






http://blog.csdn.net/ab198604/article/details/8250461
——————————————————————————————————————————————————
要想深入的学习Hadoop数据分析技术,首要的任务是必须要将hadoop集群环境搭建起来,可以将hadoop简化地想象成一个小软件,通过在各个物理节点上安装这个小软件,然后将其运行起来,就是一个hadoop分布式集群了。
说来简单,但是应该怎么做呢?不急,本文的主要目的就是让新手看了之后也能够亲自动手实施这些过程。由于本人资金不充裕,只能通过虚拟机来实施模拟集群环境,虽然说是虚机模拟,但是在虚机上的hadoop的集群搭建过程也可以使用在实际的物理节点中,思想是一样的。也如果你有充裕的资金,自己不介意烧钱买诸多电脑设备,这是最好不过的了。
也许有人想知道安装hadoop集群需要什么样的电脑配置,这里只针对虚拟机环境,下面介绍下我自己的情况:
CPU:Intel酷睿双核 2.2Ghz
内存: 4G
硬盘: 320G
系统:xp
老实说,我的本本配置显然不够好,原配只有2G内存,但是安装hadoop集群时实在是很让人崩溃,本人亲身体验过后实在无法容忍,所以后来再扩了2G,虽然说性能还是不够好,但是学习嘛,目前这种配置还勉强可以满足学习要求,如果你的硬件配置比这要高是最好不过的了,如果能达到8G,甚至16G内存,学习hadoop表示无任何压力。
说完电脑的硬件配置,下面说说本人安装hadoop的准备条件:
1 安装Vmware WorkStation软件
有些人会问,为何要安装这个软件,这是一个VM公司提供的虚拟机工作平台,后面需要在这个平台上安装Linux操作系统。具体安装过程网上有很多资料,这里不作过多的说明。
2 在虚拟机上安装linux操作系统
在前一步的基础之上安装linux操作系统,因为hadoop一般是运行在linux平台之上的,虽然现在也有windows版本,但是在linux上实施比较稳定,也不易出错,如果在windows安装hadoop集群,估计在安装过程中面对的各种问题会让人更加崩溃,其实我还没在windows上安装过,呵呵~
在虚拟机上安装的linux操作系统为ubuntu10.04,这是我安装的系统版本,为什么我会使用这个版本呢,很简单,因为我用的熟^_^其实用哪个linux系统都是可以的,比如,你可以用centos, redhat, fedora等均可,完全没有问题。在虚拟机上安装linux的过程也在此略过,如果不了解可以在网上搜搜,有许多这方面的资料。
3 准备3个虚拟机节点
其实这一步骤非常简单,如果你已经完成了第2步,此时你已经准备好了第一个虚拟节点,那第二个和第三个虚拟机节点如何准备?可能你已经想明白了,你可以按第2步的方法,再分别安装两遍linux系统,就分别实现了第二、三个虚拟机节点。不过这个过程估计会让你很崩溃,其实还有一个更简单的方法,就是复制和粘贴,没错,就是在你刚安装好的第一个虚拟机节点,将整个系统目录进行复制,形成第二和第三个虚拟机节点。简单吧!~~
很多人也许会问,这三个结点有什么用,原理很简单,按照hadoop集群的基本要求,其中一个是master结点,主要是用于运行hadoop程序中的namenode、secondorynamenode和jobtracker任务。用外两个结点均为slave结点,其中一个是用于冗余目的,如果没有冗余,就不能称之为hadoop了,所以模拟hadoop集群至少要有3个结点,如果电脑配置非常高,可以考虑增加一些其它的结点。slave结点主要将运行hadoop程序中的datanode和tasktracker任务。
所以,在准备好这3个结点之后,需要分别将linux系统的主机名重命名(因为前面是复制和粘帖操作产生另两上结点,此时这3个结点的主机名是一样的),重命名主机名的方法:
Vim /etc/hostname
通过修改hostname文件即可,这三个点结均要修改,以示区分。
以下是我对三个结点的ubuntu系统主机分别命名为:master, node1, node2

![]()

基本条件准备好了,后面要干实事了,心急了吧,呵呵,别着急,只要跟着本人的思路,一步一个脚印地,一定能成功布署安装好hadoop集群的。安装过程主要有以下几个步骤:
一、 配置hosts文件
二、 建立hadoop运行帐号
三、 配置ssh免密码连入
四、 下载并解压hadoop安装包
五、 配置namenode,修改site文件
六、 配置hadoop-env.sh文件
七、 配置masters和slaves文件
八、 向各节点复制hadoop
九、 格式化namenode
十、 启动hadoop
十一、 用jps检验各后台进程是否成功启动
十二、 通过网站查看集群情况
下面我们对以上过程,各个击破吧!~~
一、 配置hosts文件
先简单说明下配置hosts文件的作用,它主要用于确定每个结点的IP地址,方便后续
master结点能快速查到并访问各个结点。在上述3个虚机结点上均需要配置此文件。由于需要确定每个结点的IP地址,所以在配置hosts文件之前需要先查看当前虚机结点的IP地址是多少,可以通过ifconfig命令进行查看,如本实验中,master结点的IP地址为:

如果IP地址不对,可以通过ifconfig命令更改结点的物理IP地址,示例如下:

通过上面命令可以将IP改为192.168.1.100。将每个结点的IP地址设置完成后,就可以配置hosts文件了,hosts文件路径为;/etc/hosts,我的hosts文件配置如下,大家可以参考自己的IP地址以及相应的主机名完成配置
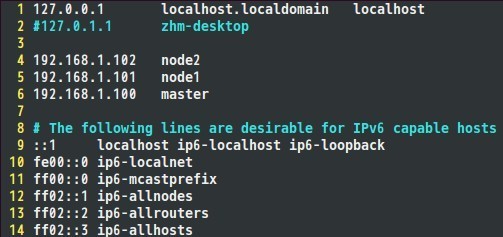
二、 建立hadoop运行帐号
即为hadoop集群专门设置一个用户组及用户,这部分比较简单,参考示例如下:
sudo groupadd hadoop //设置hadoop用户组
sudo useradd –s /bin/bash –d /home/zhm –m zhm –g hadoop –G admin //添加一个zhm用户,此用户属于hadoop用户组,且具有admin权限。
sudo passwd zhm //设置用户zhm登录密码
su zhm //切换到zhm用户中
上述3个虚机结点均需要进行以上步骤来完成hadoop运行帐号的建立。
三、 配置ssh免密码连入
这一环节最为重要,而且也最为关键,因为本人在这一步骤裁了不少跟头,走了不少弯
路,如果这一步走成功了,后面环节进行的也会比较顺利。
SSH主要通过RSA算法来产生公钥与私钥,在数据传输过程中对数据进行加密来保障数
据的安全性和可靠性,公钥部分是公共部分,网络上任一结点均可以访问,私钥主要用于对数据进行加密,以防他人盗取数据。总而言之,这是一种非对称算法,想要破解还是非常有难度的。Hadoop集群的各个结点之间需要进行数据的访问,被访问的结点对于访问用户结点的可靠性必须进行验证,hadoop采用的是ssh的方法通过密钥验证及数据加解密的方式进行远程安全登录操作,当然,如果hadoop对每个结点的访问均需要进行验证,其效率将会大大降低,所以才需要配置SSH免密码的方法直接远程连入被访问结点,这样将大大提高访问效率。
OK,废话就不说了,下面看看如何配置SSH免密码登录吧!~~
(1) 每个结点分别产生公私密钥。
键入命令:
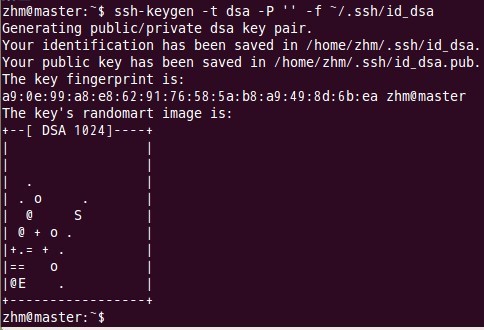
以上命令是产生公私密钥,产生目录在用户主目录下的.ssh目录中,如下:
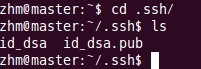
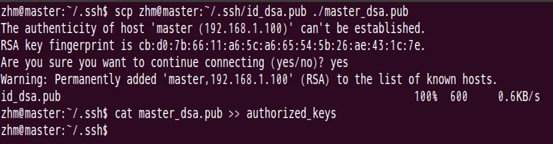
Id_dsa.pub为公钥,id_dsa为私钥,紧接着将公钥文件复制成authorized_keys文件,这个步骤是必须的,过程如下:

用上述同样的方法在剩下的两个结点中如法炮制即可。
(2) 单机回环ssh免密码登录测试
即在单机结点上用ssh进行登录,看能否登录成功。登录成功后注销退出,过程如下:

注意标红圈的指示,有以上信息表示操作成功,单点回环SSH登录及注销成功,这将为后续跨子结点SSH远程免密码登录作好准备。
用上述同样的方法在剩下的两个结点中如法炮制即可。
(3) 让主结点(master)能通过SSH免密码登录两个子结点(slave)
为了实现这个功能,两个slave结点的公钥文件中必须要包含主结点的公钥信息,这样
当master就可以顺利安全地访问这两个slave结点了。操作过程如下:
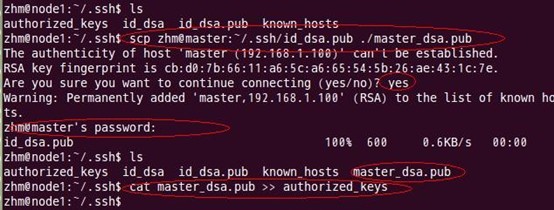
如上过程显示了node1结点通过scp命令远程登录master结点,并复制master的公钥文件到当前的目录下,这一过程需要密码验证。接着,将master结点的公钥文件追加至authorized_keys文件中,通过这步操作,如果不出问题,master结点就可以通过ssh远程免密码连接node1结点了。在master结点中操作如下:

由上图可以看出,node1结点首次连接时需要,“YES”确认连接,这意味着master结点连接node1结点时需要人工询问,无法自动连接,输入yes后成功接入,紧接着注销退出至master结点。要实现ssh免密码连接至其它结点,还差一步,只需要再执行一遍ssh node1,如果没有要求你输入”yes”,就算成功了,过程如下:
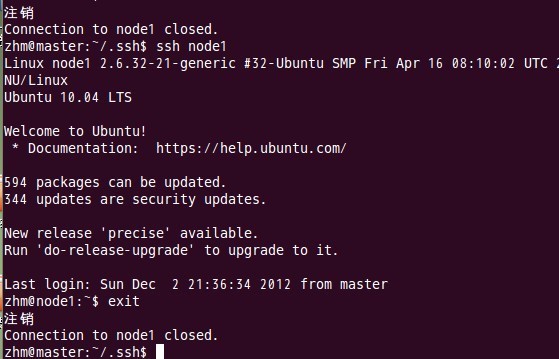
如上图所示,master已经可以通过ssh免密码登录至node1结点了。
对node2结点也可以用同样的方法进行,如下图:
Node2结点复制master结点中的公钥文件

Master通过ssh免密码登录至node2结点测试:
第一次登录时:
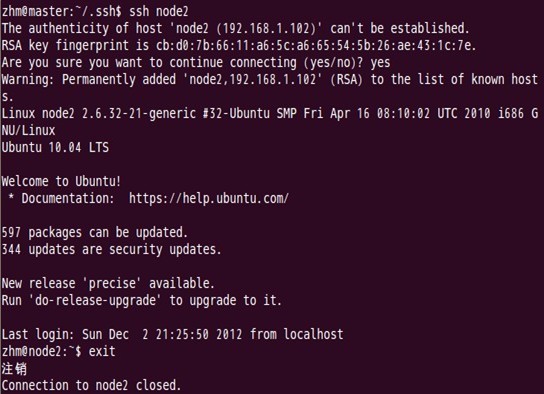
第二次登录时:

表面上看,这两个结点的ssh免密码登录已经配置成功,但是我们还需要对主结点master也要进行上面的同样工作,这一步有点让人困惑,但是这是有原因的,具体原因现在也说不太好,据说是真实物理结点时需要做这项工作,因为jobtracker有可能会分布在其它结点上,jobtracker有不存在master结点上的可能性。
对master自身进行ssh免密码登录测试工作:
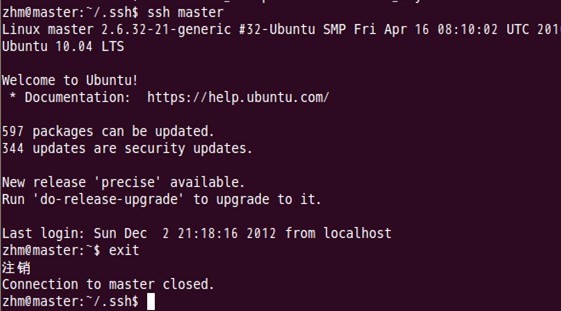
至此,SSH免密码登录已经配置成功。
四、下载并解压hadoop安装包
关于安装包的下载就不多说了,不过可以提一下目前我使用的版本为hadoop-0.20.2,
这个版本不是最新的,不过学习嘛,先入门,后面等熟练了再用其它版本也不急。而且《hadoop权威指南》这本书也是针对这个版本介绍的。
注:解压后hadoop软件目录在/home/zhm/hadoop下
五、配置namenode,修改site文件
在配置site文件之前需要作一些准备工作,下载Java最新版的JDK软件,可以从Oracle官网上下载,我使用的jdk软件版本为:jdk1.7.0_09,我将java的JDK解压安装在/opt/jdk1.7.0_09目录中,接着配置JAVA_HOME宏变量及hadoop路径,这是为了方便后面操作,这部分配置过程主要通过修改/etc/profile文件来完成,在profile文件中添加如下几行代码:

然后执行: 
让配置文件立刻生效。上面配置过程每个结点都要进行一遍。
到目前为止,准备工作已经完成,下面开始修改hadoop的配置文件了,即各种site文件,文件存放在/hadoop/conf下,主要配置core-site.xml、hdfs-site.xml、mapred-site.xml这三个文件。
Core-site.xml配置如下:
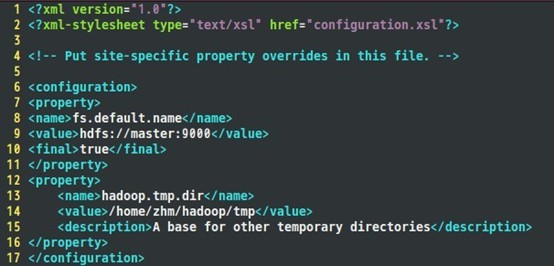
Hdfs-site.xml配置如下:
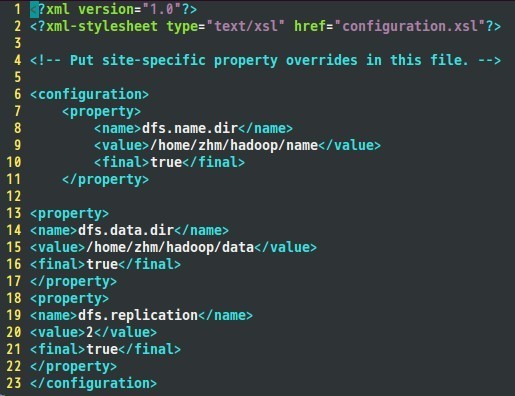
接着是mapred-site.xml文件:
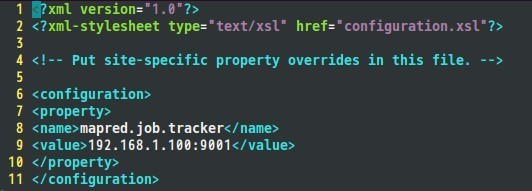
六、配置hadoop-env.sh文件
这个需要根据实际情况来配置。

七、配置masters和slaves文件
根据实际情况配置masters的主机名,在本实验中,masters主结点的主机名为master,
于是在masters文件中填入:

同理,在slaves文件中填入:
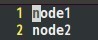
八、向各节点复制hadoop
向node1节点复制hadoop:
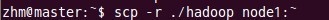
向node2节点复制hadoop:

这样,结点node1和结点node2也安装了配置好的hadoop软件了。
九、格式化namenode
这一步在主结点master上进行操作:
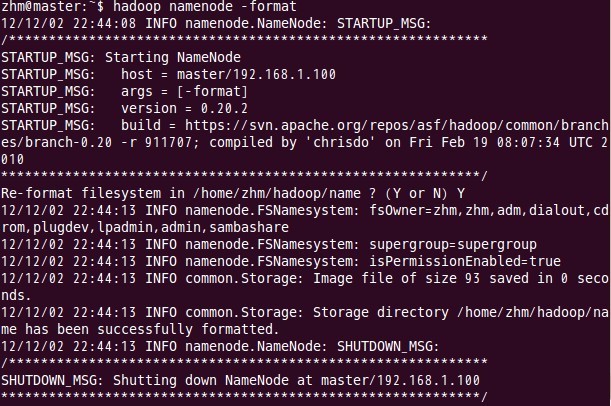
注意:上面只要出现“successfully formatted”就表示成功了。
十、启动hadoop
这一步也在主结点master上进行操作:
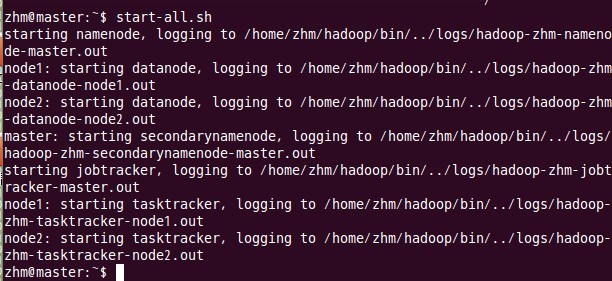
十一、 用jps检验各后台进程是否成功启动
在主结点master上查看namenode,jobtracker,secondarynamenode进程是否启动。

如果出现以上进程则表示正确。
在node1和node2结点了查看tasktracker和datanode进程是否启动。
先来node1的情况:

下面是node2的情况:

进程都启动成功了。恭喜~~~
十二、 通过网站查看集群情况
在浏览器中输入:http://192.168.1.100:50030,网址为master结点所对应的IP:
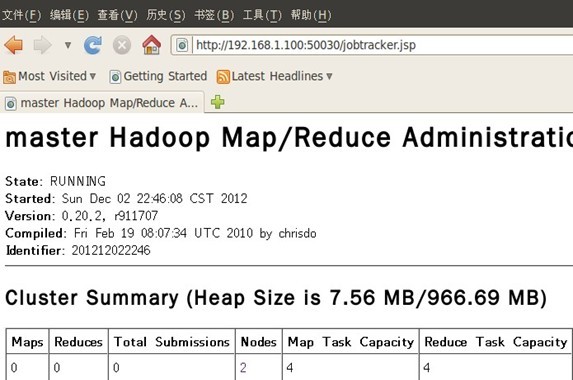

在浏览器中输入:http://192.168.1.100:50070,网址为master结点所对应的IP:
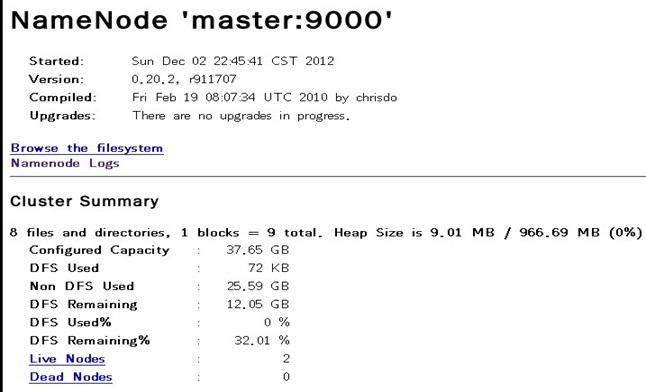
至此,hadoop的完全分布式集群安装已经全部完成,可以好好睡个觉了。~~
-
顶
- 25
-
踩
- 2
我的同类文章
- •hadoop学习之hadoop集群功能简单测试验证2012-12-08阅读10693
参考知识库
-
Hadoop知识库
6419关注|556收录

-
.NET知识库
3367关注|827收录

-
Oracle知识库
4453关注|252收录

-
Linux知识库
10612关注|3759收录

-
操作系统知识库
5360关注|2210收录

-
Java SE知识库
24114关注|477收录

-
Java EE知识库
16182关注|1265收录

-
Java 知识库
23970关注|1450收录

-
软件测试知识库
3977关注|310收录

-
算法与数据结构知识库
14265关注|2320收录

-
猜你在找















 2555
2555

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










35楼 匋宸 4天前 14:47发表 [回复]-

-
mark
34楼 xudongdong99 2017-02-22 17:53发表 [回复]-

-
写的很好,很详细,赞楼主
33楼 wu8983111 2016-11-07 11:05发表 [回复]-

-
看了这么多,楼主这个写的最详细清楚,赞!
32楼 thymerh 2016-07-15 10:20发表 [回复]-

-
ssh:localhost,失败:Host key verification failed.
.ssh里也没有known_hosts文件,怎么解决呢求救
31楼 ntsjt 2016-06-05 11:10发表 [回复]-

-
zhm@master:~$ hadoop namenode -format/home/zhm/hadoop/bin/hadoop: line 258: /opt/jdk1.7.0_79/bin/java: No such file or directory
我的配置除了下载的jdk版本不一样(在相应的配置中也改了),其余全部按文章中做的,为什么会出现上述问题,不知如何处理,请教,请教,非常感谢,
30楼 klose 2016-06-02 20:20发表 [回复]-

-
按照楼主的做法,成功将原来的伪分布式弄成正真的分布式了,一次成功开心!!!
29楼 wpzsidis 2016-04-06 20:49发表 [回复]-

-
为什么我的其他都正常,就是没有JobTracker和taskTracker两个进程?
28楼 carol123456 2016-02-24 14:38发表 [回复]-

-
感谢大神,终于成功了
27楼 死不了的奥特曼 2016-01-31 11:21发表 [回复]-

-
大神帮我安装下,给你服务费。我安装了好几天都不行快要崩溃了。。。
26楼 firewindyfire 2015-12-18 09:51发表 [回复]-

-
简直太好了,讲得很详细,马上实践一下
25楼 mayfla 2015-12-09 20:00发表 [回复]-

-
赞
24楼 刘佳翰 2015-08-19 09:46发表 [回复]-

-
刚刚开始,过来学习!
23楼 宇辰君 2015-04-16 11:45发表 [回复]-

-
大神,还有一个更简单的方法,就是复制和粘贴,没错,就是在你刚安装好的第一个虚拟机节点,将整个系统目录进行复制,形成第二和第三个虚拟机节点,具体是怎么操作的呢?
root权限管理各个节点还是自己的账户,需要一个虚拟机三个linux系统运行就行,以后对每个Linux上DataNode做JDK.Hadoop配置,能不能也复制这种子节点的环境呢,不用每个系统都重新配置?
谢谢,最近做这个,Q578645954希望详细请教您,谢谢!!
22楼 a_Clown__ 2015-03-16 22:52发表 [回复]-

-
楼主你好
请问您的虚拟机分配 了多大的内存呢?
21楼 wyl43381998 2015-02-25 19:11发表 [回复]-

-
部分作为参考吧,有图有过程,但是少量过程有省略,让人糊涂不知所措了,而且现在版本已经stable2.6.0.本文有一定的参考价值,但不完全实用了
20楼 wyl43381998 2015-02-24 20:56发表 [回复]-

-
我配置hadoop用户组的时候 提示group ‘admin’ does not exist
好奇怪大神你是怎么成功的,-G 后面我只填了个root。啥都干不了,神奇的ubuntu太神奇了,
19楼 EnterPine 2015-01-20 22:25发表 [回复]-

-
学习了,博主很用心,很佩服。。其实本来很害怕虚拟机装3遍,楼主直接复制目录的方法太方便了,受教了~~~~
18楼 搁浅的贝 2015-01-02 11:29发表 [回复]-

-
多谢了,博主好人啊! hadoop不再遥不可及了也。多谢多谢。
17楼 feige1990 2014-09-25 09:21发表 [回复]-

-
楼主你好
请问您的虚拟机分配 了多大的内存呢?
16楼 wangzhe_real 2014-06-09 08:48发表 [回复]-

-
楼主我想问一下,虚拟机和主机能够互联是不是必须要在主机用网线连接到一个局域网内?最近刚接触,很多不是太熟悉,望赐教
15楼 equalrest 2014-05-16 21:11发表 [回复]-

-
大神!!!我配置hadoop用户组的时候 提示group ‘admin’ does not exist
14楼 lunfangyu 2014-03-30 16:00发表 [回复]-

-
文中的“其实还有一个更简单的方法,就是复制和粘贴,没错,就是在你刚安装好的第一个虚拟机节点,将整个系统目录进行复制”这句话很容易让人误解成:“在虚拟机下复制整个系统目录“;我想在这里所要表达的意思应该是说复制两次虚拟机形成第二、第三个切点吧;最终结果应该是有三个虚拟机的;我初看时认为是在一个虚拟机中复制系统目录形成三个节点了呢!不知大神认为我的解读正确否?!
13楼 lunfangyu 2014-03-30 15:41发表 [回复]-

-
大神,请教一个你认为很简单的问题:文中在第三步:“还有一个更简单的方法,就是复制和粘贴,没错,就是在你刚安装好的第一个虚拟机节点,将整个系统目录进行复制,形成第二和第三个虚拟机节点。”这里是指复制虚拟机变成三个虚拟机还是指复制目录?如果是复制目录,请问在复制后是直接粘贴在当前目录下进行目录重命名吗?还是说要放到新建文件夹里?
12楼 拖拖记得正能量 2014-03-30 14:33发表 [回复]-

-
您好 有个问题想请教一下 我按照您的步骤安装成功了 不过只有root用户才能正常启动 这是什么问题呢?
11楼 lunfangyu 2014-03-30 12:06发表 [回复]-

-
大神,请教一个你认为很简单的问题:在第三步准备虚拟机的节点时“还有一个更简单的方法,就是复制和粘贴,没错,就是在你刚安装好的第一个虚拟机节点,将整个系统目录进行复制,形成第二和第三个虚拟机节点。”请问在复制后是直接粘贴在当前目录下进行目录重命名吗?还是说要放到新建文件夹里?
10楼 松月 2013-12-10 16:47发表 [回复]-

-
太感谢你了!终于集成成功了!是我看过最详细的文章了!
9楼 小琴是吃货 2013-09-12 18:30发表 [回复]-

-
还是我,必须在每个节点上创建自己hadoop账户吗?用root不行吗
Re: ab198604 2013-10-14 09:54发表 [回复]-

-
回复小琴是吃货:最好创建hadoop帐户来操作
8楼 小琴是吃货 2013-09-12 18:28发表 [回复]-

-
请问一下,我master和node1都是在root下进行的,目前master没错误,但是node1结点中datanode老是启动不了,日志文件里的错误是:Could not fin or load main class server?求大神回复啊!!
7楼 nianhua1208 2013-08-17 10:43发表 [回复]-

-
我的所有配置和启动都没问题了,但是总是只能启动namenode和secondnamenode,其他的都启动不了,请问是怎么回事呢??急死了!!
6楼 zerowmx 2013-05-08 11:29发表 [回复]-

-
你好,按照你的方法,在进行到format步骤时,出现了以下错误:
ERROR namenode.NameNode: java.io.IOException: Cannot create directory /home/hduser/hadoop/name/current
怎么弄啊~~~
Re: zasxza123 2013-08-01 15:56发表 [回复]-

-
回复zerowmx:你把临时文件tmp删掉 hadoop初始化的时候会自动建立临时文件系统
5楼 fly2749 2013-05-07 23:07发表 [回复]-

-
先收藏
4楼 lgming888888 2013-05-06 09:37发表 [回复]-

-
若是权限的问题,怎么改啊,大神?
小弟快抓狂了!!!!!!
3楼 lgming888888 2013-05-05 19:21发表 [回复]-

-
大神
在让主结点(master)能通过SSH免密码登录两个子结点(slave)这一步时,输入密码总是提示
Permission denied, please try again.
可以解释下为啥吗?
Re: ab198604 2013-05-06 09:33发表 [回复]-

-
回复lgming888888:你是在系统的一些目录下来操作的吗?应该是权限的问题。
Re: lgming888888 2013-05-06 09:35发表 [回复]-

-
我是在root下进行操作的
Re: ab198604 2013-05-06 09:41发表 [回复]-

-
回复lgming888888:对每个节点你有创建hadoop自己的运行帐号吗?只要在hadoop帐户下操作即可,也不需要是root的,在创建时已经有admin权限了
2楼 zhangyangshun 2013-03-14 14:24发表 [回复]-

-
非常感谢LZ分享学习经验!小的学习了!
1楼 liron71 2012-12-04 14:19发表 [回复] [引用] [举报]-

-
一种实现人工智能程序自进化的概念原理
http://blog.csdn.net/liron71/article/details/8242670