






前言
传统数据库遇到的问题,数据量很大的时候无法存储;没有很好的备份机制;数据达到一定数量开始缓慢,很大的话基本无法支撑;因此我们需要探究更加合适的数据库来支撑我们的业务。
HBase
什么是HBase
Hbase(Hadoop Database)是建立在HDFS之上的分布式、面向列的NoSQL的数据库系统。
HBase特点
优点:
-
- 海量存储:适合存储PB级别的海量数据,采用廉价PC存储的情况下,能在几十到百毫秒内返回数据。
- 列式存储(半结构化或非结构化数据):即列族存储,对于数据结构字段不够确定或杂乱无章非常难按一个概念去进行抽取的数据适合用。
- 极易扩展:一个是基于上层处理能力(RegionServer)的扩展,提升Hbsae服务更多Region的能力。一个是基于存储的扩展(HDFS),通过横向添加Datanode的机器,进行存储层扩容,提升Hbase的数据存储能力和提升后端存储的读写能力。
- 高并发:采用廉价PC,能获得高并发、低延迟、高性能的服务。
- 稀疏:列族中,可以指定任意多的列,列数据为空不会占用存储空间的,也提高了读性能。
- 多版本号数据:依据Row key和Column key定位到的Value能够有随意数量的版本号值,版本号默认是单元格插入时的时间戳。
- 适用于插入比查询操作更频繁的情况:比如,对于历史记录表和日志文件。
- 数据类型单一:HBase中数据类型都是字符串。
- 无模式:每一行都有一个可以排序的rowKey和任意多的截然不同的列。
缺点:
-
- 单一RowKey固有的局限性决定了它不可能有效地支持多条件查询。
- 不适合于大范围扫描查询。
- 不直接支持 SQL 的语句查询。
- 仅支持行级(单行)事务(HBase的事务是行级事务,可以保证行级数据的原子性、一致性、隔离性以及持久性)。
- HBase的配置非常麻烦,最低的限度都需要包括Zookeeper ensemble、primary HMaster、secondary HMaster、RegionServers、active NameNode、standby NameNode、HDFS quorum journal manager及DataNodes。使用HBase需求大量的专业知识——甚至是最简单的监视。RegionServer存在单点故障,当它发生故障时,一个新的RegionServer必须被选举出,而在可以投入之前,必须重新完成write-ahead日志里的内容,即故障恢复较慢,WAL回放较慢。HBase的API非常笨拙并且具有太强的Java特色,非Java客户端只能委托给Thrit或者REST。
HBase的体系结构

值得参考的网址:https://www.cnblogs.com/swordfall/p/8737328.html
HBase使用场景
Hbase是一个通过廉价PC机器集群来存储海量数据的分布式数据库解决方案。它比较适合的场景概括如下:
-
- 是巨量大(百T、PB级别)
- 查询简单(基于rowkey或者rowkey范围查询)
- 不涉及到复杂的关联
有几个典型的场景特别适合使用Hbase来存储:
-
- 海量订单流水数据(长久保存)
- 交易记录
- 数据库历史数据
如何使用HBase
三种模式:单机模式,伪分布式模式,分布式模式
一般生产环境用的是分布式模式,如果是学习的话,可以用单机模式和伪分布式模式。
安装zookeeper
https://blog.csdn.net/weixin_41558061/article/details/80597174
全分布式模式的Hbase集群需要运行ZooKeeper实例,默认情况下HBase自身维护着一组默认的ZooKeeper实例,可以自己配置实例,这样Hbase会更加健壮
注意:使用默认的实例时,HBase将自动启动或停止ZooKeeper,当使用独立的ZooKeeper实例时,需要用户手动启动和停止ZooKeeper实例
安装Hadoop
安装HBase
https://www.cnblogs.com/wishyouhappy/p/3707904.html
hbase_home/conf/hbase-site.xml文件中的configuration加入:
1 <property> 2 <name>hbase.rootdir</name> 3 <value>hdfs://hadoop0:9000/hbase</value> 4 </property> 5 <property> 6 <name>hbase.cluster.distributed</name> 7 <value>true</value> 8 </property> 9 <property> 10 <name>hbase.zookeeper.quorum</name> 11 <value>hadoop0</value> 12 </property> 13 <property> 14 <name>dfs.replication</name> //指定Hlog和Hfile副本数,此参数值并不能大于HDFS节点数,如果datanode只有一台则此参数应该设置为1 15 <value>1</value> 16 </property>
注意事项:
1.关于Hadoop
1. 目前的HBase只能依赖特定的Hadoop版本,HBae和Hadoop之间的RPC是版本话的,需要调用方与被调用方相互匹配,细微的差异可能导致通信失败
2. 由于Hadoop依赖于Hadoop,它要求Hadoop的JAR必须部署在HBase的lib目录下。HBase使用的Hadoop版本必须与底层Hadoop集群上使用的Hadoop版本一直,因而使用Hadoop集群上运行的JAR替换HBase的lib目录中依赖的Hadoop的JAR可以避免版本不匹配的问题
3. 集群中所有的节点都要更新为一样的JAR,否则版本不匹配问题可能造成集群无法启动或者假死现象
2.关于HBase Shell
1.如果使用的分布式模式,那么在关闭Hadoop之前一定要确认HBase已经被正常关闭了
2. 使用stop-hbase.sh关闭HBase时,控制台会打印关于停止的信息,会周期性的打印 ".",关闭脚本需要几分钟完成,如果集群中机器数量很多,那么执行时间会更长
介绍比较全面的网址:https://www.cnblogs.com/JamesXiao/p/6202372.html
了解完HBase后,可带着问题看这一篇文章:https://blog.csdn.net/nosqlnotes/article/details/79647096
MongoDB
什么是MongoDB
MongoDB是一个介于关系数据库和非关系数据库之间,基于分布式文件存储,由C 语言编写的数据库。
MongoDB特点
优点
高性能、易部署、易使用、高写负载,存储数据非常方便。
-
-
-
- 面向文档存储(类JSON数据模式简单而强大)
-
-
-
-
-
-
动态查询
-
全索引支持,扩展到内部对象和内嵌数组
-
查询记录分析
-
快速,就地更新
-
高效存储二进制大对象 (比如照片和视频)
-
复制和故障切换支持
-
Auto- Sharding自动分片支持云级扩展性
- 支持RUBY,PYTHON,JAVA,C ,PHP,C#等多种语言。
-
MapReduce 支持复杂聚合
-
商业支持,培训和咨询
-
-
-
缺点
-
-
-
- 不支持事务(进行开发时需要注意,哪些功能需要使用数据库提供的事务支持)
- MongoDB占用空间过大 (不过这个确定对于目前快速下跌的硬盘价格来说,也不算什么缺点了)
-
2.1、空间的预分配:
当MongoDB的空间不足时它就会申请生成一大块硬盘空间,而且申请的量都是有64M、128M、256M来增加直到2G为单个文件的较大体积,并且随着数量叠增,可以在数据目录下看到整块生成而且不断递增的文件。 -
2.2、删除记录不释放空间:
这很容易理解,为避免记录删除后的数据的大规模挪动,原记录空间不删除,只标记“已删除”即可,以后还可以重复利用。
-
- MongoDB没有如MySQL那样成熟的维护工具,这对于开发和IT运营都是个值得注意的地方
- 在32位系统上,不支持大于2.5G的数据(很多操作系统都已经抛弃了32位版本,所以这个也算不上什么缺点了,3.4版本已经放弃支持32 位 x86平台)
-
-
MongoDB原理
mongodb在电脑磁盘文件系统之上,又包装了自己的一套文件系统---gridfs,里面存储的是一个一个的json二进制对象,也就是Bson。

存储容量需求超出单机磁盘容量时,用分片技术去解决
详情可参考网址:
https://www.cnblogs.com/wangshouchang/p/6920390.html
https://blog.csdn.net/justlpf/article/details/80392944
场景适用
适用场景
● 网站数据:Mongo 非常适合实时的插入,更新与查询,并具备网站实时数据存储所需的复制及高度伸缩性。● 缓存:由于性能很高,Mongo 也适合作为信息基础设施的缓存层。在系统重启之后,由Mongo 搭建的持久化缓存层可以避免下层的数据源过载。● 大尺寸、低价值的数据:使用传统的关系型数据库存储一些数据时可能会比较昂贵,在此之前,很多时候程序员往往会选择传统的文件进行存储。● 高伸缩性的场景:Mongo 非常适合由数十或数百台服务器组成的数据库,Mongo 的路线图中已经包含对MapReduce 引擎的内置支持。● 用于对象及JSON 数据的存储:Mongo 的BSON 数据格式非常适合文档化格式的存储及查询。
不适场景
● 高度事务性的系统:例如,银行或会计系统。传统的关系型数据库目前还是更适用于需要大量原子性复杂事务的应用程序。● 传统的商业智能应用:针对特定问题的BI 数据库会产生高度优化的查询方式。对于此类应用,数据仓库可能是更合适的选择。● 需要SQL 的问题。
如何使用MongoDB
linux平台安装MongoDB
http://www.runoob.com/mongodb/mongodb-linux-install.html
spring中集成MongoDB,通过引入MongoDB的maven依赖,引入约束mongo来配置spring托管
xmlns:mongo="http://www.springframework.org/schema/data/mongo" xsi:schemaLocation=" http://www.springframework.org/schema/data/mongo http://www.springframework.org/schema/data/mongo/spring-mongo-1.0.xsd"
配置连接池
<!--连接池配置-->
<mongo:mongo host="${mongo.host}" port="${mongo.port}">
<mongo:options connections-per-host="${mongo.options.connections-per-host}"
threads-allowed-to-block-for-connection-multiplier="${mongo.options.threads-allowed-to-block-for-connection-multiplier}"
connect-timeout="${mongo.options.connect-timeout}"
max-wait-time="${mongo.options.max-wait-time}"
auto-connect-retry="${mongo.options.auto-connect-retry}"
socket-keep-alive="${mongo.options.socket-keep-alive}"
socket-timeout="${mongo.options.socket-timeout}"
slave-ok="${mongo.options.slave-ok}"
write-number="${mongo.options.write-number}"
write-timeout="${mongo.options.write-timeout}"
write-fsync="${mongo.options.write-fsync}"/>
</mongo:mongo>
<!--连接池工厂配置-->
<mongo:db-factory dbname="${mongo.dbname}" username="${mongo.username}" password="${mongo.password}" mongo-ref="mongo"/>
<bean id="mongoTemplate" class="org.springframework.data.mongodb.core.MongoTemplate">
<constructor-arg name="mongoDbFactory" ref="mongoDbFactory"/>
</bean>
<!--实体映射自动扫描注入的包-->
<mongo:mapping-converter>
<mongo:custom-converters base-package="com.xyh.mongodb_model" />
</mongo:mapping-converter>
在实体类中加入相应的@Document、@id、@Indexed、@PersistenceConstructor注解,来实现对数据实例化对象进行增删改查的操作。
详细信息可参考网址:https://blog.csdn.net/xuanyonghao/article/details/76976149
Cassandra
什么是Cassandra
Cassandra是数据放置在具有多个复制因子的不同机器上,处理大量数据的分布式架构的非关系数据库。
Cassandra特点
优点
配置简单
不需要多模块协同操作。
模式灵活
使用Cassandra,像文档存储,你不必提前解决记录中的字段。你可以在系统运行时随意的添加或移除字段。这是一个惊人的效率提升,特别是在大型部署上。
真正的可扩展性
Cassandra是纯粹意义上的水平扩展。为给集群添加更多容量,可以指向另一台电脑。你不必重启任何进程,改变应用查询,或手动迁移任何数据。
多数据中心识别
你可以调整你的节点布局来避免某一个数据中心起火,一个备用的数据中心将至少有每条记录的完全复制。
范围查询
如果你不喜欢全部的键值查询,则可以设置键的范围来查询。
列表数据结构
在混合模式可以将超级列添加到5维。对于每个用户的索引,这是非常方便的。
分布式写操作
有可以在任何地方任何时间集中读或写任何数据。并且不会有任何单点失败。
原理
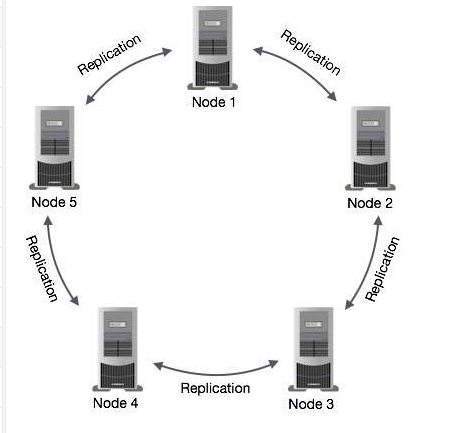
在Cassandra中,是无中心的P2P架构,网络中的所有节点都是对等的,它们构成了一个环,节点之间通过P2P协议每秒钟交换一次数据,这样每个节点都拥有其它所有节点的信息,包括位置、状态等,以避免单点故障。
写请求
当写事件发生时,首先由Commit Log捕获写事件并持久化;每个数据中心选取一个Coordinator来完成它所在数据中心的数据复制;存储结构类似LSM树(Log-Structured Merge Tree)这种结构;Commit Log记录每次写请求的完整信息,此时并不会根据主键进行排序,而是顺序写入;写入到Memtable时,Cassandra能够动态地为它分配内存空间;当memtable中的数据刷到SSTable后,Commit Log中的数据将被清理掉;Cassandra对Update操作的处理和传统关系数据库完全不一样,并不立即对原有数据进行更新,而是会增加一条新的记录,后续在进行Compaction时将数据再进行合并。Delete操作也同样如此,要删除的数据会先标记为Tombstone,后续进行Compaction时再真正永久删除。

图来源网址:https://www.yiibai.com/cassandra/cassandra-architecture.html
读请求
读取数据时,首先检查Bloom filter,每一个SSTable都有一个Bloom filter用来检查partition key是否在这个SSTable,这一步是在访问任何磁盘IO的前面就会做掉。如果存在,再检查partition key cache。读请求(Read Request)分两种,一种是Rirect Read Request,根据客户端配置的Consistency Level读取到数据即可返回客户端结果。一种是Background Read Repair Request,除了直接请求到达的节点外,会被发送到其它复制节点,用于修复之前写入有问题的节点,保证数据最终一致性。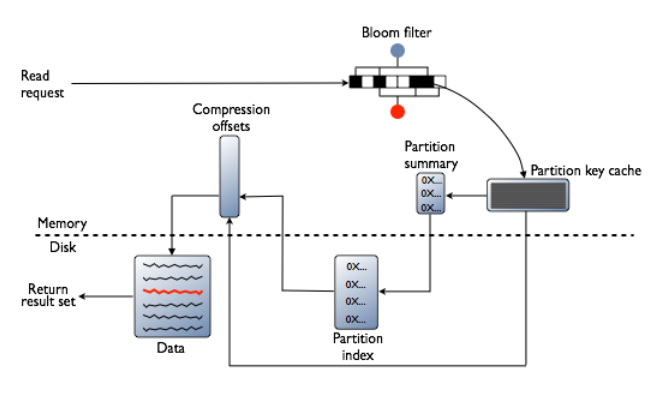
行缓存和键缓存请求流程图
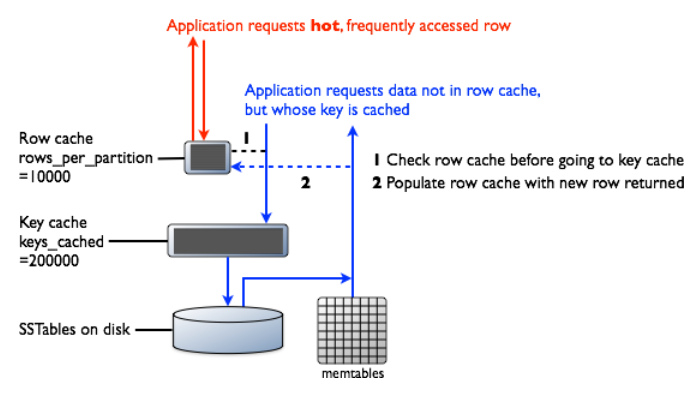
图来源网址:https://blog.csdn.net/fs1360472174/article/details/55005335
可参考网址:https://blog.csdn.net/doc_sgl/article/details/51068131
如何使用Cassandra
Cassandra集群搭建
https://blog.csdn.net/ch648966459/article/details/51671276/#commentBox
代码应用
引入pom.xml
<dependency> <groupId>com.datastax.cassandra</groupId> <artifactId>cassandra-driver-core</artifactId> <version>3.1.1</version> </dependency> <dependency> <groupId>com.datastax.cassandra</groupId> <artifactId>cassandra-driver-extras</artifactId> <version>3.1.1</version> </dependency>
连接代码
String[] hosts = new String[]{"192.168.1.1", "192.168.1.2", "192.168.1.3"};//cassandra主机地址 //认证配置 AuthProvider authProvider = new PlainTextAuthProvider("ershixiong", "123456"); LoadBalancingPolicy lbp = new TokenAwarePolicy( DCAwareRoundRobinPolicy.builder().withLocalDc("myDC").build() ); //读超时或连接超时设置 SocketOptions so = new SocketOptions().setReadTimeoutMillis(3000).setConnectTimeoutMillis(3000); //连接池配置 //PoolingOptions poolingOptions = new PoolingOptions().setConnectionsPerHost(HostDistance.LOCAL, 2, 3); //集群在同一个机房用HostDistance.LOCAL 不同的机房用HostDistance.REMOTE 忽略用HostDistance.IGNORED PoolingOptions poolingOptions= new PoolingOptions() .setMaxRequestsPerConnection(HostDistance.LOCAL, 64)//每个连接最多允许64个并发请求 .setCoreConnectionsPerHost(HostDistance.LOCAL, 2)//和集群里的每个机器都至少有2个连接 .setMaxConnectionsPerHost(HostDistance.LOCAL, 6);//和集群里的每个机器都最多有6个连接 //查询配置 //设置一致性级别ANY(0),ONE(1),TWO(2),THREE(3),QUORUM(4),ALL(5),LOCAL_QUORUM(6),EACH_QUORUM(7),SERIAL(8),LOCAL_SERIAL(9),LOCAL_ONE(10); //可以在每次生成查询statement的时候设置,也可以像这样全局设置 QueryOptions queryOptions = new QueryOptions().setConsistencyLevel(ConsistencyLevel.ONE); //重试策略 RetryPolicy retryPolicy = DowngradingConsistencyRetryPolicy.INSTANCE; int port = 9042;//端口号 String keyspace = "keyspacename";//要连接的库,可以不写 Cluster cluster = Cluster.builder() .addContactPoints(hosts) .withAuthProvider(authProvider) .withLoadBalancingPolicy(lbp) .withSocketOptions(so) .withPoolingOptions(poolingOptions) .withQueryOptions(queryOptions) .withRetryPolicy(retryPolicy) .withPort(port) .build(); Session session = cluster.connect(keyspace);
具体可参考:https://blog.csdn.net/u010003835/article/details/52516571
scylla、hazelcast大家也可以私下研究一下。
结论
当你仅仅是存储海量增长的消息数据,存储海量增长的图片,小视频的时候,你要求数据不能丢失,你要求人工维护尽可能少,你要求能迅速通过添加机器扩充存储,那么毫无疑问,Cassandra现在是占据上风的。
但是如果你希望构建一个超大规模的搜索引擎,产生超大规模的倒排索引文件(当然是逻辑上的文件,真实文件实际上被切分存储于不同的节点上),那么目前HDFS+HBase是你的首选。















 6237
6237











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









