






http://fbevmware.blogspot.com/2013/12/data-replication-in-multi-cloud.html
要翻墙。。。
——————————————————————————————————————————————————————
Context
Few years ago, i started working on a project named Jxtadoop providing Hadoop Distributed Filesystem capabilities on top of of a peer-to-peer network. This initial goal was simply to load a file once to a Data Cloud which will take care of replication wherever the peers (data nodes) are deployed... I also wanted to avoid putting my data outside of my private network to ensure complete data privacy.
After some times, it appeared that this solution is also a very good fit to support data replication in a Multi-Cloud Environment. Any file (small or big) can be loaded in one cloud and then gets automatically replicated to the other clouds. This makes multi-cloud Data Brokering very easy and straightforward.
Hadoop is a very good candidate to provide those functionalities at a datacenter level. However when moving to a multi-cloud environment, it is no longer viable unless a Virtual Private Data Network is built. This VPDN is created on top of a peer-to-peer network which provides redundancy, multi-path routing, privacy, encryption across all the clouds...
Concept
Let's assume we are in a true Multi-Cloud Broker environment. For this blog, i assume i actually have 3 clouds hosting multiple workloads (aka virtual servers) in each. The picture below depicts a classical configuration which will appear in the coming years where business will source IT from different Cloud providers and really consume IT in a true Service Broker model.
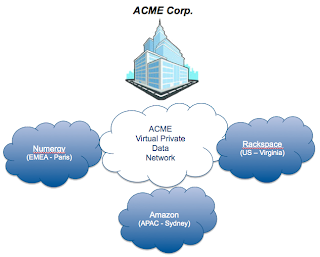 ACME Corp. has its headquarters based out of France and subsidiaries all over the world.
ACME Corp. has its headquarters based out of France and subsidiaries all over the world.
The new strategy is to source IT infrastructure from local service providers to deliver IT services directly to the local branches. There is no will to set up local IT anymore.
Data replication, propagation, protection (...) is really an issue in such a configuration and reversibility has to also be configured.
Setting up this Virtual Private Data Network will support this Service Broker Strategy.
Conceptually, the solution is very simple. A master node (calledRendez-vous Namenode) is located in the HQ and is the brain of the VPDN. That's where all the logic is handled such as data availability, multi-path data transfer, data placement... In each Cloud, there is a Relay Datanode which acts as the entry point for the Cloud. It will play a routing role communicating directly with other Cloud relays and also play a buffering role for data transmission. To avoid any SPOF, all those peers can be deployed in a multi-instance mode.
Finally each workload instance (physical servers, virtual machines, containers...) hosts a Peer Datanode which is the actual endpoint for data storage and consumption.
Virtual Private Data Network Architecture
As explained in the previous section, the overall architecture relies on three main components.
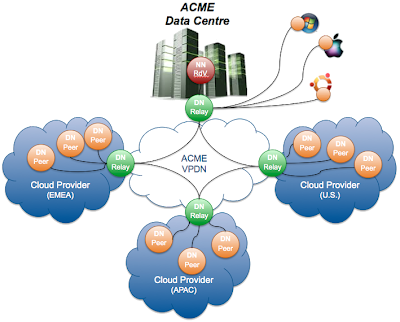
All the communications are multi-path, authenticated, encrypted... There is no need to set-up VPNs between the Clouds which could lead to some contentions points. Here the communication is either direct through multicast or going through the best (shortest) routing path at the peer-to-peer layer level.
The traffic flows are of 2 kinds.
. The RPC flow and the DATA flow. The first one handles all the signaling required to operate the VPDN such as routing, heartbeat, placement requests, updates ... There is actually no business data on this flow, hence it is possible to have a set-up where data traffic is limited to a cloud or even a country while the commands are centrally managed.
. The DATA flow is the actual business data transferred over the wire. This flow can be local to a datacentre using multicast wherever possible. It can also still be local but transiting through the Cloud relay for multiple domains. Finally this flow can go through multiple relays. In the example below, a data block located on the Windows PC will get replicated to the APAC Cloud by going through 2 relays (the DC one + the APAC Cloud one).
Benefits
This new approach brings many benefits for a mutli-Cloud environment and for companies willing to operate their IT with an IT Service Broker model.
Setting up your own environment
The technology used to create this Virtual Private Data Network can be found here. The testing described above has been done using a physical environment from OVH in France to simulate the HQ. 3 clouds have been consumed :Numergy (EMEA - France), Rackspace (U.S. - Virginia) and Amazon (APAC - Australia).
The testing leveraged Docker to create multiple Datanode peers on a single VM with a complex network topology (see1 & 2). The associated containers can be found on the Docker main repository :
Desktop clients have been installed on Mac OS, Windows and Linux. Just ensure you use Windows 7.
Conclusion
This concludes my Jxtadoop project which will get released as version 1.0.0 later this month. I'll provide a SaaS set-up with a Rendez-vous Namenode and a Relay Peer for quick testing.
Next ideas :
Links
Few years ago, i started working on a project named Jxtadoop providing Hadoop Distributed Filesystem capabilities on top of of a peer-to-peer network. This initial goal was simply to load a file once to a Data Cloud which will take care of replication wherever the peers (data nodes) are deployed... I also wanted to avoid putting my data outside of my private network to ensure complete data privacy.
After some times, it appeared that this solution is also a very good fit to support data replication in a Multi-Cloud Environment. Any file (small or big) can be loaded in one cloud and then gets automatically replicated to the other clouds. This makes multi-cloud Data Brokering very easy and straightforward.
Hadoop is a very good candidate to provide those functionalities at a datacenter level. However when moving to a multi-cloud environment, it is no longer viable unless a Virtual Private Data Network is built. This VPDN is created on top of a peer-to-peer network which provides redundancy, multi-path routing, privacy, encryption across all the clouds...
Concept
Let's assume we are in a true Multi-Cloud Broker environment. For this blog, i assume i actually have 3 clouds hosting multiple workloads (aka virtual servers) in each. The picture below depicts a classical configuration which will appear in the coming years where business will source IT from different Cloud providers and really consume IT in a true Service Broker model.
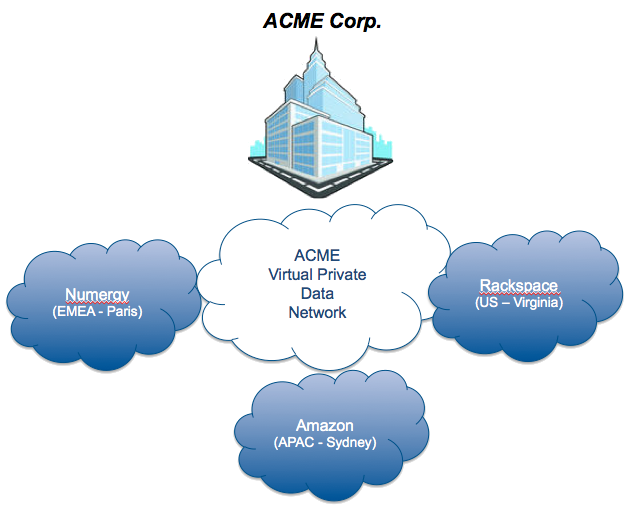
The new strategy is to source IT infrastructure from local service providers to deliver IT services directly to the local branches. There is no will to set up local IT anymore.
Data replication, propagation, protection (...) is really an issue in such a configuration and reversibility has to also be configured.
Setting up this Virtual Private Data Network will support this Service Broker Strategy.
Conceptually, the solution is very simple. A master node (calledRendez-vous Namenode) is located in the HQ and is the brain of the VPDN. That's where all the logic is handled such as data availability, multi-path data transfer, data placement... In each Cloud, there is a Relay Datanode which acts as the entry point for the Cloud. It will play a routing role communicating directly with other Cloud relays and also play a buffering role for data transmission. To avoid any SPOF, all those peers can be deployed in a multi-instance mode.
Finally each workload instance (physical servers, virtual machines, containers...) hosts a Peer Datanode which is the actual endpoint for data storage and consumption.
Virtual Private Data Network Architecture
As explained in the previous section, the overall architecture relies on three main components.
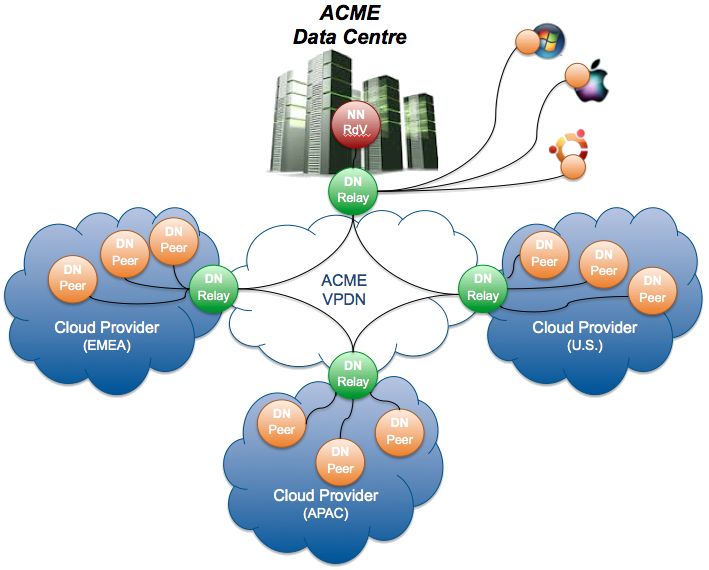
- Namenode Rendez-Vous providing Data Transport Logic as well as Data placement and replication. It has the peer-to-peer network topology overall understanding as well as the data cloud meta-data. There is no data traffic going through this peer.
- Datanode Relay providing Data Storage as well as Data Transport. The local peers which can communicate between each others through multicast, will rely on the relays to communicate with remote peers located in other data clouds. It can also store data as a temporary buffer.
- Datanode Peer providing Data Storage to store data chunks on each server peer and even on remote desktop peers.
All the communications are multi-path, authenticated, encrypted... There is no need to set-up VPNs between the Clouds which could lead to some contentions points. Here the communication is either direct through multicast or going through the best (shortest) routing path at the peer-to-peer layer level.
The traffic flows are of 2 kinds.
. The RPC flow and the DATA flow. The first one handles all the signaling required to operate the VPDN such as routing, heartbeat, placement requests, updates ... There is actually no business data on this flow, hence it is possible to have a set-up where data traffic is limited to a cloud or even a country while the commands are centrally managed.
. The DATA flow is the actual business data transferred over the wire. This flow can be local to a datacentre using multicast wherever possible. It can also still be local but transiting through the Cloud relay for multiple domains. Finally this flow can go through multiple relays. In the example below, a data block located on the Windows PC will get replicated to the APAC Cloud by going through 2 relays (the DC one + the APAC Cloud one).
Benefits
This new approach brings many benefits for a mutli-Cloud environment and for companies willing to operate their IT with an IT Service Broker model.
- Redundancy : the data is automatically replicated in the Clouds wherever needed ;
- Availability : the data is always available with the use of multiple replicas (3, 5, 7...) ;
- Efficiency : quick deployment, quick capacity expansion ;
- Simplicity : load once on a peer and automated replication ;
- Future-proof : leverage big data technologies ;
- Portable : can run on any server and desktop platforms supporting Java 7 ;
- Confidentiality : all the data transfer are encrypted, authenticated ... ;
- Locality : data can be located in a specific Cloud and not leak outside ;
Setting up your own environment
The technology used to create this Virtual Private Data Network can be found here. The testing described above has been done using a physical environment from OVH in France to simulate the HQ. 3 clouds have been consumed :Numergy (EMEA - France), Rackspace (U.S. - Virginia) and Amazon (APAC - Australia).
The testing leveraged Docker to create multiple Datanode peers on a single VM with a complex network topology (see1 & 2). The associated containers can be found on the Docker main repository :
- Namenode Rendez-Vous (jxtadoop/namenode)
- Datanode Relay (jxtadoop/relay)
- Datanode Peer (jxtadoop/datanode)
Desktop clients have been installed on Mac OS, Windows and Linux. Just ensure you use Windows 7.
Conclusion
This concludes my Jxtadoop project which will get released as version 1.0.0 later this month. I'll provide a SaaS set-up with a Rendez-vous Namenode and a Relay Peer for quick testing.
Next ideas :
- Roll-out StandaloneHDFS UI for Jxtadoop ;
- Release FileSharing capability based on Jxtadoop ;
- PaaS/SaaS set-up for Jxtadoop with Docker and CloudFoundry ;
- Think about magic combination of App Virtualization (Docker), Network Virtualization (Open vSwitch) and Data Virtualization (Jxtadoop) ;
Links














 2195
2195











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









