 Node.js流实战
Node.js流实战




 本文探讨了Node.js中流的工作原理,通过对比流式传输和一次性读取大文件的方法,展示了流在处理大量数据时的优势。文章构建了一个使用Koa.js和Knex的简单API,比较了流式传输和内存读取的性能。
本文探讨了Node.js中流的工作原理,通过对比流式传输和一次性读取大文件的方法,展示了流在处理大量数据时的优势。文章构建了一个使用Koa.js和Knex的简单API,比较了流式传输和内存读取的性能。
node.js运行js
有没有想过Node.js中的流如何工作? 我有 到目前为止,我知道在处理大文件时使用流肯定会减少服务器上的内存使用量。 与其将整个文件读入内存,我们不如将其分块地传输给任何请求它的人,并在需要时将转换应用于该流。 这是巨大的好处,因为它可以避免垂直缩放。 处理文件是常见的任务,但不像与数据库进行交互那样普遍,这将成为我现在的重点。 我将用2个端点构建简单的API。 两者都将从Postgres DB返回大量记录。 一个端点将数据流传输到客户端,而另一个端点将整个数据读入内存并返回一个块。
如果我在Node.js环境中工作,则在其前面通常带有Express.js框架以及Sequelize orm。 对于这个实验,我决定尝试一些不同的方法,然后选择Koa.js框架和Knex orm。 开始吧。
我将首先设置项目:
# let's name our project "streamer"
mkdir streamer && cd streamer
# I'm happy with npm defaults for this project so:
npm init -y现在是时候添加应用程序依赖项了。 您可以在此处查看所有软件包。 要设置我的开发环境,我将使用Docker和docker-compose。 让我们看看Dockerfile.dev的样子:
FROM node: 12.16 . 1
# create new working directory
WORKDIR /src
# expecting to receive API_PORT as argument
ARG API_PORT
# make sure to run latest version of npm
RUN npm i npm@latest -g
# fetch dependencies on a separate layer first as it's not changing that often,
# will be cached and speed up the image build process
COPY ./package.json ./package-lock.json ./
RUN npm i
# copy the rest of the source files into working directory
COPY . .
EXPOSE ${API_PORT}
CMD [ "npm" , "run" , "start:dev" ]很标准吧? 现在docker-compose.yml添加数据库依赖关系并引导整个过程:
version: "3.7"
volumes:
streamervolume:
name: streamer-volume
networks:
streamernetwork:
name: streamer-network
services:
pg:
image: postgres:12.0
restart: on-failure
env_file:
- .env
ports:
- "${POSTGRES_PORT}:${POSTGRES_PORT}"
volumes:
- streamervolume: /var/lib/postgresql/data
networks:
- streamernetwork
streamer_api:
build:
context: .
dockerfile: Dockerfile.dev
args:
API_PORT: ${API_PORT}
restart: on-failure
depends_on:
- pg
volumes:
- ./:/src
ports:
- "${API_PORT}:${API_PORT}"
networks:
- streamernetwork
env_file:
- .env现在该环境已经准备就绪,我将继续应用程序逻辑本身。 让我们看一下app.js :
// src/app.js
require ( 'dotenv' ).config();
const Koa = require ( 'koa' );
const errorHandler = require ( './middleware/errorHandler' );
const router = require ( './routes' );
const app = new Koa();
app
.use(errorHandler)
.use(router.routes())
.use(router.allowedMethods());
module .exports = app;我首先加载.env vars,导入Koa,我的自定义错误处理中间件和路由器。 错误处理中间件如下所示:
// src/middleware/errorHandler.js
module .exports = async (ctx, next) => {
try {
await next();
} catch (err) {
console .error(err);
ctx.status = err.status || 500 ;
ctx.body = {
msg : err.message || 'Oops. Something went wrong. Please try again later' ,
};
}
}根据文档,为了捕获所有异常,必须首先在Koa应用中添加错误处理中间件。 下一站是路由器:
// src/routes/index.js
const Router = require ( '@koa/router' );
const router = new Router();
router.get( '/nostream' , require ( './users/nostream' ));
router.get( '/stream' , require ( './users/stream' ));
module .exports = router; 值得一提的是,在app.js中,我使用router.allowedMethods()中间件,该中间件处理405 Method Not Allowed不受支持的方法。 接下来让我们看一下处理程序。 nostream:
// src/routes/users/nostream/index.js
const db = require ( '../../../services/db' );
module .exports = async (ctx) => {
try {
const users = await db.select( '*' ).from( 'users' );
ctx.status = 200 ;
ctx.body = users;
} catch (err) {
ctx.throw( 500 , err);
}
};可以肯定的是,您想知道该数据库的外观如何:
// src/services/db.js
const config = require ( './config' );
const knex = require ( 'knex' )({
client : 'pg' ,
connection : {
host : config.dbHost,
user : config.dbUser,
password : config.dbPwd,
database : config.db,
},
});
module .exports = knex;config只是一个简单的对象常量,它公开了一些环境变量。 你可以在这里看到它。 我需要knex,建立数据库连接并导出它的实例。 由于所有节点模块都是单例,因此无论我需要多少次此程序包,初始化都只会执行一次。 nostream处理程序中的其他所有内容都非常简单。 请参阅Koa或Knex文档以获取更多详细信息。 接下来让我们看一下流处理程序:
// src/routes/users/stream/index.js
const Stringify = require ( 'streaming-json-stringify' )
const db = require ( '../../../services/db' );
module .exports = async (ctx) => {
ctx.type = 'application/json; charset=utf-8' ;
ctx.set( 'Connection' , 'keep-alive' );
try {
const stream = db
.select( '*' )
.from( 'users' )
.stream();
ctx.status = 200 ;
await pipe(stream, ctx.res, { end : false });
} catch (err) {
ctx.throw( 500 , err);
}
};
function pipe ( from, to, options ) {
return new Promise ( ( resolve, reject ) => {
from
.pipe(Stringify())
.pipe(to, options);
from .on( 'error' , reject);
from .on( 'end' , resolve);
})
} 在这里,我对查询调用.stream()以获取流实例。 然后,我将此查询流传递给客户端。 为了做到这一点,我有一个pipe函数返回一个Promise,我们不会立即退出处理程序,而是要等到流完成或发生错误为止。 我在这里添加了stringify包,因为响应(可写流)期望输入类型字符串或Buffer的实例,并且DB流使用对象类型进行操作。
顺便说一下,所有ctx.throw都将被我们之前创建的errorHandler中间件捕获。 现在,在开始测试服务器之前,我需要一些数据库中的数据。 由于我已经在本地安装了Knex,因此我需要一个配置文件来运行迁移,种子等:
./node_modules/.bin/knex init这将生成knexfile.js 。 我已对其进行了稍微更改,以使用我的环境变量。 你可以在这里看到它。 现在,我将生成迁移:
./node_modules/.bin/knex migrate:make users 这将在migrations/{timestapm}_users.js创建一个迁移文件。您可以在此处进行查看 。 在运行它之前,请启动应用程序:
docker-compose up --build现在,由于应用程序已启动并正在运行,因此该运行迁移了:
POSTGRES_HOST=localhost npm run migrate:up我在这里指定了postgres主机,因为我是从pg主机名下在docker环境中运行的db主机从主机迁移来运行的,如果不指定它,将从env vars中使用pg名,这将导致连接尝试失败。
现在,我需要在users表中有一些记录才能使用我的API。 Knex cli可以简化此过程。 它具有生成种子文件的命令:
./node_modules/.bin/knex seed:make create_users这将在种子目录中生成一个种子文件。 您可以在这里看到我的操作。 如果您在运行它时遇到问题,请尝试减少尝试创建的记录数量。 目前,它将尝试创建60k条记录。 让我们运行它:
POSTGRES_HOST=localhost npm run db:seed好的,所有这些都准备就绪,我现在可以测试两个端点并查看它们的性能如何。 让我们从nostream端点开始:
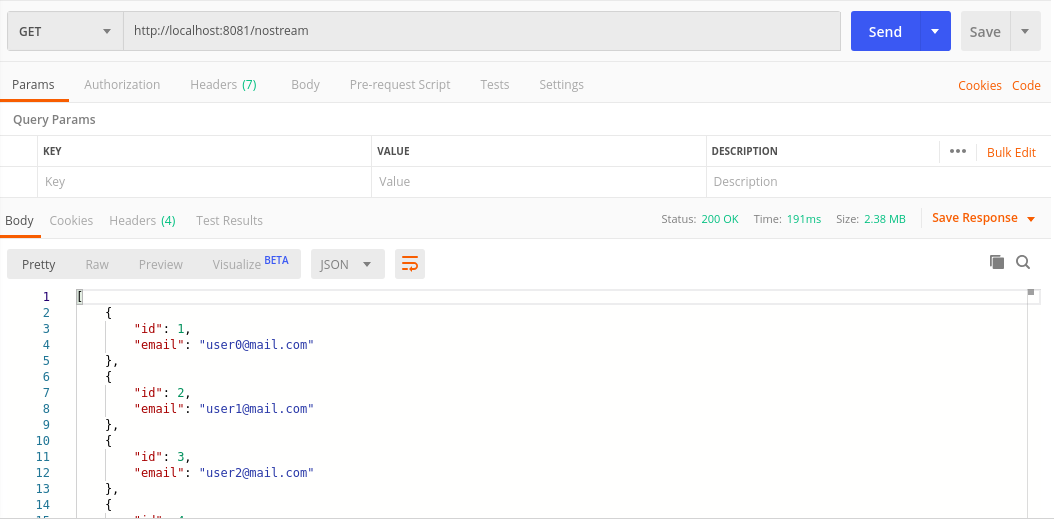
现在流端点:
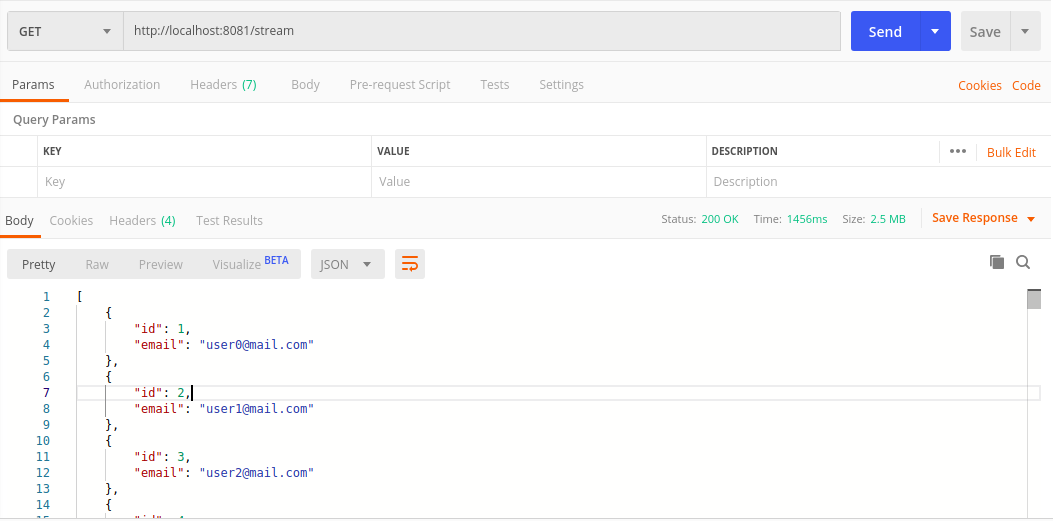
因此,流式传输可能不占用大量内存,但检索所有数据要花费更长的时间(在这种情况下为60k用户)。 在发送/处理大量数据时,这当然可以工作,并且非常适合我们必须处理大量数据集的文件处理或BI。 但是,当涉及到常见任务时,例如说要每页检索10-100条记录的管理面板,最有可能不是最适合的流式传输。
不仅因为要花费更多的时间,还因为代码复杂,因为需要更多代码才能实现相同的输出。 一切都归结为一句老话: “为工作选择合适的工具”。 希望您学到了一些有用的东西。 您可以在此处找到整个项目。
翻译自: https://hackernoon.com/nodejs-streams-in-action-m33g24qc
node.js运行js


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









