









本来想写树状数组的 好像
m
y
my
my申对这棵树有点迷茫 不过他不回我 那就接着来AVC自动机吧
U
P
D
:
20200517
UPD:20200517
UPD:20200517期中考试考完了 确实考完了…这辈子没拿过这种名次我真的是吐了
U
P
D
:
20200531
UPD:20200531
UPD:20200531先放这 题后更 坚决不能拖到下个月再发布…
第一次看到
A
C
AC
AC自动机好像是刚学的那会儿 我一看 诶这好啊 自动就能
A
C
AC
AC哈哈哈 (不过洛谷上好像真有自动
A
C
AC
AC机?
后来才知道
A
C
AC
AC是
A
h
o
−
C
o
r
a
s
i
c
k
Aho-Corasick
Aho−Corasick 俩人名(话说为什么算法名字都是好几个人名?科♂学♂家?
简介
与 K M P KMP KMP算法类似, A C AC AC自动机也是用来处理字符串匹配的问题。 K M P KMP KMP算法是用来处理单模式串的问题,即问:模式串 T T T是否是主串 S S S的子串?而 A C AC AC自动机是著名的多模匹配算法,用来处理多模式串的问题,例如:给出 n n n个单词 T i T_i Ti,再给出一段包含 m m m个字符的文章 S S S,问有多少个单词在文章里出现。
主要步骤
1.
1.
1.将所有的模式串构建成一颗
T
r
i
e
Trie
Trie树
2.
2.
2.对
T
r
i
e
Trie
Trie上所有的节点构造前缀指针
3.
3.
3.利用前缀指针对主串进行匹配
所以
A
C
AC
AC自动机是建立在
K
M
P
KMP
KMP算法和
T
r
i
e
Trie
Trie树的基础上的 如果不会怎么办?↓
一本通提高篇
K
M
P
KMP
KMP算法
一本通提高篇
T
r
i
e
Trie
Trie字典树
算法流程
我觉得书上的和网上一些博客里写的不是很清楚 我通过一个初学者的视角来讲
A
C
AC
AC自动机这个算法
大家都说
A
C
AC
AC自动机
=
K
M
P
+
T
r
i
e
=KMP+Trie
=KMP+Trie ,那么我们一起回顾一下这两个算法
K M P KMP KMP
K
M
P
KMP
KMP算法可以在线性时间内判断
A
A
A是否是
B
B
B的子串以及
A
A
A在
B
B
B中出现的位置
K
M
P
KMP
KMP中最巧妙的
n
e
x
t
next
next数组:
n
e
x
t
[
i
]
next[i]
next[i]表示
A
A
A中以
i
i
i位置为结尾的子串与
A
A
A的前缀能够匹配的最长长度
T r i e Trie Trie
T r i e Trie Trie树上根节点到每个节点的路径都代表一个前缀,用树来存储大量字符串信息
那么问题来了 如果有大量的字符串需要匹配 你会选择
K
M
P
+
KMP+
KMP+暴力,还是选择暴力
+
T
r
i
e
+Trie
+Trie呢
当然是
K
M
P
+
T
r
i
e
KMP+Trie\,\,
KMP+Trie哈哈
所谓
A
C
AC
AC自动机,就是把
K
M
P
KMP
KMP放到
T
r
i
e
Trie
Trie上跑,
K
M
P
KMP
KMP中
n
e
x
t
next
next数组特别重要,
A
C
AC
AC自动机也有一个同等地位的
f
a
i
l
fail
fail指针,和
n
e
x
t
next
next数组一样 都是后缀匹配前缀的最大长度 只不过
f
a
i
l
fail
fail是在树上搞
定义
f
a
i
l
[
i
]
fail[i]
fail[i]是与以
i
i
i节点为结尾的串的后缀有最大公共长度的前缀的结尾编号,如果找不到
f
a
i
l
fail
fail就指向根节点
也就是说,如果一个点
i
i
i的
f
a
i
l
fail
fail指针指向
j
j
j,那么根到
j
j
j的字符串是根到
i
i
i的字符串的一个后缀
拿图说话 当四个模式串分别是
A
B
C
D
,
A
B
D
,
B
C
D
,
C
D
ABCD,ABD,BCD,CD
ABCD,ABD,BCD,CD
T
r
i
e
Trie
Trie树上
f
a
i
l
fail
fail的指向就是这样的
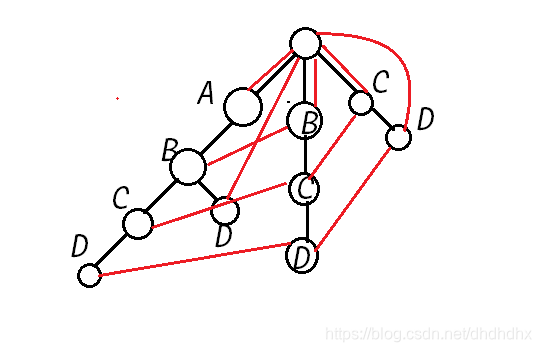
如果我们匹配到
A
B
C
D
ABCD
ABCD的
D
D
D失配,那么我们就跳到
B
C
D
BCD
BCD的
D
D
D,看看这个
D
D
D下面有没有能配上的,如果还是不行 就跳到
C
D
CD
CD上的
D
D
D看看这个
D
D
D行不行,后面也没有
D
D
D了 所以只能回到根节点。
那么如何求出
f
a
i
l
fail
fail数组呢 因为有树 所以我们想到了搜索,这里用
B
F
S
BFS
BFS来解决。为什么呢?
首先我们要确定:一个节点
f
a
i
l
fail
fail的指向一定是比这个点深度还小的节点。所以我们在处理当前节点
i
i
i的
f
a
i
l
fail
fail数组时应该已经处理好这个节点他爹
f
a
[
i
]
fa[i]
fa[i]的
f
a
i
l
fail
fail 这样一层一层的求显然要用
B
F
S
BFS
BFS。
那么我们用
B
F
S
BFS
BFS实现的原理是什么呢?
注意到如果点
i
i
i的父亲
f
i
f_i
fi的
f
a
i
l
fail
fail指向的是
f
a
i
l
f
i
fail_{f_i}
failfi,那么如果
f
a
i
l
f
i
fail_{f_i}
failfi有和
i
i
i值相同的儿子
j
j
j,那么
f
a
i
l
i
=
j
fail_i=j
faili=j。
这里比较难理解 细品品就能品出内味
代码实现
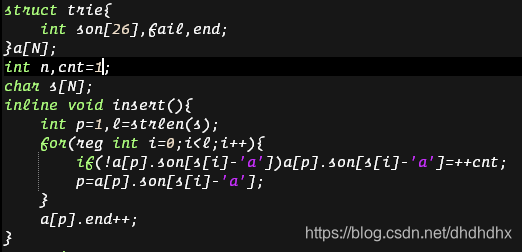
那…上代码?(有点小紧张 我也是第一次打 A C AC AC自动机
建树
A
C
AC
AC自动机建树跟
T
r
i
e
Trie
Trie其实是一样的 不过有一个要注意的就是
0
0
0号节点要留着当根 所以建树要从
1
1
1号节点开始
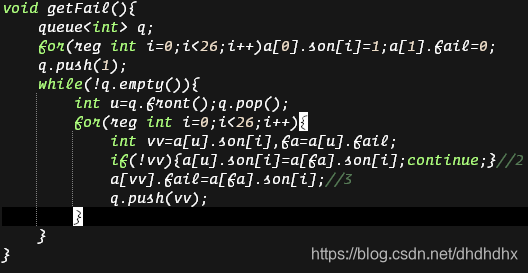
求
f
a
i
l
fail
fail
用上面说到的
B
F
S
BFS
BFS
有亿点注意事项:
1.
1.
1.刚开始我们不需要把所有的第一层
f
a
i
l
fail
fail指向根,我们可以利用一个虚拟的
0
0
0号点,让
0
0
0的所有儿子都指向根,然后让根的
f
a
i
l
fail
fail指向
0
0
0就可以了。
2.
2.
2.遍历到
u
u
u时,如果节点
u
u
u儿子中没有
i
i
i时,我们要让
a
[
u
]
.
s
o
n
[
i
]
=
a
[
f
a
u
]
.
s
o
n
[
i
]
a[u].son[i]=a[fa_u].son[i]
a[u].son[i]=a[fau].son[i](老套娃了…
虽然这不符合
T
r
i
e
Trie
Trie树的构造,但这是个很有用的优化时间的办法。 假设我们匹配时匹配到了一个字符,不巧的是这个节点没有这个字符的儿子,那么我们只能回溯到前面第一个满足存在字符
i
i
i是他儿子的节点 这样就大大地浪费了时间 。所以我们在预处理时直接给他赋值为
f
a
u
fa_u
fau的儿子
i
i
i。
f
a
u
fa_u
fau的深度小于
u
u
u,由于
B
F
S
BFS
BFS的缘故
f
a
u
fa_u
fau一定有儿子
i
i
i,这样就确保了匹配时每一步都是通过
f
a
i
l
fail
fail值转移的情况.
3.
3.
3.无论
f
a
u
fa_u
fau有没有和
i
i
i相同的儿子
j
j
j,我们都可以放心地让
f
a
i
l
i
=
j
fail_i=j
faili=j,还是因为
B
F
S
BFS
BFS的缘故,
f
a
i
l
j
fail_j
failj一定是有值的。
查询
前面优化已经做得很到位了 查询反而是最简单的一步
每个题的查询都大同小异 按照题的要求正常求就行
比如问你有多少个模式串在文本串里出现过(就是下面的模板题
那就不能算重 可以把每个已经加上的做个已经过的标记

先练练模板题
【模板】AC自动机(简单版)
#include<bits/stdc++.h>
using namespace std;
#define N int(1e6+100)
#define reg register
inline void read(int &x){
int s=0,w=1;char ch=getchar();
while(ch<'0'||ch>'9'){if(ch=='-')w=-1;ch=getchar();}
while(ch>='0'&&ch<='9'){s=(s<<3)+(s<<1)+(ch&15);ch=getchar();}
x=s*w;
}
struct trie{
int son[26],fail,end;
}a[N];
int n,cnt=1;
char s[N];
inline void insert(){
int p=1,l=strlen(s);
for(reg int i=0;i<l;i++){
if(!a[p].son[s[i]-'a'])a[p].son[s[i]-'a']=++cnt;
p=a[p].son[s[i]-'a'];
}
a[p].end++;
}
queue<int> q;
void getFail(){
for(reg int i=0;i<26;i++)a[0].son[i]=1;
q.push(1);a[1].fail=0;
while(!q.empty()){
int u=q.front();q.pop();
for(reg int i=0;i<26;i++){
int vv=a[u].son[i],fa=a[u].fail;
if(!vv){a[u].son[i]=a[fa].son[i];continue;}
a[vv].fail=a[fa].son[i];
q.push(vv);
}
}
}
inline int query(){
int p=1,ans=0,l=strlen(s);
for(reg int i=0;i<l;i++){
int vv=s[i]-'a',now=a[p].son[vv];
while(now>1&&a[now].end!=-1){
ans+=a[now].end,a[now].end=-1;
now=a[now].fail;
}
p=a[p].son[vv];
}
return ans;
}
int main(){
read(n);
for(reg int i=1;i<=n;i++){
scanf("%s",s);
insert();
}
getFail();
scanf("%s",s);
printf("%d\n",query());
}
【模板】AC自动机(加强版)
题面
S
o
l
u
t
i
o
n
:
Solution:
Solution:说是加强 其实就是换个问法
这题问出现次数 那么我们就在
T
r
i
e
Trie
Trie里在每个字符串结尾标记字符串编号,在询问时把这个字符串的数量
+
1
+1
+1就好了
这题我
M
L
E
MLE
MLE调了十分钟 以为是数据出大了 调小了还
R
E
RE
RE 后来才想起来
m
e
m
s
e
t
memset
memset也能导致
M
L
E
MLE
MLE…所以不能都暴力
m
e
m
s
e
t
memset
memset,就把用过的清零就行了
代码↓:
#include<bits/stdc++.h>
using namespace std;
#define reg register
#define N 1000001
struct trie{
int son[26],fail,end;
void clear(){
memset(son,0,sizeof(son));
fail=end=0;
}
}a[N];
int n,ans,cnt,vis[N];
char s[151][N],t[N];
inline void insert(char* s, int id){
int p=1,l=strlen(s);
for(reg int i=0;i<l;i++){
if(!a[p].son[s[i]-'a'])a[p].son[s[i]-'a']=++cnt;
p=a[p].son[s[i]-'a'];
}
a[p].end=id;
}
inline void getFail(){
queue<int> q;
for(reg int i=0;i<26;i++)a[0].son[i]=1;
q.push(1);a[1].fail=0;
while(!q.empty()){
int u=q.front(),fa=a[u].fail;q.pop();
for(reg int i=0;i<26;i++){
int vv=a[u].son[i];
if(!vv){a[u].son[i]=a[fa].son[i];continue;}
a[vv].fail=a[fa].son[i];
q.push(vv);
}
}
}
inline void query(char *s){
int p=1,l=strlen(s);
for(reg int i=0;i<l;i++){
int vv=s[i]-'a',now=a[p].son[vv];
while(now>1){
if(a[now].end)vis[a[now].end]++;
now=a[now].fail;
}
p=a[p].son[vv];
}
}
int main(){
while(scanf("%d",&n)){
if(!n)break;
for(reg int i=0;i<=cnt;i++)a[i].clear();
memset(vis,0,sizeof(vis));
cnt=1,ans=0;
for(reg int i=1;i<=n;i++){
scanf("%s",s[i]);
insert(s[i],i);
}
scanf("%s",t);
getFail();
query(t);
for(reg int i=1;i<=n;i++)ans=vis[i]>ans?vis[i]:ans;
printf("%d\n",ans);
for(reg int i=1;i<=n;i++)if(vis[i]==ans)puts(s[i]);
}
}
好了 那么我们开始刷一本通题吧
Keywords Search
英语菜鸡表示网站里的题面是英文的看不懂
题目描述
In the modern time, Search engine came into the life of everybody like Google, Baidu, etc.
Wiskey also wants to bring this feature to his image retrieval system.
Every image have a long description, when users type some keywords to find the image, the system will match the keywords with description of image and show the image which the most keywords be matched.
To simplify the problem, giving you a description of image, and some keywords, you should tell me how many keywords will be match.
输入
First line will contain one integer means how many cases will follow by.
Each case will contain two integers N means the number of keywords and N keywords follow. (N <= 10000)
Each keyword will only contains characters ‘a’-‘z’, and the length will be not longer than 50.
The last line is the description, and the length will be not longer than 1000000.
输出
Print how many keywords are contained in the description.
样例输入
【样例
1
1
1】
1
5
she
he
say
shr
her
yasherhs
样例输出
【样例
1
1
1】
3
提示
S
o
l
u
t
i
o
n
:
Solution:
Solution:简述题意:给定
n
n
n个长度不超过
50
50
50的由小写英文字母组成的单词,以及一篇长为
m
m
m的文章,问有多少个单词在文章中出现了,多组数据。
又是裸题哈哈 别忘了每个节点可能有多个单词结尾就行
连刷三道模板题真爽
上代码
#include<bits/stdc++.h>
using namespace std;
#define reg register
#define N 1000
#define M 1000001
struct trie{
int son[26],fail,end;
void clear(){
memset(son,0,sizeof(son));
fail=end=0;
}
}a[N];
int n,T,cnt;
char s[N],t[M];
inline void insert(char* s, int id){
int p=1,l=strlen(s);
for(reg int i=0;i<l;i++){
if(!a[p].son[s[i]-'a'])a[p].son[s[i]-'a']=++cnt;
p=a[p].son[s[i]-'a'];
}
a[p].end++;
}
inline void getFail(){
queue<int> q;
for(reg int i=0;i<26;i++)a[0].son[i]=1;
q.push(1);a[1].fail=0;
while(!q.empty()){
int u=q.front(),fa=a[u].fail;q.pop();
for(reg int i=0;i<26;i++){
int vv=a[u].son[i];
if(!vv){a[u].son[i]=a[fa].son[i];continue;}
a[vv].fail=a[fa].son[i];
q.push(vv);
}
}
}
inline int query(char *s){
int p=1,ans=0,l=strlen(s);
for(reg int i=0;i<l;i++){
int vv=s[i]-'a',now=a[p].son[vv];
while(now>1){
if(a[now].end>0)ans+=a[now].end,a[now].end=-1;
now=a[now].fail;
}
p=a[p].son[vv];
}
return ans;
}
int main(){
scanf("%d",&T);
while(T--){
scanf("%d",&n);
for(reg int i=0;i<=cnt;i++)a[i].clear();
cnt=1;
for(reg int i=1;i<=n;i++){
scanf("%s",s);
insert(s,i);
}
scanf("%s",t);
getFail();
printf("%d\n",query(t));
}
}
玄武密码
题面
这个题洛谷上标签是后缀自动机??紫题?。。。 我笑了
S
o
l
u
t
i
o
n
:
Solution:
Solution:把所有走过的点都加上标记,然后每个字符串都查询最末尾有标记的编号就是答案
上代码↓
#include<bits/stdc++.h>
using namespace std;
#define N int(1e7+100)
#define M int(1e5+100)
#define reg register
inline int modify(char chr){
if(chr=='E')return 0;
if(chr=='S')return 1;
if(chr=='W')return 2;
if(chr=='N')return 3;
}
struct node{
int son[4],fail;
}a[M*100];
int n,m,cnt=1;
char str[N],s[M][101];
bool ck[N];
inline void insert(int id){
int p=1,l=strlen(s[id]);
for(reg int i=0;i<l;i++){
int chr=modify(s[id][i]);
if(!a[p].son[chr])a[p].son[chr]=++cnt;
p=a[p].son[chr];
}
}
void getFail(){
queue<int> q;
for(reg int i=0;i<4;i++)a[0].son[i]=1;a[1].fail=0;
q.push(1);
while(!q.empty()){
int u=q.front();q.pop();
for(reg int i=0;i<4;i++){
int vv=a[u].son[i],fa=a[u].fail;
if(!vv){a[u].son[i]=a[fa].son[i];continue;}
a[vv].fail=a[fa].son[i];
q.push(vv);
}
}
}
void mark(){
int p=1,now=0;
for(reg int i=0;i<n;i++){
int chr=modify(str[i]),now=a[p].son[chr];
while(now>1&&!ck[now])ck[now]=1,now=a[now].fail;
p=a[p].son[chr];
}
}
inline int solve(int id){
int l=strlen(s[id]),p=1,ans=0;
for(reg int i=0;i<l;i++){
int chr=modify(s[id][i]);
p=a[p].son[chr];
if(ck[p])ans=i+1;
}
return ans;
}
int main(){
scanf("%d%d",&n,&m);
scanf("%s",str);
for(reg int i=1;i<=m;i++){
scanf("%s",s[i]);
insert(i);
}
getFail();mark();
for(reg int i=1;i<=m;i++){
printf("%d\n",solve(i));
}
}
Censoring
题面
S
o
l
u
t
i
o
n
:
A
C
Solution:AC
Solution:AC自动机
+
+
+栈
这个题
K
M
P
KMP
KMP里也有一个弱化版 具体看这里:一本通提高篇
K
M
P
KMP
KMP 用到的是
K
M
P
+
KMP+
KMP+栈
两个题思想都是一样的,每次记下当前匹配的位置,当一个单词被删除的时候,返回到单词首字母前面的位置,按上次的位置接着匹配就可以了
没什么难的 上代码就行
#include<bits/stdc++.h>
using namespace std;
#define reg register
#define N int(1e5+100)
struct node{
int son[26],fail,len;
}a[N];
int n,cnt,top,ans[N],pos[N];
char s[N],str[N];
inline void insert(){
int p=0,l=strlen(s);
for(reg int i=0;i<l;i++){
if(!a[p].son[s[i]-'a'])a[p].son[s[i]-'a']=++cnt;
p=a[p].son[s[i]-'a'];
}
a[p].len=l;
}
void getFail(){
queue<int> q;
for(reg int i=0;i<26;i++)if(a[0].son[i]){
q.push(a[0].son[i]);
a[a[0].son[i]].fail=0;
}
while(!q.empty()){
int u=q.front(),fa=a[u].fail;q.pop();
for(reg int i=0;i<26;i++){
int vv=a[u].son[i];
if(vv){
a[vv].fail=a[fa].son[i];
q.push(vv);
}
else a[u].son[i]=a[fa].son[i];
}
}
}
int main(){
scanf("%s%d",str,&n);
for(reg int i=1;i<=n;i++){
scanf("%s",s);
insert();
}
getFail();
int l=strlen(str),p=0;
for(reg int i=0;i<l;i++){
pos[i]=p=a[p].son[str[i]-'a'],ans[++top]=i;
if(a[p].len){
top-=a[p].len;
p=pos[ans[top]];
}
}
for(reg int i=1;i<=top;i++)putchar(str[ans[i]]);
puts("");
}
我说这题忘了 g e t f a i l getfail getfail调了十多分钟你们信么
单词
题面
S
o
l
u
t
i
o
n
:
Solution:
Solution:这道题有两种做法
首先最容易想到的是把所有串弄成一个大长串 然后套
A
C
AC
AC自动机,但是会
T
L
E
TLE
TLE 所以要用到拓扑排序优化的
A
C
AC
AC自动机 显然我不会
于是我想到了第二种方法,考虑
f
a
i
l
fail
fail树的性质
对于模式串
s
i
s_i
si,如果某一个串的前缀中有
s
i
s_i
si,那么这个串在
f
a
i
l
fail
fail树里一定经过
s
i
s_i
si的结尾点。如果一个串的中间或后缀中有这个
s
i
s_i
si,那么这个串的
f
a
i
l
fail
fail值对应的串一定过
s
i
s_i
si。
所以
a
n
s
i
=
s
u
m
f
a
i
l
i
+
s
u
m
i
ans_i=sum_{fail_i}+sum_i
ansi=sumfaili+sumi
要用到逆
b
f
s
bfs
bfs序,那就手写队列
上代码:
#include<bits/stdc++.h>
using namespace std;
#define N int(1e6+100)
#define reg register
struct trie{
int son[26],fail;
}a[N];
int n,cnt,ans[N],num[N],q[N];
char s[N];
inline void insert(int id){
int l=strlen(s),p=0;
for(reg int i=0;i<l;i++){
if(!a[p].son[s[i]-'a'])a[p].son[s[i]-'a']=++cnt;
p=a[p].son[s[i]-'a'],ans[p]++;
}
num[id]=p;
}
void getFail(){
int head=0,tail=0;
for(reg int i=0;i<26;i++)if(a[0].son[i])q[++tail]=a[0].son[i];
while(head<tail){
int u=q[++head],v,fa=a[u].fail;
for(int i=0;i<26;i++){
v=a[u].son[i];
if(v){
q[++tail]=v;
a[v].fail=a[fa].son[i];
}
else a[u].son[i]=a[fa].son[i];
}
}
}
int main(){
scanf("%d",&n);
for(reg int i=1;i<=n;i++){
scanf("%s",s);
insert(i);
}
getFail();
for(reg int i=cnt;i;i--)ans[a[q[i]].fail]+=ans[q[i]];
for(reg int i=1;i<=n;i++)printf("%d\n",ans[num[i]]);
}
最短母串
题面
状压
d
p
dp
dp 爬 这章写完先写动归吧 把
d
p
dp
dp好好补补 毕竟啥都得用
d
p
dp
dp
病毒
题面
S
o
l
u
t
i
o
n
:
Solution:
Solution:这题要用到判环 想看跟判环有关的题可以来这篇鸭
S
P
F
A
SPFA
SPFA判负环
要有无限长的可行串,我们可以将结点连接到儿子当作一条单向边,同时失配指针也当作一条单向边,如果存在一个环,且环上没有任何危险标记,那么
A
C
AC
AC自动机就能一直在环上匹配,并且永远也不会得到为模式串的一个子串,就像程序中的死循环一样。
求环当然还是
d
f
s
dfs
dfs简单 有环
y
e
s
yes
yes没环
n
o
no
no就行
(
(
(我把
N
I
E
NIE
NIE看成
N
T
E
NTE
NTE看半天才改过来
上代码
#include<bits/stdc++.h>
using namespace std;
#define reg register
#define N int(3e4+100)
struct node{
int son[2],fail;
bool safe;
}a[N];
int n,cnt,vis[N];
char s[N];
inline void insert(){
int p=0,l=strlen(s);
for(reg int i=0;i<l;i++){
if(!a[p].son[s[i]&15])a[p].son[s[i]&15]=++cnt;
p=a[p].son[s[i]&15];
}
a[p].safe=true;
}
void getFail(){
queue<int> q;
for(reg int i=0;i<2;i++)if(a[0].son[i]){
q.push(a[0].son[i]);
}
while(!q.empty()){
int u=q.front(),fa=a[u].fail;q.pop();
for(reg int i=0;i<2;i++){
int vv=a[u].son[i];
if(vv){
a[vv].fail=a[fa].son[i];
if(a[a[fa].son[i]].safe)a[vv].safe=true;
q.push(vv);
}
else a[u].son[i]=a[fa].son[i];
}
}
}
inline bool dfs(int x){
if(vis[x]==1)return true;
if(vis[x]==-1)return false;
vis[x]=1;
for(reg int i=0;i<2;i++){
int now=a[x].son[i];
if(!a[now].safe){
if(dfs(now))return true;
}
}
vis[x]=-1;return false;
}
int main(){
scanf("%d",&n);
for(reg int i=1;i<=n;i++){
scanf("%s",s);
insert();
}
getFail();
if(dfs(0))puts("TAK");
else puts("NIE");
}
文本生成器
题面
A
C
+
d
p
AC+dp
AC+dp写完
d
p
dp
dp回来补(不是我没时间写了














 212
212











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









