







描述:
Given a collection of numbers that might contain duplicates, return all possible unique permutations.
For example,
[1,1,2] have the following unique permutations:
[1,1,2], [1,2,1], and [2,1,1].
就该题来说,它是Permutation的进化版本,即该排列可能具有相同的元素。就Permutation这道题来说,假如第一次做的话
也不太好做,就是每次交换begin和后面的元素,然后在该位置的基础上在递归地调用排列方法并使得begin=begin+1,直
至begin=nums.length-1为止,然后将元素存储起来,详细步骤见代码。而Permutation II涉及到涉及到重复元素,在Permutation
的基础上进行修改的话,需要将将重复元素的这一段给过滤掉,具体的实现是用到
if(i!=begin&&arr[i]==arr[i-1])//当相邻元素相同时,仅能消除部分重复运算
{
continue;
}但是,即便这样,并不能过滤到所有的多余条件,比如说当当前所在的字符和前面的相同时,下一次执行到这里时i是和begin
相同的,所以会多算i==begin这一种情况。那怎么办呢?还有一种补救的方法(不完美,而且在leetcode上面运行程序会超时)
就是用HashSet来存储符合条件的list。下面直接上代码:
public class StringPermutation
{
public void strPermute(Set<String>set,char arr[],int begin)
{
if(begin==arr.length-1)
{
set.add(new String(arr));
}
for(int i=begin;i<arr.length;i++)
{
if(i!=begin&&arr[i]==arr[i-1])//当相邻元素相同时,仅能消除部分重复运算
{
continue;
}
swap(arr,begin,i);
strPermute(set, arr, begin+1);
swap(arr,begin,i);
}
}
public void swap(char arr[],int index1,int index2)
{
char temp=arr[index1];
arr[index1]=arr[index2];
arr[index2]=temp;
}
public static void main(String[] args)
{
// TODO Auto-generated method stub
StringPermutation stringPermutation=new StringPermutation();
String string="303223";
Set<String>set=new HashSet<String>();
stringPermutation.strPermute(set, string.toCharArray(), 0);
List<String>list=new ArrayList<String>(set);
Collections.sort(list);//After sort,it's convinent to find the difference between the elements
Iterator<String>iterator=list.iterator();
while(iterator.hasNext())
System.out.println(iterator.next());
}
}
而不用HashSet来处理这些重复元素呢,是这样的,代码如下:
public class StringPermutationII
{
public void strPermute(List<String> list, char arr[], int begin)
{
if (begin == arr.length - 1)
{
list.add(new String(arr));
}
for (int i = begin; i < arr.length; i++)
{
if (i != begin && arr[i] == arr[i - 1])
{
continue;
}
swap(arr, begin, i);
strPermute(list, arr, begin + 1);
swap(arr, begin, i);
}
}
public void swap(char arr[], int index1, int index2)
{
char temp = arr[index1];
arr[index1] = arr[index2];
arr[index2] = temp;
}
public static void main(String[] args)
{
// TODO Auto-generated method stub
StringPermutationII stringPermutation = new StringPermutationII();
String string = "303223";
List<String> list = new ArrayList<String>();
stringPermutation.strPermute(list, string.toCharArray(), 0);
Collections.sort(list);
Iterator<String> iterator = list.iterator();
while (iterator.hasNext())
System.out.println(iterator.next());
}
}
但list是对象啊,对象添加的不是对象的引用么?不同的对象的句柄又怎么可能相同呢?这就怪了,为了解开这个谜团,我专门写了两段小程序,来测试下set.add(Object obj),到底添加的是什么?
public class HashSetTest
{
public static void main(String[] args)
{
// TODO Auto-generated method stub
//Test String
// Set<String>set=new HashSet<String>();
// String string="hello";
// int count=100;
// for(int i=0;i<count;i++)
// set.add(string);
// for(String str:set)
// System.out.println(str);
Set<List<String>>set=new HashSet<List<String>>();
String string="hello";
int count=100;
for(int i=0;i<count;i++)
{
List<String>list=new ArrayList<String>();
list.add(new String("hello"));
set.add(list);
}
for(List<String> list:set)
System.out.println(list);
}
}输出分别为:
hello
和
[hello]
可见即使是对象也是可以用HashSet去重的,真的是这样么?再上一段代码:
class User{
String userName;
public User(String userName)
{
this.userName=userName;
}
// public int hashCode()
// {
// return this.userName.hashCode();
// }
// public boolean equals(Object obj)
// {
// if((obj instanceof User)==false)
// return false;
// if(this==obj)
// return true;
// return ((User)obj).userName.equals(this.userName);
// }
}
public class HashSetTestII
{
public static void main(String[] args)
{
// TODO Auto-generated method stub
Set<User>set=new HashSet<User>();
int count=10;
for(int i=0;i<count;i++)
{
set.add(new User(new String("Sting")));
}
for(User user:set)
System.out.println(user.userName);
}
}
输出结果:
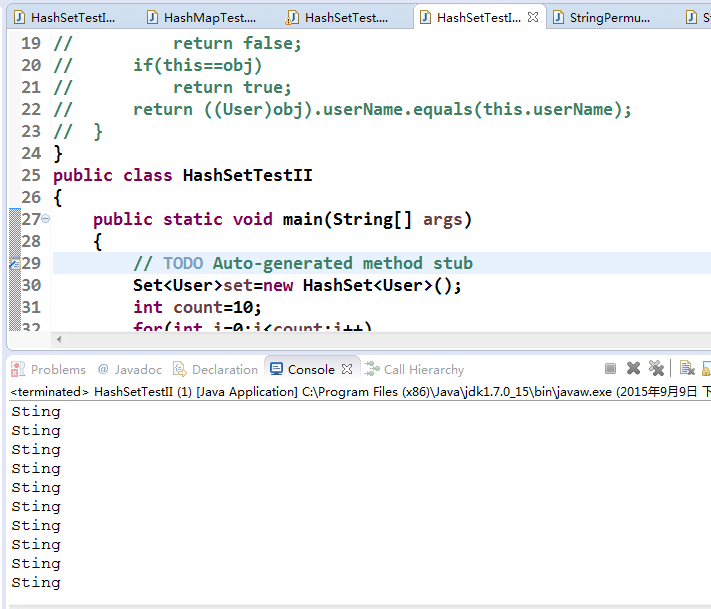
不是这样啊,同样是对象为啥HashSet就不能对User去重呢,把注释去掉会怎样呢?
去掉注释后效果就变成

这下真相大白了吧,HashSet能不能对对象元素去重得看你是如何比较这个对象的,如果你重写了基类的hashCode()和equals()方法,
你就可以设计对象相等的标准,比如本题中userName相同就代表两个对象是相同的,就不可以放在同一个HashSet中。那String和List是
如何做到相同值的元素可以不插入一个HashSet中呢?很显然就像我们做的,这两个类重写了基类的那两个方法,该两个类进行比较时
String比较的是String的字符串的值,而List比较的是list中的每一个元素的值是否相等,有一个不像等就代表对象不等。
但是插入的时候对元素的比较是非常消耗时间的,所以才导致leetcode出现TLE的错误,也就是这种方法来去重成本太大了,而是可以
用更好的方法来解决该问题。
其实,HashSet添加的确实是对象的句柄,但是比较对象是否相等的时候是不是就是比较Object obj1,Object obj2中obj1==obj2呢,其实
,这得看该对象的hashCode(Obj obj)和equals(Obj obj)方法是否被覆盖,没有被覆盖的话确实比较的是对象的句柄,被覆盖的话比较的规则
就是hashCode(Obj obj)和equals(Obj obj)方法里所写的内容了。















 341
341

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









