






作者:张亚飞
山西医科大学在读研究生
1. 并发编程
Python中实现并发编程的三种方案:多线程、多进程和异步I/O。并发编程的好处在于可以提升程序的执行效率以及改善用户体验;坏处在于并发的程序不容易开发和调试,同时对其他程序来说它并不友好。
- 多线程:Python中提供了Thread类并辅以Lock、Condition、Event、Semaphore和Barrier。Python中有GIL来防止多个线程同时执行本地字节码,这个锁对于CPython是必须的,因为CPython的内存管理并不是线程安全的,因为GIL的存在多线程并不能发挥CPU的多核特性。
- 多进程:多进程可以有效的解决GIL的问题,实现多进程主要的类是Process,其他辅助的类跟threading模块中的类似,进程间共享数据可以使用管道、套接字等,在multiprocessing模块中有一个Queue类,它基于管道和锁机制提供了多个进程共享的队列。下面是官方文档上关于多进程和进程池的一个示例。
- 异步处理:从调度程序的任务队列中挑选任务,该调度程序以交叉的形式执行这些任务,我们并不能保证任务将以某种顺序去执行,因为执行顺序取决于队列中的一项任务是否愿意将CPU处理时间让位给另一项任务。异步任务通常通过多任务协作处理的方式来实现,由于执行时间和顺序的不确定,因此需要通过回调式编程或者
future对象来获取任务执行的结果。Python 3通过asyncio模块和await和async关键字(在Python 3.7中正式被列为关键字)来支持异步处理。
Python中有一个名为
aiohttp的三方库,它提供了异步的HTTP客户端和服务器,这个三方库可以跟asyncio模块一起工作,并提供了对Future对象的支持。Python 3.6中引入了async和await来定义异步执行的函数以及创建异步上下文,在Python 3.7中它们正式成为了关键字。下面的代码异步的从5个URL中获取页面并通过正则表达式的命名捕获组提取了网站的标题。
# -*- coding: utf-8 -*-
"""
Datetime: 2019/6/13
Author: Zhang Yafei
Description: async + await + aiiohttp 异步编程示例
"""
import asyncio
import re
import aiohttp
PATTERN = re.compile(r'\<title\>(?P<title>.*)\<\/title\>')
async def fetch_page(session, url):
async with session.get(url, ssl=False) as resp:
return await resp.text()
async def show_title(url):
async with aiohttp.ClientSession() as session:
html = await fetch_page(session, url)
print(PATTERN.search(html).group('title'))
def main():
urls = ('https://www.python.org/',
'https://git-scm.com/',
'https://www.jd.com/',
'https://www.taobao.com/',
'https://www.douban.com/')
loop = asyncio.get_event_loop()
tasks = [show_title(url) for url in urls]
loop.run_until_complete(asyncio.wait(tasks))
loop.close()
if __name__ == '__main__':
main()
当程序不需要真正的并发性或并行性,而是更多的依赖于异步处理和回调时,asyncio就是一种很好的选择。如果程序中有大量的等待与休眠时,也应该考虑asyncio,它很适合编写没有实时数据处理需求的Web应用服务器。
2. 自定义异步爬虫架构 - AsyncSpider
- 目录结构

目录结构
- manage.py: 项目启动文件
- engine.py: 项目引擎
- settings.py: 项目参数设置
- spiders文件夹: spider爬虫编写
- settings设置
import os
DIR_PATH = os.path.abspath(os.path.dirname(__file__))
# 爬虫项目模块类路径
Spider_Name = 'spiders.xiaohua.XiaohuaSpider'
# 全局headers
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 6.3; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.106 Safari/537.36'}
TO_FILE = 'xiaohua.csv'
# 若要保存图片,设置文件夹
IMAGE_DIR = 'images'
if not os.path.exists(IMAGE_DIR):
os.mkdir(IMAGE_DIR)
- spider编写
- 结构

spider编写
- 编写爬取xiaohua网示例
# -*- coding: utf-8 -*-
"""
Datetime: 2019/6/11
Author: Zhang Yafei
Description: 爬虫Spider
"""
import os
import re
from urllib.parse import urljoin
from engine import Request
from settings import TO_FILE
import pandas as pd
class XiaohuaSpider(object):
""" 自定义Spider类 """
# 1. 自定义起始url列表
start_urls = [f'http://www.xiaohuar.com/list-1-{i}.html' for i in range(4)]
def filter_downloaded_urls(self):
""" 2. 添加过滤规则 """
# self.start_urls = self.start_urls
pass
def start_request(self):
""" 3. 将请求加入请求队列(集合),发送请求 """
for url in self.start_urls:
yield Request(url=url, callback=self.parse)
async def parse(self, response):
""" 4. 拿到请求响应,进行数据解析 """
html = await response.text(encoding='gbk')
reg = re.compile('<img width="210".*alt="(.*?)".*src="(.*?)" />')
results = re.findall(reg, html)
item_list = []
request_list = []
for name, src in results:
img_url = src if src.startswith('http') else urljoin('http://www.xiaohuar.com', src)
item_list.append({'name': name, 'img_url': img_url})
request_list.append(Request(url=img_url, callback=self.download_img, meta={'name': name}))
# 4.1 进行数据存储
await self.store_data(data=item_list, url=response.url)
# 4.2 返回请求和回调函数
return request_list
@staticmethod
async def store_data(data, url):
""" 5. 数据存储 """
df = pd.DataFrame(data=data)
if os.path.exists(TO_FILE):
df.to_csv(TO_FILE, index=False, mode='a', header=False, encoding='utf_8_sig')
else:
df.to_csv(TO_FILE, index=False, encoding='utf_8_sig')
print(f'{url}\t数据下载完成')
@staticmethod
async def download_img(response):
""" 二层深度下载 """
name = response.request.meta.get('name')
with open(f'images/{name}.jpg', mode='wb') as f:
f.write(await response.read())
print(f'{name}\t下载成功')
- 运行
cd AsyncSpider
python manage.py

-
运行结果


-
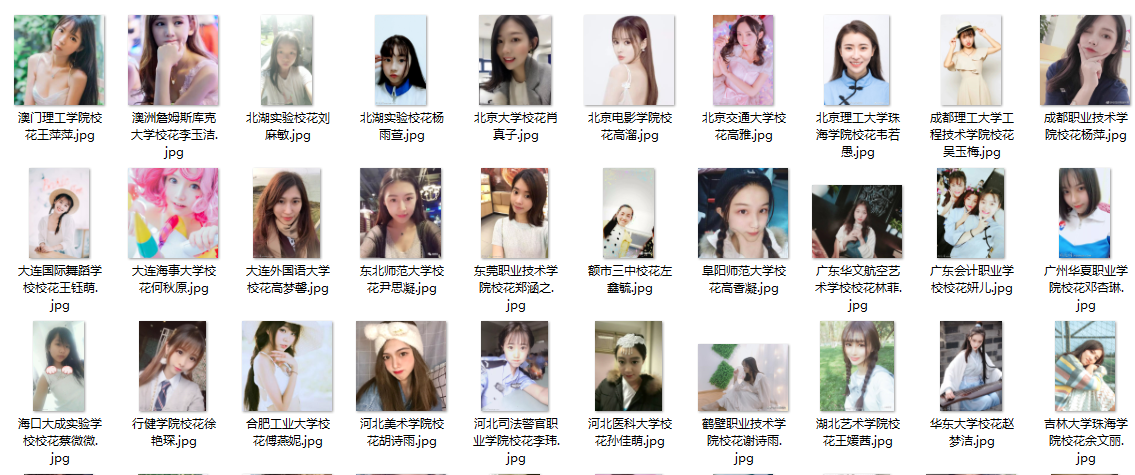
下载图片
- 生成文件
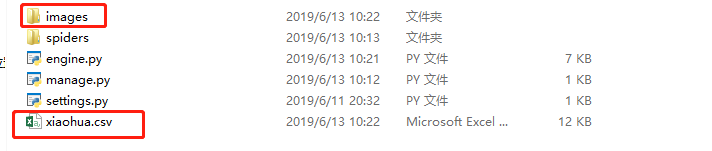















 1118
1118











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









