回任何数值,所以sum()的结果为0[1] 01:5 %T>% plot() %>% sum() # 传递给sum()的是1:5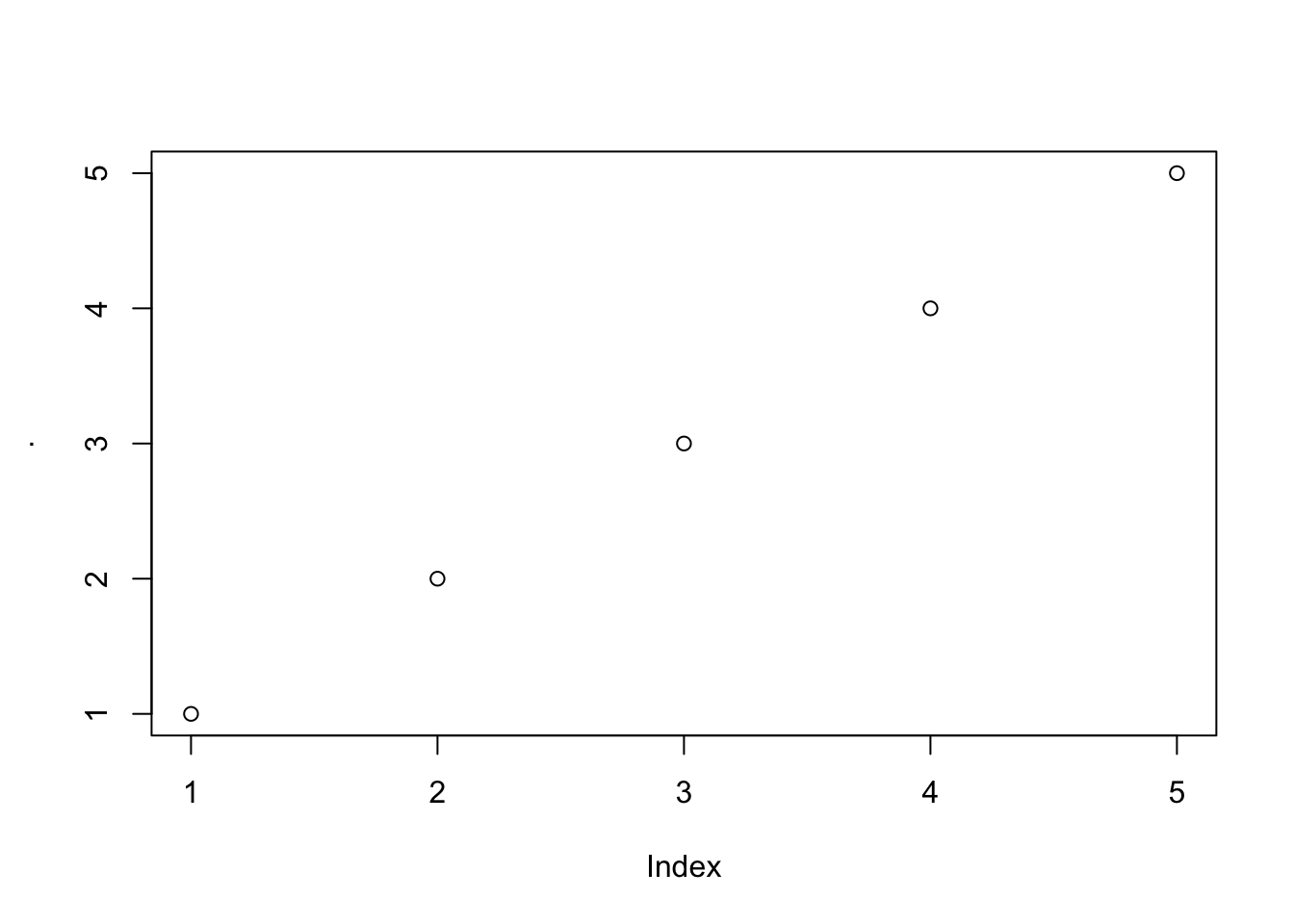
[1] 15# 另一个例子
rnorm(200) %>%
matrix(ncol = 2) %T>%
plot %>%
colSums() # 传递给colSums()的是“rnorm(200) %>% matrix(ncol = 2)”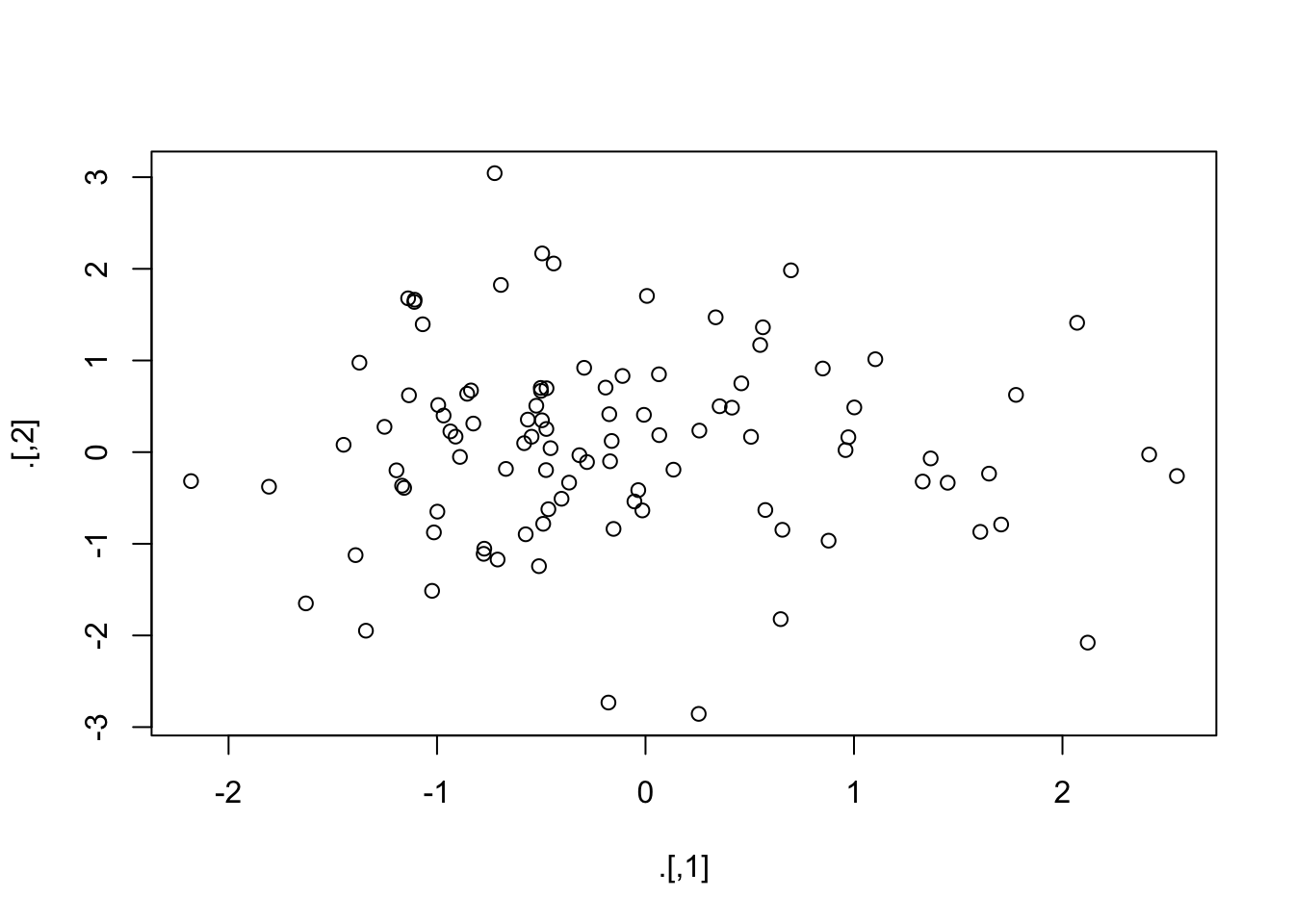
[1] -15.23708 7.826923 对行的操作
3.1 filter()
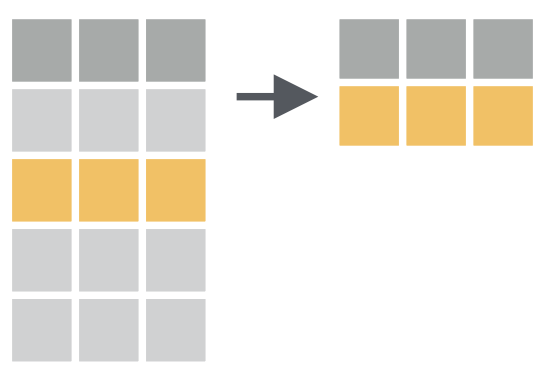
用于提取满足某(些)条件的行,基本等同于subset()。
# 查找所有晚点 120 分钟(两小时)以上起飞的航班:
filter(flights, dep_delay > 120)# A tibble: 9,723 × 19
year month day dep_time sched_dep_time dep_delay arr_time sched_arr_time
<int> <int> <int> <int> <int> <dbl> <int> <int>
1 2013 1 1 848 1835 853 1001 1950
2 2013 1 1 957 733 144 1056 853
3 2013 1 1 1114 900 134 1447 1222
4 2013 1 1 1540 1338 122 2020 1825
5 2013 1 1 1815 1325 290 2120 1542
6 2013 1 1 1842 1422 260 1958 1535
7 2013 1 1 1856 1645 131 2212 2005
8 2013 1 1 1934 1725 129 2126 1855
9 2013 1 1 1938 1703 155 2109 1823
10 2013 1 1 1942 1705 157 2124 1830
# ℹ 9,713 more rows
# ℹ 11 more variables: arr_delay <dbl>, carrier <chr>, flight <int>,
# tailnum <chr>, origin <chr>, dest <chr>, air_time <dbl>, distance <dbl>,
# hour <dbl>, minute <dbl>, time_hour <dttm># 查找一月或二月起飞的航班
filter(flights, month %in% c(1, 2))# A tibble: 51,955 × 19
year month day dep_time sched_dep_time dep_delay arr_time sched_arr_time
<int> <int> <int> <int> <int> <dbl> <int> <int>
1 2013 1 1 517 515 2 830 819
2 2013 1 1 533 529 4 850 830
3 2013 1 1 542 540 2 923 850
4 2013 1 1 544 545 -1 1004 1022
5 2013 1 1 554 600 -6 812 837
6 2013 1 1 554 558 -4 740 728
7 2013 1 1 555 600 -5 913 854
8 2013 1 1 557 600 -3 709 723
9 2013 1 1 557 600 -3 838 846
10 2013 1 1 558 600 -2 753 745
# ℹ 51,945 more rows
# ℹ 11 more variables: arr_delay <dbl>, carrier <chr>, flight <int>,
# tailnum <chr>, origin <chr>, dest <chr>, air_time <dbl>, distance <dbl>,
# hour <dbl>, minute <dbl>, time_hour <dttm>3.2 arrange()
排序,以某列为依据对行进行排序(在前面的数据处理基本函数一章中已涉及该函数)。对应的功能在base包中是order()函数。如果提供的列名不止一个,则依次根据提供的列的顺序对数据进行排序。例如,下面的代码按航班出发时间排序,出发时间分布在四列中。我们首先得到最早的年份,然后在一年内得到最早的月份,依此类推。
arrange(flights, year, month, day, dep_time)# A tibble: 336,776 × 19
year month day dep_time sched_dep_time dep_delay arr_time sched_arr_time
<int> <int> <int> <int> <int> <dbl> <int> <int>
1 2013 1 1 517 515 2 830 819
2 2013 1 1 533 529 4 850 830
3 2013 1 1 542 540 2 923 850
4 2013 1 1 544 545 -1 1004 1022
5 2013 1 1 554 600 -6 812 837
6 2013 1 1 554 558 -4 740 728
7 2013 1 1 555 600 -5 913 854
8 2013 1 1 557 600 -3 709 723
9 2013 1 1 557 600 -3 838 846
10 2013 1 1 558 600 -2 753 745
# ℹ 336,766 more rows
# ℹ 11 more variables: arr_delay <dbl>, carrier <chr>, flight <int>,
# tailnum <chr>, origin <chr>, dest <chr>, air_time <dbl>, distance <dbl>,
# hour <dbl>, minute <dbl>, time_hour <dttm>可以加上desc()实现降序排列:
arrange(flights, desc(dep_delay))# A tibble: 336,776 × 19
year month day dep_time sched_dep_time dep_delay arr_time sched_arr_time
<int> <int> <int> <int> <int> <dbl> <int> <int>
1 2013 1 9 641 900 1301 1242 1530
2 2013 6 15 1432 1935 1137 1607 2120
3 2013 1 10 1121 1635 1126 1239 1810
4 2013 9 20 1139 1845 1014 1457 2210
5 2013 7 22 845 1600 1005 1044 1815
6 2013 4 10 1100 1900 960 1342 2211
7 2013 3 17 2321 810 911 135 1020
8 2013 6 27 959 1900 899 1236 2226
9 2013 7 22 2257 759 898 121 1026
10 2013 12 5 756 1700 896 1058 2020
# ℹ 336,766 more rows
# ℹ 11 more variables: arr_delay <dbl>, carrier <chr>, flight <int>,
# tailnum <chr>, origin <chr>, dest <chr>, air_time <dbl>, distance <dbl>,
# hour <dbl>, minute <dbl>, time_hour <dttm>3.3 distinct()
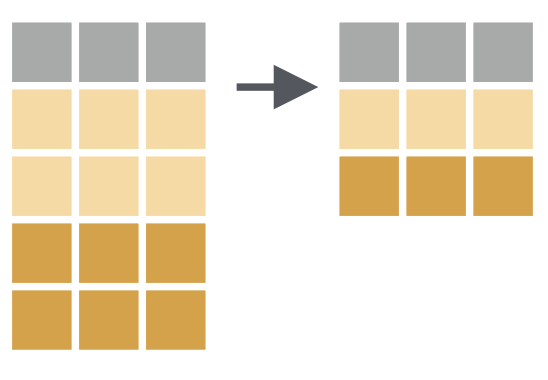
查找数据集中所有唯一的行。
# 移除所有完全相同的行
distinct(flights)# A tibble: 336,776 × 19
year month day dep_time sched_dep_time dep_delay arr_time sched_arr_time
<int> <int> <int> <int> <int> <dbl> <int> <int>
1 2013 1 1 517 515 2 830 819
2 2013 1 1 533 529 4 850 830
3 2013 1 1 542 540 2 923 850
4 2013 1 1 544 545 -1 1004 1022
5 2013 1 1 554 600 -6 812 837
6 2013 1 1 554 558 -4 740 728
7 2013 1 1 555 600 -5 913 854
8 2013 1 1 557 600 -3 709 723
9 2013 1 1 557 600 -3 838 846
10 2013 1 1 558 600 -2 753 745
# ℹ 336,766 more rows
# ℹ 11 more variables: arr_delay <dbl>, carrier <chr>, flight <int>,
# tailnum <chr>, origin <chr>, dest <chr>, air_time <dbl>, distance <dbl>,
# hour <dbl>, minute <dbl>, time_hour <dttm># 查找所有唯一的出发地和目的地配对
distinct(flights, origin, dest)# A tibble: 224 × 2
origin dest
<chr> <chr>
1 EWR IAH
2 LGA IAH
3 JFK MIA
4 JFK BQN
5 LGA ATL
6 EWR ORD
7 EWR FLL
8 LGA IAD
9 JFK MCO
10 LGA ORD
# ℹ 214 more rows可以看到,如果根据某列或某几列为依据来查找非重复值,那么默认只输出这几列,我们可以通过加入.keep_all = TRUE参数来保留其他列。.表示 .keep_all 是函数的一个参数,而不是另一个变量的名称。
distinct(flights, origin, dest, .keep_all = TRUE)# A tibble: 224 × 19
year month day dep_time sched_dep_time dep_delay arr_time sched_arr_time
<int> <int> <int> <int> <int> <dbl> <int> <int>
1 2013 1 1 517 515 2 830 819
2 2013 1 1 533 529 4 850 830
3 2013 1 1 542 540 2 923 850
4 2013 1 1 544 545 -1 1004 1022
5 2013 1 1 554 600 -6 812 837
6 2013 1 1 554 558 -4 740 728
7 2013 1 1 555 600 -5 913 854
8 2013 1 1 557 600 -3 709 723
9 2013 1 1 557 600 -3 838 846
10 2013 1 1 558 600 -2 753 745
# ℹ 214 more rows
# ℹ 11 more variables: arr_delay <dbl>, carrier <chr>, flight <int>,
# tailnum <chr>, origin <chr>, dest <chr>, air_time <dbl>, distance <dbl>,
# hour <dbl>, minute <dbl>, time_hour <dttm>可以发现所有这些不同的航班都是在 1 月 1 日,这绝非巧合:distinct() 会在数据集中找到唯一值第一次出现的那一行,并舍弃其他行。
如果要得到每种出发地和目的地配对出现的次数,可以将 distinct() 换成 count(),并可使用 sort = TRUE 参数按出现次数降序排列。count()同样来自dplyr包,用于快速统计一个或多个变量的唯一值的出现次数。
count(flights, origin, dest, sort = TRUE)# A tibble: 224 × 3
origin dest n
<chr> <chr> <int>
1 JFK LAX 11262
2 LGA ATL 10263
3 LGA ORD 8857
4 JFK SFO 8204
5 LGA CLT 6168
6 EWR ORD 6100
7 JFK BOS 5898
8 LGA MIA 5781
9 JFK MCO 5464
10 EWR BOS 5327
# ℹ 214 more rows3.4 nth()
first(x) 、 last(x) 和 nth(x, n) 都是用于从向量中提取特定位置的值的函数。
-
first(x):提取x中的第一个值 -
last(x):提取x中最后一个值 -
nth(x, n):提取x中的第n个值
它们有共同的可选参数:
-
order_by:提供一个和x相同长度的向量,按照这个向量的顺序对x排序。默认是按照x的原始顺序取值。 -
na_rm:在取值前是否忽略x中的缺失值。⚠️注意不要写成了na.rm。
例如,提取每天数据中的第一个、第五个和最后一个“dep_time”记录:
flights %>%
group_by(year, month, day) |>
summarize(
first_dep = first(dep_time, na_rm = TRUE),
fifth_dep = nth(dep_time, 5, na_rm = TRUE),
last_dep = last(dep_time, na_rm = TRUE)
)# A tibble: 365 × 6
# Groups: year, month [12]
year month day first_dep fifth_dep last_dep
<int> <int> <int> <int> <int> <int>
1 2013 1 1 517 554 2356
2 2013 1 2 42 535 2354
3 2013 1 3 32 520 2349
4 2013 1 4 25 531 2358
5 2013 1 5 14 534 2357
6 2013 1 6 16 555 2355
7 2013 1 7 49 536 2359
8 2013 1 8 454 544 2351
9 2013 1 9 2 524 2252
10 2013 1 10 3 530 2320
# ℹ 355 more rows在R语言的基础函数中实现 nth(x, n) 类似效果的是“[]”。下面的代码用“[]”输出和上面相同的结果:
flights %>%
group_by(year, month, day) %>%
filter(is.na(dep_time) == F) %>%
summarize(
first_dep = dep_time[1],
fifth_dep = dep_time[5],
last_dep = dep_time[n()]
)# A tibble: 365 × 6
# Groups: year, month [12]
year month day first_dep fifth_dep last_dep
<int> <int> <int> <int> <int> <int>
1 2013 1 1 517 554 2356
2 2013 1 2 42 535 2354
3 2013 1 3 32 520 2349
4 2013 1 4 25 531 2358
5 2013 1 5 14 534 2357
6 2013 1 6 16 555 2355
7 2013 1 7 49 536 2359
8 2013 1 8 454 544 2351
9 2013 1 9 2 524 2252
10 2013 1 10 3 530 2320
# ℹ 355 more rows但是由于 first(x) 、 last(x) 和 nth(x, n) 可以定义order_by 和 na_rm 等额外参数,因此能够实现更多的应用场景。
4 对列的操作
4.1 mutate()
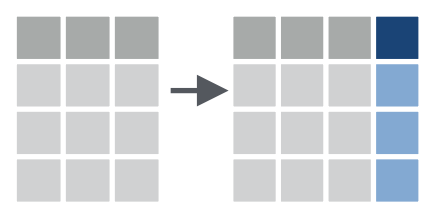
mutate()的作用是根据现有列计算并添加新列。
# 计算延误航班在空中停留的时间(gain)以及平均速度(speed,英里/小时):
mutate(
flights,
gain = dep_delay - arr_delay,
speed = distance / air_time * 60
)# A tibble: 336,776 × 21
year month day dep_time sched_dep_time dep_delay arr_time sched_arr_time
<int> <int> <int> <int> <int> <dbl> <int> <int>
1 2013 1 1 517 515 2 830 819
2 2013 1 1 533 529 4 850 830
3 2013 1 1 542 540 2 923 850
4 2013 1 1 544 545 -1 1004 1022
5 2013 1 1 554 600 -6 812 837
6 2013 1 1 554 558 -4 740 728
7 2013 1 1 555 600 -5 913 854
8 2013 1 1 557 600 -3 709 723
9 2013 1 1 557 600 -3 838 846
10 2013 1 1 558 600 -2 753 745
# ℹ 336,766 more rows
# ℹ 13 more variables: arr_delay <dbl>, carrier <chr>, flight <int>,
# tailnum <chr>, origin <chr>, dest <chr>, air_time <dbl>, distance <dbl>,
# hour <dbl>, minute <dbl>, time_hour <dttm>, gain <dbl>, speed <dbl>默认情况下,mutate() 会在数据集的最右侧添加计算后的新列,因此很难看到这里发生了什么。我们可以使用 .before 参数将变量添加到数据集的左侧:
mutate(
flights,
gain = dep_delay - arr_delay,
speed = distance / air_time * 60,
.before = 1 # 添加到第一列
)# A tibble: 336,776 × 21
gain speed year month day dep_time sched_dep_time dep_delay arr_time
<dbl> <dbl> <int> <int> <int> <int> <int> <dbl> <int>
1 -9 370. 2013 1 1 517 515 2 830
2 -16 374. 2013 1 1 533 529 4 850
3 -31 408. 2013 1 1 542 540 2 923
4 17 517. 2013 1 1 544 545 -1 1004
5 19 394. 2013 1 1 554 600 -6 812
6 -16 288. 2013 1 1 554 558 -4 740
7 -24 404. 2013 1 1 555 600 -5 913
8 11 259. 2013 1 1 557 600 -3 709
9 5 405. 2013 1 1 557 600 -3 838
10 -10 319. 2013 1 1 558 600 -2 753
# ℹ 336,766 more rows
# ℹ 12 more variables: sched_arr_time <int>, arr_delay <dbl>, carrier <chr>,
# flight <int>, tailnum <chr>, origin <chr>, dest <chr>, air_time <dbl>,
# distance <dbl>, hour <dbl>, minute <dbl>, time_hour <dttm>也可以使用 .after 指定新变量应该在哪个变量后添加,在 .before 和 .after 中,都可以使用变量名和列数两种方法指定新变量出现的位置。例如,我们可以在 “day” 之后添加新变量:
mutate(
flights,
gain = dep_delay - arr_delay,
speed = distance / air_time * 60,
.after = day # 在 “day” 之后添加新变量
)# A tibble: 336,776 × 21
year month day gain speed dep_time sched_dep_time dep_delay arr_time
<int> <int> <int> <dbl> <dbl> <int> <int> <dbl> <int>
1 2013 1 1 -9 370. 517 515 2 830
2 2013 1 1 -16 374. 533 529 4 850
3 2013 1 1 -31 408. 542 540 2 923
4 2013 1 1 17 517. 544 545 -1 1004
5 2013 1 1 19 394. 554 600 -6 812
6 2013 1 1 -16 288. 554 558 -4 740
7 2013 1 1 -24 404. 555 600 -5 913
8 2013 1 1 11 259. 557 600 -3 709
9 2013 1 1 5 405. 557 600 -3 838
10 2013 1 1 -10 319. 558 600 -2 753
# ℹ 336,766 more rows
# ℹ 12 more variables: sched_arr_time <int>, arr_delay <dbl>, carrier <chr>,
# flight <int>, tailnum <chr>, origin <chr>, dest <chr>, air_time <dbl>,
# distance <dbl>, hour <dbl>, minute <dbl>, time_hour <dttm>另外,也可以使用 .keep 参数来控制在计算新变量后哪些变量会被保留:
-
.keep = "all":默认。保留所有变量 -
.keep = "used":保留用于计算新变量的旧变量。这可以用于检查我们的新变量是否计算正确,因为它和原始变量一起展示。 -
.keep = "unused":保留其他不用于计算新变量的旧变量。
例如,下面的输出将只包含旧变量 “dep_delay”、“arr_delay”、“distance”、“air_time”,以及新变量“gain”、“speed”:
mutate(
flights,
gain = dep_delay - arr_delay,
speed = distance / air_time * 60,
.keep = "used"
)# A tibble: 336,776 × 6
dep_delay arr_delay air_time distance gain speed
<dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
1 2 11 227 1400 -9 370.
2 4 20 227 1416 -16 374.
3 2 33 160 1089 -31 408.
4 -1 -18 183 1576 17 517.
5 -6 -25 116 762 19 394.
6 -4 12 150 719 -16 288.
7 -5 19 158 1065 -24 404.
8 -3 -14 53 229 11 259.
9 -3 -8 140 944 5 405.
10 -2 8 138 733 -10 319.
# ℹ 336,766 more rows4.2 select()
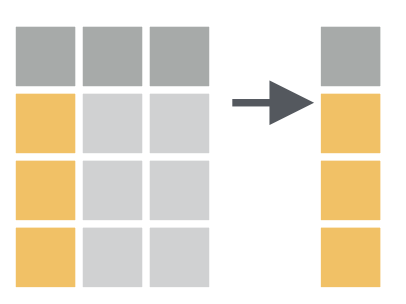
选择并输出某几列。
# 根据列名选择某几列
select(flights, year, month, day)# A tibble: 336,776 × 3
year month day
<int> <int> <int>
1 2013 1 1
2 2013 1 1
3 2013 1 1
4 2013 1 1
5 2013 1 1
6 2013 1 1
7 2013 1 1
8 2013 1 1
9 2013 1 1
10 2013 1 1
# ℹ 336,766 more rows# 选择“year”和“day”及其之间的所有列
select(flights, year:day)# A tibble: 336,776 × 3
year month day
<int> <int> <int>
1 2013 1 1
2 2013 1 1
3 2013 1 1
4 2013 1 1
5 2013 1 1
6 2013 1 1
7 2013 1 1
8 2013 1 1
9 2013 1 1
10 2013 1 1
# ℹ 336,766 more rows# 选择不在“year”和“day”及其之间的所有列
select(flights, !year:day)# A tibble: 336,776 × 16
dep_time sched_dep_time dep_delay arr_time sched_arr_time arr_delay carrier
<int> <int> <dbl> <int> <int> <dbl> <chr>
1 517 515 2 830 819 11 UA
2 533 529 4 850 830 20 UA
3 542 540 2 923 850 33 AA
4 544 545 -1 1004 1022 -18 B6
5 554 600 -6 812 837 -25 DL
6 554 558 -4 740 728 12 UA
7 555 600 -5 913 854 19 B6
8 557 600 -3 709 723 -14 EV
9 557 600 -3 838 846 -8 B6
10 558 600 -2 753 745 8 AA
# ℹ 336,766 more rows
# ℹ 9 more variables: flight <int>, tailnum <chr>, origin <chr>, dest <chr>,
# air_time <dbl>, distance <dbl>, hour <dbl>, minute <dbl>, time_hour <dttm># 选择所有字符型的列
select(flights, where(is.character))# A tibble: 336,776 × 4
carrier tailnum origin dest
<chr> <chr> <chr> <chr>
1 UA N14228 EWR IAH
2 UA N24211 LGA IAH
3 AA N619AA JFK MIA
4 B6 N804JB JFK BQN
5 DL N668DN LGA ATL
6 UA N39463 EWR ORD
7 B6 N516JB EWR FLL
8 EV N829AS LGA IAD
9 B6 N593JB JFK MCO
10 AA N3ALAA LGA ORD
# ℹ 336,766 more rowsTip
在 select() 内有许多经常可以组合使用的函数:
-
starts_with("abc"): 以特定字符开头的列名. -
ends_with("xyz"): 以特定字符结尾的列名. -
contains("ijk"): 包含特定字符的列名. -
num_range("x", 1:3): 列名x1,x2和x3.
通过 ?tidyselect::language 获取更多 tidyselect 内的选择函数。
⚠️这些函数只能在 select() 内使用。与之相反,base 包中也有两个类似的函数 startsWith() 和 endsWith() 可以独立使用,它们返回逻辑向量。
可以在选择变量的同时使用 = 对这些变量进行重命名。新变量名在 = 的左侧,旧变量名在右侧(new_name = old_name):
select(flights, tail_num = tailnum)# A tibble: 336,776 × 1
tail_num
<chr>
1 N14228
2 N24211
3 N619AA
4 N804JB
5 N668DN
6 N39463
7 N516JB
8 N829AS
9 N593JB
10 N3ALAA
# ℹ 336,766 more rows4.3 rename()
重命名列。新变量名在 = 的左侧,旧变量名在右侧(new_name = old_name)。
rename(
flights,
years = year,
months = month
)# A tibble: 336,776 × 19
years months day dep_time sched_dep_time dep_delay arr_time sched_arr_time
<int> <int> <int> <int> <int> <dbl> <int> <int>
1 2013 1 1 517 515 2 830 819
2 2013 1 1 533 529 4 850 830
3 2013 1 1 542 540 2 923 850
4 2013 1 1 544 545 -1 1004 1022
5 2013 1 1 554 600 -6 812 837
6 2013 1 1 554 558 -4 740 728
7 2013 1 1 555 600 -5 913 854
8 2013 1 1 557 600 -3 709 723
9 2013 1 1 557 600 -3 838 846
10 2013 1 1 558 600 -2 753 745
# ℹ 336,766 more rows
# ℹ 11 more variables: arr_delay <dbl>, carrier <chr>, flight <int>,
# tailnum <chr>, origin <chr>, dest <chr>, air_time <dbl>, distance <dbl>,
# hour <dbl>, minute <dbl>, time_hour <dttm>Caution
和其他dplyr中的函数一样,rename不会对原始数据进行修改,因此需要将rename后的数据重新赋值给新的对象或覆盖原来的对象以应用对变量名的修改。
如果我们有一个提供了重命名依据的字符串向量,那么可以通过all_of()来基于这个字符串向量对数据集的列进行重命名:
lookup <- c(
years = "year",
months = "month"
)
rename(flights, all_of(lookup))# A tibble: 336,776 × 19
years months day dep_time sched_dep_time dep_delay arr_time sched_arr_time
<int> <int> <int> <int> <int> <dbl> <int> <int>
1 2013 1 1 517 515 2 830 819
2 2013 1 1 533 529 4 850 830
3 2013 1 1 542 540 2 923 850
4 2013 1 1 544 545 -1 1004 1022
5 2013 1 1 554 600 -6 812 837
6 2013 1 1 554 558 -4 740 728
7 2013 1 1 555 600 -5 913 854
8 2013 1 1 557 600 -3 709 723
9 2013 1 1 557 600 -3 838 846
10 2013 1 1 558 600 -2 753 745
# ℹ 336,766 more rows
# ℹ 11 more variables: arr_delay <dbl>, carrier <chr>, flight <int>,
# tailnum <chr>, origin <chr>, dest <chr>, air_time <dbl>, distance <dbl>,
# hour <dbl>, minute <dbl>, time_hour <dttm>如果提供重命名依据的字符串向量中有的变量是原数据集中不存在的,那么可以用 any_of()代替 all_of() 来实现:
lookup <- c(
years = "year",
months = "month",
new = "unknown"
)
rename(flights, any_of(lookup))# A tibble: 336,776 × 19
years months day dep_time sched_dep_time dep_delay arr_time sched_arr_time
<int> <int> <int> <int> <int> <dbl> <int> <int>
1 2013 1 1 517 515 2 830 819
2 2013 1 1 533 529 4 850 830
3 2013 1 1 542 540 2 923 850
4 2013 1 1 544 545 -1 1004 1022
5 2013 1 1 554 600 -6 812 837
6 2013 1 1 554 558 -4 740 728
7 2013 1 1 555 600 -5 913 854
8 2013 1 1 557 600 -3 709 723
9 2013 1 1 557 600 -3 838 846
10 2013 1 1 558 600 -2 753 745
# ℹ 336,766 more rows
# ℹ 11 more variables: arr_delay <dbl>, carrier <chr>, flight <int>,
# tailnum <chr>, origin <chr>, dest <chr>, air_time <dbl>, distance <dbl>,
# hour <dbl>, minute <dbl>, time_hour <dttm>4.3.1 rename_with()
根据函数批量重命名列。
# 将所有列名变为大写
rename_with(flights, toupper)# A tibble: 336,776 × 19
YEAR MONTH DAY DEP_TIME SCHED_DEP_TIME DEP_DELAY ARR_TIME SCHED_ARR_TIME
<int> <int> <int> <int> <int> <dbl> <int> <int>
1 2013 1 1 517 515 2 830 819
2 2013 1 1 533 529 4 850 830
3 2013 1 1 542 540 2 923 850
4 2013 1 1 544 545 -1 1004 1022
5 2013 1 1 554 600 -6 812 837
6 2013 1 1 554 558 -4 740 728
7 2013 1 1 555 600 -5 913 854
8 2013 1 1 557 600 -3 709 723
9 2013 1 1 557 600 -3 838 846
10 2013 1 1 558 600 -2 753 745
# ℹ 336,766 more rows
# ℹ 11 more variables: ARR_DELAY <dbl>, CARRIER <chr>, FLIGHT <int>,
# TAILNUM <chr>, ORIGIN <chr>, DEST <chr>, AIR_TIME <dbl>, DISTANCE <dbl>,
# HOUR <dbl>, MINUTE <dbl>, TIME_HOUR <dttm># 将所有以“dep_"开头的列名转换为大写
rename_with(flights, toupper, .cols = starts_with("dep_"))# A tibble: 336,776 × 19
year month day DEP_TIME sched_dep_time DEP_DELAY arr_time sched_arr_time
<int> <int> <int> <int> <int> <dbl> <int> <int>
1 2013 1 1 517 515 2 830 819
2 2013 1 1 533 529 4 850 830
3 2013 1 1 542 540 2 923 850
4 2013 1 1 544 545 -1 1004 1022
5 2013 1 1 554 600 -6 812 837
6 2013 1 1 554 558 -4 740 728
7 2013 1 1 555 600 -5 913 854
8 2013 1 1 557 600 -3 709 723
9 2013 1 1 557 600 -3 838 846
10 2013 1 1 558 600 -2 753 745
# ℹ 336,766 more rows
# ℹ 11 more variables: arr_delay <dbl>, carrier <chr>, flight <int>,
# tailnum <chr>, origin <chr>, dest <chr>, air_time <dbl>, distance <dbl>,
# hour <dbl>, minute <dbl>, time_hour <dttm># 将列名中所有的"_"替换成“.”,并将所有列名转换成大写
rename_with(
flights,
function(x) {
gsub(pattern = "_", replacement = ".", x = x) %>%
toupper()
}
)# A tibble: 336,776 × 19
YEAR MONTH DAY DEP.TIME SCHED.DEP.TIME DEP.DELAY ARR.TIME SCHED.ARR.TIME
<int> <int> <int> <int> <int> <dbl> <int> <int>
1 2013 1 1 517 515 2 830 819
2 2013 1 1 533 529 4 850 830
3 2013 1 1 542 540 2 923 850
4 2013 1 1 544 545 -1 1004 1022
5 2013 1 1 554 600 -6 812 837
6 2013 1 1 554 558 -4 740 728
7 2013 1 1 555 600 -5 913 854
8 2013 1 1 557 600 -3 709 723
9 2013 1 1 557 600 -3 838 846
10 2013 1 1 558 600 -2 753 745
# ℹ 336,766 more rows
# ℹ 11 more variables: ARR.DELAY <dbl>, CARRIER <chr>, FLIGHT <int>,
# TAILNUM <chr>, ORIGIN <chr>, DEST <chr>, AIR.TIME <dbl>, DISTANCE <dbl>,
# HOUR <dbl>, MINUTE <dbl>, TIME.HOUR <dttm># 匿名函数形式
rename_with(flights, ~ gsub(pattern = "_", replacement = ".", x= .x) %>% toupper())# A tibble: 336,776 × 19
YEAR MONTH DAY DEP.TIME SCHED.DEP.TIME DEP.DELAY ARR.TIME SCHED.ARR.TIME
<int> <int> <int> <int> <int> <dbl> <int> <int>
1 2013 1 1 517 515 2 830 819
2 2013 1 1 533 529 4 850 830
3 2013 1 1 542 540 2 923 850
4 2013 1 1 544 545 -1 1004 1022
5 2013 1 1 554 600 -6 812 837
6 2013 1 1 554 558 -4 740 728
7 2013 1 1 555 600 -5 913 854
8 2013 1 1 557 600 -3 709 723
9 2013 1 1 557 600 -3 838 846
10 2013 1 1 558 600 -2 753 745
# ℹ 336,766 more rows
# ℹ 11 more variables: ARR.DELAY <dbl>, CARRIER <chr>, FLIGHT <int>,
# TAILNUM <chr>, ORIGIN <chr>, DEST <chr>, AIR.TIME <dbl>, DISTANCE <dbl>,
# HOUR <dbl>, MINUTE <dbl>, TIME.HOUR <dttm>4.4 relocate()
调整列的顺序。
# 将“day”和“year”放到最前面
relocate(flights, day, year)# A tibble: 336,776 × 19
day year month dep_time sched_dep_time dep_delay arr_time sched_arr_time
<int> <int> <int> <int> <int> <dbl> <int> <int>
1 1 2013 1 517 515 2 830 819
2 1 2013 1 533 529 4 850 830
3 1 2013 1 542 540 2 923 850
4 1 2013 1 544 545 -1 1004 1022
5 1 2013 1 554 600 -6 812 837
6 1 2013 1 554 558 -4 740 728
7 1 2013 1 555 600 -5 913 854
8 1 2013 1 557 600 -3 709 723
9 1 2013 1 557 600 -3 838 846
10 1 2013 1 558 600 -2 753 745
# ℹ 336,766 more rows
# ℹ 11 more variables: arr_delay <dbl>, carrier <chr>, flight <int>,
# tailnum <chr>, origin <chr>, dest <chr>, air_time <dbl>, distance <dbl>,
# hour <dbl>, minute <dbl>, time_hour <dttm>也可以和上面的[mutate()]一样通过.before 和 .after 参数指定放置位置:
# 将“year”和“dep_time”及其之间的列放到“sched_dep_time”之后
relocate(flights, year:dep_time, .after = sched_dep_time)# A tibble: 336,776 × 19
sched_dep_time year month day dep_time dep_delay arr_time sched_arr_time
<int> <int> <int> <int> <int> <dbl> <int> <int>
1 515 2013 1 1 517 2 830 819
2 529 2013 1 1 533 4 850 830
3 540 2013 1 1 542 2 923 850
4 545 2013 1 1 544 -1 1004 1022
5 600 2013 1 1 554 -6 812 837
6 558 2013 1 1 554 -4 740 728
7 600 2013 1 1 555 -5 913 854
8 600 2013 1 1 557 -3 709 723
9 600 2013 1 1 557 -3 838 846
10 600 2013 1 1 558 -2 753 745
# ℹ 336,766 more rows
# ℹ 11 more variables: arr_delay <dbl>, carrier <chr>, flight <int>,
# tailnum <chr>, origin <chr>, dest <chr>, air_time <dbl>, distance <dbl>,
# hour <dbl>, minute <dbl>, time_hour <dttm># 将所有以“dep_”开头的列放到“sched_dep_time”之前
relocate(flights, starts_with("dep_"), .before = sched_dep_time)# A tibble: 336,776 × 19
year month day dep_time dep_delay sched_dep_time arr_time sched_arr_time
<int> <int> <int> <int> <dbl> <int> <int> <int>
1 2013 1 1 517 2 515 830 819
2 2013 1 1 533 4 529 850 830
3 2013 1 1 542 2 540 923 850
4 2013 1 1 544 -1 545 1004 1022
5 2013 1 1 554 -6 600 812 837
6 2013 1 1 554 -4 558 740 728
7 2013 1 1 555 -5 600 913 854
8 2013 1 1 557 -3 600 709 723
9 2013 1 1 557 -3 600 838 846
10 2013 1 1 558 -2 600 753 745
# ℹ 336,766 more rows
# ℹ 11 more variables: arr_delay <dbl>, carrier <chr>, flight <int>,
# tailnum <chr>, origin <chr>, dest <chr>, air_time <dbl>, distance <dbl>,
# hour <dbl>, minute <dbl>, time_hour <dttm>5 分组统计
5.1 group_by()
根据某一列或几列将数据分组,便于后续的分组统计/运算。
group_by(flights, month)# A tibble: 336,776 × 19
# Groups: month [12]
year month day dep_time sched_dep_time dep_delay arr_time sched_arr_time
<int> <int> <int> <int> <int> <dbl> <int> <int>
1 2013 1 1 517 515 2 830 819
2 2013 1 1 533 529 4 850 830
3 2013 1 1 542 540 2 923 850
4 2013 1 1 544 545 -1 1004 1022
5 2013 1 1 554 600 -6 812 837
6 2013 1 1 554 558 -4 740 728
7 2013 1 1 555 600 -5 913 854
8 2013 1 1 557 600 -3 709 723
9 2013 1 1 557 600 -3 838 846
10 2013 1 1 558 600 -2 753 745
# ℹ 336,766 more rows
# ℹ 11 more variables: arr_delay <dbl>, carrier <chr>, flight <int>,
# tailnum <chr>, origin <chr>, dest <chr>, air_time <dbl>, distance <dbl>,
# hour <dbl>, minute <dbl>, time_hour <dttm>group_by()本身不会改变数据,除了在输出结果中出现了# Groups: month [12],提示我们该数据集进行了分组。这意味着随后的操作将按不同的月份分别进行。group_by()向数据添加了这个分组特性(称为类),从而改变了接下来对数据应用的函数的行为。
5.2 summarize()
分组汇总数据。根据某列或某几列的数据汇总一个包含了统计数据的新表。
# 计算每月的平均起飞延误时间
group_by(flights, month) |>
summarise(avg_delay = mean(dep_delay))# A tibble: 12 × 2
month avg_delay
<int> <dbl>
1 1 NA
2 2 NA
3 3 NA
4 4 NA
5 5 NA
6 6 NA
7 7 NA
8 8 NA
9 9 NA
10 10 NA
11 11 NA
12 12 NA可以看到,这里出现了问题,所有的结果都是“NA”。这是因为一些航班在延误时间(dep_delay)列中有缺失数据,所以当我们计算包括这些缺失值的平均值时,得到了一个NA结果。所以需要在mean()中设置参数 na.rm = TRUE 来忽略所有缺失值:
# 计算每月的平均起飞延误时间
group_by(flights, month) |>
summarise(avg_delay = mean(dep_delay, na.rm = TRUE))# A tibble: 12 × 2
month avg_delay
<int> <dbl>
1 1 10.0
2 2 10.8
3 3 13.2
4 4 13.9
5 5 13.0
6 6 20.8
7 7 21.7
8 8 12.6
9 9 6.72
10 10 6.24
11 11 5.44
12 12 16.6 可以在单次对summarize()的调用中创建任意数量的数据汇总。但其中一个非常有用的汇总函数是n(),它返回每个组中行数:
# 计算每月的平均起飞延误时间和延误航班数量
flights |>
group_by(month) |>
summarize(
avg_delay = mean(dep_delay, na.rm = TRUE),
n = n()
)# A tibble: 12 × 3
month avg_delay n
<int> <dbl> <int>
1 1 10.0 27004
2 2 10.8 24951
3 3 13.2 28834
4 4 13.9 28330
5 5 13.0 28796
6 6 20.8 28243
7 7 21.7 29425
8 8 12.6 29327
9 9 6.72 27574
10 10 6.24 28889
11 11 5.44 27268
12 12 16.6 281355.3 slice_系列函数
分组提取n行数据。
-
df |> slice_head(n = 1)从每一组中取前n行数据. -
df |> slice_tail(n = 1)从每一组中取后n行数据. -
df |> slice_min(x, n = 1)从每一组中取x列的值最小的n行数据. -
df |> slice_max(x, n = 1)从每一组中取x列的值最大的n行数据. -
df |> slice_sample(n = 1)从每一组中随机取n行数据.
其中的n参数指定需要提取的行数,同时,也可以用prop参数指定从每组中提取多少比例的行。例如,prop = 0.1 表示从每组中提取10%的行。
# 找出到达每个目的地的延误最严重的航班
flights %>%
group_by(dest) %>%
slice_max(order_by = arr_delay, n = 1) %>%
relocate(dest, arr_delay) %T>%
print() %>%
nrow()# A tibble: 108 × 19
# Groups: dest [105]
dest arr_delay year month day dep_time sched_dep_time dep_delay arr_time
<chr> <dbl> <int> <int> <int> <int> <int> <dbl> <int>
1 ABQ 153 2013 7 22 2145 2007 98 132
2 ACK 221 2013 7 23 1139 800 219 1250
3 ALB 328 2013 1 25 123 2000 323 229
4 ANC 39 2013 8 17 1740 1625 75 2042
5 ATL 895 2013 7 22 2257 759 898 121
6 AUS 349 2013 7 10 2056 1505 351 2347
7 AVL 228 2013 8 13 1156 832 204 1417
8 BDL 266 2013 2 21 1728 1316 252 1839
9 BGR 238 2013 12 1 1504 1056 248 1628
10 BHM 291 2013 4 10 25 1900 325 136
# ℹ 98 more rows
# ℹ 10 more variables: sched_arr_time <int>, carrier <chr>, flight <int>,
# tailnum <chr>, origin <chr>, air_time <dbl>, distance <dbl>, hour <dbl>,
# minute <dbl>, time_hour <dttm>[1] 108nrow(flights)[1] 336776上面的例子中,relocate()函数后用到了分支管道[%T>%],先通过print()把分组统计的结果打印出来,然后通过nrow()返回分组统计数据的行数。结果发现有108行,和原来数据的105行不符合,这是因为有的目的地可能有几架次并列延误最严重的航班。例如,第22行和23行的航班信息:
flights |>
group_by(dest) |>
slice_max(order_by = arr_delay, n = 1) |>
relocate(dest, arr_delay) |>
_[22:23,]# A tibble: 2 × 19
# Groups: dest [1]
dest arr_delay year month day dep_time sched_dep_time dep_delay arr_time
<chr> <dbl> <int> <int> <int> <int> <int> <dbl> <int>
1 CHS 331 2013 3 8 1202 751 251 1530
2 CHS 331 2013 9 2 1906 1359 307 2134
# ℹ 10 more variables: sched_arr_time <int>, carrier <chr>, flight <int>,
# tailnum <chr>, origin <chr>, air_time <dbl>, distance <dbl>, hour <dbl>,
# minute <dbl>, time_hour <dttm>5.4 多变量分组统计
例如分别统计每个日期(年+月+日)的航班数量:
daily <- flights |>
group_by(year, month, day)
daily |>
summarize(flights = n())# A tibble: 365 × 4
# Groups: year, month [12]
year month day flights
<int> <int> <int> <int>
1 2013 1 1 842
2 2013 1 2 943
3 2013 1 3 914
4 2013 1 4 915
5 2013 1 5 720
6 2013 1 6 832
7 2013 1 7 933
8 2013 1 8 899
9 2013 1 9 902
10 2013 1 10 932
# ℹ 355 more rows需要注意到结果中的第二行提示我们 summarise() 后的数据按照“year”和“month”进行了group处理。这是因为summarise() 在处理超过一个分组的数据时,输出的结果默认去除最后一个分组依据。这一行为可以通过设定.groups参数进行修改:
-
.groups = "drop_last":默认。summarise()后丢掉最后一个分组依据。 -
.groups = "drop":summarise()后取消分组。 -
.groups = "keep":summarise()后保留原分组。
flights |>
group_by(year, month, day) |>
summarize(
flights = n(),
.groups = "keep"
) # A tibble: 365 × 4
# Groups: year, month, day [365]
year month day flights
<int> <int> <int> <int>
1 2013 1 1 842
2 2013 1 2 943
3 2013 1 3 914
4 2013 1 4 915
5 2013 1 5 720
6 2013 1 6 832
7 2013 1 7 933
8 2013 1 8 899
9 2013 1 9 902
10 2013 1 10 932
# ℹ 355 more rows5.5 ungroup()
取消分组。
daily |>
ungroup() |>
summarize(
avg_delay = mean(dep_delay, na.rm = TRUE),
flights = n()
)# A tibble: 1 × 2
avg_delay flights
<dbl> <int>
1 12.6 3367765.6 .by
![]()
dplyr从1.1.0版本开始包括了一个新的实验性语法,用于直接在统计函数中指定分组依据,即 .by 参数。group_by() 和 ungroup() 不会消失,但现在也可以使用 .by 参数来在单个操作中进行分组:
flights |>
summarize(
avg_delay = mean(dep_delay, na.rm = TRUE),
flights = n(),
.by = month # 按“month”分组统计
) |>
arrange(month)# A tibble: 12 × 3
month avg_delay flights
<int> <dbl> <int>
1 1 10.0 27004
2 2 10.8 24951
3 3 13.2 28834
4 4 13.9 28330
5 5 13.0 28796
6 6 20.8 28243
7 7 21.7 29425
8 8 12.6 29327
9 9 6.72 27574
10 10 6.24 28889
11 11 5.44 27268
12 12 16.6 28135# 等价于:
flights |>
group_by(month) |>
summarise(
avg_delay = mean(dep_delay, na.rm = TRUE),
flights = n()
)# A tibble: 12 × 3
month avg_delay flights
<int> <dbl> <int>
1 1 10.0 27004
2 2 10.8 24951
3 3 13.2 28834
4 4 13.9 28330
5 5 13.0 28796
6 6 20.8 28243
7 7 21.7 29425
8 8 12.6 29327
9 9 6.72 27574
10 10 6.24 28889
11 11 5.44 27268
12 12 16.6 28135# 支持指定多个分组依据
flights |>
summarize(
avg_delay = mean(dep_delay, na.rm = TRUE),
flights = n(),
.by = c(origin, dest)
) |>
arrange(origin, dest)# A tibble: 224 × 4
origin dest avg_delay flights
<chr> <chr> <dbl> <int>
1 EWR ALB 23.6 439
2 EWR ANC 12.9 8
3 EWR ATL 15.5 5022
4 EWR AUS 11.5 968
5 EWR AVL 8.62 265
6 EWR BDL 17.7 443
7 EWR BNA 17.7 2336
8 EWR BOS 12.5 5327
9 EWR BQN 23.9 297
10 EWR BTV 17.8 931
# ℹ 214 more rows# 等价于:
flights |>
group_by(origin, dest) |>
summarize(
avg_delay = mean(dep_delay, na.rm = TRUE),
flights = n()
) |>
ungroup()# A tibble: 224 × 4
origin dest avg_delay flights
<chr> <chr> <dbl> <int>
1 EWR ALB 23.6 439
2 EWR ANC 12.9 8
3 EWR ATL 15.5 5022
4 EWR AUS 11.5 968
5 EWR AVL 8.62 265
6 EWR BDL 17.7 443
7 EWR BNA 17.7 2336
8 EWR BOS 12.5 5327
9 EWR BQN 23.9 297
10 EWR BTV 17.8 931
# ℹ 214 more rows
### 基于tidyr的长/宽数据转换

Tidyr是tidyverse的核心包之一,其目标是帮助创建整洁的数据。整洁的数据是具有以下特征的数据:
-
每个变量都是一列
-
每个观测值是一行
-
每个值是一个单元格

Figure 1: 整洁数据的基本特征
1 加载包
library(tidyverse)
library(nycflights13)这里的案例数据显示了以三种不同方式组织的相同数据。每个数据集都有相同的四个变量:country(国家)、year(年份)、population(总人口)和cases(结核病病例数),但每个数据集以不同的方式组织这些值。
table1# A tibble: 6 × 4
country year cases population
<chr> <dbl> <dbl> <dbl>
1 Afghanistan 1999 745 19987071
2 Afghanistan 2000 2666 20595360
3 Brazil 1999 37737 172006362
4 Brazil 2000 80488 174504898
5 China 1999 212258 1272915272
6 China 2000 213766 1280428583table2# A tibble: 12 × 4
country year type count
<chr> <dbl> <chr> <dbl>
1 Afghanistan 1999 cases 745
2 Afghanistan 1999 population 19987071
3 Afghanistan 2000 cases 2666
4 Afghanistan 2000 population 20595360
5 Brazil 1999 cases 37737
6 Brazil 1999 population 172006362
7 Brazil 2000 cases 80488
8 Brazil 2000 population 174504898
9 China 1999 cases 212258
10 China 1999 population 1272915272
11 China 2000 cases 213766
12 China 2000 population 1280428583table3# A tibble: 6 × 3
country year rate
<chr> <dbl> <chr>
1 Afghanistan 1999 745/19987071
2 Afghanistan 2000 2666/20595360
3 Brazil 1999 37737/172006362
4 Brazil 2000 80488/174504898
5 China 1999 212258/1272915272
6 China 2000 213766/1280428583table1中的数据符合 Figure 1 中的整洁数据规范。
2 pivot_longer():转换成长数据

这里我们以billboard数据集为例。该数据记录了 2000 年歌曲在广告牌上的排名情况:
billboard# A tibble: 317 × 79
artist track date.entered wk1 wk2 wk3 wk4 wk5 wk6 wk7 wk8
<chr> <chr> <date> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
1 2 Pac Baby… 2000-02-26 87 82 72 77 87 94 99 NA
2 2Ge+her The … 2000-09-02 91 87 92 NA NA NA NA NA
3 3 Doors D… Kryp… 2000-04-08 81 70 68 67 66 57 54 53
4 3 Doors D… Loser 2000-10-21 76 76 72 69 67 65 55 59
5 504 Boyz Wobb… 2000-04-15 57 34 25 17 17 31 36 49
6 98^0 Give… 2000-08-19 51 39 34 26 26 19 2 2
7 A*Teens Danc… 2000-07-08 97 97 96 95 100 NA NA NA
8 Aaliyah I Do… 2000-01-29 84 62 51 41 38 35 35 38
9 Aaliyah Try … 2000-03-18 59 53 38 28 21 18 16 14
10 Adams, Yo… Open… 2000-08-26 76 76 74 69 68 67 61 58
# ℹ 307 more rows
# ℹ 68 more variables: wk9 <dbl>, wk10 <dbl>, wk11 <dbl>, wk12 <dbl>,
# wk13 <dbl>, wk14 <dbl>, wk15 <dbl>, wk16 <dbl>, wk17 <dbl>, wk18 <dbl>,
# wk19 <dbl>, wk20 <dbl>, wk21 <dbl>, wk22 <dbl>, wk23 <dbl>, wk24 <dbl>,
# wk25 <dbl>, wk26 <dbl>, wk27 <dbl>, wk28 <dbl>, wk29 <dbl>, wk30 <dbl>,
# wk31 <dbl>, wk32 <dbl>, wk33 <dbl>, wk34 <dbl>, wk35 <dbl>, wk36 <dbl>,
# wk37 <dbl>, wk38 <dbl>, wk39 <dbl>, wk40 <dbl>, wk41 <dbl>, wk42 <dbl>, …在这个数据集中,每个观测(行)都是一首歌曲。前三列(“artist”、“track”和“date.entered”)是描述歌曲的变量。在此之后的76 列(“wk1”-“wk76”)描述了该歌曲在发行后每周的排名信息(仅在进入前100名时记录名次信息)。因此,对于“wk1”-“wk76”中的数据,所有的列名是一个变量(周数),每个单元格值则是另一个变量(每周的排名)。因此,这个数据集是不符合整洁数据的要求的。
下面,我们通过pivot_longer()将该数据转换成一个长数据,使其符合整洁数据:
billboard |>
pivot_longer(
cols = starts_with("wk"),
names_to = "week",
values_to = "rank"
)# A tibble: 24,092 × 5
artist track date.entered week rank
<chr> <chr> <date> <chr> <dbl>
1 2 Pac Baby Don't Cry (Keep... 2000-02-26 wk1 87
2 2 Pac Baby Don't Cry (Keep... 2000-02-26 wk2 82
3 2 Pac Baby Don't Cry (Keep... 2000-02-26 wk3 72
4 2 Pac Baby Don't Cry (Keep... 2000-02-26 wk4 77
5 2 Pac Baby Don't Cry (Keep... 2000-02-26 wk5 87
6 2 Pac Baby Don't Cry (Keep... 2000-02-26 wk6 94
7 2 Pac Baby Don't Cry (Keep... 2000-02-26 wk7 99
8 2 Pac Baby Don't Cry (Keep... 2000-02-26 wk8 NA
9 2 Pac Baby Don't Cry (Keep... 2000-02-26 wk9 NA
10 2 Pac Baby Don't Cry (Keep... 2000-02-26 wk10 NA
# ℹ 24,082 more rows-
cols:指定需要转换哪些列,即哪些列不是变量。此参数使用与select()相同的语法(见此前章节),因此在这里我们可以使用!c(artist, track, date.entered)或starts_with("wk")来选择“wk1”到“wk76”列。 -
names_to:转换后的列的列名,即新变量名。这里我们将该变量命名为 “week” 。 -
values_to:指定单元格值所代表的变量的变量名。我们将该变量命名为 “rank”。⚠️注意”week”和”rank”加了引号。
现在,让我们聚焦生成的长数据。如果一首歌进入前 100 名的时间少于 76 周,会发生什么情况?以 2 Pac 的《Baby Don’t Cry》为例。上面的输出结果表明,这首歌在前 100 名中只停留了 7 周,其余的周数都是缺失值。这些缺失值其实并不代表未知观测值,而是转换后的长数据集的结构迫使它们存在,因此我们可以通过设置 values_drop_na = TRUE 来要求 pivot_longer()去掉它们:
billboard |>
pivot_longer(
cols = starts_with("wk"),
names_to = "week",
values_to = "rank",
values_drop_na = TRUE
)# A tibble: 5,307 × 5
artist track date.entered week rank
<chr> <chr> <date> <chr> <dbl>
1 2 Pac Baby Don't Cry (Keep... 2000-02-26 wk1 87
2 2 Pac Baby Don't Cry (Keep... 2000-02-26 wk2 82
3 2 Pac Baby Don't Cry (Keep... 2000-02-26 wk3 72
4 2 Pac Baby Don't Cry (Keep... 2000-02-26 wk4 77
5 2 Pac Baby Don't Cry (Keep... 2000-02-26 wk5 87
6 2 Pac Baby Don't Cry (Keep... 2000-02-26 wk6 94
7 2 Pac Baby Don't Cry (Keep... 2000-02-26 wk7 99
8 2Ge+her The Hardest Part Of ... 2000-09-02 wk1 91
9 2Ge+her The Hardest Part Of ... 2000-09-02 wk2 87
10 2Ge+her The Hardest Part Of ... 2000-09-02 wk3 92
# ℹ 5,297 more rows注意到“week”目前为字符型变量,可以通过readr包中的parse_number()将其转换成数值型变量(详见此前章节),便于后续分析:
billboard_longer <- billboard |>
pivot_longer(
cols = starts_with("wk"),
names_to = "week",
values_to = "rank",
values_drop_na = TRUE
) |>
mutate(
week = parse_number(week)
)
billboard_longer# A tibble: 5,307 × 5
artist track date.entered week rank
<chr> <chr> <date> <dbl> <dbl>
1 2 Pac Baby Don't Cry (Keep... 2000-02-26 1 87
2 2 Pac Baby Don't Cry (Keep... 2000-02-26 2 82
3 2 Pac Baby Don't Cry (Keep... 2000-02-26 3 72
4 2 Pac Baby Don't Cry (Keep... 2000-02-26 4 77
5 2 Pac Baby Don't Cry (Keep... 2000-02-26 5 87
6 2 Pac Baby Don't Cry (Keep... 2000-02-26 6 94
7 2 Pac Baby Don't Cry (Keep... 2000-02-26 7 99
8 2Ge+her The Hardest Part Of ... 2000-09-02 1 91
9 2Ge+her The Hardest Part Of ... 2000-09-02 2 87
10 2Ge+her The Hardest Part Of ... 2000-09-02 3 92
# ℹ 5,297 more rows现在,我们在一个变量中拥有了所有的周数,在另一个变量中拥有了所有的排名值,这样我们就可以很好地直观显示歌曲排名随时间的变化情况。代码如下,结果如 Figure 2 所示。我们可以看到,很少有歌曲能在前 100 名中停留 20 周以上。
billboard_longer |>
ggplot(aes(x = week,
y = rank,
group = track)) +
geom_line(alpha = 0.25) +
scale_y_reverse() +
theme_bw()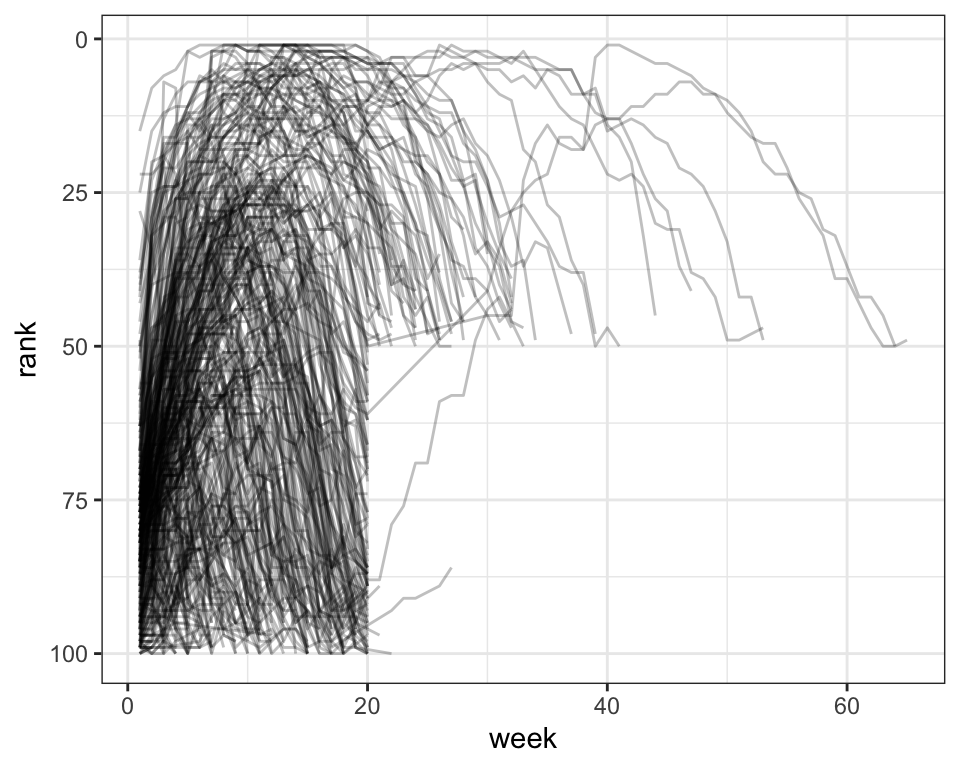
Figure 2: 显示歌曲排名随时间变化的折线图
2.1 pivot_longer()的转换原理
假设我们有三个病人,id 分别为 A、B 和 C,我们为每个病人测量了两次血压。这里我们用在此前章节中已经介绍过的 tribble() 来创建这个数据:
df <- tribble(
~id, ~bp1, ~bp2,
"A", 100, 120,
"B", 140, 115,
"C", 120, 125
)该数据集的“bp1”和“bp2”列不符合整洁数据的要求。因此,我们通过pivot_longer()将该数据转换成包含三个变量:id(已存在)、measurement(血压测定次数)和 value(血压值)的新数据:
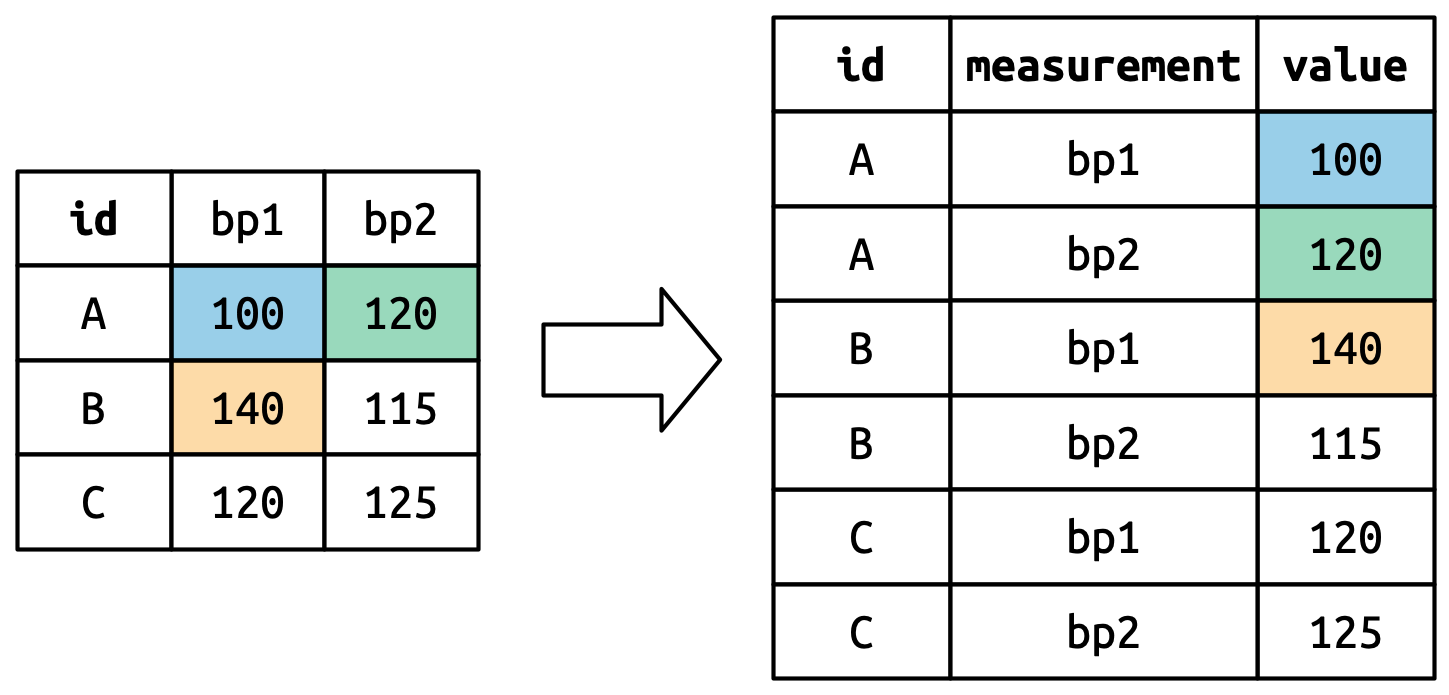
df |>
pivot_longer(
cols = bp1:bp2,
names_to = "measurement",
values_to = "value"
)# A tibble: 6 × 3
id measurement value
<chr> <chr> <dbl>
1 A bp1 100
2 A bp2 120
3 B bp1 140
4 B bp2 115
5 C bp1 120
6 C bp2 125转换是如何进行的呢?如果我们逐列考虑,就会比较容易理解。如下图所示,在原始数据集中已经是变量的一列(id)的值需要重复,重复的次数等于需要转换的列数。这里我们需要转换的列是“bp1”和“bp2”,因此每个“id”需要重复两次。
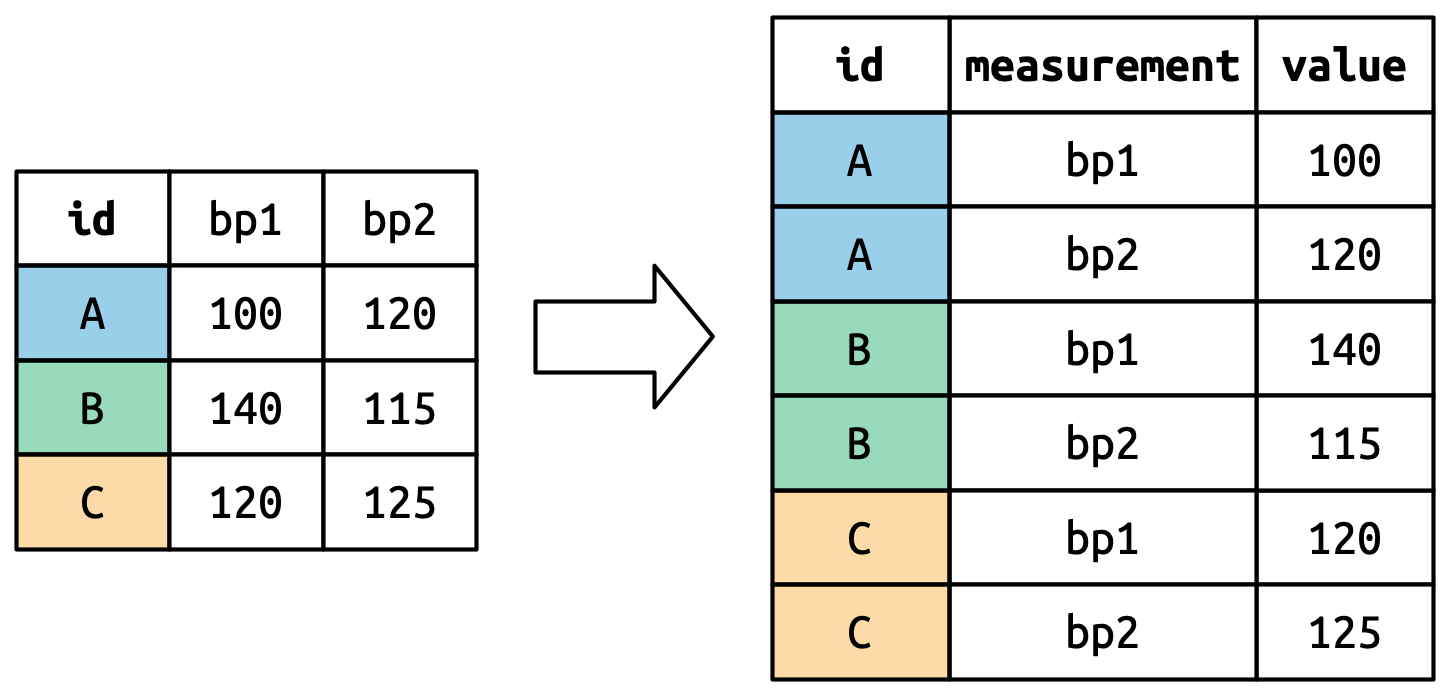
旧列名将成为新变量的值,该变量的名称由 names_to 参数定义。
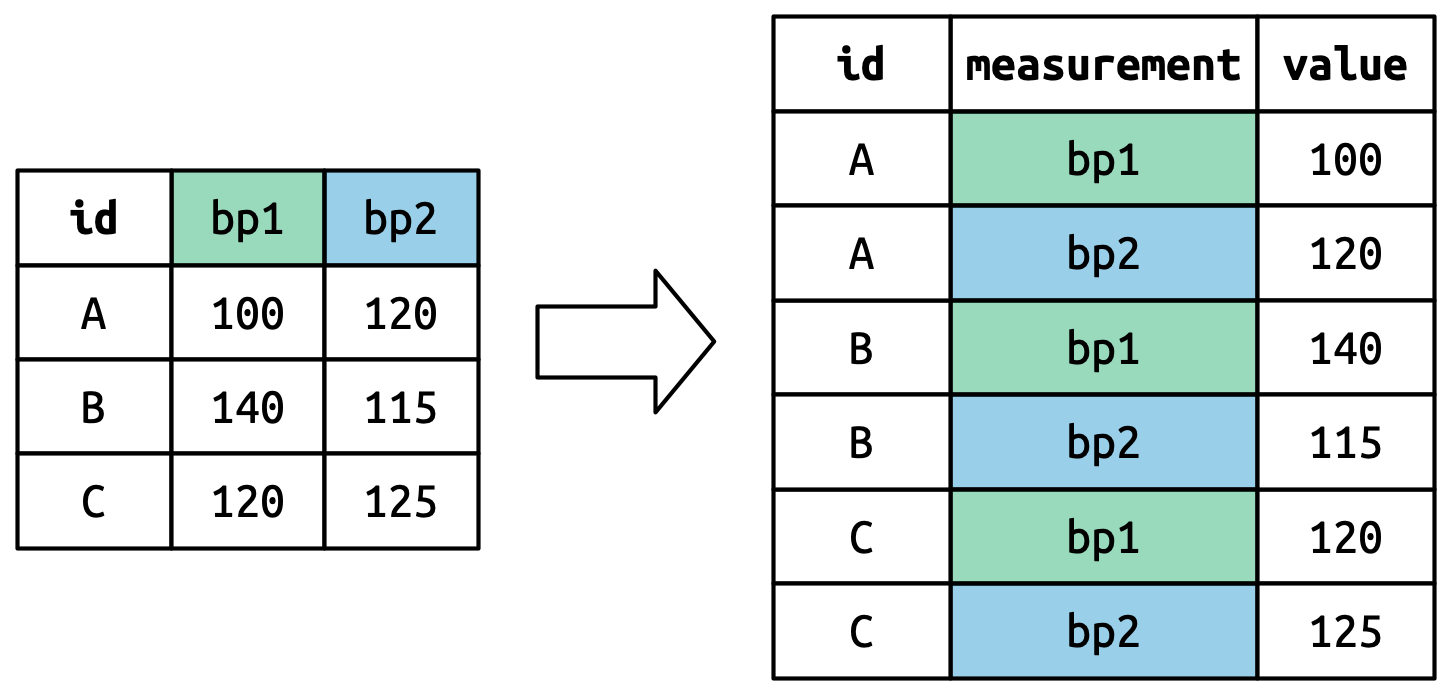
单元格值也会变成一个新变量的值,其名称由 values_to 定义。这些值将逐行填充。
2.2 包含多个变量信息的列名
更具挑战性的情况是,列名中包含了多个变量信息,而我们希望将这些信息分别存储在不同的新变量中。以 who2 数据集为例,该数据集由世界卫生组织收集,记录了肺结核诊断的相关信息:
Table 1: 肺结核病例信息-列名包含多个变量信息
who2# A tibble: 7,240 × 58
country year sp_m_014 sp_m_1524 sp_m_2534 sp_m_3544 sp_m_4554 sp_m_5564
<chr> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
1 Afghanistan 1980 NA NA NA NA NA NA
2 Afghanistan 1981 NA NA NA NA NA NA
3 Afghanistan 1982 NA NA NA NA NA NA
4 Afghanistan 1983 NA NA NA NA NA NA
5 Afghanistan 1984 NA NA NA NA NA NA
6 Afghanistan 1985 NA NA NA NA NA NA
7 Afghanistan 1986 NA NA NA NA NA NA
8 Afghanistan 1987 NA NA NA NA NA NA
9 Afghanistan 1988 NA NA NA NA NA NA
10 Afghanistan 1989 NA NA NA NA NA NA
# ℹ 7,230 more rows
# ℹ 50 more variables: sp_m_65 <dbl>, sp_f_014 <dbl>, sp_f_1524 <dbl>,
# sp_f_2534 <dbl>, sp_f_3544 <dbl>, sp_f_4554 <dbl>, sp_f_5564 <dbl>,
# sp_f_65 <dbl>, sn_m_014 <dbl>, sn_m_1524 <dbl>, sn_m_2534 <dbl>,
# sn_m_3544 <dbl>, sn_m_4554 <dbl>, sn_m_5564 <dbl>, sn_m_65 <dbl>,
# sn_f_014 <dbl>, sn_f_1524 <dbl>, sn_f_2534 <dbl>, sn_f_3544 <dbl>,
# sn_f_4554 <dbl>, sn_f_5564 <dbl>, sn_f_65 <dbl>, ep_m_014 <dbl>, …# 查看3:56的列名规则
colnames(who2)[3:56] %>%
str_split(
pattern = "_",
simplify = T
) %>%
apply(MARGIN = 2, unique)[[1]]
[1] "sp" "sn" "ep" "rel"
[[2]]
[1] "m" "f"
[[3]]
[1] "014" "1524" "2534" "3544" "4554" "5564" "65" 可以看到,该数据的前两列“country”和“year”是正常的变量。剩余的56列,每一列的名称都由三个部分组成,中间用 “_” 分隔:
-
第一部分为“sp/rel/ep”,代表采用的诊断方法;
-
第二部分为“m/f” ,代表性别;
-
第三部分为“014/1524/2534/3535/44/4554/5564/65”, 代表年龄范围(例如,014 代表 0-14岁)。
因此,在这种情况下,who2 数据中记录了六条变量信息:国家和年份(已列出);诊断方法、性别和年龄范围(包含在3-56列的列名中),以及该类别中的患者人数(单元格值)。为了将这六条变量信息转换到六个独立的列中,我们可以通过指定 pivot_longer() 中的 names_sep 参数,按照“_”分隔符将原始变量名分割成若干个字符串:
who2 |>
pivot_longer(
cols = !(country:year),
names_sep = "_", # 指定原始列名的分隔符
names_to = c("diagnosis", "gender", "age"),
values_to = "count"
)# A tibble: 405,440 × 6
country year diagnosis gender age count
<chr> <dbl> <chr> <chr> <chr> <dbl>
1 Afghanistan 1980 sp m 014 NA
2 Afghanistan 1980 sp m 1524 NA
3 Afghanistan 1980 sp m 2534 NA
4 Afghanistan 1980 sp m 3544 NA
5 Afghanistan 1980 sp m 4554 NA
6 Afghanistan 1980 sp m 5564 NA
7 Afghanistan 1980 sp m 65 NA
8 Afghanistan 1980 sp f 014 NA
9 Afghanistan 1980 sp f 1524 NA
10 Afghanistan 1980 sp f 2534 NA
# ℹ 405,430 more rows除了用 names_sep ,也可以使用 names_pattern 参数,通过正则表达式来实现上述效果。在这个案例中的数据转换过程参考如下示意图:
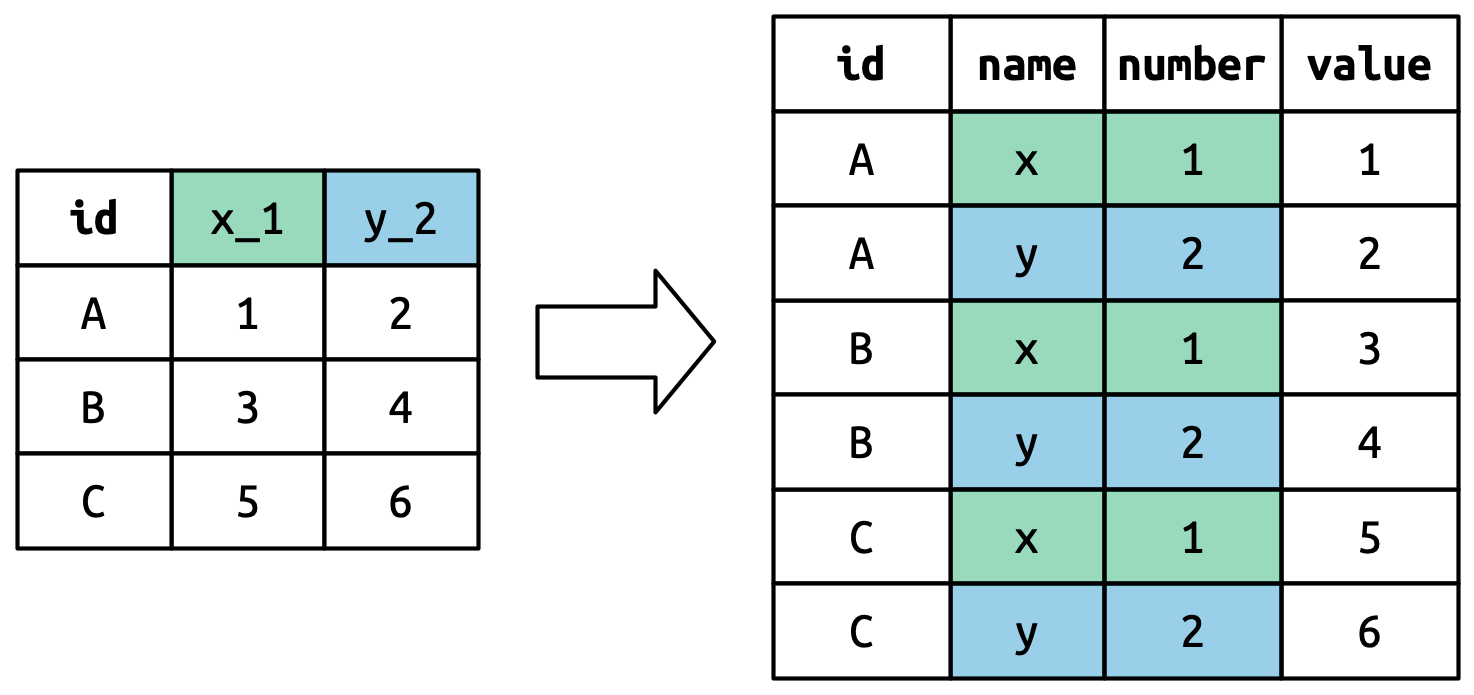
2.3 混合了变量名和变量取值的列名
Table 2: 家庭数据
household# A tibble: 5 × 5
family dob_child1 dob_child2 name_child1 name_child2
<int> <date> <date> <chr> <chr>
1 1 1998-11-26 2000-01-29 Susan Jose
2 2 1996-06-22 NA Mark <NA>
3 3 2002-07-11 2004-04-05 Sam Seth
4 4 2004-10-10 2009-08-27 Craig Khai
5 5 2000-12-05 2005-02-28 Parker Gracie 该数据集包含五个家庭的数据,每个家庭最多记录两个孩子的姓名(name_child1、name_child2)和出生日期(dob_child1、dob_child2)。仔细观察 Table 1 和 Table 2 可以发现 :Table 1 中需要转换的列名均由不同变量的具体取值构成(如“sp_m_014”,我们就可以知道这一列对应的诊断方法为“sp”,性别为“m”,年龄段为0-14岁);而 Table 2 的列名既有变量的具体取值,如“child1”告诉我们这是编号为1的child,也有变量的名称,如“dob”(出生日期)和“name”(姓名)。
为了解决这个问题,我们同样需要根据“_”分隔符分割原始列名,然后向 names_to 提供新变量名。但由于列名混合了变量名和变量取值,我们难以一一对应新旧列名。因此,这时候我们使用特殊的”.value “字符,让分割后的旧列名的第一个元素直接作为新变量的名称;分割后的旧列名的第二个元素(child1或child2)作为新的“child”变量的取值:
household |>
pivot_longer(
cols = !family,
names_sep = "_",
names_to = c(".value", "child"),
values_drop_na = TRUE
)# A tibble: 9 × 4
family child dob name
<int> <chr> <date> <chr>
1 1 child1 1998-11-26 Susan
2 1 child2 2000-01-29 Jose
3 2 child1 1996-06-22 Mark
4 3 child1 2002-07-11 Sam
5 3 child2 2004-04-05 Seth
6 4 child1 2004-10-10 Craig
7 4 child2 2009-08-27 Khai
8 5 child1 2000-12-05 Parker
9 5 child2 2005-02-28 Gracie使用 names_to = c(".value", "num") 进行数据转换会将列名分成两部分:第一部分决定输出的列名(x 或 y),第二部分决定 num 列的值。见下面的示意图:
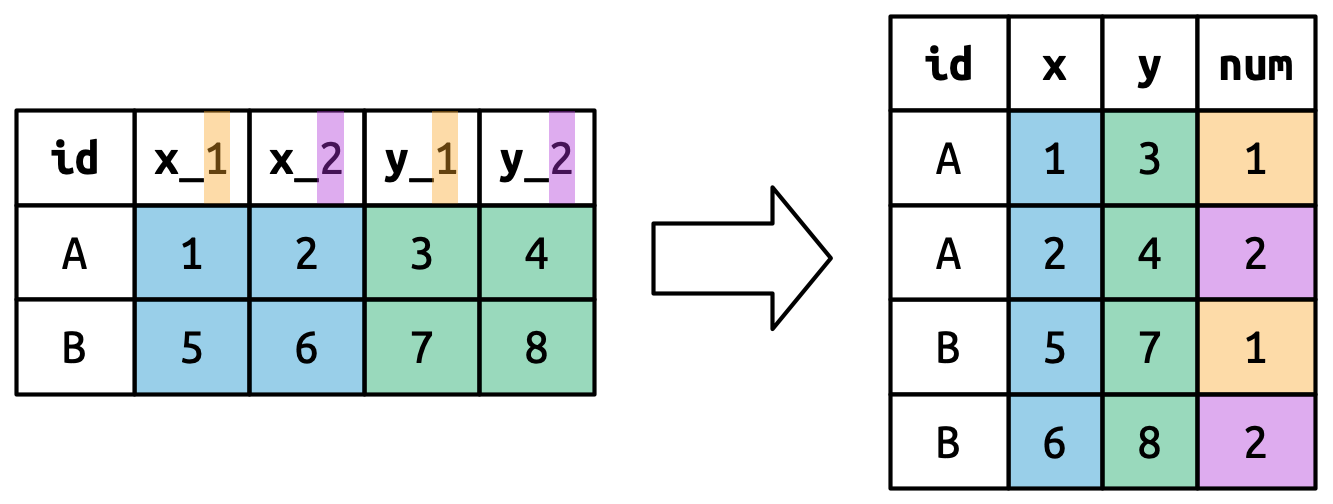
3 pivot_wider():转换成宽数据

pivot_wider() 可以通过增加列数和减少行数使数据集变宽。例如在重复测量数据中,一般而言我们会将每次观测作为一个个案,这时候一个对象多个时间点的观测数据分布在多行。这样的数据即为长数据,便于进行各种统计分析。但是如果你想了解每个对象的观测情况,就可以通过pivot_wider() 来将一个对象的多次观测结果合并到一行,即转换为宽数据。这种情况的实际应用场景较少,因此下面我们只简单演示了一个转换宽数据的基本语法,相关详细解释参考该链接。
cms_patient_experience# A tibble: 500 × 5
org_pac_id org_nm measure_cd measure_title prf_rate
<chr> <chr> <chr> <chr> <dbl>
1 0446157747 USC CARE MEDICAL GROUP INC CAHPS_GRP… CAHPS for MI… 63
2 0446157747 USC CARE MEDICAL GROUP INC CAHPS_GRP… CAHPS for MI… 87
3 0446157747 USC CARE MEDICAL GROUP INC CAHPS_GRP… CAHPS for MI… 86
4 0446157747 USC CARE MEDICAL GROUP INC CAHPS_GRP… CAHPS for MI… 57
5 0446157747 USC CARE MEDICAL GROUP INC CAHPS_GRP… CAHPS for MI… 85
6 0446157747 USC CARE MEDICAL GROUP INC CAHPS_GRP… CAHPS for MI… 24
7 0446162697 ASSOCIATION OF UNIVERSITY PHYSI… CAHPS_GRP… CAHPS for MI… 59
8 0446162697 ASSOCIATION OF UNIVERSITY PHYSI… CAHPS_GRP… CAHPS for MI… 85
9 0446162697 ASSOCIATION OF UNIVERSITY PHYSI… CAHPS_GRP… CAHPS for MI… 83
10 0446162697 ASSOCIATION OF UNIVERSITY PHYSI… CAHPS_GRP… CAHPS for MI… 63
# ℹ 490 more rowscms_patient_experience |>
pivot_wider(
id_cols = starts_with("org"), # 哪一列/几列定义了行的唯一标识
names_from = measure_cd, # 从哪一列(或哪几列)获取输出列的名称
values_from = prf_rate # 从哪一列(或哪几列)获取单元格值
)# A tibble: 95 × 8
org_pac_id org_nm CAHPS_GRP_1 CAHPS_GRP_2 CAHPS_GRP_3 CAHPS_GRP_5 CAHPS_GRP_8
<chr> <chr> <dbl> <dbl> <dbl> <dbl> <dbl>
1 0446157747 USC C… 63 87 86 57 85
2 0446162697 ASSOC… 59 85 83 63 88
3 0547164295 BEAVE… 49 NA 75 44 73
4 0749333730 CAPE … 67 84 85 65 82
5 0840104360 ALLIA… 66 87 87 64 87
6 0840109864 REX H… 73 87 84 67 91
7 0840513552 SCL H… 58 83 76 58 78
8 0941545784 GRITM… 46 86 81 54 NA
9 1052612785 COMMU… 65 84 80 58 87
10 1254237779 OUR L… 61 NA NA 65 NA
# ℹ 85 more rows
# ℹ 1 more variable: CAHPS_GRP_12 <dbl>4 拆分/合并列

4.1 unite():合并多列
unite(data, col, ..., sep, remove, na.rm) 可以将多列中的字符粘贴起来构成新的一列。其中:
-
data:目标数据集。 -
col:新列的名称。 -
...:需要合并的列名(若用“:”连接则表示合并两列及之间的所有列)。 -
sep:指定连接符。 -
remove:是否移除原始列。 -
na.rm:如果为“True”,则在合并每个值之前将删除缺失值。
flights %>%
unite(
col = "date",
sep = "/",
year, month, day,
na.rm = T
)# A tibble: 336,776 × 17
date dep_time sched_dep_time dep_delay arr_time sched_arr_time arr_delay
<chr> <int> <int> <dbl> <int> <int> <dbl>
1 2013/1/1 517 515 2 830 819 11
2 2013/1/1 533 529 4 850 830 20
3 2013/1/1 542 540 2 923 850 33
4 2013/1/1 544 545 -1 1004 1022 -18
5 2013/1/1 554 600 -6 812 837 -25
6 2013/1/1 554 558 -4 740 728 12
7 2013/1/1 555 600 -5 913 854 19
8 2013/1/1 557 600 -3 709 723 -14
9 2013/1/1 557 600 -3 838 846 -8
10 2013/1/1 558 600 -2 753 745 8
# ℹ 336,766 more rows
# ℹ 10 more variables: carrier <chr>, flight <int>, tailnum <chr>,
# origin <chr>, dest <chr>, air_time <dbl>, distance <dbl>, hour <dbl>,
# minute <dbl>, time_hour <dttm>也可以用 str_c() 或 str_glue() (见基于tidyr的字符串处理-拼接字符串)实现同样的效果:
flights %>%
mutate(
date = str_c(year, month, day, sep = "/"),
.before = year
)# A tibble: 336,776 × 20
date year month day dep_time sched_dep_time dep_delay arr_time
<chr> <int> <int> <int> <int> <int> <dbl> <int>
1 2013/1/1 2013 1 1 517 515 2 830
2 2013/1/1 2013 1 1 533 529 4 850
3 2013/1/1 2013 1 1 542 540 2 923
4 2013/1/1 2013 1 1 544 545 -1 1004
5 2013/1/1 2013 1 1 554 600 -6 812
6 2013/1/1 2013 1 1 554 558 -4 740
7 2013/1/1 2013 1 1 555 600 -5 913
8 2013/1/1 2013 1 1 557 600 -3 709
9 2013/1/1 2013 1 1 557 600 -3 838
10 2013/1/1 2013 1 1 558 600 -2 753
# ℹ 336,766 more rows
# ℹ 12 more variables: sched_arr_time <int>, arr_delay <dbl>, carrier <chr>,
# flight <int>, tailnum <chr>, origin <chr>, dest <chr>, air_time <dbl>,
# distance <dbl>, hour <dbl>, minute <dbl>, time_hour <dttm>flights %>%
mutate(
date = str_glue("{year}/{month}/{day}"),
.before = year
)4.2 拆分列
在 tidyr 中,separate_wider_position() 、 separate_wider_delim() 以及 separate_wider_regex() 可以将某一列根据分割符(separate_wider_delim())、固定宽度(separate_wider_position())或正则表达式(separate_wider_regex())拆分为多列。把这些函数中的“wider”替换成“longer”就构成了另外三个类似函数,用于将某一列根据分割符、固定宽度或正则表达式拆分为多行(不常用)。因为涉及到字串的处理以及正则表达式,我们在基于tidyr的字符串处理-拼接字符串中对这些函数进行了详细介绍。
### 不同类型向量的处理
本章按照数据处理中不同的变量类型分别介绍常用的一些函数。这些函数大部分来自base包,但是为了保持一致性和贴合实际场景,本章的语法仍遵循tidyverse风格。
1 加载包和案例数据
library(tidyverse)
library(nycflights13)
library(VIM)2 逻辑向量(logical vectors)
用 nycflights13 包内“flights”数据集为例,该数据集包含 2013 年从纽约市起飞的所有 336,776 次航班的信息。下面是一个简单的生成逻辑向量的例子,在“flights”中新增两列,判断航班是否在白天起飞(新列命名为“daytime”),是否准时到达(到达延误<20 min,新列命名为“approx_ontime”):
flights# A tibble: 336,776 × 19
year month day dep_time sched_dep_time dep_delay arr_time sched_arr_time
<int> <int> <int> <int> <int> <dbl> <int> <int>
1 2013 1 1 517 515 2 830 819
2 2013 1 1 533 529 4 850 830
3 2013 1 1 542 540 2 923 850
4 2013 1 1 544 545 -1 1004 1022
5 2013 1 1 554 600 -6 812 837
6 2013 1 1 554 558 -4 740 728
7 2013 1 1 555 600 -5 913 854
8 2013 1 1 557 600 -3 709 723
9 2013 1 1 557 600 -3 838 846
10 2013 1 1 558 600 -2 753 745
# ℹ 336,766 more rows
# ℹ 11 more variables: arr_delay <dbl>, carrier <chr>, flight <int>,
# tailnum <chr>, origin <chr>, dest <chr>, air_time <dbl>, distance <dbl>,
# hour <dbl>, minute <dbl>, time_hour <dttm>flights |>
mutate(
daytime = dep_time > 600 & dep_time < 2000,
approx_ontime = abs(arr_delay) < 20,
.keep = "used"
)# A tibble: 336,776 × 4
dep_time arr_delay daytime approx_ontime
<int> <dbl> <lgl> <lgl>
1 517 11 FALSE TRUE
2 533 20 FALSE FALSE
3 542 33 FALSE FALSE
4 544 -18 FALSE TRUE
5 554 -25 FALSE FALSE
6 554 12 FALSE TRUE
7 555 19 FALSE TRUE
8 557 -14 FALSE TRUE
9 557 -8 FALSE TRUE
10 558 8 FALSE TRUE
# ℹ 336,766 more rows2.1 逻辑摘要
-
any(x):相当于|。如果“x”中有任何“TRUE”,则返回“TRUE”。 -
all(x):相当于&。只有当“x”中所有值均为“TRUE”时,才返回“TRUE”。
例如,我们可以使用 all() 和 any() 来判断所有航班的起飞延误是否都在一个小时以内,以及是否有任何航班在到达时延误了五个小时或以上。通过使用 group_by(),我们可以按月来统计:
flights |>
group_by(year, month, day) |>
summarize(
all_delayed = all(dep_delay <= 60, na.rm = TRUE),
any_long_delay = any(arr_delay >= 300, na.rm = TRUE),
.groups = "drop"
)# A tibble: 365 × 5
year month day all_delayed any_long_delay
<int> <int> <int> <lgl> <lgl>
1 2013 1 1 FALSE TRUE
2 2013 1 2 FALSE TRUE
3 2013 1 3 FALSE FALSE
4 2013 1 4 FALSE FALSE
5 2013 1 5 FALSE TRUE
6 2013 1 6 FALSE FALSE
7 2013 1 7 FALSE TRUE
8 2013 1 8 FALSE FALSE
9 2013 1 9 FALSE TRUE
10 2013 1 10 FALSE TRUE
# ℹ 355 more rows2.2 逻辑向量计数
在数学计算中使用逻辑向量时,“TRUE” 变为 1,“FALSE” 变为 0。因此,我们可以通过 sum() 和 mean() 来计数逻辑向量。sum() 可以给出 “TRUE” 的个数,而 mean() 可以给出 “TRUE” 的比例(因为 mean(x) = sum(x) ÷ length(x))。
例如,我们可以统计每个月起飞延误在一小时以内的航班比例,以及抵达时延误五小时或以上的航班数量:
flights |>
group_by(year, month) |>
summarize(
proportion_delayed = mean(dep_delay <= 60, na.rm = TRUE),
count_long_delay = sum(arr_delay >= 300, na.rm = TRUE),
.groups = "drop"
)# A tibble: 12 × 4
year month proportion_delayed count_long_delay
<int> <int> <dbl> <int>
1 2013 1 0.931 25
2 2013 2 0.930 21
3 2013 3 0.916 64
4 2013 4 0.908 50
5 2013 5 0.918 47
6 2013 6 0.872 93
7 2013 7 0.866 140
8 2013 8 0.920 40
9 2013 9 0.951 58
10 2013 10 0.953 19
11 2013 11 0.960 19
12 2013 12 0.906 502.3 条件转换
逻辑向量最重要的应用之一是用于条件转换,即对条件 x 做一件事,而对条件 y 做另一件事。可以通过 base 包的 ifelse() 函数实现。而在 tidyverse 中的函数为:if_else() 和 case_when()。
if_else() 与 ifelse() 的使用基本相同。if_else() 可以通过指定 missing 参数来定义缺失值的表示形式,并且在确定输出类型时总是将 true、false 和 missing 考虑在内:
x <- c(1:3, NA, 4, 5, NA)
ifelse(x <3, "<3", "≥3")[1] "<3" "<3" "≥3" NA "≥3" "≥3" NA if_else(x <3, "<3", "≥3", missing = "Unknown")[1] "<3" "<3" "≥3" "Unknown" "≥3" "≥3" "Unknown"在统计分析中 ifelse() 和 if_else() 的一个十分常见的应用场景就是对变量进行赋值或替换已有赋值。例如我们可以根据到达延误时间(“arr_delay”)生成一个新变量“arr_2”,如果到达延误时间在30 min以内,赋值为“undelayed”,否则就为“delayed”:
# 新根据到达延误时间
flights %>%
mutate(
arr_2 = if_else(arr_delay <= 30, "undelayed", "delayed"),
.after = dep_delay
) # A tibble: 336,776 × 20
year month day dep_time sched_dep_time dep_delay arr_2 arr_time
<int> <int> <int> <int> <int> <dbl> <chr> <int>
1 2013 1 1 517 515 2 undelayed 830
2 2013 1 1 533 529 4 undelayed 850
3 2013 1 1 542 540 2 delayed 923
4 2013 1 1 544 545 -1 undelayed 1004
5 2013 1 1 554 600 -6 undelayed 812
6 2013 1 1 554 558 -4 undelayed 740
7 2013 1 1 555 600 -5 undelayed 913
8 2013 1 1 557 600 -3 undelayed 709
9 2013 1 1 557 600 -3 undelayed 838
10 2013 1 1 558 600 -2 undelayed 753
# ℹ 336,766 more rows
# ℹ 12 more variables: sched_arr_time <int>, arr_delay <dbl>, carrier <chr>,
# flight <int>, tailnum <chr>, origin <chr>, dest <chr>, air_time <dbl>,
# distance <dbl>, hour <dbl>, minute <dbl>, time_hour <dttm>如果需要进行多重逻辑判断的话需要嵌套使用 if_else() 。如:
flights %>%
mutate(
status = if_else(
is.na(arr_delay), "cancelled",
if_else(
arr_delay < -30, "very early",
if_else(
arr_delay < -15, "early",
if_else(
arr_delay <= 15, "on time",
if_else(
arr_delay < 60, "late", "very late"
)
)
)
)
),
.after = dep_delay
) %>%
select(status) %>%
table()status
cancelled early late on time very early very late
9430 70416 49313 159216 20084 28317 这种情况我们可以使用 case_when() 来避免 if_else() 的反复嵌套使用,让代码更简洁易懂。case_when() 受到了 SQL 的 CASE 语句的启发,提供了一种针对不同条件执行不同计算的灵活方式。它有一个特殊的语法:condition ~ output。其中 condition 必须是逻辑向量;当 condition 为 “TRUE” 时,将输出 output 。
flights %>%
mutate(
status = case_when(
is.na(arr_delay) ~ "cancelled",
arr_delay < -30 ~ "very early",
arr_delay < -15 ~ "early",
arr_delay <= 15 ~ "on time",
arr_delay < 60 ~ "late",
arr_delay < Inf ~ "very late",
),
.after = dep_delay
) %>%
select(status) %>%
table()status
cancelled early late on time very early very late
9430 70416 49313 159216 20084 28317 我们还可以通过添加 .default 参数,来指定默认的输出结果,当某个个案不满足所有列出的条件时就输出这个默认结果。在上面的例子中,如果我们添加了 .default = "very late" ,就不需要写 arr_delay < Inf ~ "very late" 了:
flights %>%
mutate(
status = case_when(
is.na(arr_delay) ~ "cancelled",
arr_delay < -30 ~ "very early",
arr_delay < -15 ~ "early",
arr_delay <= 15 ~ "on time",
arr_delay < 60 ~ "late",
.default = "very late"
),
.after = dep_delay
) %>%
select(status) %>%
table()2.4 缺失值
2.4.1 判断缺失值
is.na(c(TRUE, NA, FALSE))[1] FALSE TRUE FALSEis.na(c(1, NA, 3))[1] FALSE TRUE FALSEis.na(c("a", NA, "b"))[1] FALSE TRUE FALSE我们可以使用 is.na() 查找缺失了“dep_time”的所有行:
flights |>
filter(is.na(dep_time))# A tibble: 8,255 × 19
year month day dep_time sched_dep_time dep_delay arr_time sched_arr_time
<int> <int> <int> <int> <int> <dbl> <int> <int>
1 2013 1 1 NA 1630 NA NA 1815
2 2013 1 1 NA 1935 NA NA 2240
3 2013 1 1 NA 1500 NA NA 1825
4 2013 1 1 NA 600 NA NA 901
5 2013 1 2 NA 1540 NA NA 1747
6 2013 1 2 NA 1620 NA NA 1746
7 2013 1 2 NA 1355 NA NA 1459
8 2013 1 2 NA 1420 NA NA 1644
9 2013 1 2 NA 1321 NA NA 1536
10 2013 1 2 NA 1545 NA NA 1910
# ℹ 8,245 more rows
# ℹ 11 more variables: arr_delay <dbl>, carrier <chr>, flight <int>,
# tailnum <chr>, origin <chr>, dest <chr>, air_time <dbl>, distance <dbl>,
# hour <dbl>, minute <dbl>, time_hour <dttm>is.na() 在 arrange() 中也很有用。用 arrange() 基于某列排序时默认会将该列的所有缺失值放在最后,但可以先用 is.na() 进行降序排序,从而让缺失值在最前面显示:
# 按照“dep_time”排序
flights |>
filter(month == 1, day == 1) |>
arrange(dep_time)# A tibble: 842 × 19
year month day dep_time sched_dep_time dep_delay arr_time sched_arr_time
<int> <int> <int> <int> <int> <dbl> <int> <int>
1 2013 1 1 517 515 2 830 819
2 2013 1 1 533 529 4 850 830
3 2013 1 1 542 540 2 923 850
4 2013 1 1 544 545 -1 1004 1022
5 2013 1 1 554 600 -6 812 837
6 2013 1 1 554 558 -4 740 728
7 2013 1 1 555 600 -5 913 854
8 2013 1 1 557 600 -3 709 723
9 2013 1 1 557 600 -3 838 846
10 2013 1 1 558 600 -2 753 745
# ℹ 832 more rows
# ℹ 11 more variables: arr_delay <dbl>, carrier <chr>, flight <int>,
# tailnum <chr>, origin <chr>, dest <chr>, air_time <dbl>, distance <dbl>,
# hour <dbl>, minute <dbl>, time_hour <dttm># 按照“dep_time”排序,同时将缺失值放到最前面
flights |>
filter(month == 1, day == 1) |>
arrange(desc(is.na(dep_time)), dep_time)# A tibble: 842 × 19
year month day dep_time sched_dep_time dep_delay arr_time sched_arr_time
<int> <int> <int> <int> <int> <dbl> <int> <int>
1 2013 1 1 NA 1630 NA NA 1815
2 2013 1 1 NA 1935 NA NA 2240
3 2013 1 1 NA 1500 NA NA 1825
4 2013 1 1 NA 600 NA NA 901
5 2013 1 1 517 515 2 830 819
6 2013 1 1 533 529 4 850 830
7 2013 1 1 542 540 2 923 850
8 2013 1 1 544 545 -1 1004 1022
9 2013 1 1 554 600 -6 812 837
10 2013 1 1 554 558 -4 740 728
# ℹ 832 more rows
# ℹ 11 more variables: arr_delay <dbl>, carrier <chr>, flight <int>,
# tailnum <chr>, origin <chr>, dest <chr>, air_time <dbl>, distance <dbl>,
# hour <dbl>, minute <dbl>, time_hour <dttm>2.4.2 删除缺失值
# 删除缺失“dep_time”的所有行
flights %>%
filter(is.na(dep_time) == FALSE) # A tibble: 328,521 × 19
year month day dep_time sched_dep_time dep_delay arr_time sched_arr_time
<int> <int> <int> <int> <int> <dbl> <int> <int>
1 2013 1 1 517 515 2 830 819
2 2013 1 1 533 529 4 850 830
3 2013 1 1 542 540 2 923 850
4 2013 1 1 544 545 -1 1004 1022
5 2013 1 1 554 600 -6 812 837
6 2013 1 1 554 558 -4 740 728
7 2013 1 1 555 600 -5 913 854
8 2013 1 1 557 600 -3 709 723
9 2013 1 1 557 600 -3 838 846
10 2013 1 1 558 600 -2 753 745
# ℹ 328,511 more rows
# ℹ 11 more variables: arr_delay <dbl>, carrier <chr>, flight <int>,
# tailnum <chr>, origin <chr>, dest <chr>, air_time <dbl>, distance <dbl>,
# hour <dbl>, minute <dbl>, time_hour <dttm># 删除flights数据集中包含缺失值的所有行
flights %>%
na.omit()# A tibble: 327,346 × 19
year month day dep_time sched_dep_time dep_delay arr_time sched_arr_time
<int> <int> <int> <int> <int> <dbl> <int> <int>
1 2013 1 1 517 515 2 830 819
2 2013 1 1 533 529 4 850 830
3 2013 1 1 542 540 2 923 850
4 2013 1 1 544 545 -1 1004 1022
5 2013 1 1 554 600 -6 812 837
6 2013 1 1 554 558 -4 740 728
7 2013 1 1 555 600 -5 913 854
8 2013 1 1 557 600 -3 709 723
9 2013 1 1 557 600 -3 838 846
10 2013 1 1 558 600 -2 753 745
# ℹ 327,336 more rows
# ℹ 11 more variables: arr_delay <dbl>, carrier <chr>, flight <int>,
# tailnum <chr>, origin <chr>, dest <chr>, air_time <dbl>, distance <dbl>,
# hour <dbl>, minute <dbl>, time_hour <dttm>VIM 包:可视化缺失模式
3 数值向量(numeric vectors)
3.1 转换数值向量
R 中的数值有两种类型:整数(integer)或双倍精度(double)。但有些时候由于导入数据的格式问题等原因数值会以字符串的形式保存。readr 提供了两个将字符串解析为数字常用函数:parse_double() 和 parse_number()。parse_number() 涵盖了parse_double() 的功能,同时能够进行数值解析。parse_number()会解析它找到的第一个数字,然后删除第一个数字之前的所有非数字字符和第一个数字之后的所有字符,同时也会忽略千分位分隔符“,”。所以在实际场景中主要使用 parse_number() 。
# 字符转数值。开头的非数值字符被忽略
c("euro1,000", "euro2,000") %>%
parse_number()[1] 1000 2000# 字符转数值。只输出找到的第一个数值
c("t1000t1000", "t2000t2000") %>%
parse_number()[1] 1000 2000# 小数点会被保留
c("1,234.56", "t1,234.56") %>%
parse_number()[1] 1234.56 1234.56# 货币转换。开头的“$”和千分位分隔符“,”被忽略
c("$1,000", "$1,500") %>%
parse_number() [1] 1000 1500# 可以通过locale参数指定在待转换向量中千分位分隔符(grouping_mark)和小数点(decimal_mark)的表示方法
c("1 234.56") %T>%
parse_number() %T>% print() %>%
parse_number(locale = locale(decimal_mark = ".", grouping_mark = " "))[1] "1 234.56"[1] 1234.563.2 计数
只需使用计数和一些基本算术,就能完成大量数据科学工作,因此 dplyr 努力通过 count() 使计数变得尽可能简单。这个函数非常适合在分析过程中进行快速探索和检查:
# 统计各个目的地的航班数
flights |> count(dest, sort = TRUE)# A tibble: 105 × 2
dest n
<chr> <int>
1 ORD 17283
2 ATL 17215
3 LAX 16174
4 BOS 15508
5 MCO 14082
6 CLT 14064
7 SFO 13331
8 FLL 12055
9 MIA 11728
10 DCA 9705
# ℹ 95 more rows记住,如果想查看所有值,可以使用 |> View() 或 |> print(n = Inf)。
在 base 包中能够实现类似效果的是 table() 函数:
table(flights$dest) %>% head()
ABQ ACK ALB ANC ATL AUS
254 265 439 8 17215 2439 可以使用 group_by()、summarize() 和 n() “手动”执行相同的计算。这在需要同时计算其他数据摘要时十分有用。例如,我们除了要统计各个目的地的航班数之外还需要统计到的各个目的地航班的平均延误时间:
flights |>
group_by(dest) |>
summarize(
n = n(),
delay = mean(arr_delay, na.rm = TRUE)
)# A tibble: 105 × 3
dest n delay
<chr> <int> <dbl>
1 ABQ 254 4.38
2 ACK 265 4.85
3 ALB 439 14.4
4 ANC 8 -2.5
5 ATL 17215 11.3
6 AUS 2439 6.02
7 AVL 275 8.00
8 BDL 443 7.05
9 BGR 375 8.03
10 BHM 297 16.9
# ℹ 95 more rowsWarning
n() 是一个特殊的摘要函数,不需要任何参数,而是访问 “当前” group 的信息。这意味着它只能在 dplyr 语句,如summarize() 、 mutate() 、 filter() 和 group_by() 等函数的内部使用。
3.2.1 n() 和 count() 的变体
计数唯一值
n_distinct() 计算一个或多个变量的唯一值的数量。例如,我们可以推荐每个目的地有多少家航空公司提供服务:
flights |>
group_by(dest) |>
summarize(carriers = n_distinct(carrier)) |>
arrange(desc(carriers))# A tibble: 105 × 2
dest carriers
<chr> <int>
1 ATL 7
2 BOS 7
3 CLT 7
4 ORD 7
5 TPA 7
6 AUS 6
7 DCA 6
8 DTW 6
9 IAD 6
10 MSP 6
# ℹ 95 more rowsn_distinct(flights$carrier) 等价于:
unique(flights$carrier) %>% length()[1] 16练习:查找由至少两家航空公司(“carrier”)运营的目的地(“dest”),并在每个目的地中挑选最优的一家航空公司,挑选标准为平均出发延误时间(“dep_delay”)和到达延误时间(“arr_delay”)最短的公司:
flights %>%
group_by(dest) %>%
mutate(
carrier_count = n_distinct(carrier)
) %>%
filter(carrier_count >= 2) %>%
group_by(dest, carrier) %>%
summarise(
mean_delay = mean(arr_delay, na.rm = T) + mean(dep_delay, na.rm = T)
) %>%
slice_min(mean_delay, n = 1) # A tibble: 76 × 3
# Groups: dest [76]
dest carrier mean_delay
<chr> <chr> <dbl>
1 ATL 9E 1.82
2 AUS WN -7.40
3 AVL 9E -14.7
4 BDL EV 24.4
5 BGR EV 27.5
6 BNA DL -31
7 BOS US -2.96
8 BQN B6 13.6
9 BTV 9E -7
10 BUF DL -14
# ℹ 66 more rows加权计数
加权计数是分组计算总和(sum())。例如,统计每个航线飞机飞行的总里程数:
flights |>
group_by(tailnum) |>
summarize(miles = sum(distance))# A tibble: 4,044 × 2
tailnum miles
<chr> <dbl>
1 D942DN 3418
2 N0EGMQ 250866
3 N10156 115966
4 N102UW 25722
5 N103US 24619
6 N104UW 25157
7 N10575 150194
8 N105UW 23618
9 N107US 21677
10 N108UW 32070
# ℹ 4,034 more rows加权计数经常使用,因此 count() 有一个 wt 参数,可以实现同样的目的:
# 统计每个航线飞行的次数
flights %>% count(tailnum)# A tibble: 4,044 × 2
tailnum n
<chr> <int>
1 D942DN 4
2 N0EGMQ 371
3 N10156 153
4 N102UW 48
5 N103US 46
6 N104UW 47
7 N10575 289
8 N105UW 45
9 N107US 41
10 N108UW 60
# ℹ 4,034 more rows# 统计每个航线飞行的总里程数
flights |> count(tailnum, wt = distance)# A tibble: 4,044 × 2
tailnum n
<chr> <dbl>
1 D942DN 3418
2 N0EGMQ 250866
3 N10156 115966
4 N102UW 25722
5 N103US 24619
6 N104UW 25157
7 N10575 150194
8 N105UW 23618
9 N107US 21677
10 N108UW 32070
# ℹ 4,034 more rows实际上如果指定了 wt 参数,就是对其分组进行 sum(wt) 操作。理解加权计数的作用的另一个很好的例子参考后面的章节。
计数缺失值
结合 sum() 和 is.na() 可以计数缺失值。例如统计每个目的地取消的航班数:
flights |>
group_by(dest) |>
summarize(n_cancelled = sum(is.na(dep_time)))# A tibble: 105 × 2
dest n_cancelled
<chr> <int>
1 ABQ 0
2 ACK 0
3 ALB 20
4 ANC 0
5 ATL 317
6 AUS 21
7 AVL 12
8 BDL 31
9 BGR 15
10 BHM 25
# ℹ 95 more rows3.3 查找最大值和最小值
两个重要函数是 pmin() 和 pmax(),当给定两个或多个变量时,它们将返回每一行中最小或最大值:
df <- tribble(
~x, ~y,
1, 3,
5, 2,
7, NA,
)
df |>
mutate(
min = pmin(x, y, na.rm = TRUE),
max = pmax(x, y, na.rm = TRUE)
)# A tibble: 3 × 4
x y min max
<dbl> <dbl> <dbl> <dbl>
1 1 3 1 3
2 5 2 2 5
3 7 NA 7 7请注意, pmin() 和 pmax()不同于汇总函数 min() 和 max(),当给定两个或多个变量时,后者只返回单一值,即所有变量的最大值或最小值。在本例中,如果所有行的最小值和最大值都相同,就说明使用了错误的形式:
df |>
mutate(
min = min(x, y, na.rm = TRUE),
max = max(x, y, na.rm = TRUE)
)# A tibble: 3 × 4
x y min max
<dbl> <dbl> <dbl> <dbl>
1 1 3 1 7
2 5 2 1 7
3 7 NA 1 7如果要用 min() 和 max() 实现同样的目的需要如下代码:
min <- apply(df, MARGIN = 1, min, na.rm = TRUE)
max <- apply(df, MARGIN = 1, max, na.rm = TRUE)
df %>%
mutate(min, max)# A tibble: 3 × 4
x y min max
<dbl> <dbl> <dbl> <dbl>
1 1 3 1 3
2 5 2 2 5
3 7 NA 7 73.4 数学计算
3.4.1 整除和余数(modular arithmetic)
# 返回整除结果
1:10 %/% 3 [1] 0 0 1 1 1 2 2 2 3 3# 返回余数
1:10 %% 3 [1] 1 2 0 1 2 0 1 2 0 13.4.2 对数
在 R 中,有三种对数可供选择:
建议使用 log2() 或 log10()。log2() 容易解释,因为对数刻度上的差值为 1 相当于原始刻度的两倍,差值为-1 相当于减半;而 log10() 容易推算原始数值,例如 3 是 10^3 = 1000。log() 的倒数是 exp();要计算 log2() 或 log10() 的原始数值,需要使用 2^ 或 10^。
3.4.3 四舍五入
round() 函数。第二个参数控制保留的小数位数:
# 保留两位小数
round(123.456, 2) [1] 123.46# 四舍五入到最接近的十位数
round(123.456, -1) [1] 120# 四舍五入到最接近的百位数
round(123.456, -2) [1] 100如果一个小数正好位于两个整数之间,即*.5的形式,round() 这时候会返回比较奇怪的结果(例如下面的例子)。这是因为 round() 使用了所谓的 “四舍五入,半为偶数”或银行家四舍五入法(Banker’s roundin):即对于一个.5的小数,它将被四舍五入为离它最近的一个偶数。这是一种很好的策略,因为它能保持在对多个数值进行四舍五入后能够不偏不倚:*.5 小数的一半向上舍入,一半向下舍入。
round(c(1.4, 1.5, 2.5, 3.5, 4.5, 4.6))[1] 1 2 2 4 4 5另外两个取整函数:
x <- 123.456
floor(x)[1] 123ceiling(x)[1] 1243.5 切割数值向量
可以使用 cut() 将数值向量按照不同的截断值切割(又称bin)为不同的分段:
x <- c(-1, NA, 0, 1, 2, 5, 10, 15, 20, 50)
cut(x, breaks = c(0, 5, 15, 20)) [1] <NA> <NA> <NA> (0,5] (0,5] (0,5] (5,15] (5,15] (15,20]
[10] <NA>
Levels: (0,5] (5,15] (15,20]cut(x, breaks = c(-Inf, 5, 15, Inf)) [1] (-Inf,5] <NA> (-Inf,5] (-Inf,5] (-Inf,5] (-Inf,5] (5,15]
[8] (5,15] (15, Inf] (15, Inf]
Levels: (-Inf,5] (5,15] (15, Inf]cut(x, breaks = c(0, 5, 15, 20), include.lowest = T) [1] <NA> <NA> [0,5] [0,5] [0,5] [0,5] (5,15] (5,15] (15,20]
[10] <NA>
Levels: [0,5] (5,15] (15,20]cut(x, breaks = c(0, 5, 15, 20), include.lowest = T, right = F) [1] <NA> <NA> [0,5) [0,5) [0,5) [5,15) [5,15) [15,20] [15,20]
[10] <NA>
Levels: [0,5) [5,15) [15,20]-
cut()返回的结果是一个因子型向量 -
“NA”以及任何超出截断值范围的值都将变为 “NA”
-
include.lowest:是否包括下截断值(默认为“FALSE”) -
right:是否包括上截断值(默认为“TRUE”) -
labels:给不同的分段打标签。注意,标签数应该比截断点少一个:c(1, 2, 5, 10, 15, 20) %>% cut( breaks = c(0, 5, 10, 15, 20), labels = c("sm", "md", "lg", "xl") )[1] sm sm sm md lg xl Levels: sm md lg xl
3.6 数值排名
dplyr 提供了许多受 SQL 启发的排名函数,例如 min_rank() ,它使用典型的方法来处理并列关系: 1st, 2nd, 2nd, 4th:
x <- c(1, 2, 2, 2, 3, 4, NA)
min_rank(x)[1] 1 2 2 2 5 6 NA# 通过 desc() 按从高到低排名
min_rank(desc(x))[1] 6 3 3 3 2 1 NA如果 min_rank() 无法满足需求,dplyr 还提供了很多变体排名函数:
-
row_number(): 为向量中的每个对象生成连续数字。row_number()可以不带任何参数,这种情况下常用于生成行号。 -
dense_rank():类似于min_rank(),但是生成连续排名,如:1st, 2nd, 2nd, 3th -
percent_rank():percent_rank(x)计算小于 xi 的值的总数 ÷ (x的总数 -1) -
cume_dist():cume_dist(x)计算小于或等于 xi 的值的总数 ÷ x的总数
以上所有函数会忽略缺失值。
df <- tibble(x)
df |>
mutate(
row_number = row_number(),
row_number_x = row_number(x),
min_rank = min_rank(x),
dense_rank = dense_rank(x),
percent_rank = percent_rank(x),
cume_dist = cume_dist(x)
)# A tibble: 7 × 7
x row_number row_number_x min_rank dense_rank percent_rank cume_dist
<dbl> <int> <int> <int> <int> <dbl> <dbl>
1 1 1 1 1 1 0 0.167
2 2 2 2 2 2 0.2 0.667
3 2 3 3 2 2 0.2 0.667
4 2 4 4 2 2 0.2 0.667
5 3 5 5 5 3 0.8 0.833
6 4 6 6 6 4 1 1
7 NA 7 NA NA NA NA NA
### 基于stringr的字符串处理

本章主要介绍基于 stringr 包的字符串和字符向量的处理。我们需要记住 stringr 中用于字符串处理的函数大多都以 str_ 开头,这样我们在 RStudio 通过键入 str_ 就能方便的浏览并选择我们需要的函数:
和字符处理密切相关的一个内容是正则表达式(regular expressions),由于这一部分内容较多,我们将在下一章介绍。
1 加载包
library(tidyverse)
library(babynames)本章用到的案例数据集“babynames”记录了美国婴儿的姓名分布数据。
babynames# A tibble: 1,924,665 × 5
year sex name n prop
<dbl> <chr> <chr> <int> <dbl>
1 1880 F Mary 7065 0.0724
2 1880 F Anna 2604 0.0267
3 1880 F Emma 2003 0.0205
4 1880 F Elizabeth 1939 0.0199
5 1880 F Minnie 1746 0.0179
6 1880 F Margaret 1578 0.0162
7 1880 F Ida 1472 0.0151
8 1880 F Alice 1414 0.0145
9 1880 F Bertha 1320 0.0135
10 1880 F Sarah 1288 0.0132
# ℹ 1,924,655 more rows2 查找字符
下面是 stringr 包中用于查找字符的函数,它们接受字符向量输入,常常和正则表达式配合使用:

2.1 str_dect() 和 str_starts()
str_dect(string, pattern) 查找 string 中是否有包含目标字符 pattern 的对象,返回一个逻辑向量。str_starts(string, pattern) 查找 string 中是否有开头为目标字符 pattern 的对象。
names <- babynames$name[1:10]
names [1] "Mary" "Anna" "Emma" "Elizabeth" "Minnie" "Margaret"
[7] "Ida" "Alice" "Bertha" "Sarah" # 查找“names”中是否有以“M”开头的对象
str_detect(names, "^M") [1] TRUE FALSE FALSE FALSE TRUE TRUE FALSE FALSE FALSE FALSE# 也可以用str_starts()
str_starts(names, "M") [1] TRUE FALSE FALSE FALSE TRUE TRUE FALSE FALSE FALSE FALSE【练习】统计每年有多少名婴儿的名字中包含了“x”,并用折线图可视化这些婴儿每年的占比情况:
babynames %>%
mutate(x_count = str_detect(name, "x") * n) %>%
group_by(year) %>%
summarise(prop_x = sum(x_count) / sum(n)) %>%
ggplot(aes(x = year, y = prop_x)) +
geom_line() +
theme_bw()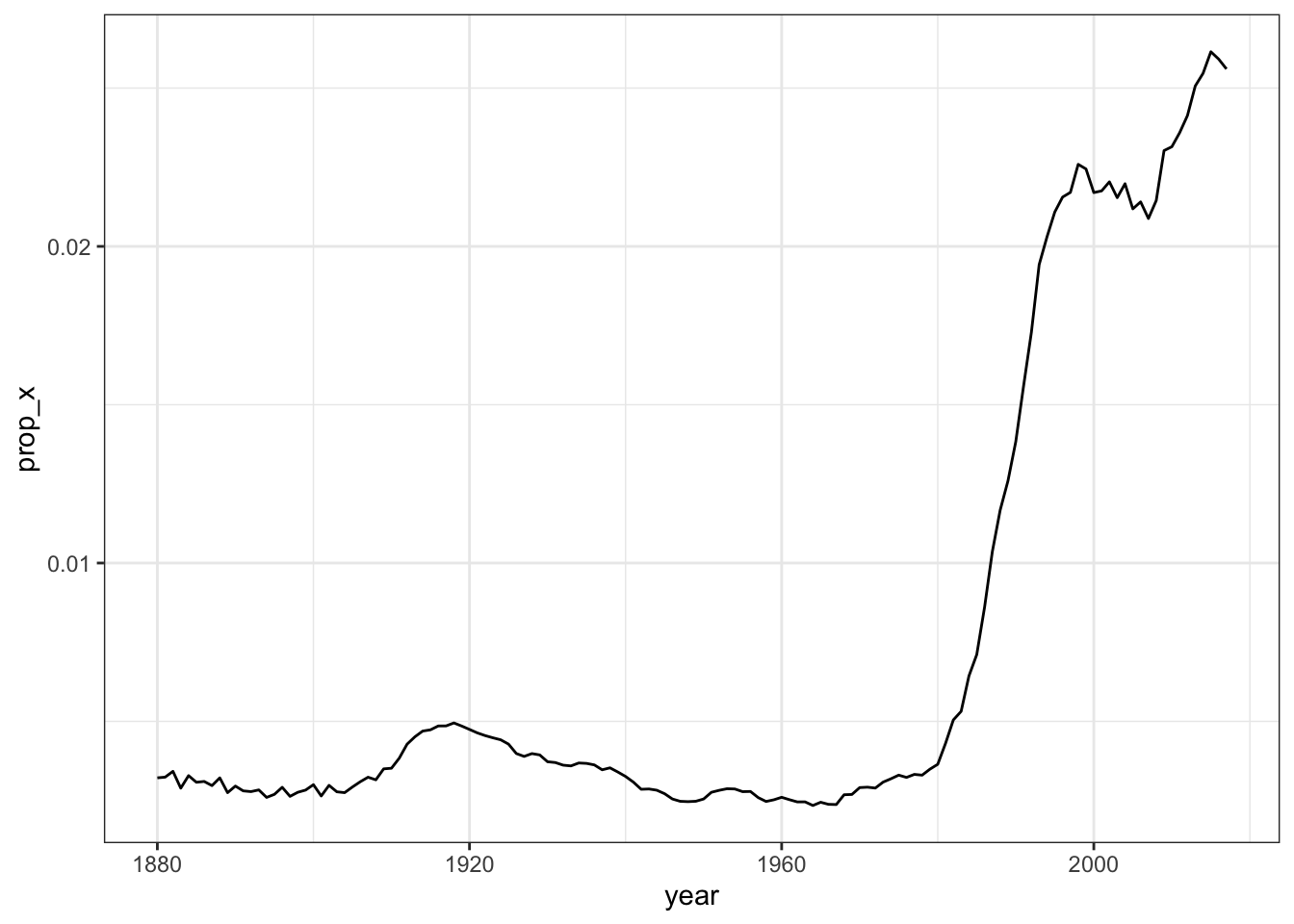
2.2 str_which()
str_which(string, pattern) 查找 string 中是否有包含目标字符 pattern 的对象,返回匹配到的对象的位置。
str_which(names, "^M")[1] 1 5 6Tip
stringr 包的字符查找函数中的 pattern 是要区分大小写的,也意味着这些函数在查找时会区分大小写。
上述函数都可以添加一个 negate = TRUE 参数,表示查找没有包含目标字符的对象,如:
str_detect(names, "^M", negate = TRUE) [1] FALSE TRUE TRUE TRUE FALSE FALSE TRUE TRUE TRUE TRUEstr_which(names, "^M", negate = TRUE)[1] 2 3 4 7 8 9 102.3 str_view()

str_view(string, pattern) 是一个比较特殊的字符查找函数,它返回的结果以HTML渲染样式来返回 string 中所有匹配的字符,并且会将其中的 pattern 以“<>”标记出来:
str_view(names, "^M")[1] │ <M>ary
[5] │ <M>innie
[6] │ <M>argaretbase 包中的字符查找函数
3 截取字符

3.1 str_sub()
str_sub(string,start,end) 用于提取指定长度和位置的字符串,其中 start 和 end 是截取字符串应该开始和结束的位置。返回的字符串的长度 = end - start + 1。base 包中与之对应的函数是 substr() 。
fruit_list <- c("A_p ple", " Banana", "Pear", NA)
str_sub(fruit_list, 1, 3)[1] "A_p" " Ba" "Pea" NA # 负号表示距末尾多少个字符截取:
str_sub(fruit_list, -3, -1)[1] "ple" "ana" "ear" NA str_sub() 在其后方添加赋值后还可以实现对特定位置字符的替换,见下文。
3.2 str_subset()
str_subset(string, pattern) 返回 string 中包含 pattern 的所有对象。功能类似于添加了 value = TRUE 参数时的 grep() 函数。
# 返回“names”中开头为“M”的对象
str_subset(names, "^M")[1] "Mary" "Minnie" "Margaret"4 替换字符

4.1 str_sub() <- value
用 str_sub() <- value 可以实现对特定位置字符的替换。例如将“fruit_list”中的第1-3位字符替换成“***”:
str_sub(fruit_list, 1, 3) <- "***"
fruit_list[1] "*** ple" "***nana" "***r" NA 4.2 str_replace()
-
str_replace(string, pattern, replacement)将string中的第一个pattern替换成replacement。 -
str_replace_all(string, pattern, replacement)将string中的所有pattern替换成replacement。
fruit_list <- c("A_p p le", " B anana", "Pear ", NA)
# 将“fruit_list”中的第一个空格替换成“#”
str_replace(fruit_list, pattern = " ", replacement = "#")[1] "A_p#p le" "#B anana" "Pear#" NA # 将“fruit_list”中的所有空格替换成“#”
str_replace_all(fruit_list, pattern = " ", replacement = "#")[1] "A_p#p#le" "#B#anana" "Pear#" NA 4.3 str_remove()
-
str_remove(string, pattern)将string中的第一个pattern删除。 -
str_remove_all(string, pattern)将string中的所有pattern删除。
# 删除“fruit_list”中的第一个空格
str_remove(fruit_list, pattern = " ")[1] "A_pp le" "B anana" "Pear" NA # 删除“fruit_list”中的所有空格
str_remove_all(fruit_list, pattern = " ")[1] "A_pple" "Banana" "Pear" NA base 包中的字符替换函数
4.4 转换大小写

str_to_upper(c("abc", "def"))[1] "ABC" "DEF"str_to_lower(c("ABC", "DEF"))[1] "abc" "def"str_to_title(c("ABC", "DEF"))[1] "Abc" "Def"base 包中与之对应的函数是 toupper() 和 tolower() 。
5 拼接字符

5.1 str_c()
str_c() 和 str_glue() 用于拼接字符。str_c() 与 base 包的 paste0() 的用法非常相似,但前者遵循 tidyverse 规则,不会对缺失值进行处理,能够更好的与 mutate() 配合使用:
df <- tibble(name = c("Flora", "David", "Terra", NA, "Eric", NA))
df %>% mutate(greeting = str_c("Hi ", name, "!"))# A tibble: 6 × 2
name greeting
<chr> <chr>
1 Flora Hi Flora!
2 David Hi David!
3 Terra Hi Terra!
4 <NA> <NA>
5 Eric Hi Eric!
6 <NA> <NA> # 用paste0()的效果
df %>% mutate(greeting = paste0("Hi ", name, "!"))# A tibble: 6 × 2
name greeting
<chr> <chr>
1 Flora Hi Flora!
2 David Hi David!
3 Terra Hi Terra!
4 <NA> Hi NA!
5 Eric Hi Eric!
6 <NA> Hi NA! Caution
从上面的例子中可以发现,str_c() 和 paste0() 的一个最重要的区别是 str_c() 会忽略缺失值,而 paste0() 会将缺失值也作为一个字符处理。
如果希望在遇到缺失值时以其他字符替换显示,可以使用 coalesce(x, "y") ,它会将x中的所有缺失值替换成“y”。根据需要,可以在 str_c() 内部或外部使用它:
# 演示coalesc()的作用
coalesce(df$name, "you")[1] "Flora" "David" "Terra" "you" "Eric" "you" df |>
mutate(
greeting1 = str_c("Hi ", coalesce(name, "you"), "!"),
greeting2 = coalesce(str_c("Hi ", name, "!"), "Hi someone!"),
.keep = "used"
)# A tibble: 6 × 3
name greeting1 greeting2
<chr> <chr> <chr>
1 Flora Hi Flora! Hi Flora!
2 David Hi David! Hi David!
3 Terra Hi Terra! Hi Terra!
4 <NA> Hi you! Hi someone!
5 Eric Hi Eric! Hi Eric!
6 <NA> Hi you! Hi someone!可以通过添加 sep 参数,以固定的分隔符分隔多个字符向量,类似于 paste() 中的 sep 参数(两者对待缺失值的行为不一样):
df <- df %>%
mutate(
age = c(11, 16, 20, 18, NA, 22),
height = c(116, 170, NA, 180, NA, 177)
)
df %>%
mutate(
combine = str_c(coalesce(name, "unknown"), age, height, sep = "-")
)# A tibble: 6 × 4
name age height combine
<chr> <dbl> <dbl> <chr>
1 Flora 11 116 Flora-11-116
2 David 16 170 David-16-170
3 Terra 20 NA <NA>
4 <NA> 18 180 unknown-18-180
5 Eric NA NA <NA>
6 <NA> 22 177 unknown-22-177# 用paste()替换str_c()
df %>%
mutate(
combine = paste(coalesce(name, "unknown"), age, height, sep = "-")
)# A tibble: 6 × 4
name age height combine
<chr> <dbl> <dbl> <chr>
1 Flora 11 116 Flora-11-116
2 David 16 170 David-16-170
3 Terra 20 NA Terra-20-NA
4 <NA> 18 180 unknown-18-180
5 Eric NA NA Eric-NA-NA
6 <NA> 22 177 unknown-22-177如果给 str_c() 只提供了一个字符向量,这个时候如果需要将该向量内的字符以固定的分隔符合并为一个字符,则需要指定 collapse 参数。这种情况可以和 summarize() 配合使用,并且一般会使用另一个字符连接函数 str_flatten() (见)。
str_c(coalesce(df$name, "unknown"), collapse = "-")[1] "Flora-David-Terra-unknown-Eric-unknown"paste(df$name, collapse = "-")[1] "Flora-David-Terra-NA-Eric-NA"5.2 str_glue() 和 str_glu_data()
如果你需要将很多字符串向量和多个固定字符粘贴起来,如果这时候仍然用 str_c() 会让代码看上去比较混乱和难以理解。这种情况我们可以使用 str_glue() 来简化代码。 str_glue() 将需要调用的字符向量放到“{}”内,括号外可以输入任意自定义字符。
df %>%
mutate(
greeting = str_glue(
"My name is {name}, ",
"my age is {age}, ",
"my height is {height/100} meters.",
.na = "**"
)
)# A tibble: 6 × 4
name age height greeting
<chr> <dbl> <dbl> <glue>
1 Flora 11 116 My name is Flora, my age is 11, my height is 1.16 meters.
2 David 16 170 My name is David, my age is 16, my height is 1.7 meters.
3 Terra 20 NA My name is Terra, my age is 20, my height is ** meters.
4 <NA> 18 180 My name is **, my age is 18, my height is 1.8 meters.
5 Eric NA NA My name is Eric, my age is **, my height is ** meters.
6 <NA> 22 177 My name is **, my age is 22, my height is 1.77 meters. Caution
str_glue() 默认情况下会将缺失值转换为字符串 “NA”,这一点与 str_c() 不一致。可以通过添加 .na 参数指定将缺失值替换成什么。
5.2.1 str_glue_data()
如果你想脱离 mutate(),在一个表格中简单的通过连接几列来返回一个字符向量,那么用 str_glue_data() 可能更合适。其语法为:str_glue_data(.x, ..., .sep, .na = "NA") 。
cars <- head(mtcars)
cars mpg cyl disp hp drat wt qsec vs am gear carb
Mazda RX4 21.0 6 160 110 3.90 2.620 16.46 0 1 4 4
Mazda RX4 Wag 21.0 6 160 110 3.90 2.875 17.02 0 1 4 4
Datsun 710 22.8 4 108 93 3.85 2.320 18.61 1 1 4 1
Hornet 4 Drive 21.4 6 258 110 3.08 3.215 19.44 1 0 3 1
Hornet Sportabout 18.7 8 360 175 3.15 3.440 17.02 0 0 3 2
Valiant 18.1 6 225 105 2.76 3.460 20.22 1 0 3 1str_glue_data(cars, "{rownames(cars)} has {hp} hp")Mazda RX4 has 110 hp
Mazda RX4 Wag has 110 hp
Datsun 710 has 93 hp
Hornet 4 Drive has 110 hp
Hornet Sportabout has 175 hp
Valiant has 105 hp# 在mutate()外使用str_glue()实现同样的目的需要反复调用数据集名称
str_glue("{rownames(cars)} has {cars$hp} hp") Mazda RX4 has 110 hp
Mazda RX4 Wag has 110 hp
Datsun 710 has 93 hp
Hornet 4 Drive has 110 hp
Hornet Sportabout has 175 hp
Valiant has 105 hp5.3 str_flatten()
str_c() 和 str_glue() 可以很好地与 mutate() 配合使用,因为它们的输出与输入长度相同。如果想要一个能与 summarize() 完美配合的函数,即总是返回单个字符串的函数,就可以用 str_flatten() :它接收单个字符向量,并以固定的分隔符将向量中的每个元素合并为一个字符。
str_flatten(c("x", "y", "z"), collapse = ", ", last = ", and ")[1] "x, y, and z"例如,统计每个人喜欢的水果,把每个人喜欢的水果用逗号连接起来:
df <- tribble(
~ name, ~ fruit,
"Carmen", "banana",
"Carmen", "apple",
"Marvin", "nectarine",
"Terence", "cantaloupe",
"Terence", "papaya",
"Terence", "mandarin"
)
df |>
group_by(name) |>
summarize(fruits = str_flatten(fruit, collapse = ", "))# A tibble: 3 × 2
name fruits
<chr> <chr>
1 Carmen banana, apple
2 Marvin nectarine
3 Terence cantaloupe, papaya, mandarin# 也可以用str_c()并指定collapse参数
df |>
group_by(name) |>
summarize(fruits = str_c(fruit, collapse = ", "))# A tibble: 3 × 2
name fruits
<chr> <chr>
1 Carmen banana, apple
2 Marvin nectarine
3 Terence cantaloupe, papaya, mandarin6 分割字符

str_split(string, pattern, simplify, i) 可以根据某个分割符将字符向量中的每一个对象分割成n列。其中:
-
string:待分割的字符向量。其中每个对象包含的分割符数量可以是不同的。 -
pattern:指定分割符。 -
simplify:默认“FALSE”,返回一个字符向量列表。设置为“TRUE”时(常用),则返回字符矩阵(character matrix)。
可以在 str_split() 外通过添加 [x, y] 来提取拆分后的指定列或行的字符。
df <- tibble(
fruits = c(
"apples-oranges-pears-bananas",
"pineapples-mangos-guavas"
)
)
str_split(df$fruits, "-", simplify = T) [,1] [,2] [,3] [,4]
[1,] "apples" "oranges" "pears" "bananas"
[2,] "pineapples" "mangos" "guavas" "" str_split(df$fruits, "-", simplify = T)[,2] [1] "oranges" "mangos" df %>%
mutate(
"2nd_fruit" = str_split(fruits, "-", simplify = T)[,2]
)# A tibble: 2 × 2
fruits `2nd_fruit`
<chr> <chr>
1 apples-oranges-pears-bananas oranges
2 pineapples-mangos-guavas mangos 6.1 字符列的分割
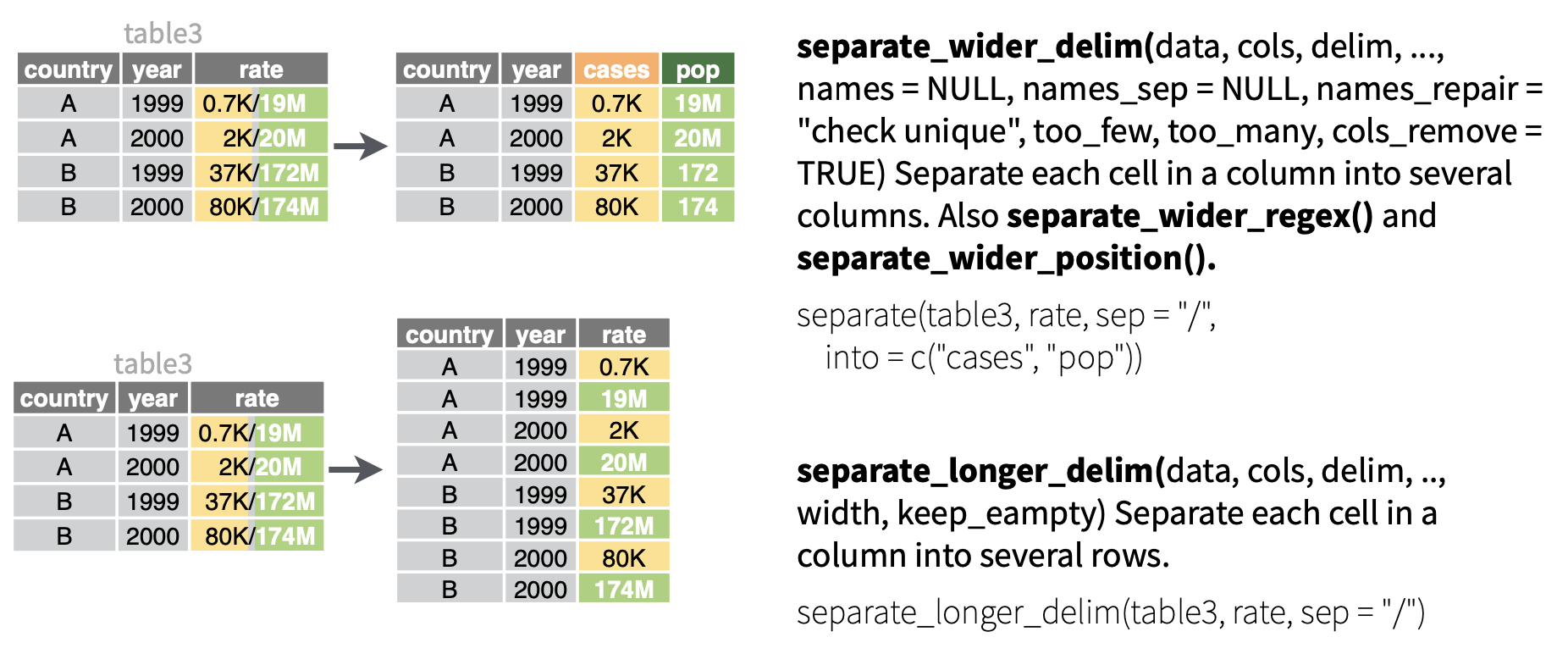
separate_wider_position() 、 separate_wider_delim() 以及 separate_wider_regex() 用于将某一列根据分割符(separate_wider_delim())、固定宽度(separate_wider_position())或正则表达式(separate_wider_regex())拆分为多列。这些函数包括在 tidyr 包中,因为它们的操作对象是数据框(列),而不是单个字符向量。把这些函数中的“wider”替换成“longer”就构成了另外三个类似函数,用于将某一列根据分割符、固定宽度或正则表达式拆分为多行(不常用)。
6.1.1 separate_wider_delim()
将数据框中的某列根据某个符号(delim)拆分成几列:
Table 1: 字符列的分割案例
df3 <- tibble(x = c("a10-1-2022", "b10-2-2011", "e15-1-2015"))
df3# A tibble: 3 × 1
x
<chr>
1 a10-1-2022
2 b10-2-2011
3 e15-1-2015df3 |>
separate_wider_delim(
x,
delim = "-",
names = c("code", "edition", "year"),
cols_remove = F # 不要移除原始列
)# A tibble: 3 × 4
code edition year x
<chr> <chr> <chr> <chr>
1 a10 1 2022 a10-1-2022
2 b10 2 2011 b10-2-2011
3 e15 1 2015 e15-1-2015这个效果是否用上面的 str_split() 也可以实现?
如果拆分后某几列的数据不需要,可以将其指定为“NA”,这样在输出结果中指定为“NA”的列将不会显示:
df3 |>
separate_wider_delim(
x,
delim = "-",
names = c("code", NA, "year")
)# A tibble: 3 × 2
code year
<chr> <chr>
1 a10 2022
2 b10 2011
3 e15 2015 在上面的 Table 1 中,待分割列有固定的分隔符分隔我们想要提取的变量,这种情况用 separate_wider_delim() 可以便捷的分割这些变量。但是在下面的 Table 2 中待分割列中的变量间由不同的分隔符分隔,这个时候我们可以通过正则表达式来定义分隔符。delim 参数支持通过 regex() 包装的正则表达式:
Table 2: 在separate_wider_delim()中应用正则表达式
df4 <- tibble(x = c("a10-1_2022 January", "b10-2_2011 February", "e15-1_2015 March"))
df4# A tibble: 3 × 1
x
<chr>
1 a10-1_2022 January
2 b10-2_2011 February
3 e15-1_2015 March df4 |>
separate_wider_delim(
x,
delim = regex("-|_|\\s"), # 或者写成 "-|_| "
names = c("code", "edition", "year", "month"),
cols_remove = F
)# A tibble: 3 × 5
code edition year month x
<chr> <chr> <chr> <chr> <chr>
1 a10 1 2022 January a10-1_2022 January
2 b10 2 2011 February b10-2_2011 February
3 e15 1 2015 March e15-1_2015 March 6.1.2 separate_wider_regex()
根据正则表达式拆分列:
df_age <- tribble(
~str,
"<Sheryl>-F_34",
"<Kisha>-F_45",
"<Brandon>-N_33",
"<Sharon>-F_38",
"<Penny>-F_58",
"<Justin>-M_41",
"<Patricia>-F_84",
)
# 给予赋值的对象会被写入新列,其他字符会被删除
df_age |>
separate_wider_regex(
str,
patterns = c(
"<",
name = ".+",
">-",
gender = ".",
"_",
age = ".+"
)
)# A tibble: 7 × 3
name gender age
<chr> <chr> <chr>
1 Sheryl F 34
2 Kisha F 45
3 Brandon N 33
4 Sharon F 38
5 Penny F 58
6 Justin M 41
7 Patricia F 84 6.1.3 separate_wider_position()
拆分指定长度的字符构成新列:
df4 <- tibble(x = c("202215TX", "202122LA", "202325CA"))
df4 |>
separate_wider_position(
x,
widths = c(year = 4, age = 2, state = 2)
)# A tibble: 3 × 3
year age state
<chr> <chr> <chr>
1 2022 15 TX
2 2021 22 LA
3 2023 25 CA 6.1.4 拆分错误调试
在使用 separate_wider_delim() 时,如果需要拆分的字符串中某些字符根据指定分割符拆封后片段数不足,则会发生报错:
df <- tibble(x = c("1-1-1", "1-1-2", "1-3", "1-3-2", "1"))df |>
separate_wider_delim(
x,
delim = "-",
names = c("x", "y", "z")
)Error in `separate_wider_delim()`:
! Expected 3 pieces in each element of `x`.
! 2 values were too short.
ℹ Use `too_few = "debug"` to diagnose the problem.
ℹ Use `too_few = "align_start"/"align_end"` to silence this message.
Run `rlang::last_trace()` to see where the error occurred.对于这种情况,可以手动检查数据问题,但是在实际应用中需要转换的字符列可能非常长,我们难以知道到底在哪一行出现了问题。这个时候,我们可以按照错误提示所说的那样,通过添加 too_few = "debug" 参数来进入调试模式:
debug <- df |>
separate_wider_delim(
x,
delim = "-",
names = c("x", "y", "z"),
too_few = "debug"
)
debug# A tibble: 5 × 6
x y z x_ok x_pieces x_remainder
<chr> <chr> <chr> <lgl> <int> <chr>
1 1-1-1 1 1 TRUE 3 ""
2 1-1-2 1 2 TRUE 3 ""
3 1-3 3 <NA> FALSE 2 ""
4 1-3-2 3 2 TRUE 3 ""
5 1 <NA> <NA> FALSE 1 "" 使用调试模式时,输出的结果会多出三列:“x_ok”、“x_pieces” 和 “x_remainder”(前缀“x”是输入的变量名):
-
“x_ok”列:“TRUE”代表这一行能够被成功分割;而“FALSE”代表这一行分割失败。
-
“x_pieces”列:告诉我们这一行能够被分割成多少片段。
-
“x_remainder”列:在指定了
too_many参数时有用。它告诉我们每一行多出来的具体字符(见下文)。
因此,利用“x_ok”我们可以方便的找出转换失败的行:
debug |> filter(!x_ok)# A tibble: 2 × 6
x y z x_ok x_pieces x_remainder
<chr> <chr> <chr> <lgl> <int> <chr>
1 1-3 3 <NA> FALSE 2 ""
2 1 <NA> <NA> FALSE 1 "" 在发现了这些错误之处后,可以在原始数据中修复这些问题,然后重新运行 separate_wider_delim() ,并确保删除 too_few = "debug"。
在其他情况下,我们可能想用 “NA” 填补缺失的部分。这就是 too_few = "align_start" 和 too_few = "align_end" 的作用,它们可以控制 “NA” 填充的位置(一般用 "align_start"):
df |>
separate_wider_delim(
x,
delim = "-",
names = c("x", "y", "z"),
too_few = "align_start"
)# A tibble: 5 × 3
x y z
<chr> <chr> <chr>
1 1 1 1
2 1 1 2
3 1 3 <NA>
4 1 3 2
5 1 <NA> <NA> 在上面这个案例中我们指定了 too_few 参数,它告诉程序如何处理分割后片段数少于 name 中所定义的新列数的情况,是debug还是用“NA”填充。另一种情况是指定 too_many 参数,它告诉程序如何处理分割后片段数超出 name 中所定义的新列数的情况,是debug(too_many = "debug")、舍弃(too_many = "drop"),还是合并(too_many = "merge")多出来的片段。下面是一个案例:
df <- tibble(x = c("1-1-1", "1-1-2", "1-3-5-6", "1-3-2", "1-3-5-7-9"))
debug <- df |>
separate_wider_delim(
x,
delim = "-",
names = c("x", "y", "z"),
too_many = "debug"
)
debug# A tibble: 5 × 6
x y z x_ok x_pieces x_remainder
<chr> <chr> <chr> <lgl> <int> <chr>
1 1-1-1 1 1 TRUE 3 ""
2 1-1-2 1 2 TRUE 3 ""
3 1-3-5-6 3 5 FALSE 4 "-6"
4 1-3-2 3 2 TRUE 3 ""
5 1-3-5-7-9 3 5 FALSE 5 "-7-9" 我们同样可以通过“x_ok”列寻找转换失败的行。在定义 too_many 的情况下,“x_remainder”就会发挥它的作用,这一列告诉我们每一行超出来的具体字符。
接下来我们可以决定如何处理超出来的片段:
# 删除超出的片段
df |>
separate_wider_delim(
x,
delim = "-",
names = c("x", "y", "z"),
too_many = "drop"
)# A tibble: 5 × 3
x y z
<chr> <chr> <chr>
1 1 1 1
2 1 1 2
3 1 3 5
4 1 3 2
5 1 3 5 # 合并超出的片段
df |>
separate_wider_delim(
x,
delim = "-",
names = c("x", "y", "z"),
too_many = "merge"
)# A tibble: 5 × 3
x y z
<chr> <chr> <chr>
1 1 1 1
2 1 1 2
3 1 3 5-6
4 1 3 2
5 1 3 5-7-97 计算字符长度

str_length() 可以返回字符串中每一个字符的长度(空格算一个字符):
str_length(c("a", "R for data science", NA))[1] 1 18 NA下面我们用“babynames”数据集,来演示如何利用 str_length() + count(),来统计婴儿名字长度的分布情况,然后使用 Filter() 来查看最长的名字:
babynames# A tibble: 1,924,665 × 5
year sex name n prop
<dbl> <chr> <chr> <int> <dbl>
1 1880 F Mary 7065 0.0724
2 1880 F Anna 2604 0.0267
3 1880 F Emma 2003 0.0205
4 1880 F Elizabeth 1939 0.0199
5 1880 F Minnie 1746 0.0179
6 1880 F Margaret 1578 0.0162
7 1880 F Ida 1472 0.0151
8 1880 F Alice 1414 0.0145
9 1880 F Bertha 1320 0.0135
10 1880 F Sarah 1288 0.0132
# ℹ 1,924,655 more rowsbabynames |>
count(length = str_length(name), wt = n)# A tibble: 14 × 2
length n
<int> <int>
1 2 338150
2 3 8589596
3 4 48506739
4 5 87011607
5 6 90749404
6 7 72120767
7 8 25404066
8 9 11926551
9 10 1306159
10 11 2135827
11 12 16295
12 13 10845
13 14 3681
14 15 830# 查看最长的名字
babynames |>
filter(str_length(name) == max(str_length(name))) |>
count(name, wt = n, sort = TRUE)# A tibble: 34 × 2
name n
<chr> <int>
1 Franciscojavier 123
2 Christopherjohn 118
3 Johnchristopher 118
4 Christopherjame 108
5 Christophermich 52
6 Ryanchristopher 45
7 Mariadelosangel 28
8 Jonathanmichael 25
9 Christianjoseph 22
10 Christopherjose 22
# ℹ 24 more rows
### 正则表达式
正则表达式是一种简洁而强大的语言,用于描述字符串中的模式。正则表达式(regular expressions)有时被缩写为 “regex” 或 “regexp”。
library(tidyverse)1 轮流匹配(alternas)

用于模糊匹配。
1.1 "ab|d"
"ab|d" 匹配“ab”或“d”:
alternas <- c("abc", "abcde", "acbde")
str_view(alternas, "ab|d")[1] │ <ab>c
[2] │ <ab>c<d>e
[3] │ acb<d>e1.2 "[abd]"
"[abd]" 匹配“a”、“b”和“c”中的任意一个:
str_view(alternas, "[abc]")[1] │ <a><b><c>
[2] │ <a><b><c>de
[3] │ <a><c><b>de1.3 "[a-c]"
"[a-c]" 匹配包含“a”到“c”及其之间字母的字符,即匹配“a”、“b”或“c”:
str_view(alternas, "[a-c]")[1] │ <a><b><c>
[2] │ <a><b><c>de
[3] │ <a><c><b>de1.4 "[^abc]"
"[^abc]" 匹配不包含“a”、“b”及“c”的字符:
str_view(alternas, "[^abc]")[2] │ abc<d><e>
[3] │ acb<d><e>区分大小写
2 定量匹配(quantifiers)

2.1 "a."
"a." 匹配包含 “a” 和另一个任意字符的字符串:
str_view(c("a", "ab", "ae", "bd", "ea", "eab"), "a.")[2] │ <ab>
[3] │ <ae>
[6] │ e<ab># 匹配开头为“a”,最后为”e”,并且中间包含任意三个字符的字符串:
str_view(fruit, "a...e") [1] │ <apple>
[7] │ bl<ackbe>rry
[48] │ mand<arine>
[51] │ nect<arine>
[62] │ pine<apple>
[64] │ pomegr<anate>
[70] │ r<aspbe>rry
[73] │ sal<al be>rry# 如果只写一个点"."则只要有任意字符(包括空格)的对象都会被匹配到,而空对象不会被匹配到:
str_view(c("", "a ", "a b", "ae", "bd", "ea", "eab", "%"), ".")[2] │ <a>< >
[3] │ <a>< ><b>
[4] │ <a><e>
[5] │ <b><d>
[6] │ <e><a>
[7] │ <e><a><b>
[8] │ <%>2.2 "ab?"
"ab?" 匹配 “a”或“ab”:
str_view(c("a", "ac", "ab", "abb", "abc", "abcd"), "ab?")[1] │ <a>
[2] │ <a>c
[3] │ <ab>
[4] │ <ab>b
[5] │ <ab>c
[6] │ <ab>cd2.3 "ab+"
"ab+" 匹配“ab”、“abb”、“abbb”……,即“a”后至少一个“b”:
str_view(c("a", "ac", "ab", "abb", "abc", "abcd"), "ab+")[3] │ <ab>
[4] │ <abb>
[5] │ <ab>c
[6] │ <ab>cd2.4 "ab*"
“ab*” 匹配“a”、“ab”、“abb”、“abbb”……,即“a”或“a”后加任意数量的“b”:
str_view(c("ab", "ac", "ab", "abb", "abc", "abcd"), "ab*")[1] │ <ab>
[2] │ <a>c
[3] │ <ab>
[4] │ <abb>
[5] │ <ab>c
[6] │ <ab>cdTip
匹配“ab”或以“a”开头“b”结尾的字符:
str_view(c("ab", "acb", "a b", "acdb"), "a.*b")[1] │ <ab>
[2] │ <acb>
[3] │ <a b>
[4] │ <acdb>2.5 "a{n}"
除了上面任意数量字符的匹配,我们还可以使用 {} 精确指定字符的匹配数量:
chr <- c("a", "aab", "aba", "aaa.b", "aaaabc")
# 匹配“aa”
str_view(chr, "a{2}")[2] │ <aa>b
[4] │ <aa>a.b
[5] │ <aa><aa>bc# 等价于
str_view(chr, "aa")[2] │ <aa>b
[4] │ <aa>a.b
[5] │ <aa><aa>bc2.6 "a{n,}"
"a{2,}" 匹配“aa”、“aaa”、“aaaa”……,即匹配连续≥2次“a”的字符:
str_view(chr, "a{2,}")[2] │ <aa>b
[4] │ <aaa>.b
[5] │ <aaaa>bc2.7 "a{n,m}"
"a{n,m}" 匹配连续n-m个“a”:
# 匹配“aaa”和“aaaa”
str_view(chr, "a{3,4}")[4] │ <aaa>.b
[5] │ <aaaa>bc3 锚点匹配(anchors)

3.1 "^a" 和 "a$"
给匹配字符加上了位置锚点,只匹配开头("^a")或结尾(“a$”)字符:
str_view(fruit, "^a")[1] │ <a>pple
[2] │ <a>pricot
[3] │ <a>vocadostr_view(fruit, "a$") [4] │ banan<a>
[15] │ cherimoy<a>
[30] │ feijo<a>
[36] │ guav<a>
[56] │ papay<a>
[74] │ satsum<a># 强制完全匹配
str_view(fruit, "^apple$")[1] │ <apple>3.2 "\\b"
"\\b" 是字符边界标志,匹配单词之间的边界(即单词的开始或结束)。例如,我们要匹配以“The”开头的对象,如果直接写 "^The",则还会匹配到“These”、“There”、“Their”等单词,所以这个时候我们可以在“The”的后面加上边界标志 "\\b" ,表示这是一个独立的单词:
chr <- sentences[1:10]
chr [1] "The birch canoe slid on the smooth planks."
[2] "Glue the sheet to the dark blue background."
[3] "It's easy to tell the depth of a well."
[4] "These days a chicken leg is a rare dish."
[5] "Rice is often served in round bowls."
[6] "The juice of lemons makes fine punch."
[7] "The box was thrown beside the parked truck."
[8] "The hogs were fed chopped corn and garbage."
[9] "Four hours of steady work faced us."
[10] "A large size in stockings is hard to sell." str_view(chr, "^The")[1] │ <The> birch canoe slid on the smooth planks.
[4] │ <The>se days a chicken leg is a rare dish.
[6] │ <The> juice of lemons makes fine punch.
[7] │ <The> box was thrown beside the parked truck.
[8] │ <The> hogs were fed chopped corn and garbage.str_view(chr, "^The\\b")[1] │ <The> birch canoe slid on the smooth planks.
[6] │ <The> juice of lemons makes fine punch.
[7] │ <The> box was thrown beside the parked truck.
[8] │ <The> hogs were fed chopped corn and garbage.# 或者限定“The”后面必须有至少一个空格
str_view(chr, "^The\\s+")[1] │ <The >birch canoe slid on the smooth planks.
[6] │ <The >juice of lemons makes fine punch.
[7] │ <The >box was thrown beside the parked truck.
[8] │ <The >hogs were fed chopped corn and garbage.4 转译符(escape)
以上的这些符号称为元字符(metacharacters),它们在正则表达式中起到类似函数名的作用,不参与字面匹配。所有的元字符包括:.^$\|*+?{}[]()。如果我们想匹配元字符本身时应该怎么做呢?这时候就需要引入转译符(escape)。有两种转译符:"\\" 和 "[]":
chr <- c("abc", "a.bc", "a^bc", "a|bc", "a*bc", "a?bc", "a\\bc", "a\bc")
str_view(chr, "a\\.b")[2] │ <a.b>cstr_view(chr, "a\\^b")[3] │ <a^b>cstr_view(chr, "a\\|b")[4] │ <a|b>cstr_view(chr, "a\\*b")[5] │ <a*b>cstr_view(chr, "a\\?b")[6] │ <a?b>cstr_view(chr, "\\\\") [7] │ a<\>bc"[]" 的的效果和上面一样,但是它不能用于匹配转译符"//":
str_view(chr, "a[.]b")
str_view(chr, "a[*]b")
str_view(chr, "a[?]b")5 字符类别(character class/character set)匹配
匹配某种类型的字符,如 [a-z] 匹配任何小写字母, [0-9] 匹配任何数字。比较特殊的有:
5.1 "\\d+"
匹配任意数字字符:
chr <- "abcd ABCD 12345 -!@#%."
str_view(chr, "\\d+")[1] │ abcd ABCD <12345> -!@#%.# 等价
str_view(chr, "[0-9]+")[1] │ abcd ABCD <12345> -!@#%.5.2 "\\D+"
匹配任何非数字字符:
str_view(chr, "\\D+")[1] │ <abcd ABCD >12345< -!@#%.>5.3 "\\s+"
匹配空格(whitespaces),包括制表和换行符:
str_view(chr, "\\s+")[1] │ abcd< >ABCD< >12345< >-!@#%.# 或者直接输入空格
str_view(chr, " +")[1] │ abcd< >ABCD< >12345< >-!@#%.5.4 "\\S+"
匹配任何非空格字符:
str_view(chr, "\\S+")[1] │ <abcd> <ABCD> <12345> <-!@#%.>区分 "\\S+" 和 ".+"
5.5 "\\w+"
匹配任何单词字符,即字母和数字:
str_view(chr, "\\w+")[1] │ <abcd> <ABCD> <12345> -!@#%.5.6 "\\W+"
匹配任何“非单词”字符,即一些特殊字符:
str_view(chr, "\\W+")[1] │ abcd< >ABCD< >12345< -!@#%.>
### 循环
参考:
循环迭代,就是将一个函数依次应用(映射)到序列的每一个元素上。用R写循环从低到高有三种境界:基础的显式for循环,到apply()函数家族,最后到purrr包map()函数家族泛函式编程。在R语言中应该尽量避免显式循环的应用。而apply()函数家族和map()函数家族都能够用于避免显式使用循环结构。map()系列函数提供了更多的一致性、规范性和便利性,更容易记住和使用。速度来说,apply()家族稍快,但可以忽略不计。
1 apply函数家族
lapply()包含在R的基础包内,返回一个长度与 X(输入)相同的列表,其中的每个元素都是将目标函数(FUN)应用于X的相应元素的结果。其基本语法和map()一致,所以参考下面的map()函数的介绍。与之类似的apply()函数适合对数据框的操作,能够将目标函数应用于输入数据的行或列,然后输出一个向量或列表。
生成案例数据
mydata <- matrix(1:9, ncol = 3,nrow = 6) #生成一个3列、6行的矩阵数据
mydata[3,3] <- NA #生成一个缺失值
mydata <- as.data.frame(mydata) #如果要生成新的一列需要转换为数据框形式
mydata V1 V2 V3
1 1 7 4
2 2 8 5
3 3 9 NA
4 4 1 7
5 5 2 8
6 6 3 9计算mydata数据集中每一行的均值并添加到每一行后面
mydata$Row_Means <- apply(
mydata,
MARGIN = 1, # 1:对每行进行运算;2:对列进行运算;MARGIN=c(1,2)对行、列运算
mean, # 要应用的函数
na.rm = T # 是否忽略缺失值
)
mydata V1 V2 V3 Row_Means
1 1 7 4 4
2 2 8 5 5
3 3 9 NA 6
4 4 1 7 4
5 5 2 8 5
6 6 3 9 6求mydata数据集每一行第一列和第二列的均值
mydata$Row_Means12 <- apply(mydata[, c(1:2)], MARGIN = 1, mean,na.rm = T)
mydata V1 V2 V3 Row_Means Row_Means12
1 1 7 4 4 4.0
2 2 8 5 5 5.0
3 3 9 NA 6 6.0
4 4 1 7 4 2.5
5 5 2 8 5 3.5
6 6 3 9 6 4.5对mydata的每一列进行求和运算
Col_Sums <- apply(mydata, MARGIN = 2, sum, na.rm = T)
mydata <- rbind(mydata, Col_Sums)
mydata V1 V2 V3 Row_Means Row_Means12
1 1 7 4 4 4.0
2 2 8 5 5 5.0
3 3 9 NA 6 6.0
4 4 1 7 4 2.5
5 5 2 8 5 3.5
6 6 3 9 6 4.5
7 21 30 33 30 25.52 purrr包map()函数家族
2.1 map()
依次应用一元函数到一个序列的每个元素上,基本等同 lapply():
Tip
序列包括以下的类型:
-
原子向量(各个元素都是同类型的),包括 6 种类型:logical、integer、double、character、complex、raw,其中 integer 和 double 也统称为numeric
-
列表(包含的元素可以是不同类型的)
library(purrr)
chr <- list(x = c("a", "b"), y = c("c", "d"))
chr$x
[1] "a" "b"
$y
[1] "c" "d"# 让chr中的字符降序排列
map(chr, sort, decreasing = TRUE)$x
[1] "b" "a"
$y
[1] "d" "c"如过map()应用对象是数据框,那么会将函数应用于数据框的每一列(可以把数据框的每一列看作一个元素):
x_df <- data.frame(a = 1:10, b = 11:20, c = 21:30)
x_df a b c
1 1 11 21
2 2 12 22
3 3 13 23
4 4 14 24
5 5 15 25
6 6 16 26
7 7 17 27
8 8 18 28
9 9 19 29
10 10 20 30# 计算x_tab每一列的均值
map(x_df, mean)$a
[1] 5.5
$b
[1] 15.5
$c
[1] 25.5mean()函数还有其它参数,如 na.rm,这些需要特别指定的目标函数参数可以放到函数的后面:
map(x_df, mean, na.rm = TRUE) # 因为数据不含NA, 故结果同上$a
[1] 5.5
$b
[1] 15.5
$c
[1] 25.52.2 map2()
依次应用二元函数到两个序列的每对元素上(要求两个序列有相同的长度):
x <- list(a = 1:10, b = 11:20, c = 21:30)
x$a
[1] 1 2 3 4 5 6 7 8 9 10
$b
[1] 11 12 13 14 15 16 17 18 19 20
$c
[1] 21 22 23 24 25 26 27 28 29 30y <- list(1, 2, 3)
y[[1]]
[1] 1
[[2]]
[1] 2
[[3]]
[1] 3map2(x, y,\(x, y) x*y)$a
[1] 1 2 3 4 5 6 7 8 9 10
$b
[1] 22 24 26 28 30 32 34 36 38 40
$c
[1] 63 66 69 72 75 78 81 84 87 90map2()应用对象也可以是数据框和向量:
y_vec <- c(1:3)
y_vec[1] 1 2 3# 将y_vec中的每一个元素逐一与x_df中对应的列中的每个值相乘
map2(x_df, y_vec, \(x, y) x*y)$a
[1] 1 2 3 4 5 6 7 8 9 10
$b
[1] 22 24 26 28 30 32 34 36 38 40
$c
[1] 63 66 69 72 75 78 81 84 87 90y_df <- data.frame(d = 21:30, e = 11:20, f = 1:10)
y_df d e f
1 21 11 1
2 22 12 2
3 23 13 3
4 24 14 4
5 25 15 5
6 26 16 6
7 27 17 7
8 28 18 8
9 29 19 9
10 30 20 10# 将y_df中的每列逐一与x_df中对应的列中的每个值相乘
map2(x_df, y_df, \(x, y) x*y)$a
[1] 21 44 69 96 125 156 189 224 261 300
$b
[1] 121 144 169 196 225 256 289 324 361 400
$c
[1] 21 44 69 96 125 156 189 224 261 300# 输出数据框
map2_df(x_df, y_df, \(x, y) x*y)# A tibble: 10 × 3
a b c
<int> <int> <int>
1 21 121 21
2 44 144 44
3 69 169 69
4 96 196 96
5 125 225 125
6 156 256 156
7 189 289 189
8 224 324 224
9 261 361 261
10 300 400 3002.3 pmap()
应用多元函数到多个序列的每组元素上,可以实现对数据框逐行迭代

z <- list(4, 5, 6)
pmap(
list(x, y, z),
function(first, second, third) first * (second + third)
)$a
[1] 5 10 15 20 25 30 35 40 45 50
$b
[1] 77 84 91 98 105 112 119 126 133 140
$c
[1] 189 198 207 216 225 234 243 252 261 270也可以应用于数据框,实现对数据框逐行迭代:
x_df a b c
1 1 11 21
2 2 12 22
3 3 13 23
4 4 14 24
5 5 15 25
6 6 16 26
7 7 17 27
8 8 18 28
9 9 19 29
10 10 20 30pmap_dbl(
x_df,
~ ..1 * (..2 + ..3)
) # 这里用带后缀的形式(pmap_dbl)返回数值型向量(见下文) [1] 32 68 108 152 200 252 308 368 432 5002.4 给map函数添加后缀
map系列函数的运算结果默认是列表型的,但是map系列函数都有后缀形式,以决定循环迭代之后返回的数据类型,这是 purrr 比 apply函数族更先进和便利的一大优势。常用后缀如下(这里以map()为例,map2()和pmap()也有与之对应的后缀):
-
map_dbl(.x, .f): 返回数值型向量
【案例】在上面的map()案例中,求均值返回的结果是数值型,所以更好的做法是将返回结果指定为数值型向量,只需在
map后加上_dbl的后缀:map_dbl(x_df, mean)a b c 5.5 15.5 25.5 -
map_int(.x, .f): 返回整数型向量
-
map_lgl(.x, .f): 返回逻辑型向量
-
map_chr(.x, .f): 返回字符型向量
-
map_dfr(.x, .f): 返回数据框列表,再bind_rows按行合并为一个数据框【案例】批量读取具有相同列名的数据文件并合并成一个数据框
files = list.files("datas/", pattern = "xlsx", full.names = TRUE) df = map_dfr(files, read_xlsx) # 批量读取+按行堆叠合并map_dfr(files, read_xlsx)依次将read_xlsx()函数应用到各个文件路径上,即依次读取数据,返回结果是数据框,同时“dfr”表示再做按行合并,一步到位。若需要设置read_xlsx()的其它参数,只需在后面设置即可。 -
map_dfc(.x, .f): 返回数据框列表,再bind_cols按列合并为一个数据框
2.5 walk()系列
将函数依次作用到序列上,不返回结果。有些批量操作是没有或不关心返回结果的,例如批量保存到文件:save(), write_csv() 、saveRDS()等。walk()系列同样包括了walk()、walk2和pwalk()。
【例一】将mpg数据按“manufacturer”分组,每个“manufacturer”的数据分别保存为单独数据文件。
# 读取ggplot2包自带mpg数据集(该数据为tibble型)
df <- ggplot2::mpg
head(df)# A tibble: 6 × 11
manufacturer model displ year cyl trans drv cty hwy fl class
<chr> <chr> <dbl> <int> <int> <chr> <chr> <int> <int> <chr> <chr>
1 audi a4 1.8 1999 4 auto(l5) f 18 29 p compa…
2 audi a4 1.8 1999 4 manual(m5) f 21 29 p compa…
3 audi a4 2 2008 4 manual(m6) f 20 31 p compa…
4 audi a4 2 2008 4 auto(av) f 21 30 p compa…
5 audi a4 2.8 1999 6 auto(l5) f 16 26 p compa…
6 audi a4 2.8 1999 6 manual(m5) f 18 26 p compa…# 通过group_nest将mpg数据按“manufacturer”分组,每个“manufacturer”的数据分别保存为单独数据
library(dplyr)
df <- group_nest(df, manufacturer)
df# A tibble: 15 × 2
manufacturer data
<chr> <list<tibble[,10]>>
1 audi [18 × 10]
2 chevrolet [19 × 10]
3 dodge [37 × 10]
4 ford [25 × 10]
5 honda [9 × 10]
6 hyundai [14 × 10]
7 jeep [8 × 10]
8 land rover [4 × 10]
9 lincoln [3 × 10]
10 mercury [4 × 10]
11 nissan [13 × 10]
12 pontiac [5 × 10]
13 subaru [14 × 10]
14 toyota [34 × 10]
15 volkswagen [27 × 10]# 批量输出这些数据
pwalk(df, ~ write.csv(..2, paste0("output/r_basic/", ..1, ".csv")))
【例二】这个例子来自读取非标准10X格式文件,要实现在”output/r_basic/GSE184880_RAW”中批量建立文件夹的目的。
首先是构建文件夹的目录和名字,这一部分的目的参照读取非标准10X格式文件。
# 列出
files <- list.files("data/sc_supplementary/GSE184880_RAW")
files[1:10] [1] "GSM5599220_Norm1" "GSM5599220_Norm1.barcodes.tsv.gz"
[3] "GSM5599220_Norm1.genes.tsv.gz" "GSM5599220_Norm1.matrix.mtx.gz"
[5] "GSM5599221_Norm2" "GSM5599221_Norm2.barcodes.tsv.gz"
[7] "GSM5599221_Norm2.genes.tsv.gz" "GSM5599221_Norm2.matrix.mtx.gz"
[9] "GSM5599222_Norm3" "GSM5599222_Norm3.barcodes.tsv.gz"dirnames <- gsub(pattern = ".barcodes.tsv.gz|.genes.tsv.gz|.matrix.mtx.gz",
replacement = "",
x = files) %>%
unique() %>%
paste0("output/r_basic/GSE184880_RAW/", .)
dirnames [1] "output/r_basic/GSE184880_RAW/GSM5599220_Norm1"
[2] "output/r_basic/GSE184880_RAW/GSM5599221_Norm2"
[3] "output/r_basic/GSE184880_RAW/GSM5599222_Norm3"
[4] "output/r_basic/GSE184880_RAW/GSM5599223_Norm4"
[5] "output/r_basic/GSE184880_RAW/GSM5599224_Norm5"
[6] "output/r_basic/GSE184880_RAW/GSM5599225_Cancer1"
[7] "output/r_basic/GSE184880_RAW/GSM5599226_Cancer2"
[8] "output/r_basic/GSE184880_RAW/GSM5599227_Cancer3"
[9] "output/r_basic/GSE184880_RAW/GSM5599228_Cancer4"
[10] "output/r_basic/GSE184880_RAW/GSM5599229_Cancer5"
[11] "output/r_basic/GSE184880_RAW/GSM5599230_Cancer6"
[12] "output/r_basic/GSE184880_RAW/GSM5599231_Cancer7"# 在“output/r_basic”目标位置先建立一个“GSE184880_RAW”用于存放一会儿构建的文件夹
dir.create("output/r_basic/GSE184880_RAW")通过pwalk()根据文件夹的名称“dirnames”建立文件夹。⚠️注意pwalk()只能应用于列表对象,所以这里通过list()进行了转化:
pwalk(list(dirnames), dir.create)
建立好的文件夹
Tip
更多关于purr包的应用,参考:【R语言】优雅的循环迭代:purrr包、https://purrr.tidyverse.org。
apply家族 vs. map家族函数
3 在循环语句中的其他常用函数
3.1 assign()函数
assign函数能够将某个值赋值给指定名称,从而实现循环中将每次运行的结果保存到一个对象中,而不覆盖上一次运行的结果。
-
x:变量名称/赋值对象/最后的新变量的名称 -
value:需要赋给x的值
下面的案例实现输出”A”, “B”, “C”, “D”四个变量,每个变量就是一次循环的结果:
for (x in c("A", "B", "C", "D")){
y <- paste0(x, x)
assign(x = x, value = y)
}3.2 append函数
append()函数被广泛应用于将新的向量添加到现有的向量、列表或数据框中。
- 将新向量添加到已有向量中:
v1 <- c(1, 2, 3, 4, 5)
v2 <- c(6, 7, 8)
v3 <- append(v1, v2)
v3[1] 1 2 3 4 5 6 7 8#等价于
v3 <- c(v1, v2)- 将新列表添加到已有列表中:
list1 <- list(a = 1, b = 2, c = 3)
list2 <- list(d = 4, e = 5, f = 6)
list3 <- append(list1, list2)
list3$a
[1] 1
$b
[1] 2
$c
[1] 3
$d
[1] 4
$e
[1] 5
$f
[1] 6实际应用场景:在批量读取构建Seurat对象时,通过append()函数将每次的Seurat对象添加到列表中,最终得到一个包含了所有样本的单细胞数据的列表:
for (file in file_list) {
# 拼接文件路径
data.path <- paste0("data/other_single_cell_content/GSE234933_MGH_HNSCC_gex_raw_counts/", file)
# 读取RDS文件数据
seurat_data <- readRDS(data.path)
# 创建Seurat对象,并指定项目名称为文件名(去除后缀)
sample_name <- file_path_sans_ext(file)
seurat_obj <- CreateSeuratObject(counts = seurat_data,
project = sample_name,
min.features = 200,
min.cells = 3)
# 将Seurat对象添加到列表中
seurat_list <- append(seurat_list, seurat_obj)
}
### 数据可视化
本章介绍基于ggplot2包的数据可视化基本语法,主要介绍几个常用图形的语法。
1 加载包
library(tidyverse)
library(palmerpenguins) # 提供案例数据
library(ggthemes) # 提供调色板案例数据为Palmer Archipelago三个岛屿上企鹅的身体测量数据,这是一个tibble类型的数据集:
penguins# A tibble: 344 × 8
species island bill_length_mm bill_depth_mm flipper_length_mm body_mass_g
<fct> <fct> <dbl> <dbl> <int> <int>
1 Adelie Torgersen 39.1 18.7 181 3750
2 Adelie Torgersen 39.5 17.4 186 3800
3 Adelie Torgersen 40.3 18 195 3250
4 Adelie Torgersen NA NA NA NA
5 Adelie Torgersen 36.7 19.3 193 3450
6 Adelie Torgersen 39.3 20.6 190 3650
7 Adelie Torgersen 38.9 17.8 181 3625
8 Adelie Torgersen 39.2 19.6 195 4675
9 Adelie Torgersen 34.1 18.1 193 3475
10 Adelie Torgersen 42 20.2 190 4250
# ℹ 334 more rows
# ℹ 2 more variables: sex <fct>, year <int>2 ggplot基本语法
下面我们通过相关性散点图可视化企鹅的鳍长度和体重之间的关系,并通过不同的颜色和形状标注企鹅的种类。
ggplot(
penguins,
aes(x = flipper_length_mm,
y = body_mass_g,
color = species,
shape = species)
) +
geom_point() +
geom_smooth(method = "lm")
Tip
aes() 函数定义了如何将数据集中的变量映射到绘图的可视化属性(即美学,aesthetics)上。
可以看到,它给每个不同的企鹅类型都拟合了一条相关性趋势线。如果我们需要在整个数据集中拟合一条趋势线,则需要将区分企鹅类型的color = species和shape = species参数从全局的ggplot()中移动到geom_point()中:
ggplot(
data = penguins,
aes(x = flipper_length_mm,
y = body_mass_g)
) +
geom_point(aes(color = species, shape = species)) +
geom_smooth(method = "lm")
这是因为在ggplot()中定义了全局级别的美学映射后,这些映射会向下传递到绘图的每个后续geom层。不过,ggplot2 中的每个 geom 函数也可以接受一个映射参数,这样就可以在局部层级添加美学映射,并将其添加到从全局层级继承的映射中。由于我们希望根据企鹅种类定义每个点的颜色和形状,但不希望分别为每个企鹅种类绘制拟合线,因此我们应该只为 geom_point()指定 color = species和shape = species。
最后,为其添加文字并调用调色板:
ggplot(
penguins,
aes(x = flipper_length_mm, y = body_mass_g)
) +
geom_point(aes(color = species, shape = species)) +
geom_smooth(method = "lm") +
labs(
title = "Body mass and flipper length",
subtitle = "Dimensions for Adelie, Chinstrap, and Gentoo Penguins",
x = "Flipper length (mm)",
y = "Body mass (g)",
) +
scale_color_colorblind()
3 可视化分布
3.1 可视化分类变量的分布
用条形图可视化企鹅类型的分布:
ggplot(penguins,
aes(x = species)) +
geom_bar(fill = "red")
按照每个类型企鹅数量的多少重新排序条形图。可以通过fct_infreq()对“species”按照其频数重新排序:
ggplot(penguins,
aes(x = fct_infreq(species))) +
geom_bar(fill = "red")
3.2 可视化数值变量的分布
通过直方图可视化企鹅体重对分布情况:
ggplot(penguins,
aes(x = body_mass_g)) +
geom_histogram(binwidth = 200,
fill = "darkblue") 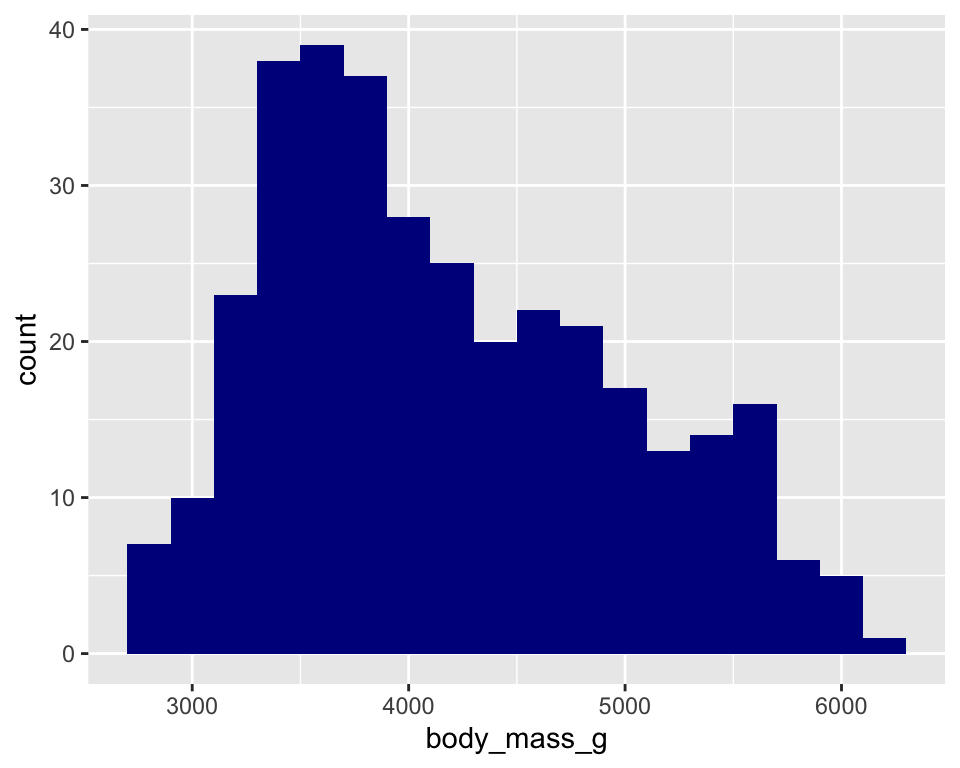
密度图是数值变量分布的另一种可视化方式。密度图是直方图的平滑化版本,与直方图相比,它显示的细节较少,但能让人更容易快速了解分布的形状。
ggplot(penguins,
aes(x = body_mass_g)) +
geom_density(color = "darkblue")
4 可视化关系
4.1 一个数值变量和一个分类变量
通过箱型图比较不同种类企鹅的体重:
ggplot(penguins,
aes(x = species,
y = body_mass_g)) +
geom_boxplot()
箱型图的解释
密度图:
ggplot(penguins,
aes(x = body_mass_g,
color = species,
fill = species)) +
geom_density(alpha = 0.5)
4.2 两个分类变量
通过堆叠条形图比价不同岛屿上的企鹅类型分布情况:
ggplot(penguins,
aes(x = island,
fill = species)) +
geom_bar()
可以通过在 geom 中设置 position = "fill"(填充)绘制相对频率图,它更适用于比较各岛屿的物种分布情况,因为它不会受到各岛屿企鹅数量不等的影响。
ggplot(penguins,
aes(x = island,
fill = species)) +
geom_bar(position = "fill")
4.3 两个数值变量
在上面的ggplot基本语法中我们已经介绍了通过散点图展示两个数值型变量关系的语法:
ggplot(
penguins,
aes(x = flipper_length_mm,
y = body_mass_g)
) +
geom_point() +
geom_smooth(method = "lm") 
4.4 两个以上变量
正如我们在ggplot基本语法中所看到的,我们可以通过将更多变量映射到其他美学元素中,从而将更多变量整合到散点图中。例如,在下面的散点图中,点的颜色代表企鹅种类,点的形状代表所在岛屿:
ggplot(penguins,
aes(x = flipper_length_mm,
y = body_mass_g)) +
geom_point(aes(color = species,
shape = island))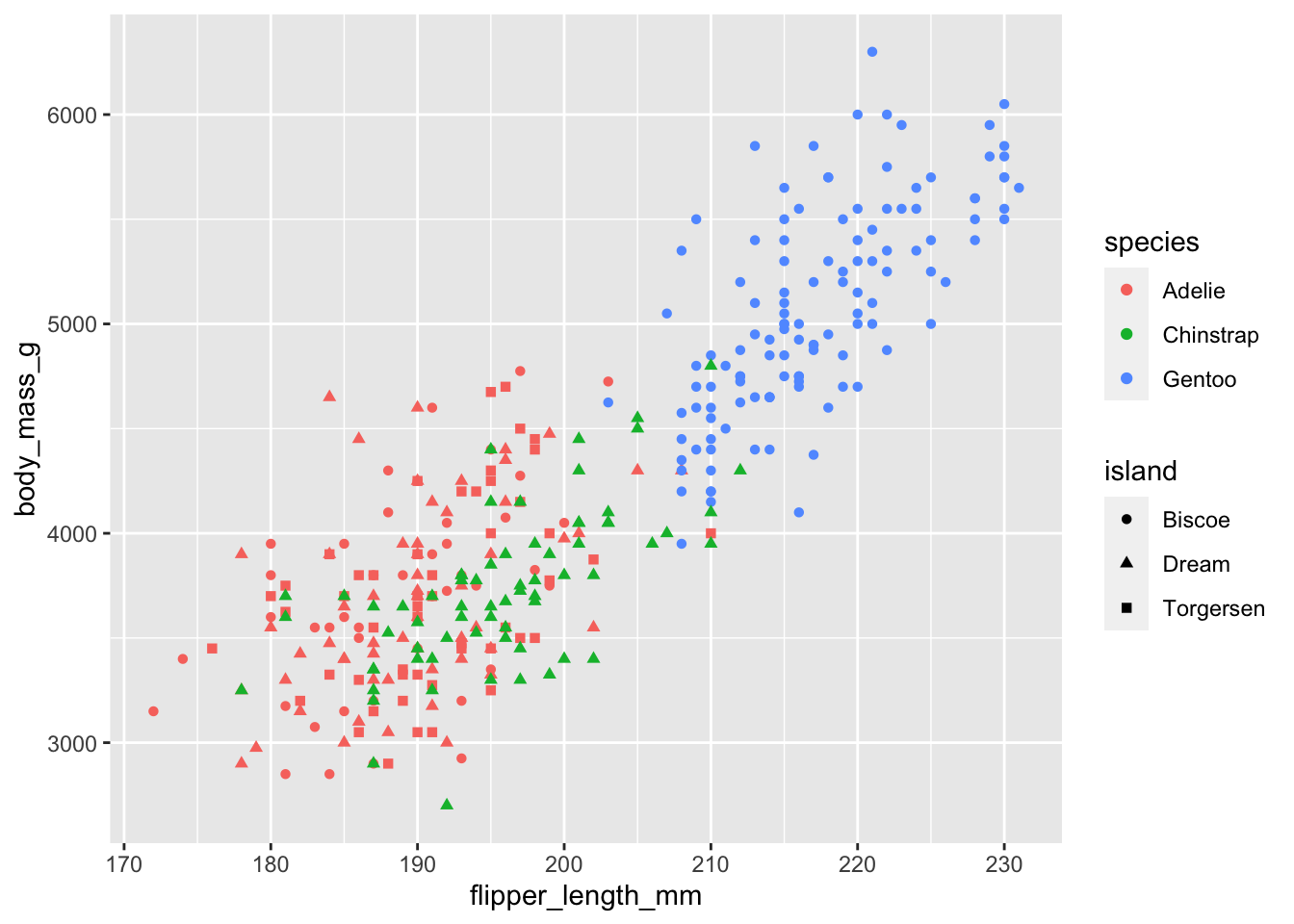
然而,在绘图中添加过多的美学映射会使绘图变得杂乱无章,难以理解。另一种方法对分类变量尤为有用,那就是通过facet_wrap()绘制分面图,即分别显示一个数据子集的子绘图。
ggplot(penguins,
aes(x = flipper_length_mm,
y = body_mass_g)) +
geom_point(aes(color = species,
shape = species)) +
geom_smooth(method = "lm") +
facet_wrap(~island)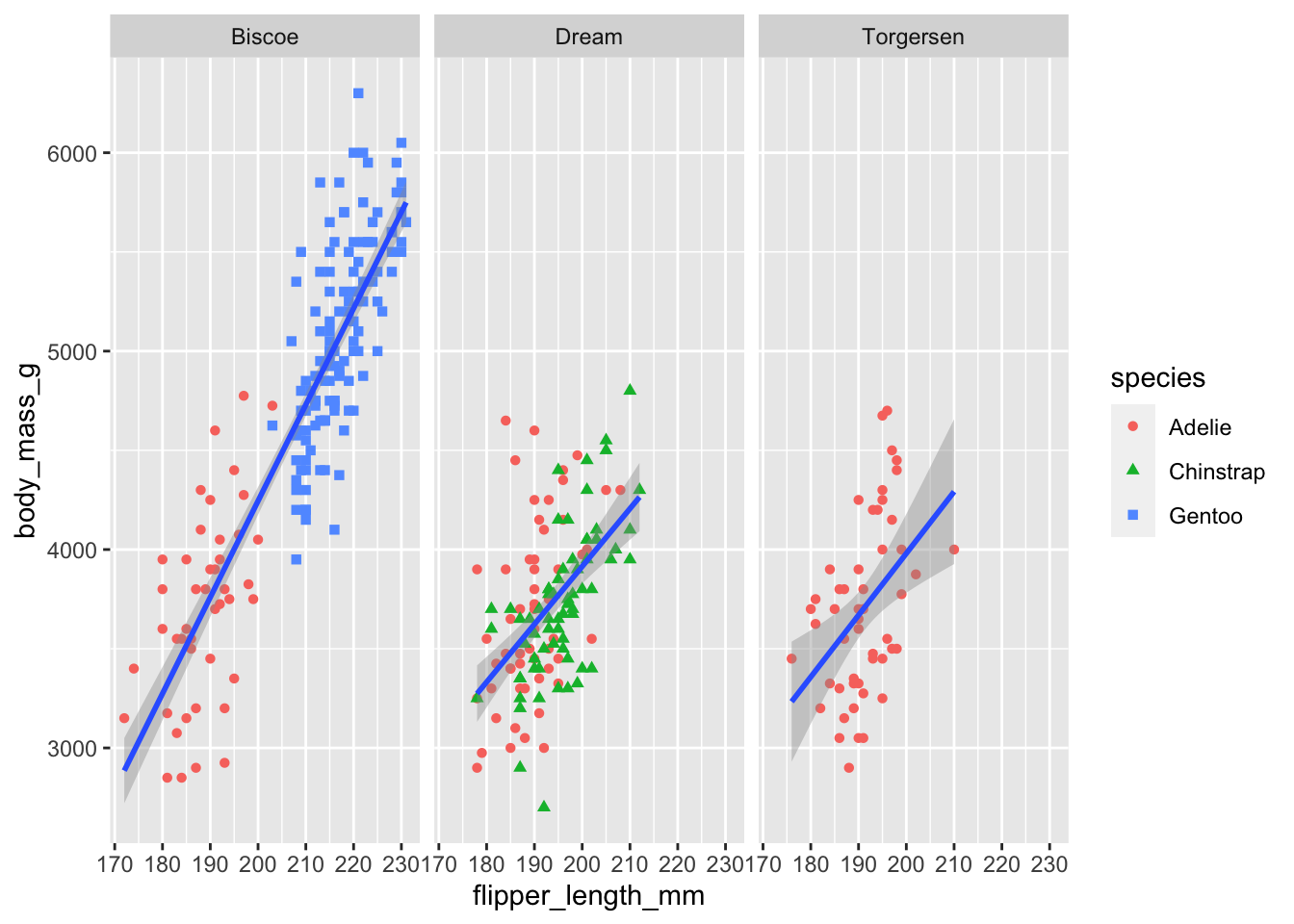

















 2938
2938

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









