







原文地址:http://www.datalearner.com/blog/1051509365677137
网络爬虫需要解决的一个重要的问题就是要针对某些需要用户名和密码访问的页面可以模拟用户自动登录。在这一篇博客中我们将介绍如何使用Chrome浏览器自带的抓包工具分析页面并模拟用户自动登录。我们会以CSDN的用户登录为例,讲述如何使用抓包工具获取登录方式并使用HttpClient工具模拟登陆访问。在之前的博客中我们已经讲述了如下内容:
Java爬虫入门简介(一) —— HttpClient请求及其详细使用
Java爬虫入门简介(二) —— Jsoup解析HTML页面
Java爬虫入门简介(三) —— HttpClient保存和使用Cookie登录
Java爬虫入门简介(四)——抓包工具的使用以及使用HttpClient模拟用户登录的访问(本篇博客)
抓包工具
抓包工具是指那些可以捕获网络传送的数据包的工具。网站的登录是客户端浏览器与服务器端的通信。很多时候,很多时候有价值的网页都需要用户登录之后才能浏览。而登录的过程一般是向服务器某个地址发送请求,并将用户名和密码等参数一同发送给服务器验证。这个地址通常都是我们在正常浏览网站的时候看不到的。因此需要抓包工具获取并分析。在这篇博客中我们将讲述使用Chrome自带的抓包工具进行分析。
首先我们需要使用浏览器访问:https://passport.csdn.net/account/login 页面。这是CSDN的登录页面,然后我们鼠标右击“登录”按钮,选择“检查(N)”,这样就打开了Chrome浏览器自带的开发者工具了。
 ](
http://www.datalearner.com/resources/blog_images/59c2b9a6-093f-40fa-999f-b1f2af489069.png)
](
http://www.datalearner.com/resources/blog_images/59c2b9a6-093f-40fa-999f-b1f2af489069.png)
在下面的工具栏中我们可以看到很多个标签页,依次是“Element” - “Console” - “Sources” - “Network” - “Performance” 等等。我们最常用的是前面四个,后面就不列举了。
Elements是展示页面的源代码的,就是这个网页里面HTML/CSS/JavaScript等源代码。鼠标点击到任何一个标签的时候会在右侧展示出几个子标签,如上图所示,在爬虫中我们最常用的是选择Event Listeners标签,因为通常我们需要根据页面的某个元素的事件寻找处理的JavaScript代码,并在代码中找到一些请求的结果。
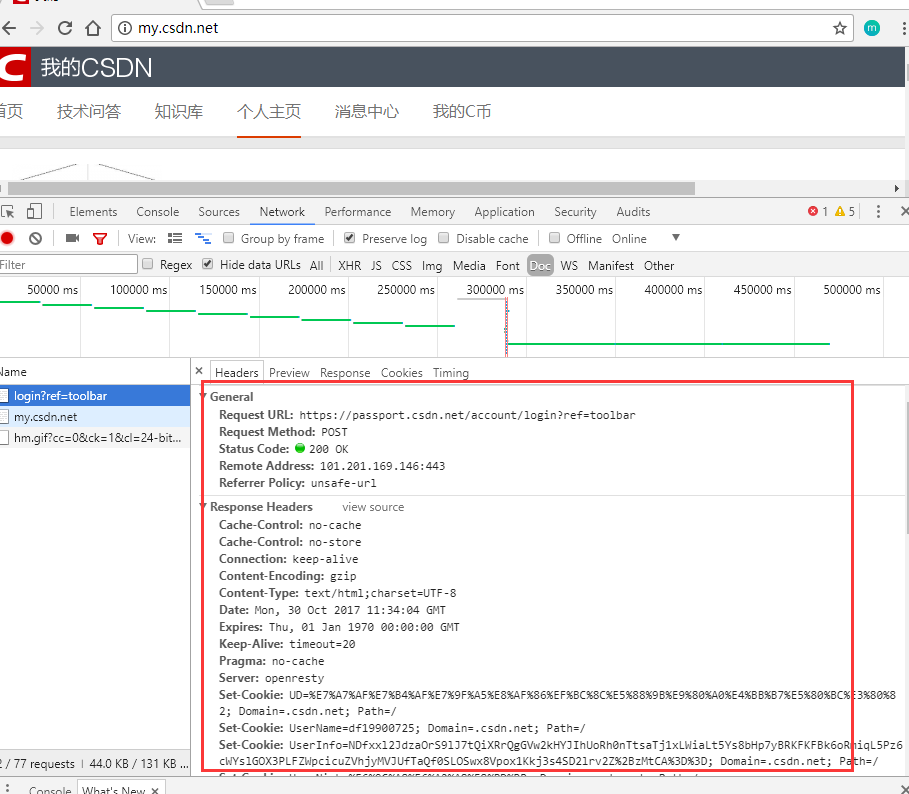
接下来我们打开Network标签,Network主要就是展示浏览器与服务器之间发送请求的页面了。注意到,在抓包的时候,如图所示,第一个红色方框里面我们通常要勾选Preserve log。因为页面一旦跳转,之前的页面与服务器之间传送的数据就会丢失,但我们需要分析这些数据,所以一般还是需要保存下来请求的日志。下面的方框主要包含几类请求的分类,如 XHR JS CSS Doc等。在爬虫中,我们一般只会用到请求Doc页面和XHR的内容,前者一般就是请求的一个完整页面,XHR一般是Ajax请求的结果。
CSDN登录分析
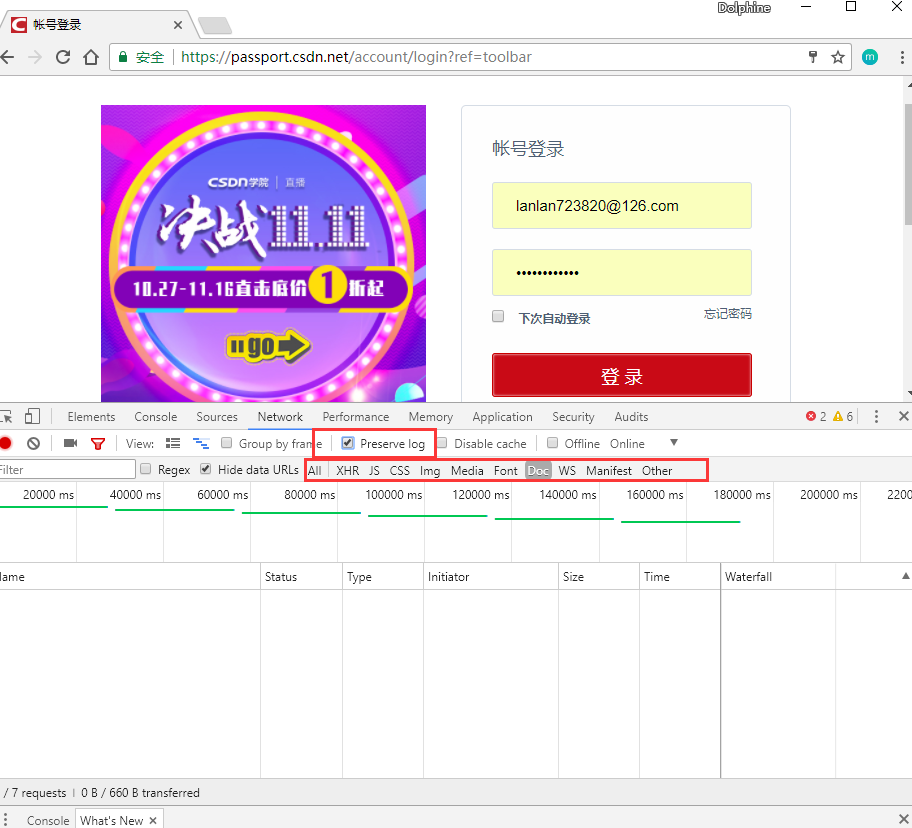
简单了解之后我们现在开始分析CSDN的登录。首先打开上述开发者工具,切换到Network标签,勾选Preserve log。然后点击登录。然后我们看到工具栏里面出现了很多的请求,我们先从Doc标签下看有没有我们需要的。我们看到有一个请求了”login”的地址。这一般就是登录请求的URL了。我们点开这个地址后看到右侧展开了如下内容:
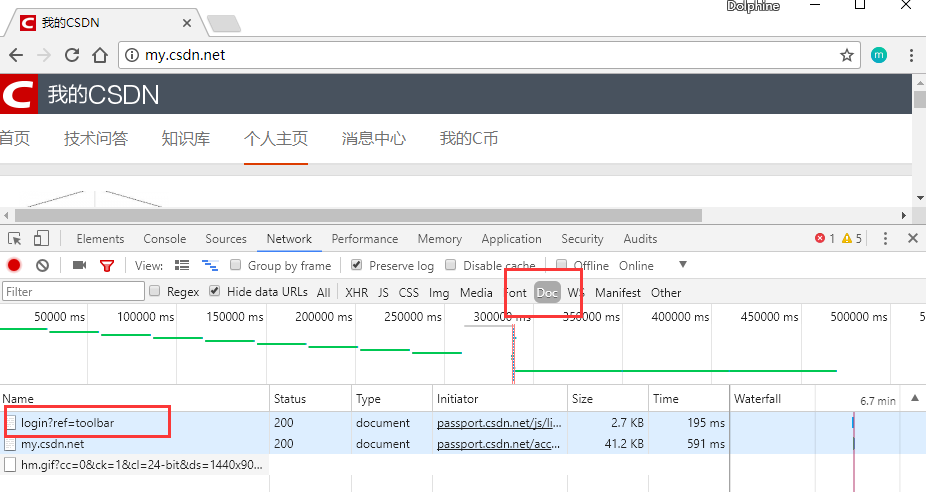
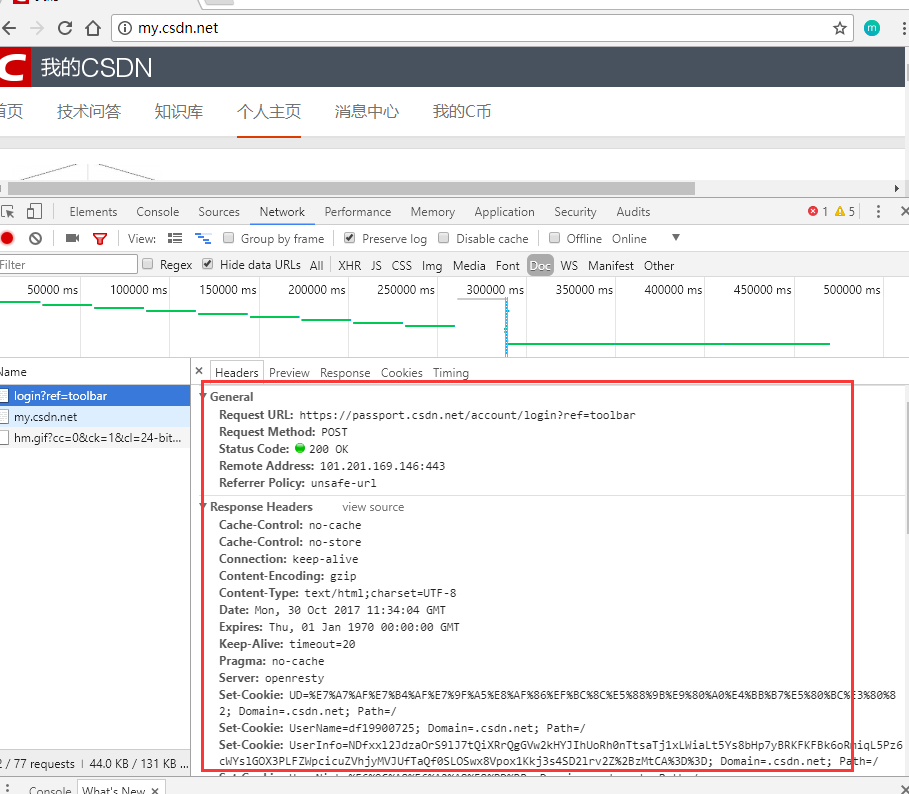
首先第一块是General,这里展示的是一般的请求情况。我们看到:
Request URL是请求的地址
Request Method是指请求的方式,这里是Post(当然登录一般都是Post)
Status Code:请求的情况,就是状态,200表示没有任何问题。
剩下的两个一般没啥意义不说了。
这里看到了请求,再把这个标签也拉到最底下我们看到:
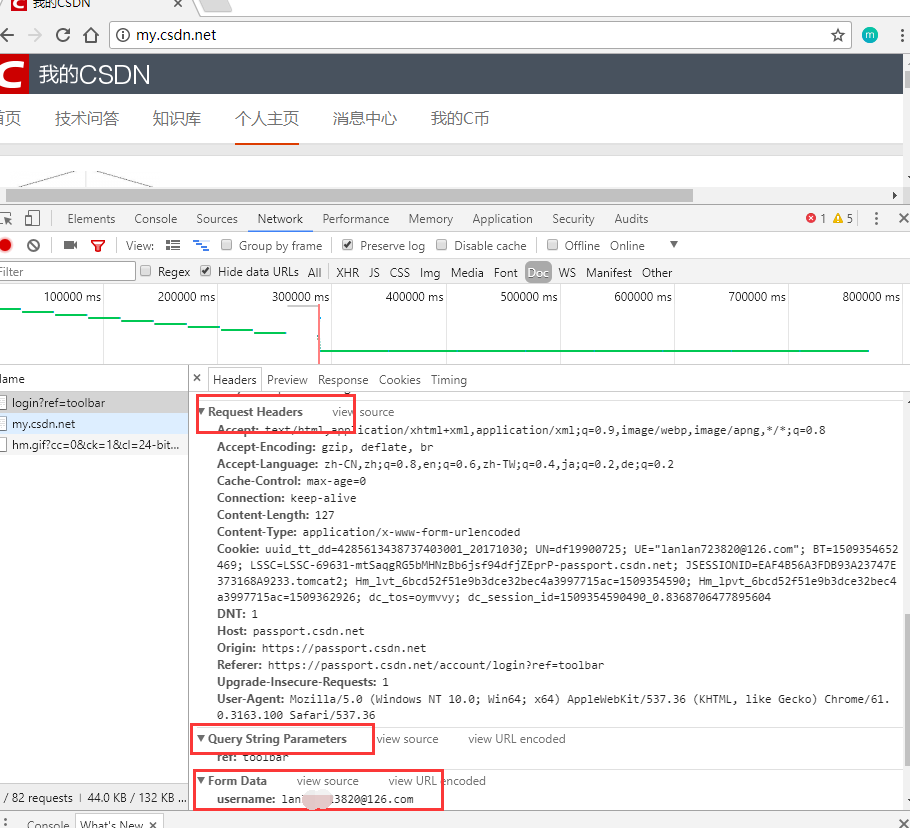
Request Headers这是我们请求的头部信息了。在之前的博客中我们已经说明了如何使用带头部的HttpClient请求了。一般情况下,头部都要写对,不然很容易出错。
Query String Parameters:这个是请求的参数,一般情况下请求的参数都在这里,和下面的Form Data其实是一个意思。只不过一个是通过地址参数,一个是通过表单提交的,这些都是我们需要获得的参数提交。我们把这个标签看完整,如下图所示:
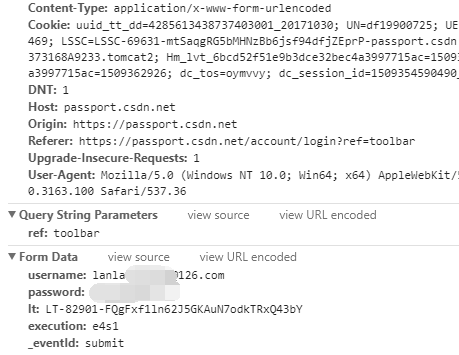
我们看到在登录CSDN的时候其实我们是发送了好多参数,并不是只有用户名和密码。一般情况下都会有些额外的标识符表明用户是正常访问他们的页面并提交验证请求的。这里的参数分别如下:
ref: toobar这个是表明ref的地址,不用管。不写也是可以的(因为我是退出后点击登录,所以有这个,你们直接输入上面的地址应该是没有的)。
username:这是用户名,我这里打码了,是我的邮箱
password:这个是密码。通常密码很有可能是加密的,那就需要我们写个加密程序,一般都是利用页面的一个公钥来加密,但是CSDN真是的。。太懒了。
lt/execution/_eventId:这个是页面的一些代码,用来注明是用户访问了这个页面才登录的。后面我们会描述怎么找这些参数。
寻找登录参数
一般来说上面这三个参数有两种方式生成,一种是直接在页面添加几个隐藏的元素,把这些值放到这些元素中,然后直接通过JavaScript取出来,并连同用户名和密码发送。还有种方式也是类似的,但是JavaScript处理的时候会做一些简单的运算,比如做个转换啥的,这样也增加了爬虫的困难。后一种方式可以通过对JavaScript添加断点寻找。也很简单,就是通过上面右键单击登录按钮,然后找到这个按钮监听的事件对应的JavaScript,然后在里面追踪即可。以后有机会我们举个例子。这里很简单,我们就直接能在页面找到。我们在Elements的标签下看到如下的内容:

这里也就是说我们可以直接通过Jsoup解析这个页面就能得到这些参数了。
使用HttpClient登录
通过上面的分析我们可以看到登录CSDN的过程应该是:
1、访问https://passport.csdn.net/account/login 页面
2、解析上述页面,并获取页面的参数lt/execution/_eventId
3、同用户名和密码一起,将这些参数发送给服务器验证。
那么我们把核心代码放到下面(注意,这里CSDN都是用Https访问的,所以不能像之前那样直接使用HttpClient,要使用SSL的访问方式)。核心代码如下:
1、初始化一个可以访问Https的HttpClient
(这个有机会我们再说,这里按照下面的方式初始化即可,我们使用的是免证书验证的方式)
X509TrustManager xtm = new HFUT509TrustManager();
SSLContext sslcontext = SSLContexts.custom().loadTrustMaterial(new TrustSelfSignedStrategy()).build();
sslcontext.init(new KeyManager[0], new TrustManager[] {xtm }, new SecureRandom());
sslcontext.init(null, new X509TrustManager[]{xtm}, new SecureRandom());
//注意,这个右边是Lambda表达式,我们用的是jdk1.8
SSLConnectionSocketFactory factory = new SSLConnectionSocketFactory(sslcontext, (s, sslSession) -> true);
Registry r = RegistryBuilder. create().register("https", factory).build();
PoolingHttpClientConnectionManager connPool = new PoolingHttpClientConnectionManager(r);
connPool.setMaxTotal(200);
connPool.setDefaultMaxPerRoute(20);
CloseableHttpClient httpClient = HttpClients.custom().
setConnectionManagerShared(true).
setConnectionManager(connPool).
setSSLSocketFactory(factory).build();2、访问登录页面获取参数
HFUTRequest hfutRequest = new HFUTRequest();
hfutRequest.getSSLClient();
String loginPage = "https://passport.csdn.net/account/login";
String loginPageContent = hfutRequest.getHTMLContentByHttpGetMethod(loginPage);
Document document = Jsoup.parse(loginPageContent);
//一般我们直接使用上面的登陆地址就好,CSDN在他的form表单中给出了请求地址,这里是解析的表单的action值获取地址的,大家可以之间用上面抓包结果的地址
String loginRequestURL = document.select("form#fm1").attr("action");
loginRequestURL = "https://passport.csdn.net"+loginRequestURL+"";
//获取三个参数
String lt = document.select("input[name=lt]").attr("value");
String execution = document.select("input[name=execution]").attr("value");
String _eventId = document.select("input[name=_eventId]").attr("value");3、请求登录验证
List<NameValuePair> nameValuePairList = Lists.newArrayList();
nameValuePairList.add(new BasicNameValuePair("username", username));
nameValuePairList.add(new BasicNameValuePair("password", password));
nameValuePairList.add(new BasicNameValuePair("lt", lt));
nameValuePairList.add(new BasicNameValuePair("execution", execution));
nameValuePairList.add(new BasicNameValuePair("_eventId", _eventId));
List<Header> headerList = Lists.newArrayList();
headerList.add(new BasicHeader(HttpHeaders.ACCEPT,"text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8"));
headerList.add(new BasicHeader(HttpHeaders.ACCEPT_ENCODING, "gzip, deflate, br"));
headerList.add(new BasicHeader(HttpHeaders.ACCEPT_LANGUAGE, "zh-CN,zh;q=0.8,en;q=0.6,zh-TW;q=0.4,ja;q=0.2,de;q=0.2"));
headerList.add(new BasicHeader(HttpHeaders.CACHE_CONTROL, "max-age=0"));
headerList.add(new BasicHeader(HttpHeaders.CONNECTION, "keep-alive"));
headerList.add(new BasicHeader(HttpHeaders.CONTENT_TYPE, "application/x-www-form-urlencoded"));
headerList.add(new BasicHeader("DNT","1"));
headerList.add(new BasicHeader(HttpHeaders.HOST, "passport.csdn.net"));
headerList.add(new BasicHeader("Origin", "https://passport.csdn.net"));
headerList.add(new BasicHeader(HttpHeaders.REFERER, "https://passport.csdn.net/account/login?from=http://my.csdn.net/my/mycsdn"));
headerList.add(new BasicHeader("Upgrade-Insecure-Requests","1"));
headerList.add(new BasicHeader(HttpHeaders.USER_AGENT, "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/61.0.3163.100 Safari/537.36"));
HttpPost httpPost = new HttpPost(loginRequestURL);
for( Header header : headerList ){
httpPost.addHeader(header);
}
String content = EntityUtils.toString(httpClient.execute(httpPost).getEntity());
content = hfutRequest.getHTMLContentByHttpPostMethod(loginRequestURL, nameValuePairList);
System.out.println(content);最后我们看到了如下的结果证明我们获取是对的。
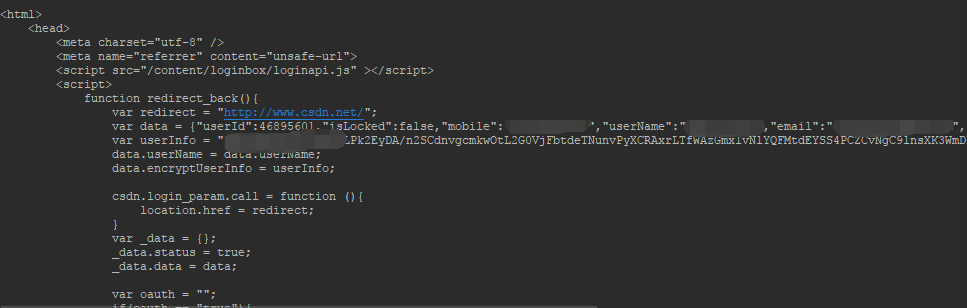














 786
786











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









