







附链
你也可以在这些平台阅读本文:
定义
用原型实例指定创建对象的种类,并且通过拷贝这些原型创建新的对象。
原型模式不需要知道任何创建的细节,也不调用构造函数。
三个基本步骤
原型模式的核心在于原型类,而满足原型模式的原型类需要进行以下三个步骤:
- 实现Cloneable接口。
Cloneable接口实际上是个空接口(标记接口)。表明只有实现该接口才能够被复制,否则在运行的时候会抛出CloneNotSupportedException异常。 - 重写Object类中的clone方法。
Object类作为顶级父类,其内部包含一个clone()方法,用来返回对象的一个拷贝。 - 在clone()方法中调用super.clone()。
场景示例
笔者这里以改简历为例子。绝大多数读者应该和笔者一样将原来的简历拷贝一份,然后在拷贝的简历上进行修改。
创建简历类
这里简历类作为原型类,需要实现 Cloneable 接口的,同时重写 clone() 方法,并在 clone() 方法内部调用 super.clone() 。
/**
* @author zhh
* @description 简历类
* @date 2020-02-13 00:13
*/
public class Resume implements Cloneable {
/**
* 姓名
*/
private String name;
/**
* 生日
*/
private Date birthday;
/**
* 性别
*/
private String sex;
/**
* 学校
*/
private String school;
/**
* 工龄
*/
private String socialWorkAge;
/**
* 公司
*/
private String company;
/**
* 工作描述
*/
private String workDescription;
public Resume() {
System.out.println("Resume类的无参构造函数");
}
// 此处省略 getter、setter方法
@Override
protected Object clone() throws CloneNotSupportedException {
System.out.println("开始克隆简历");
return super.clone();
}
public void display() {
System.out.println(String.format("姓名: %s", name));
System.out.println(String.format("生日: %s, 性别: %s, 毕业院校: %s, 工龄: %s", birthday, sex, school, socialWorkAge));
System.out.println(String.format("公司: %s, 工作描述: %s", company, workDescription));
}
}
测试类及输出
/**
* @author zhh
* @description 测试类
* @date 2020-02-13 00:20
*/
public class Test {
public static void main(String[] args) throws Exception {
// 原版简历
Resume resumeA = new Resume();
resumeA.setName("海豪");
resumeA.setBirthday(new Date(94, 0, 1));
resumeA.setSex("男");
resumeA.setSchool("XXXX大学");
resumeA.setSocialWorkAge("1");
resumeA.setCompany("A科技有限公司");
resumeA.setWorkDescription("在A公司的工作描述");
// 拷贝简历改版
Resume resumeB = (Resume) resumeA.clone();
resumeB.setSocialWorkAge("3");
resumeB.setCompany("B科技有限公司");
resumeB.setWorkDescription("在B公司的工作描述");
System.out.println("=====简历修改前=====");
resumeA.display();
System.out.println("=====简历修改后=====");
resumeB.display();
System.out.println("是否为同一对象: " + (resumeA == resumeB));
}
}
测试类的输出结果如下:
Resume类的无参构造函数
开始克隆简历
=简历修改前=
姓名: 海豪
生日: Sat Jan 01 00:00:00 CST 1994, 性别: 男, 毕业院校: XXXX大学, 工龄: 1
公司: A科技有限公司, 工作描述: 在A公司的工作描述
=简历修改后=
姓名: 海豪
生日: Sat Jan 01 00:00:00 CST 1994, 性别: 男, 毕业院校: XXXX大学, 工龄: 3
公司: B科技有限公司, 工作描述: 在B公司的工作描述
是否为同一对象: false
从测试类的输出结果中我们可以看到:
- 克隆的时候并没有调用类的构造器
- 克隆后的对象是一个新的对象
知识扩展
说到克隆,就不得不说下深克隆(深拷贝)与浅克隆(浅拷贝)。
定义
先来看下深克隆与浅克隆各自的定义:
- **深克隆:**被复制的对象所有的变量都含有与原来对象相同的值,所有的对其他对象的引用也都指向复制过的新对象。换句话也就是说,深克隆不仅拷贝对象本身(包括对象中的基本变量),而且也拷贝对象包含的引用指向的所有对象。
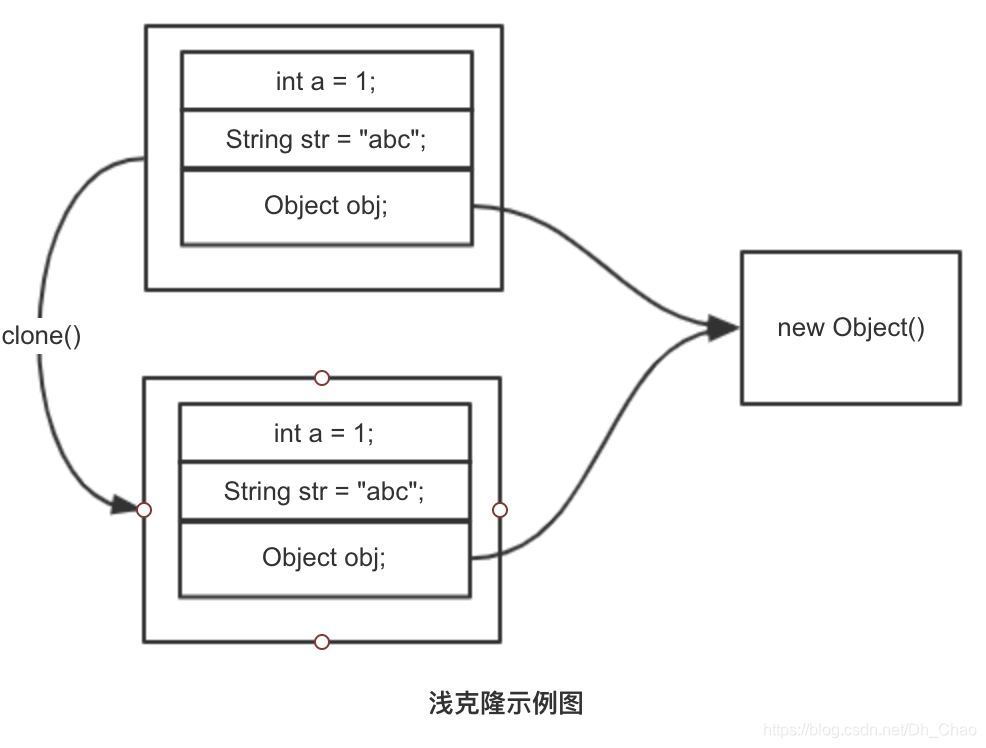
- **浅克隆:**被复制的对象所有的变量都含有与原来对象相同的值,所有的对其他对象的引用都仍然指向原来的对象。换句话也就是说,浅克隆拷贝对象时仅拷贝对象本身(包括对象中的基本变量),不拷贝对象包含的引用指向的对象。
图解定义

示例
我们对上述场景示例中的简历类做一个测试。
/**
* @author zhh
* @description 测试类
* @date 2020-02-13 00:20
*/
public class Test {
public static void main(String[] args) throws Exception {
// 原版简历
Resume resumeA = new Resume();
resumeA.setName("海豪");
resumeA.setBirthday(new Date(94, 0, 1));
resumeA.setSex("男");
resumeA.setSchool("XXXX大学");
resumeA.setSocialWorkAge("1");
resumeA.setCompany("A科技有限公司");
resumeA.setWorkDescription("在A公司的工作描述");
// 拷贝简历
Resume resumeB = (Resume) resumeA.clone();
System.out.println("=====原版简历=====");
resumeA.display();
System.out.println("=====拷贝简历=====");
resumeB.display();
resumeA.getBirthday().setDate(5);
System.out.println();
System.out.println("=====修改后原版简历=====");
resumeA.display();
System.out.println("=====修改后拷贝简历=====");
resumeB.display();
}
}
测试类的输出结果如下:
Resume类的无参构造函数
开始克隆简历
=原版简历=
姓名: 海豪
生日: Sat Jan 01 00:00:00 CST 1994, 性别: 男, 毕业院校: XXXX大学, 工龄: 1
公司: A科技有限公司, 工作描述: 在A公司的工作描述
=拷贝简历=
姓名: 海豪
生日: Sat Jan 01 00:00:00 CST 1994, 性别: 男, 毕业院校: XXXX大学, 工龄: 1
公司: A科技有限公司, 工作描述: 在A公司的工作描述
=修改后原版简历=
姓名: 海豪
生日: Wed Jan 05 00:00:00 CST 1994, 性别: 男, 毕业院校: XXXX大学, 工龄: 1
公司: A科技有限公司, 工作描述: 在A公司的工作描述
=修改后拷贝简历=
姓名: 海豪
生日: Wed Jan 05 00:00:00 CST 1994, 性别: 男, 毕业院校: XXXX大学, 工龄: 1
公司: A科技有限公司, 工作描述: 在A公司的工作描述
我们可以看到,在测试类中我们只修改了原版简历的生日,但是输出的结果当中拷贝简历的生日也跟着发生了变化。
上述即为浅克隆,其并不拷贝生日变量引用指向的日期对象,与原对象共享日期对象。
改进
那么我们如何来实现深克隆?
其实方法很简单,大体上代码与浅克隆类似,主要的差别在于 clone() 方法。下段改进代码省略了其余方法,主要来看下 clone() 方法的变化。
/**
* @author zhh
* @description 简历类
* @date 2020-02-13 00:13
*/
public class Resume implements Cloneable {
// 省略其他方法
@Override
protected Object clone() throws CloneNotSupportedException {
System.out.println("开始克隆简历");
Resume resume = (Resume) super.clone();
// 深克隆
resume.birthday = (Date) resume.birthday.clone();
return resume;
}
}
这时再用示例的测试类进行测试的结果如下:
Resume类的无参构造函数
开始克隆简历
=原版简历=
姓名: 海豪
生日: Sat Jan 01 00:00:00 CST 1994, 性别: 男, 毕业院校: XXXX大学, 工龄: 1
公司: A科技有限公司, 工作描述: 在A公司的工作描述
=拷贝简历=
姓名: 海豪
生日: Sat Jan 01 00:00:00 CST 1994, 性别: 男, 毕业院校: XXXX大学, 工龄: 1
公司: A科技有限公司, 工作描述: 在A公司的工作描述
=修改后原版简历=
姓名: 海豪
生日: Wed Jan 05 00:00:00 CST 1994, 性别: 男, 毕业院校: XXXX大学, 工龄: 1
公司: A科技有限公司, 工作描述: 在A公司的工作描述
=修改后拷贝简历=
姓名: 海豪
生日: Wed Jan 01 00:00:00 CST 1994, 性别: 男, 毕业院校: XXXX大学, 工龄: 1
公司: A科技有限公司, 工作描述: 在A公司的工作描述
我们可以看到,在修改了原版简历的生日后,拷贝简历的生日并未发生改变。这也说明经过深克隆后,两者的日期引用并不是引用同一个对象。
总结
适用场景
- 类初始化需要消耗较多的资源
- new产生的一个对象需要非常繁琐的过程(数据准备、访问权限等)
- 构造函数比较复杂
- 循环体中生产大量对象时
优点
- 性能提高。原型模式性能比直接new一个对象的性能高。
- 摆脱构造函数的约束,简化创建的过程
缺点
- 必须配备克隆方法
- 对克隆复杂对象或者对克隆出的对象进行复杂改造时,容易引入风险
参考
- 《Head First 设计模式》
- 《大话设计模式》
- 维基百科-原型模式
- 菜鸟教程-原型模式
- 彻底理解Java深克隆和浅克隆的原理及实现















 702
702











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









