






seajs如此神奇,究竟是如何做到的呢,想知基原理,方可看其源码~~之前冲忙写下的,可能有点乱哦~~有什么不对的,欢迎拍砖!
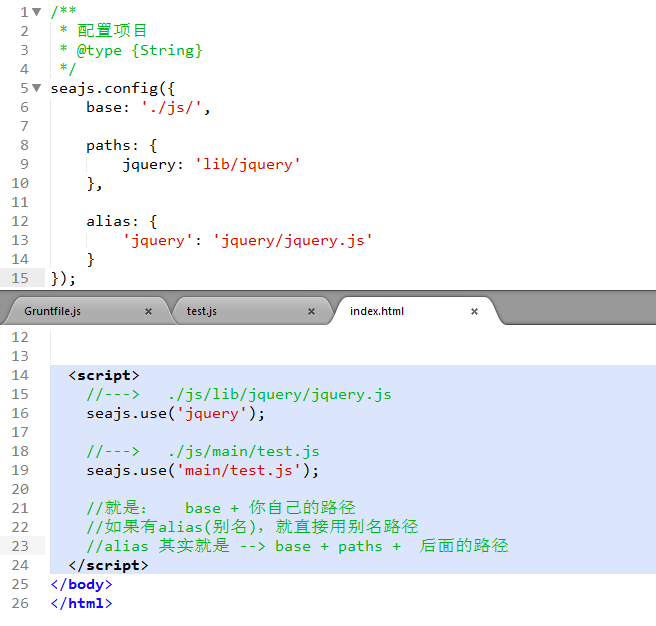
如果进入seajs了管理范围,那么路径分为:
1.
/ 或
http://www.xxx.com/
这些和平时用的都一样。
2.
./ 或
../
a.如果是在html中用seajs.use('./main/test.js'), 这些和平时用的都一样, seajs.config也是和平时的一样,引进在html,那么就是相对于html所在目录。
b.如果是在define(function (){ }), 则是相对于当前的js文件所在目录

3. 直接为目录开头的就会经过seajs的 base, alias,的处理
a. seajs.use('main/test.js');
b. define(function ( ){ require('main/test.js') });
即在你写的路径前加上 seajs的 base路径,
可以用seajs.config自定义配置,
如果不配置, base路径是seajs.js所在目录
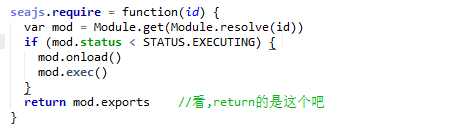
seajs源码解析id的过程
Module.resolve是给对seajs插件和没seajs插件时的一个兼容,如果没插件会调用下面的id2Uri对路径进行解析


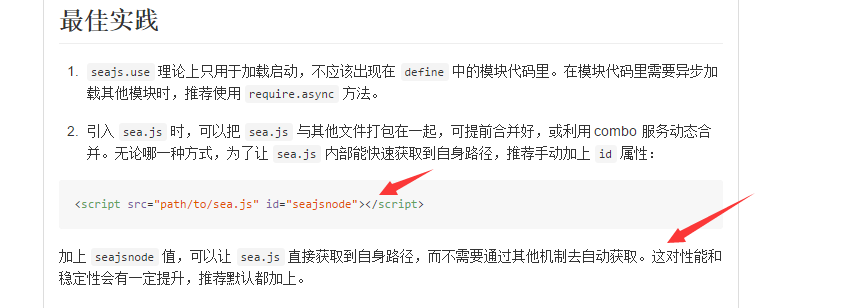
推荐在sea.js上加上id="seajsnode"


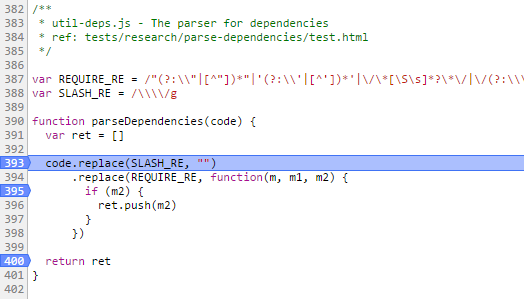
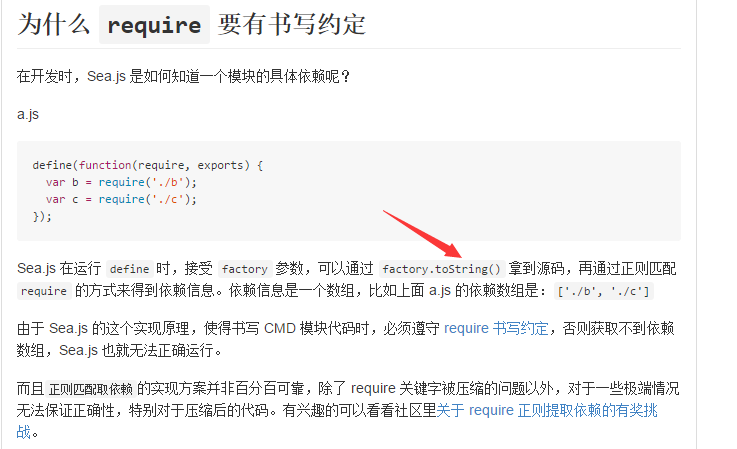
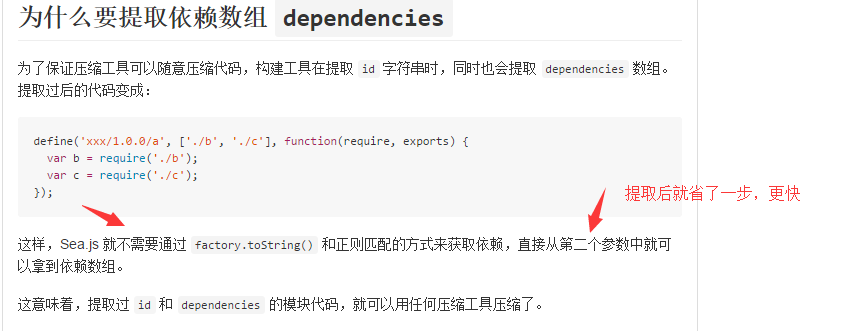
提取依赖,可以看出是通过正则来提取依赖的,所以如果在压缩时将require参数压成了a,是提取不到依赖的哦
















 1795
1795











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









